














2019 年是 JuiceFS 提供订阅式 SaaS 服务第二年,站在农历新年之前,回顾一下我们过去一年的工作进展,给关注我们的朋友们做一个总结汇报。
过去一年,我们为全球 16 个公有云,总计 100多个服务区提供即时可用的 SaaS 服务。 你只要有这些服务的账号,五分钟就可以创建并开始使用一个可存储 10PiB 容量,1 亿文件的共享文件系统,以最简单便捷的方式使用对象存储。
过去一年,我们全球的客户数据更新操作数量已经超过百亿。产品发布了 7 个版本,客户数量增长 1 倍,收入增长 4 倍。 团队分布在 5 个城市工作,在中国杭州、厦门、美国旧金山设有办公室,每个人都在自己专注的领域里拥有足够深入的挑战,以及足够开放的探索机会。
过去一年,我们专注于 JuiceFS 在大数据平台上的应用,帮助客户将自己基于 Hadoop 生态建设的大数据平台升级为存储计算分离的架构, 为客户提供高可用、全托管、弹性伸缩、兼容 HDFS 和 POSIX、高 ROI 的企业数据湖服务。并在一年的时间里完成了 100T - 1PB 不同量级客户的项目实施。
过去一年,我们也和优秀的合作伙伴一起在广电、安防、航空航天、金融证券等领域实施了私有云存储的项目。
下面说 5 个重要的产品升级。

首先,让我们说说 JuiceFS 为什么要去解决大数据平台存储计算分离的问题。 在 Hadoop 创立之初特意设计的存储计算耦合架构为什么今天不适用了?简而言之,因为在过去的十几年里,网络带宽提升了 100 倍以上,而磁盘 IO 没有明显变化,所以曾经的网络带宽瓶颈已经不存在了。而存储计算分离架构为部署、运维、扩缩容等方面带来了超多的灵活性,计算节点成为无状态节点,存储集群可以作为独立的服务来管理和使用。目前在云原生的环境中,不仅 Hadoop 其他领域也都在朝这个方向发展。我们在 2018年就写过一篇文章「为什么存储计算分离才是未来?」讨论这个话题。
实现存储计算分离,HDFS 是难以胜任的,目前也还没有一家公有云提供了弹性的 HDFS 全托管服务。用户希望用对象存储,AWS 也继 s3:// 之后相继推出了 s3n:// 和 s3a:// 等协议去加强大数据场景下的表现,但始终无法彻底解决数据一致性和文件原子语义的问题(如:rename),性能表现也不好。
JuiceFS 最初就是为云环境下的海量数据分析而设计的。但是在 2018 年刚推出时,我们只有 POSIX 接口,客户把 JuiceFS 用在大数据环境中,可以用 local filesystem 的方式,但是随着业务使用范围的扩大我们发现 Hadoop 计算框架大多为 HDFS 接口做优化,local filesystem 接口的性能表现有时实在对不起观众。所以,在 2019 年里我们发布了 JuiceFS Java SDK for Hadoop,完全兼容了 HDFS API,包括快照,ACL 等。通过 SDK 不仅可以完美支持所有的 Hadoop 计算框架,还包括 Kerberos、Ranger 等权限管理组件。而且,通过 SDK 还可以获得本地缓存和调度优化,性能可以达到有数据本地化的 HDFS 同样的水准。

第二,JuiceFS 元数据管理具备了多机分布式的横向扩展能力,支持单一文件系统 100 亿文件。 熟悉文件系统的朋友应该知道,目前最流行的几个开源文件系统中,HDFS、CephFS、GlusterFS 都无法支撑 10 亿以上的文件数量,最高端的商用 NAS 产品因为价格原因,少有客户会用来支撑这样的大规模数据存储。而在客户越来越清晰数据价值的今天,只好随着数据规模的增长,不得不去维护很多套存储集群,这样带来的问题是管理难度大、成本高,资源利用率低,采购周期长。JuiceFS 做为软件定义存储方案,为企业客户提供数据统一管理,统一名字空间的方案,无论对 IT 运维部门还是业务部分,都是高性价比的选择。
随着近几年深度学习为 CV(计算机视觉)方向带来的快速发展,在人脸识别、自动驾驶等领域,要分析、处理的数据量越来越大,通常是数十亿到数百亿的小文件,大小在几十至几百 KB。就训练数据的管理来说,无论对哪一个存储系统来说都是巨大的挑战。目前,JuiceFS 已经在独角兽级别的自动驾驶公司落地,除了优秀的元数据管理能力外,多机共享和 POSIX 兼容对用户来说没有任何学习和使用门槛,大幅提升了团队的工作效率。

第三方面,JuiceFS 在一年的时间里做了多方面的性能改进和兼容性提升,并陆续发布了一些结果,包括:
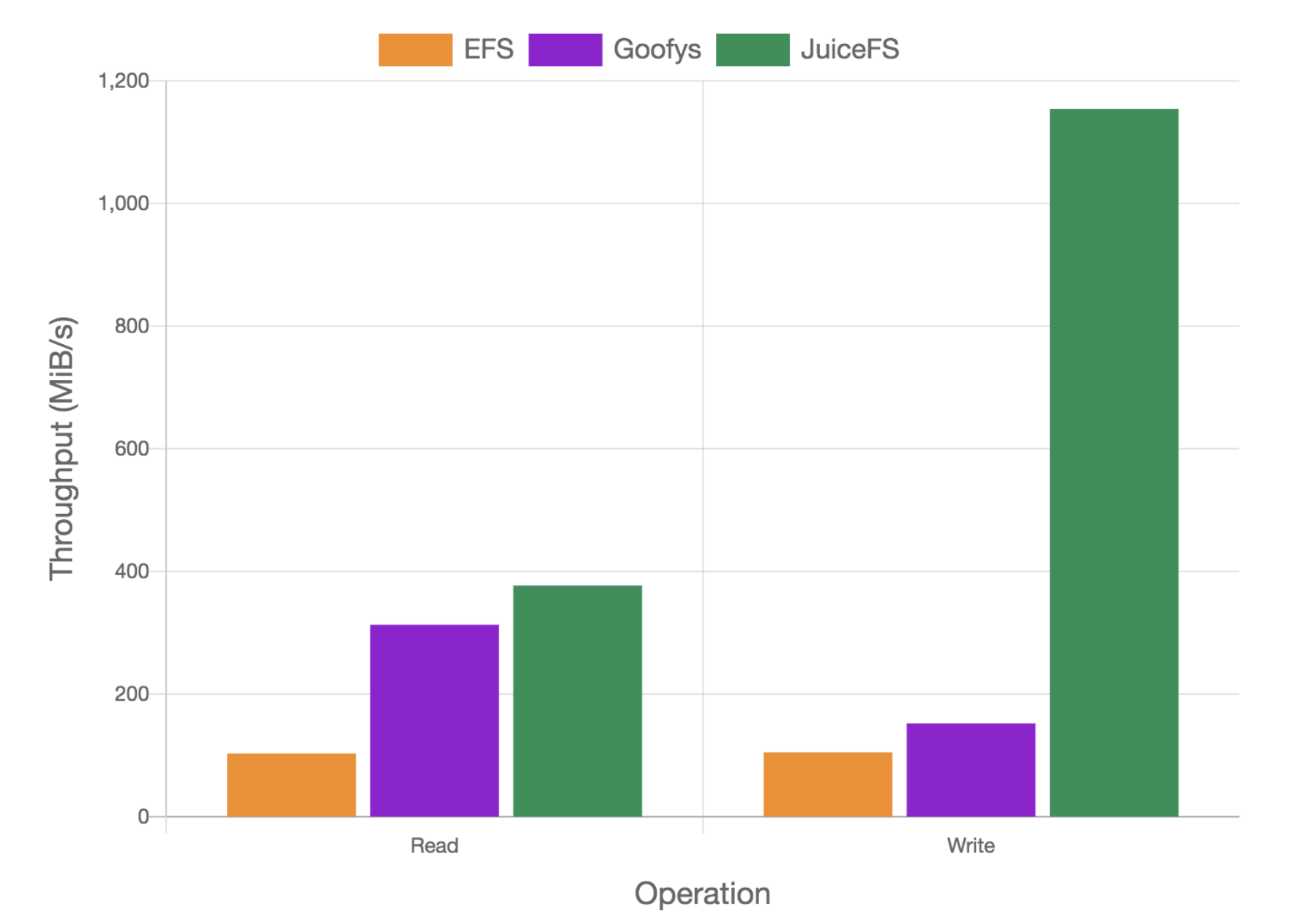
JuiceFS 与 AWS EFS,Goofys 的性能比较
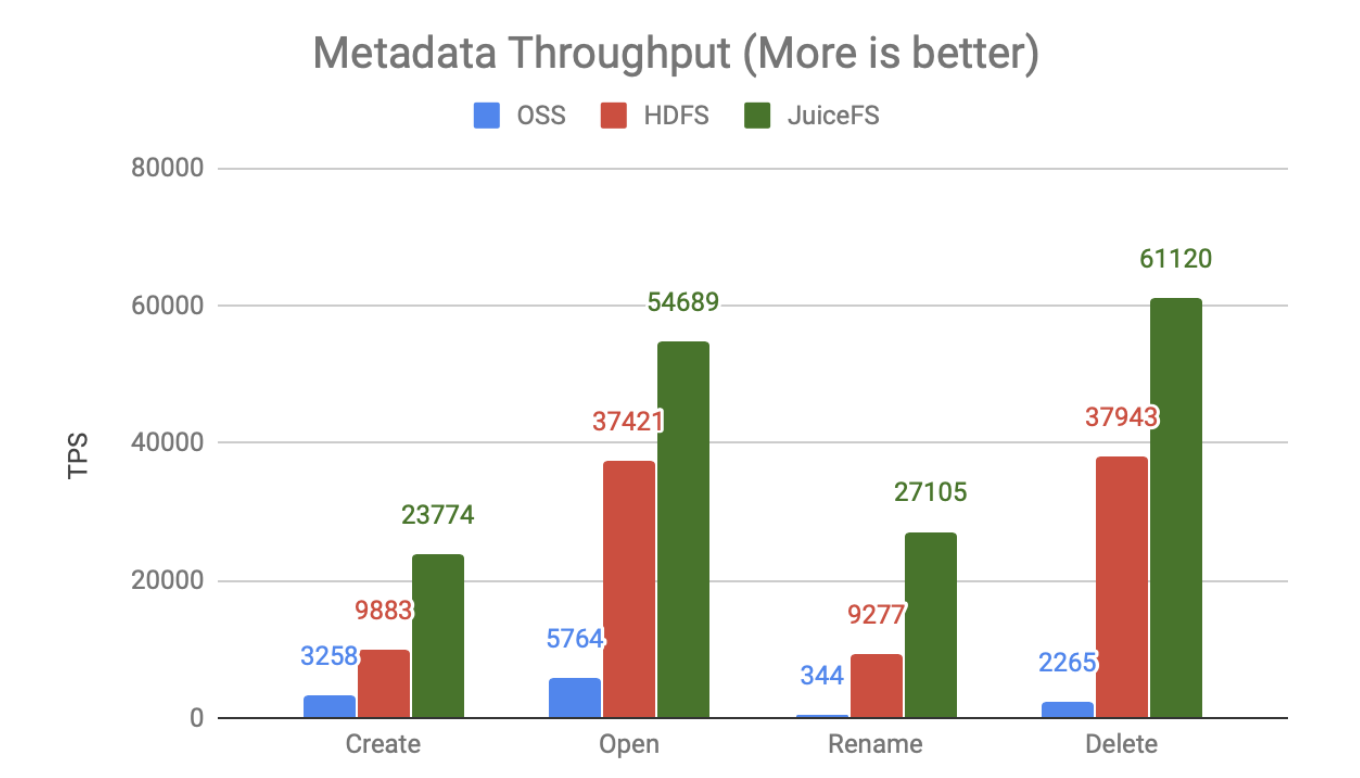
JuiceFS 与 HDFS,Aliyun OSS 的元数据性能比较
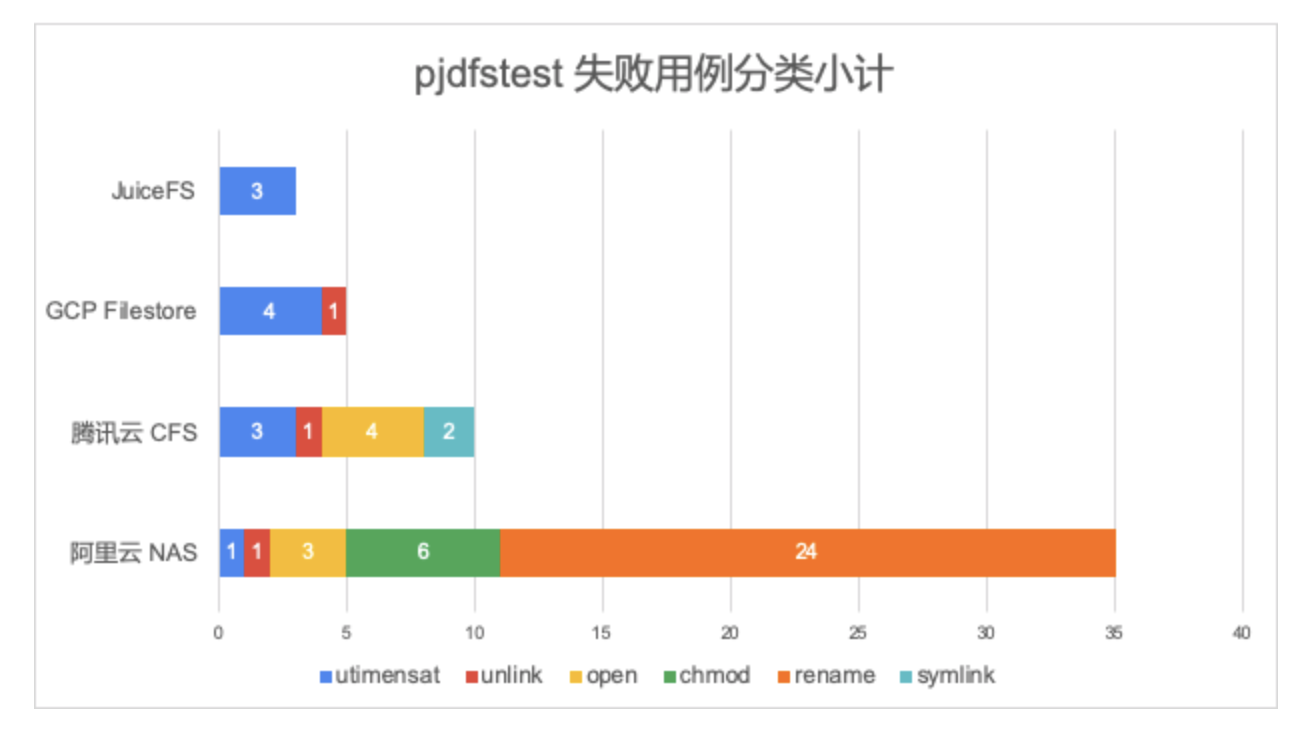
JuiceFS 与多家公有云文件存储服务的 pjdfstest 兼容性比较

第四方面,JuiceFS 有了 CSI 插件支持 Kubernetes,这也是在客户需求推动下完成的功能。 Kubernetes 的流行有目共睹,但持久卷(Persistent Volume)的方案选择一直是用户左右为难的事情。JuiceFS 作为 POSIX 兼容的共享文件系统,在 Kubernetes 中完成日志收集、中间临时数据落盘、Model Serving 等需求再适合不过。还有客户直接用 JuiceFS 做了 Docker Registry 的存储,再也不用担心磁盘空间不足了。

最后,JuiceFS 已经支持私有部署,后端对象存储可以支持几个商业对象存储、Ceph 和 MinIO 等,并完成了几个不同行业的客户实施。
2019 年也有遗憾,我们在市场方面投入的精力太少了,没有做线下大会演讲,没有参加奖项评选,没有在行业活动上布展。只组织了一个几百人的线上 User Group,集合了国内最棒的一批系统工程师、存储工程师、SRE,大家聚到一起交流还是挺活跃的(加入 JuiceFS 开源社区)。写了几篇文章,内容都比较长,比较多干货:
- 如何让 HBase 更快、更稳、更省钱
- 如何解决 NAS 单点故障还顺便省了 90% 成本
- 元数据性能大比拼:HDFS vs OSS vs JuiceFS
- Linux 进程卡住了怎么办?
- 云上共享文件系统的兼容性大比拼
归根到底,客户信任与满意是我们前进的根基和动力。

2018 年客户选择 JuiceFS 主要还是用来做归档、备份等非核心业务场景。2019 年客户已经将 JuiceFS 用在了大数据平台、Kubernetes PV 等场景中,承载很高的 workload,我们喜欢这样的考验,也交了一份不错的答卷。
感谢您的阅读,2020 共创。
