














最近,留意到 MinIO 官方博客的一篇题为“在对象存储上实现 POSIX 访问接口是坏主意”的文章,作者以 S3FS-FUSE 为例分享了通过 POSIX 方式访问 MinIO 中的数据时碰到了性能方面的困难,性能远不如直接访问 MinIO。在对结果进行分析时,作者认为是 POSIX 本身存在的缺陷导致的性能问题。这个结论与我们既有经验有一定出入。
我们知道 POSIX 是一个有用而且广泛应用的标准,遵循它而开发的程序可以保证不同操作系统之间的兼容性和可移植性。各行各业中常用的业务系统和应用程序,大多遵循 POSIX 标准。
随着云计算、大数据、人工智能等技术的发展和数据存储量的攀升,本地化应用也逐渐产生对对象存储等弹性存储的需求,MinIO 等对象存储虽然提供了各种语言的 SDK,但许多传统应用很难甚至无法修改代码去适配对象存储的访问接口,这促使很多存储产品在对象存储的基础上去实现 POSIX 接口来满足这样的刚性需求。
业内在对象存储上实现 POSIX 接口的产品有很多,比如 Ceph、JuiceFS、Weka 等,它们都有广泛的用户群和大量的成功案例,在性能方面也都有不错的表现。
诚然,我们认可 POSIX 存在较大的复杂性,需要付出很大的努力才能解决好相关的问题,但这些问题并不是无法解决。抱着尊重和求证的态度,我搭建了测试环境,采用相同的样本和测试方法,进行了一番验证。
测试项目
为了得到更为全面的测试结果,我将 JuiceFS 引入了对比。
JuiceFS 是开源的云原生分布式文件系统,它采用对象存储作为数据存储层,采用独立的数据库存储元数据。提供了包括 POSIX API、S3 API、CSI Driver、HDFS API、WebDAV 在内的多种访问方式,具有独特的数据分块、缓存和并发读写机制。JuiceFS 是文件系统,与 s3fs-fuse 等只提供简单的从对象存储到 POSIX 协议转换的工具有着本质的不同。
通过将 JuiceFS 引入对比,可以更为客观地求证以对象存储为底层实现 POSIX 等协议的利弊。
在本文中,我会对 MinIO、JuiceFS 和 s3fs-fuse 进行以下两项测试:
-
10GB 大文件的写入测试
-
Pandas 小文件覆盖写测试
在底层存储方面,它们均使用部署在独立服务器上的 MinIO 实例;在测试样本方面,10GB 文件会采用那篇文章中使用的 csv 文件。
本文所提及的环境、软件、脚本、样本数据等均提供完整的代码和说明,确保读者可以复现环境和测试结果。
服务器及测试环境准备
两台配置相同的云服务器:
- System: Ubuntu 22.04 x64
- CPU: 8 cores
- RAM: 16GB
- SSD: 500GB
- Network: VPC
每台服务器的信息如下:
| Server | IP | For |
|---|---|---|
| Server A | 172.16.254.18 | MinIO Instance |
| Server B | 172.16.254.19 | Test Environment |
Server A 的准备工作
1.我在 Server A 上通过 Docker 部署了 MinIO,命令如下:
# 创建并进入专用目录
mkdir minio && cd minio
# 创建配置文件
mkdir config
touch config/minio
config/minio 文件中写入以下信息:
MINIO_ROOT_USER=admin
MINIO_ROOT_PASSWORD=abc123abc
MINIO_VOLUMES="/mnt/data"
2.创建 MinIO 容器:
bahs
sudo docker run -d --name minio \
-p 9000:9000 \
-p 9090:9090 \
-v /mnt/minio-data:/mnt/data \
-v ./config/minio:/etc/config.env \
-e "MINIO_CONFIG_ENV_FILE=/etc/config.env" \
--restart unless-stopped \
minio/minio server --console-address ":9090"
3.在 MinIO 的 Web Console 中预先创建三个 buckets:
| Bucket Name | 目的 |
|---|---|
| test-minio | 用于测试 MinIO |
| test-juicefs | 用于测试 JuiceFS |
| test-s3fs | 用于测试 s3fs-fuse |
Server B 的准备工作
下载 10GB 测试样本文件
curl -LO https://data.cityofnewyork.us/api/views/t29m-gskq/rows.csv?accessType=DOWNLOAD
2.安装 mc 客户端
mc 是 MinIO 项目开发的命令行文件管理器,可以在 Linux 命令行读写本地以及 S3 兼容的对象存储。mc 的 cp 命令可以实时显示数据拷贝的进度和速度,便于观察各项测试。
注:为了保持测试的公平性,三种方案均采用 mc 进行写测试。
# 下载 mc
wget https://dl.min.io/client/mc/release/linux-amd64/mc
# 检查版本
mc -v
mc version RELEASE.2023-09-20T15-22-31Z (commit-id=38b8665e9e8649f98e6162bdb5163172e6ecc187)
Runtime: go1.21.1 linux/amd64
# 安装 mc
sudo install mc /usr/bin
# 为 MinIO 添加别名
mc alias set my http://172.16.254.18:9000 admin abc123abc
3.安装 s3fs-fuse
sudo apt install s3fs
# 检查版本
s3fs --version
Amazon Simple Storage Service File System V1.93 (commit:unknown) with OpenSSL
# 设置对象存储访问密钥
echo admin:abc123abc > ~/.passwd-s3fs
# 修改密钥文件权限
chmod 600 ~/.passwd-s3fs
# 创建挂载目录
mkdir mnt-s3fs
# 挂载对象存储
s3fs test-s3fs:/ /root/mnt-s3fs -o url=http://172.16.254.18:9000 -o use_path_request_style
4.安装 JuiceFS
这里使用官方提供的脚本安装最新的 JuiceFS 社区版
# 一键安装脚本
curl -sSL https://d.juicefs.com/install | sh -
# 检查版本
juicefs version
juicefs version 1.1.0+2023-09-04.08c4ae6
JuiceFS 是文件系统,需要先创建才能使用。除了对象存储,还需要一个数据库作为元数据引擎,支持多种数据库,这里使用较常用的 Redis 作为元数据引擎。
注:我在这里将 Redis 安装在 Server A,通过 172.16.254.18:6379 进行访问,无密码,安装过程略,详情参考 Redis 官方文档。
# 创建文件系统
juicefs format --storage minio \
--bucket http://172.16.254.18:9000/test-juicefs \
--access-key admin \
--secret-key abc123abc \
--trash-days 0 \
redis://172.16.254.18/1 \
myjfs
5.另外,我会同时以较为常用的 POSIX 和 S3 API 两种方式访问 JuiceFS 并分别测试它们的性能。
# 创建挂载目录
mkdir ~/mnt-juicefs
# 以 POSIX 方式挂载文件系统
juicefs mount redis://172.16.254.18/1 /root/mnt-juicefs
# 以 S3 API 方式访问文件系统
export MINIO_ROOT_USER=admin
export MINIO_ROOT_PASSWORD=abc123abc
juicefs gateway redis://172.16.254.18/1 0.0.0.0:9000
# 在 mc 中为 JuiceFS S3 API 添加别名
mc alias set juicefs http://172.16.254.18:9000 admin abc123abc
注:JuiceFS Gateway 也可以部署在 Server A 或其他任何可联网服务器上,因为它开放的是基于网络访问的 S3 API。
测试及结果
测试一:10GB 文件写入测试
这项测试用来评估写大文件的性能,耗时越短性能越好。这里会使用 time 命令统计写入耗时,结果会包含三个指标:
-
real:从命令开始到结束的实际时间。它包括了所有的等待时间,例如等待 I/O 操作完成、等待进程切换、等待资源等。
-
user:在用户态(用户模式)执行的时间,也就是 CPU 用于执行用户代码的时间。它通常表示命令的计算工作量。
-
sys:在内核态(系统模式)执行的时间,也就是 CPU 用于执行内核代码的时间。它通常表示命令与系统调用(如文件 I/O、进程管理等)相关的工作量。
MinIO
# 执行拷贝测试
time mc cp ./2018_Yellow_Taxi_Trip_Data.csv my/test-minio/
MinIO 直写 10 GB 文件的测试结果:
real 0m27.651s
user 0m10.767s
sys 0m5.439s
s3fs-fuse
# 执行拷贝测试
time mc cp ./2018_Yellow_Taxi_Trip_Data.csv /root/mnt-s3fs/
s3fs-fuse 写 10 GB 文件的测试结果:
real 3m6.380s
user 0m0.012s
sys 0m5.459s
注:虽然写入耗时 3 分零 6 秒,但并没有出现那篇文章所谓写入失败的情况。
JuiceFS POSIX 和 S3 API
分别测试 JuiceFS 的 POSIX 和 S3 API 的大文件写性能:
# POSIX 写测试
time mc cp ./2018_Yellow_Taxi_Trip_Data.csv /root/mnt-juicefs/
# S3 API 写测试
time mc cp ./2018_Yellow_Taxi_Trip_Data.csv juicefs/myjfs/
JuiceFS POSIX 写 10 GB 文件的测试结果:
real 0m28.107s
user 0m0.292s
sys 0m6.930s
JuiceFS S3 API 写 10GB 文件的测试结果:
real 0m28.091s
user 0m13.643s
sys 0m4.142s
大文件写结果总结
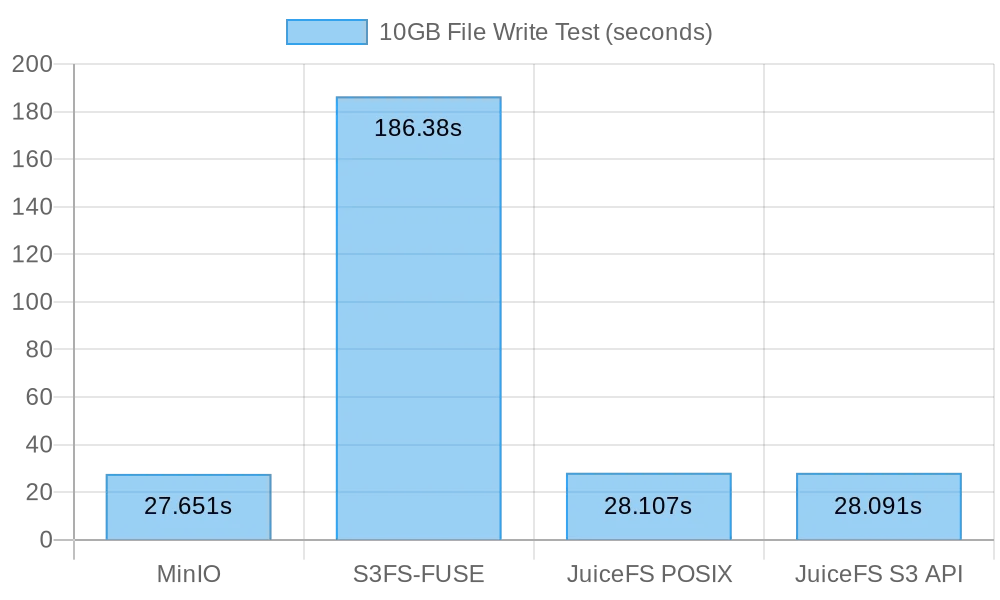
从测试结果来看,直接写 MinIO 和 JuiceFS 的性能相当,均可在 30s 内完成,而 s3fs-fuse 写入 10GB 文件耗时 3 分钟以上,平均比前两者慢了 6 倍左右。
在写入大文件时,mc 会使用 Multipart API 来将文件分块上传到 S3 接口,而只能单线程写入到 POSIX。JuiceFS 在大文件的顺序写也会自动将文件分块并并发写入到 MinIO 中,因此与直接写 MinIO 性能相当。而 S3FS 默认先是单线程写入到缓存盘,然后再分块写入到 MinIO 中,这会耗费更多写入时间。
按照写 10GB 文件耗时 30 秒计算,平均速度为 333 MB/s,这是云服务器 SSD 的带宽限制,测试结果表明,MinIO 和 JuiceFS 都能打满本地 SSD 的带宽,它们的性能会随着服务器云盘和网络带宽的提升而提升。
测试二:Pandas 小文件覆盖写
这项测试主要用来评估对象存储在小文件覆盖写方面的性能,各个软件的测试脚本略有不同,你可以在这里找到所有脚本代码。
# 获取测试脚本
curl -LO https://gist.githubusercontent.com/yuhr123/7acb7e6bb42fb0ff12f3ba64d2cdd7da/raw/30c748e20b56dec642a58f9cccd7ea6e213dab3c/pandas-minio.py
# 执行测试
python3 pandas-minio.py
测试结果:
Execution time: 0.83 seconds
s3fs-fuse
# 获取测试脚本
curl -LO gist.githubusercontent.com/yuhr123/7acb7e6bb42fb0ff12f3ba64d2cdd7da/raw/30c748e20b56dec642a58f9cccd7ea6e213dab3c/pandas-s3fs.py
# 执行测试
python3 pandas-s3fs.py
测试结果:
Execution time: 0.78 seconds
JuiceFS POSIX
# 获取测试脚本
curl -LO gist.githubusercontent.com/yuhr123/7acb7e6bb42fb0ff12f3ba64d2cdd7da/raw/30c748e20b56dec642a58f9cccd7ea6e213dab3c/pandas-juicefs-posix.py
# 执行测试
python3 pandas-juicefs-posix.py
测试结果:
Execution time: 0.43 seconds
JuiceFS S3 API
# 获取测试脚本
curl -LO https://gist.githubusercontent.com/yuhr123/7acb7e6bb42fb0ff12f3ba64d2cdd7da/raw/30c748e20b56dec642a58f9cccd7ea6e213dab3c/pandas-juicefs-s3api.py
# 执行测试
python3 pandas-juicefs-s3api.py
测试结果:
Execution time: 0.86 seconds
Pandas 小文件覆盖写结果总结
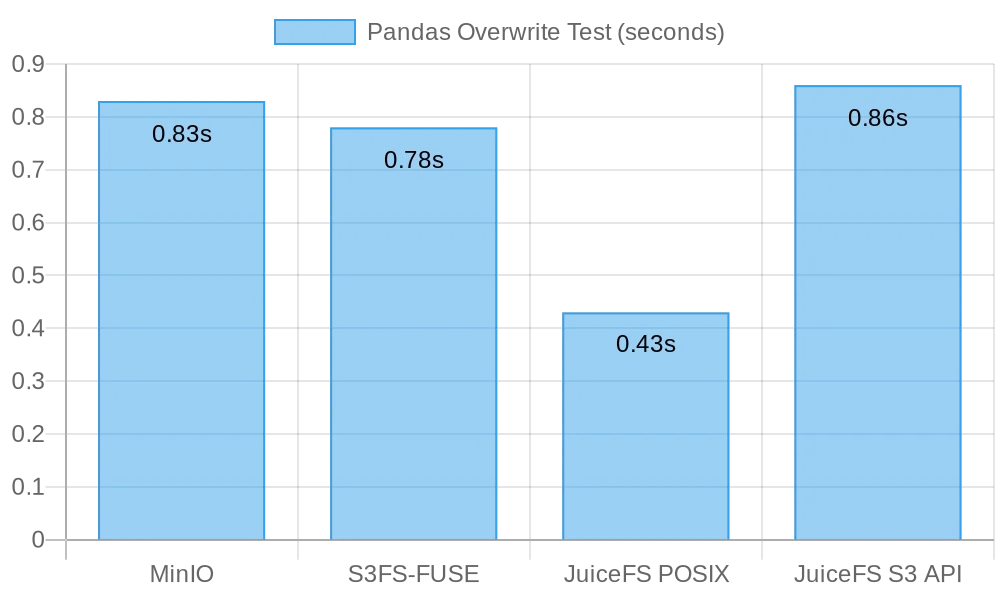
在这项测试中,JuiceFS FUSE-POSIX 的速度最快,几乎是其他方案的 2 倍。MinIO、s3fs-fuse、JuiceFS S3 Gateway 的速度相当。从小文件覆盖写的角度来看,POSIX 接口效率更高,比对象存储接口有更好的性能表现。
测试结果
| MinIO | S3FS-FUSE | JuiceFS (FUSE) | JuiceFS (s3 gateway) | |
|---|---|---|---|---|
| 10GB 大文件写 | 0m27.651s | 3m6.380s | 0m28.107s | 0m28.091s |
| Pandas 小文件覆盖写 | 0.83s | 0.78s | 0.46s | 0.96s |
分析和总结
问题一:S3FS 为什么这么慢?
从测试数据可以清楚地看到,写入同样的 10GB 大文件,S3FS 需要 3 分钟,而 MinIO 和 JuiceFS 只需要 30 秒左右,速度相差近 6 倍,这主要是由于不同的技术实现导致的。
s3fs-fuse 在写入文件时,会优先写入本地临时文件,然后以分片方式上传对象存储。如果本地磁盘空间不足,则会以同步的方式上传。因为它需要在本地磁盘和 S3 存储之间进行数据复制,在处理大文件或大量文件时就会导致性能下降。
再者,S3FS 依赖底层对象存储的元数据管理能力,当需要读写大量文件时,频繁地与对象存储交互获取元数据也会对性能产生很大的影响。
简单来说,写入 S3FS 的文件体积和总量越大,相应的性能开销也会成比例地放大。
问题二:JuiceFS 为什么更快?
同样是通过 FUSE 进行读写,为什么 JuiceFS 可以与 MinIO 一样打满磁盘带宽,而没有像 S3FS 那样出现性能问题呢?这同样也是由技术架构决定的。
在写入文件时,数据虽然也经由 FUSE 层处理,但 JuiceFS 通过高并发、缓存、数据分块等技术降低了与底层对象存储之间的通信开销,一次性处理更多文件的读写请求,从而减少了等待时间和传输延迟。
另外,JuiceFS 采用独立的数据库(在本文中使用了 Redis)管理元数据,当文件量特别大时,独立的元数据引擎能有效释放压力,可以更快地定位文件位置。
结论
以上数据表明,把对象存储作为底层,在其上实现 POSIX 接口不一定会损失性能,不论是写大文件还是小文件,JuiceFS 的性能与直接写 MinIO 是相当的,并没有因为访问 POSIX 而损失底层对象存储的性能。而在 Pandas 表格覆盖写方面,JuiceFS FUSE-POSIX 的性能不降反升,超过 MinIO 近两倍。
从测试结果不难发现,某些软件(例如 s3fs-fuse)将 S3 API 与 POSIX 接口相互转换可能会导致对象存储的性能损失,但它不失为一款还算方便的临时访问 S3 的小工具,但要想长期稳定的高性能使用,需要通过更为审慎的调研和验证来选择其他更适的方案。
简单的非结构化文件归档存储,直接使用 MinIO 或云上对象存储是不错的选择。而对于需要进行大规模数据存储和处理,如 AI 模型训练、大数据分析和 Kubernetes 数据持久化等频繁读写的场景,JuiceFS 的独立元数据管理、并发读写和缓存机制会带来更好的性能表现,是更值得尝试的高性能文件系统解决方案。
Author

