














为了提升性能,JuiceFS 在数据存储过程中实施了分块策略,chunk、slice 、block 等概念以及他们的工作原理对于新用户来说,并不容易理解。本文转载自社区用户 Arthur ,他将结合代码示例深入解析 JuiceFS 的设计原理,包括数据存储及元数据存储。本文为其系列长文中的部分内容。原文请点此查看。
1 对象存储中 JuiceFS 写入的文件
以 MinIO 为例,来看 JuiceFS 写入到对象存储中的文件是怎样组织的。其他云厂商的对象存储(AWS S3、阿里云 OSS 等)也都是类似的。
1.1 Bucket 内:每个 volume 一个“目录”
可以用 juicefs format 命令再创建两个 volume,方便观察它们在 bucket 中的组织关系,
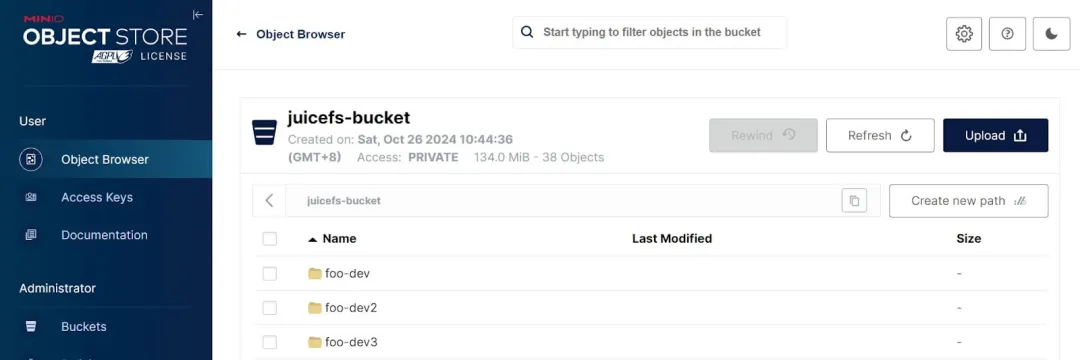
如上图所示,bucket 内的顶层“目录”就是 JuiceFS 的 volumes, 我们这里提到“目录”时加双引号,是因为对象存储是扁平的 key-value 存储,没有目录的概念, 前端展示时模拟出目录结构(key 前缀一样的,把这个前缀作为一个“目录”)是为了查看和理解方便。简单起见,后文不再加双引号。
1.2 每个 volume 的目录:{chunks/, juicefs_uuid, meta/, ...}
每个 volume 目录内的结构如下:
|-chunks/ # 数据目录,volume 中的所有用户数据都放在这里面
|-juicefs_uuid
|-meta/ # `juicefs mount --backup-meta ...` 产生的元数据备份存放的目录
1.2.1 juicefs_uuid:JuiceFS volume 的唯一标识
可以把这个文件下载下来查看内容,会发现里面存放的就是 juicefs format 输出里看到的那个 uuid, 也就是这个 volume 的唯一标识。
删除 volume 时需要用到这个 uuid。
1.2.2 meta/:JuiceFS 元数据备份
如果在 juicefs mount 时指定了 --backup-meta,JuiceFS 就会定期把元数据(存在在 TiKV 中)备份到这个目录中, 用途:
- 元数据引擎故障时,可以从这里恢复;
- 在不同元数据引擎之间迁移元数据。详见JuiceFS 元数据引擎五探:元数据备份与恢复(2024)。
1.2.3 chunks/
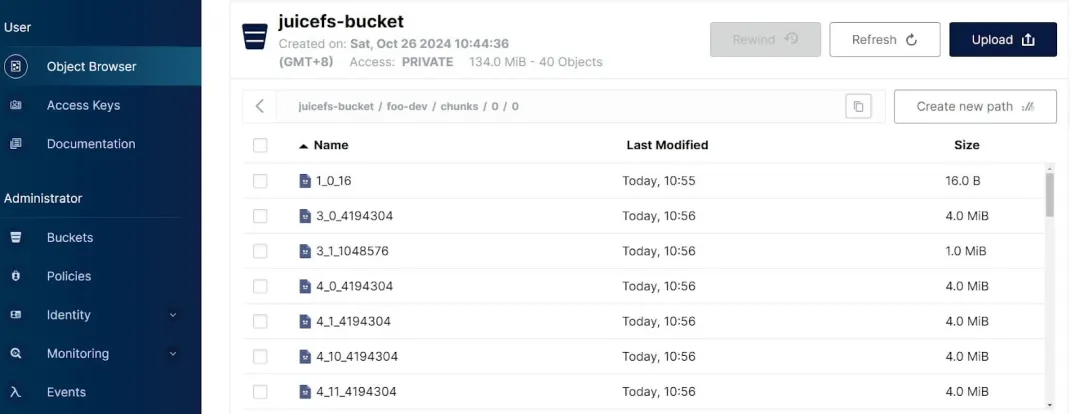
chunks/ 内的目录结构如下,
|-chunks/
| |-0/ # <-- id1 = slice_id / 1000 / 1000
| | |-0/ # <-- id2 = slice_id / 1000
| | |-1_0_16 # <-- {slice_id}_{block_id}_{size_of_this_block}
| | |-3_0_4194304 #
| | |-3_1_1048576 #
| | |-...
|-juicefs_uuid
|-meta/
如上,所有的文件在 bucket 中都是用数字命名和存放的,分为三个层级:
- 第一层级:纯数字,是 sliceID 除以 100 万得到的;
- 第二层级:纯数字,是 sliceID 除以 1000 得到的;
- 第三层级:纯数字加下划线,{slice_id}{block_id}{size_of_this_block},表示的是这个 chunk 的这个 slice 内的 block_id 和 block 的大小。不理解 chunk/slice/block 这几个概念没关系,我们马上将要介绍。
1.3 小结
通过以上 bucket 页面,我们非常直观地看到了一个 JuiceFS volume 的所有数据在对象存储中是如何组织的。
接下来进入正题,了解一下 JuiceFS 的数据和元数据设计。
2 JuiceFS 数据的设计
2.1 顶层切分:一切文件先切 chunk
对于每个文件,JuiceFS 首先会按固定大小(64MB)切大块, 这些大块称为「Chunk」。
- 这是为了读或修改文件内容时,方便查找和定位。
- 不管是一个只有几字节的文本文件,还是一个几十 GB 的视频文件, 在 JuiceFS 中都是切分成 chunk,只是 chunk 的数量不同而已。
2.1.1 示意图

2.1.2 对象存储:不存在 chunk 实体
结合上一节在对象存储中看到的目录结构,
|-chunks/
| |-0/ # <-- id1 = slice_id / 1000 / 1000
| | |-0/ # <-- id2 = slice_id / 1000
| | |-1_0_16 # <-- {slice_id}_{block_id}_{size_of_this_block}
| | |-3_0_4194304 #
| | |-3_1_1048576 #
| | |-...
|-juicefs_uuid
|-meta/
- Chunk 在对象存储中 没有对应任何实际文件,也就是说在对象存储中没有一个个 64MB 的 chunks;
- 用 JuiceFS 的话来说,Chunk 是一个逻辑概念。暂时不理解没关系,接着往下看。
2.2 Chunk 内的一次连续写入:Slice
chunk 只是一个“框”,在这个框里面对应文件读写的,是 JuiceFS 称为「Slice」 的东西。chunk 内的一次连续写入,会创建一个 slice,对应这段连续写入的数据;由于 slice 是 chunk 内的概念,因此它不能跨 Chunk 边界,长度也不会超 max chunk size 64M。slice ID 是全局唯一的;
2.2.1 Slice 的重叠问题
根据写入行为的不同,一个 Chunk 内可能会有多个 Slice, 如果文件是由一次连贯的顺序写生成,那每个 Chunk 只包含一个 Slice。如果文件是多次追加写,每次追加均调用 flush 触发写入上传,就会产生多个 Slice。

以 chunk1 为例,
- 用户先写了一段 ~30MB 数据,产生 slice5;
- 过了一会,从 ~20MB 的地方重新开始写 45MB(删掉了原文件的最后一小部分,然后开始追加写),
- chunk1 内的部分产生 slice6;
- 超出 chunk1 的部分,因为 slice 不能跨 chunk 边界,因此产生 chunk2 和 slice7;
- 过了一会,从 chunk1 ~10MB 的地方开始修改(覆盖写),产生 slice8。由于 Slice 存在重叠,因此引入了几个字段标识它的有效数据范围,
type slice struct {
id uint64
size uint32
off uint32
len uint32
pos uint32
left *slice // 这个字段不会存储到 TiKV 中
right *slice // 这个字段不会存储到 TiKV 中
}
2.2.2 读 chunk 数据时的多 slice 处理:碎片化和碎片合并
对 JuiceFS 用户来说,文件永远只有一个,但在 JuiceFS 内部,这个文件对应的 Chunk 可能会有多个重叠的 Slice,
- 有重叠的部分,以最后一次写入的为准。
- 直观上来说,就是上图 chunk 中的 slices 从上往下看,被盖掉的部分都是无效的。
因此,读文件时,需要查找「当前读取范围内最新写入的 Slice」,
- 在大量重叠 Slice 的情况下,这会显著影响读性能,称为文件「碎片化」。
- 碎片化不仅影响读性能,还会在对象存储、元数据等层面增加空间占用。
- 每当写入发生时,客户端都会判断文件的碎片化情况,并异步地运行碎片合并,将一个 Chunk 内的所有 Slice 合并。
2.2.3 对象存储:不存在 slice 实体
跟 chunk 类似,在对象存储中 slice 也没有 没有对应实际文件。
|-chunks/
| |-0/ # <-- id1 = slice_id / 1000 / 1000
| | |-0/ # <-- id2 = slice_id / 1000
| | |-1_0_16 # <-- {slice_id}_{block_id}_{size_of_this_block}
| | |-3_0_4194304 #
| | |-3_1_1048576 #
| | |-...
|-juicefs_uuid
|-meta/
2.3 Slice 切分成固定大小 Block(e.g. 4MB):并发读写对象存储
为了加速写到对象存储,JuiceFS 将 Slice 进一步拆分成一个个「Block」(默认 4MB),多线程并发写入。

Block 是 JuiceFS 数据切分设计中最后一个层级,也是 chunk/slice/block 三个层级中唯一能在 bucket 中看到对应文件的。
- 连续写:前面 Block 默认都是 4MB,最后一个 Block 剩多少是多少。
- 追加写:数据不足 4MB 时,最终存入对象存储的也会是一个小于 4M 的 Block。
从上图的名字和大小其实可以看出分别对应我们哪个文件:
1_0_16:对应我们的file1_1KB;- 我们上一篇的的追加写
echo "hello" >> file1_1KB并不是写入了1_0_16, 而是创建了一个新对象7_0_16,这个 object list 最后面,所以在截图中没显示出来; - 换句话说,我们的
file1_1KB虽然只有两行内容,但在 MinIO 中对应的却是两个 object,各包含一行。 - 通过这个例子,大家可以体会到 JuiceFS 中连续写和追加写的巨大区别。
- 我们上一篇的的追加写
3_0_4194304 + 3_1_1048576:总共 5MB,对应我们的file2_5MB;4_*:对应我们的file3_129MB;
2.4 object key 命名格式(及代码)
格式:{volume}/chunks/{id1}/{id2}/{slice_id}_{block_id}_{size_of_this_block},对应的代码,
func (s *rSlice) key(blockID int) string {
if s.store.conf.HashPrefix // false by default
return fmt.Sprintf("chunks/%02X/%v/%v_%v_%v", s.id%256, s.id/1000/1000, s.id, blockID, s.blockSize(blockID))
return fmt.Sprintf("chunks/%v/%v/%v_%v_%v", s.id/1000/1000, s.id/1000, s.id, blockID, s.blockSize(blockID))
}
2.5 将 chunk/slice/block 对应到对象存储
最后,我们将 volume 的数据切分和组织方式对应到 MinIO 中的路径和 objects,
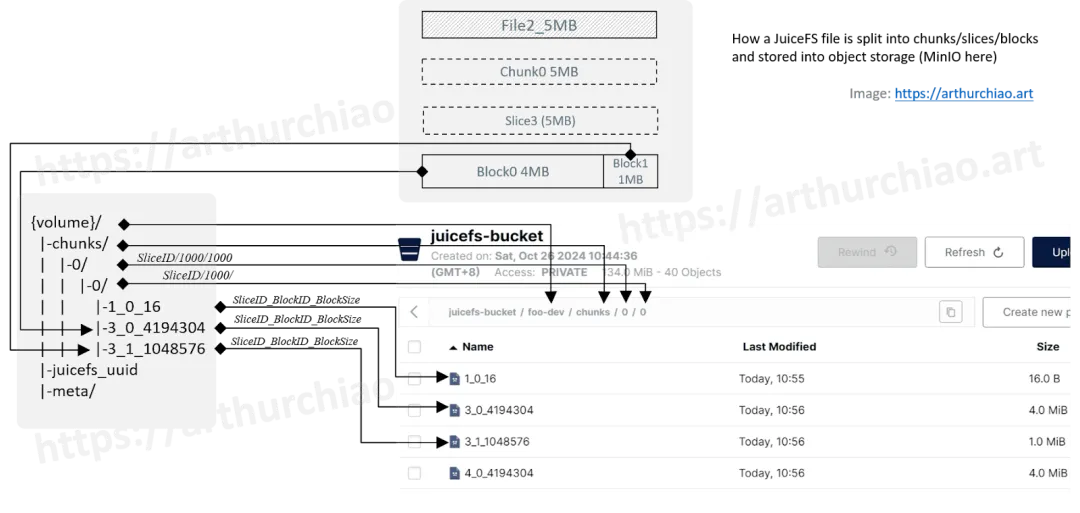
2.6 小结:光靠对象存储数据和 slice/block 信息无法还原文件
至此,JuiceFS 解决了数据如何切分和存放的问题,这是一个正向的过程:用户创建一个文件,我们能按这个格式切分、命名、上传到对象存储。对应的反向过程是:给定对象存储中的 objects,我们如何将其还原成用户的文件呢?显然,光靠 objects 名字中包含的 slice/block ID 信息是不够的,例如,
- 最简单情况下,每个 chunk 都没有任何 slice 重叠问题,那我们能够根据 object 名字中的 slice_id/block_id/block_size 信息拼凑出一个文件, 但仍然无法知道这个文件的文件名、路径(父目录)、文件权限(rwx)等等信息;
- chunk 一旦存在 slice 重叠,光靠对象存储中的信息就无法还原文件了;
- 软链接、硬链接、文件属性等信息,更是无法从对象存储中还原。
解决这个反向过程,我们就需要文件的一些元数据作为辅助 —— 这些信息在文件切分和写入对象存储之前,已经记录到 JuiceFS 的元数据引擎中了。
3 JuiceFS 元数据的设计(TKV 版)
JuiceFS 支持不同类型的元数据引擎,例如 Redis、MySQL、TiKV/etcd 等等,每种类型的元数据引擎都有自己的 key 命名规则。本文讨论的是 JuiceFS 使用 transactional key-value(TKV)类型的元数据引擎时的 key 命名规则。更具体地,我们将拿 TiKV 作为元数据引擎来研究。
3.1 TKV 类型 key 列表
这里的 key 是 JuiceFS 定义元数据 key,key/value 写入元数据引擎;请注意跟前面提到的对象存储 key 区别开,那个 key/value 是写入对象存储的。key 是一个字符串,所有 key 的列表,
setting format
C{name} counter
A{8byte-inode}I inode attribute
A{8byte-inode}D{name} dentry
A{8byte-inode}P{8byte-inode} parents // for hard links
A{8byte-inode}C{4byte-blockID} file chunks
A{8byte-inode}S symlink target
A{8byte-inode}X{name} extented attribute
D{8byte-inode}{8byte-length} deleted inodes
F{8byte-inode} Flocks
P{8byte-inode} POSIX locks
K{8byte-sliceID}{8byte-blockID} slice refs
Ltttttttt{8byte-sliceID} delayed slices
SE{8byte-sessionID} session expire time
SH{8byte-sessionID} session heartbeat // for legacy client
SI{8byte-sessionID} session info
SS{8byte-sessionID}{8byte-inode} sustained inode
U{8byte-inode} usage of data length, space and inodes in directory
N{8byte-inode} detached inde
QD{8byte-inode} directory quota
R{4byte-aclID} POSIX acl
在 TKV 的 Keys 中,所有整数都以编码后的二进制形式存储:
- inode 和 counter value 占 8 个字节,使用小端编码
- SessionID、sliceID 和 timestamp 占 8 个字节,使用大端编码 setting 是一个特殊的 key,对应的 value 就是这个 volume 的设置信息。前面的 JuiceFS 元数据引擎系列文章中介绍过,这里不再赘述。
其他的,每个 key 的首字母可以快速区分 key 的类型,
- C:counter,这里面又包含很多种类,例如 name 可以是:
- nextChunk
- nextInode
- nextSession
- A:inode attribute
- D:deleted inodes
- F:Flocks
- P:POSIX lock
- S:session related
- K:slice ref
- L: delayed (to be deleted?) slices
- U:usage of data length, space and inodes in directory
- N:detached inode
- QD:directory quota
- R:POSIX acl
需要注意的是,这里是 JuiceFS 定义的 key 格式,在实际将 key/value 写入元数据引擎时, 元数据引擎可能会对 key 再次进行编码,例如 TiKV 就会在 key 中再插入一些自己的字符。前面的 JuiceFS 元数据引擎系列文章中也介绍过,这里不再赘述。
3.2 元数据引擎中的 key/value
3.2.1 扫描相关的 TiKV key
TiKV 的 scan 操作类似 etcd 的 list prefix,这里扫描所有 foo-dev volume 相关的 key,
key: zfoo-dev\375\377A\000\000\000\020\377\377\377\377\177I\000\000\000\000\000\000\371
key: zfoo-dev\375\377A\001\000\000\000\000\000\000\377\000Dfile1_\3771KB\000\000\000\000\000\372
key: zfoo-dev\375\377A\001\000\000\000\000\000\000\377\000Dfile2_\3775MB\000\000\000\000\000\372
...
key: zfoo-dev\375\377SI\000\000\000\000\000\000\377\000\001\000\000\000\000\000\000\371
default cf value: start_ts: 453485726123950084 value: 7B225665727369...33537387D
key: zfoo-dev\375\377U\001\000\000\000\000\000\000\377\000\000\000\000\000\000\000\000\370
key: zfoo-dev\375\377setting\000\376
default cf value: start_ts: 453485722598113282 value: 7B0A224E616D65223A202266...0A7D
3.2.2 解码成 JuiceFS metadata key
用 tikv-ctl --decode <key>可以解码出来,注意去掉最前面的 z,得到的就是 JuiceFS 的原始 key,看着会更清楚一点,
foo-dev\375A\001\000\000\000\000\000\000\000Dfile1_1KB
foo-dev\375A\001\000\000\000\000\000\000\000Dfile2_5MB
foo-dev\375A\001\000\000\000\000\000\000\000Dfile3_129MB
foo-dev\375A\001\000\000\000\000\000\000\000I
foo-dev\375A\002\000\000\000\000\000\000\000C\000\000\000\000
foo-dev\375A\002\000\000\000\000\000\000\000I
foo-dev\375A\003\000\000\000\000\000\000\000C\000\000\000\000
foo-dev\375A\003\000\000\000\000\000\000\000I
foo-dev\375A\004\000\000\000\000\000\000\000C\000\000\000\000
foo-dev\375A\004\000\000\000\000\000\000\000C\000\000\000\001
foo-dev\375A\004\000\000\000\000\000\000\000C\000\000\000\002
foo-dev\375A\004\000\000\000\000\000\000\000I
foo-dev\375ClastCleanupFiles
foo-dev\375ClastCleanupSessions
foo-dev\375ClastCleanupTrash
foo-dev\375CnextChunk
foo-dev\375CnextCleanupSlices
foo-dev\375CnextInode
foo-dev\375CnextSession
foo-dev\375CtotalInodes
foo-dev\375CusedSpace
foo-dev\375SE\000\000\000\000\000\000\000\001
foo-dev\375SI\000\000\000\000\000\000\000\001
foo-dev\375U\001\000\000\000\000\000\000\000
foo-dev\375setting
从上面的 keys,可以看到我们创建的三个文件的元信息了, 这里面是用 slice_id 等信息关联的,所以能和对象存储里的数据 block 关联上。
可以基于上一节的 key 编码规则进一步解码,得到更具体的 sliceID/inode 等等信息,这里我们暂时就不展开了。
5 这个设计下产生的常见问题
5.1 如何从数据和元数据中恢复文件
5.1.2 理论步骤
对于一个给定的 JuiceFS 文件,我们在上一篇中已经看到两个正向的过程: 1. 文件本身被切分成 Chunk、Slice、Block,然后写入对象存储; 2. 文件的元数据以 inode、slice、block 等信息组织,写入元数据引擎。
有了对正向过程的理解,我们反过来就能从对象存储和元数据引擎中恢复文件:对于一个给定的 JuiceFS 文件,
- 首先扫描元数据引擎,通过文件名、inode、slice 等等信息,拼凑出文件的大小、位置、权限等等信息;
- 然后根据 slice_id/block_id/block_size 拼凑出对象存储中的 object key;
- 依次去对象存储中根据这些 keys 读取数据拼到一起,得到的就是这个文件,然后写到本地、设置文件权限等等。
5.1.3 juicefs info 查看文件 chunk/slice/block 信息
JuiceFS 已经提供了一个命令行选项,能直接查看文件的 chunk/slice/block 信息,例如:
foo-dev/file2_5MB :
inode: 3
files: 1
dirs: 0
length: 5.00 MiB (5242880 Bytes)
size: 5.00 MiB (5242880 Bytes)
path: /file2_5MB
objects:
+------------+--------------------------------+---------+--------+---------+
| chunkIndex | objectName | size | offset | length |
+------------+--------------------------------+---------+--------+---------+
| 0 | foo-dev/chunks/0/0/3_0_4194304 | 4194304 | 0 | 4194304 |
| 0 | foo-dev/chunks/0/0/3_1_1048576 | 1048576 | 0 | 1048576 |
+------------+--------------------------------+---------+--------+---------+
和我们在 MinIO 中看到的一致。
5.2 为什么 JuiceFS 写入对象存储的文件,不能通过对象存储直接读取?
这里说的“不能读取”,是指不能直接读出原文件给到用户,而不是说不能读取 objects。
看过本文应该很清楚了,JuiceFS 写入对象存储的文件是按照 Chunk、Slice、Block 进行切分的, 只有数据内容,且保护重复数据,还没有文件信息元信息(文件名等)。
所以,以对象的存储的方式只能读这些 objects,是无法恢复出原文件给到用户的。
