














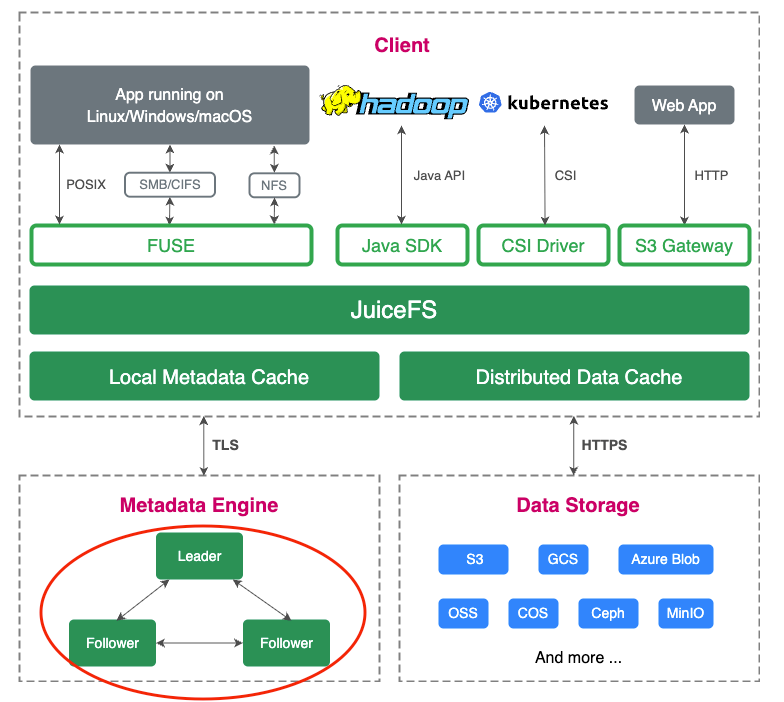
JuiceFS 企业版 5.3 近日发布,单文件系统支持超 5,000 亿文件,实现里程碑式突破。此次升级针对元数据多分区架构进行了多项关键优化,并首次引入 RDMA 技术,以提升分布式缓存效率;此外,5.3 版本还增强了可写镜像,为跨桶导入的对象提供数据缓存等多项功能,旨在支持高性能要求及多云应用场景。
JuiceFS 企业版专为高性能场景设计。自 2019 年起开始应用于机器学习领域,现已成为 AI 行业核心基础设施之一。商业客户涵盖大模型公司:MiniMax、智谱 AI、阶跃星辰;AI 基础设施及应用如 Fal.ai、HeyGen 等;自动驾驶领域的 Momenta、地平线等,以及众多应用 AI 技术的各行业领先科技企业。
01 单文件系统支持超 5,000 亿文件
多分区架构是 JuiceFS 应对千亿文件规模的关键技术之一,保证了系统的高扩展性和高并发处理能力。为了继续满足如自动驾驶场景业务增长的需求,5.3 版本对多分区架构进行了深入优化,将分区数量限制提高到 1,024 个,单文件系统能够存储和访问至少 5,000 亿个文件。(每个分区可存储 5 亿个文件,最大支持 20 亿)。
这一突破对系统性能、数据一致性、稳定性要求提出了几何级的难度,背后是一系列繁杂的底层优化与研发工作。
关键优化 1 - 分区间热点均衡:自动监测和热点迁移;提供手动运维工具
在分布式系统中,热点问题是常见的挑战,特别是当数据被分布到多个分区时,某些分区的负载可能比其他分区更高,这种不均衡会引发热点问题,影响系统的性能。
当分区数量达到数百时,热点问题变得更加普遍。尤其是在数据集较小、涉及的文件数量较多的情况下,读写热点问题会加剧,进一步增加延迟波动。
我们引入了自动化的热点迁移机制,将访问频繁的文件迁移到其他分区,从而分担负载并降低特定分区的压力。然而在实际环境中,我们发现仅依赖自动迁移并不能完全解决所有问题。特别是在某些特殊场景或极端情况下,自动迁移工具可能无法及时应对。因此,我们在自动监测和迁移的基础上,增加了手动运维工具,允许运维人员在遇到复杂场景时介入,进行人工分析并实施优化方案。
关键优化 2 - 大规模迁移:提升迁移速度,少量多次并发迁移
面对热点过高的分区,早期的迁移操作比较简单,但随着系统规模扩大,迁移效率逐渐降低。为此,我们引入了“少量多次并发迁移”的策略,将高访问量的目录分解成多个小块,并行迁移到多个负载较低的分区,从而迅速分散热点,恢复业务的正常访问体验。
关键优化 3 - 强化可靠性自检:自动修复与清理迁移中间态文件
在大规模集群中,分布式事务的失败概率显著上升,特别是在大量迁移过程中。为应对这一问题,我们增强了可靠性检测机制,增加了后台周期性的检查功能,定期扫描跨分区文件的状态,特别关注中间状态问题,并自动进行修复和清理。
此前,系统曾遇到过中间状态数据残留的问题,虽然短期内未影响系统运行,但随着时间推移,这些残留数据可能导致错误。通过增强的自检机制,我们确保了后台能够定期扫描并及时处理中间状态问题,从而提升了系统的稳定性和可靠性。
除了上述三项关键优化外,我们还在控制台进行了多项改进,以更好地适应更多分区的管理需求。我们优化了并发处理、运维操作和查询展示,提升了整体性能和用户体验。特别是,在 UI 设计方面,我们做了优化,以便更好地展示大规模分区环境下的系统状态。
千亿文件性能压测:稳定性与资源利用良好
我们在谷歌云上使用自定义的 mdtest 测试工具进行了大规模测试,部署了 60 个节点,每个节点的内存超过 1 TB。在软件配置方面,我们将分区数增加至 1,024 个。部署方式与之前类似,为了降低内存消耗,我们选择仅部署一个服务进程,另两个作为冷备。
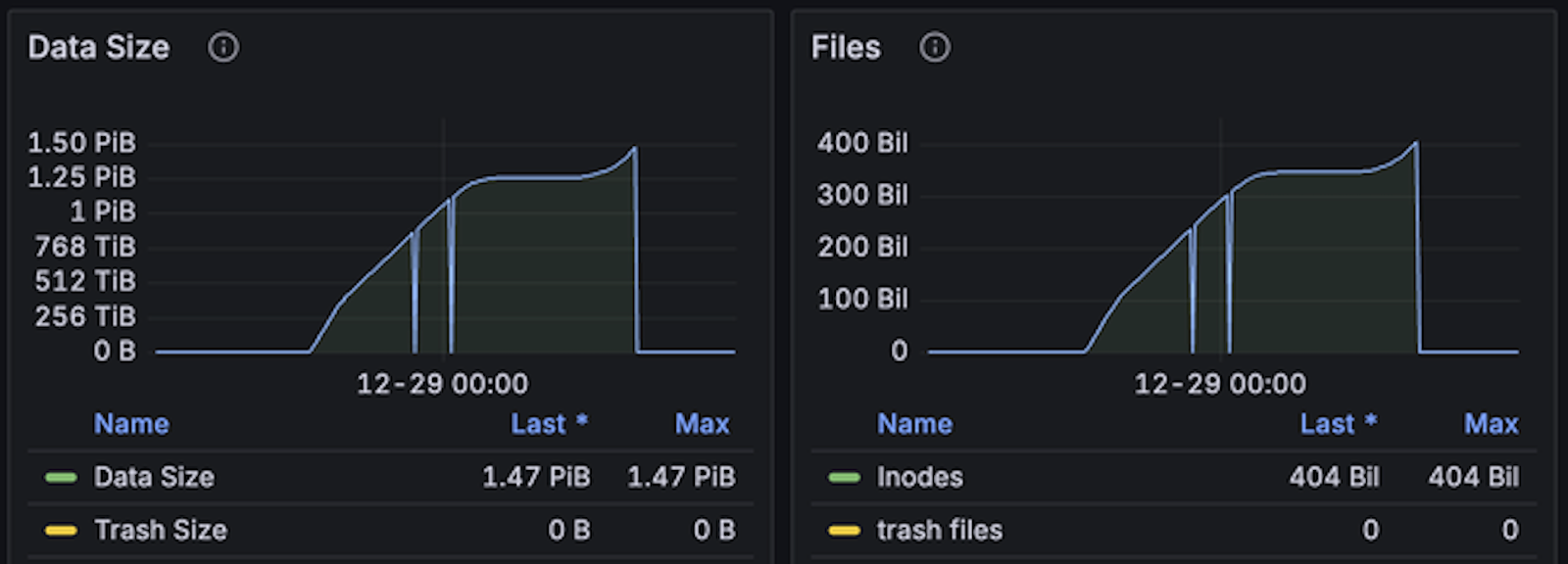
- 测试持续时间:大约 20 小时
- 写入的文件总数:约 4,000 亿个文件
- 每秒写入速度:500 万个文件
- 内存占用:约 35% 到 40%
- 硬盘使用: 40% 到 50%,主要用于元数据的持久化,使用情况良好
根据我们的经验,如果采用一个服务进程、一个热备进程和一个冷备进程的配置,内存占用会增加 20% 到 30%。
由于云端资源有限,本次测试只写到 4,000 亿文件。在压测过程中,系统表现稳定,且硬件资源尚有富余。后续,我们会继续尝试更大规模的测试。
02 首次支持 RDMA:带宽上限提升,CPU 占用降低
在此次新版本中首次支持了 RDMA(Remote Direct Memory Access)技术,它的基本原理架构如下图所示。RDMA 通过允许直接访问远程节点的内存,绕过操作系统的网络协议栈,显著提高了数据传输效率。
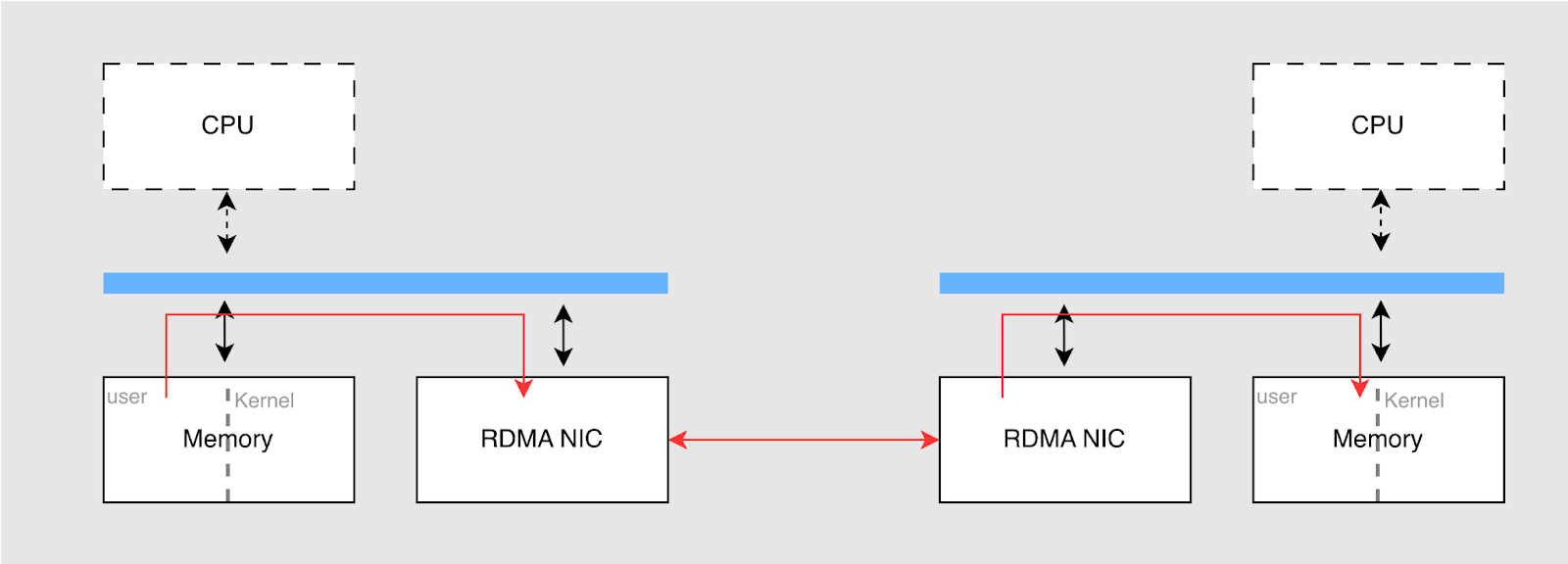
RDMA 的主要优点包括:
- 低延迟:通过直接从内存到内存的传输,绕过操作系统的网络协议层,减少 CPU 的中断和上下文切换,从而降低延迟。
- 高吞吐量:RDMA 通过硬件直接传输数据,能够更好地发挥网卡(NIC)的带宽。
- 减少 CPU 占用:在 RDMA 中,数据的拷贝几乎全部由网卡完成,CPU 仅用于处理控制消息。这样,网卡负责硬件传输,释放了 CPU 的资源。
在 JuiceFS 中,客户端与元数据服务之间的网络请求消息都较小,现有的 TCP 配置已能满足需求。而在分布式缓存中,客户端与缓存节点之间传输的是文件数据,使用 RDMA 可以有效提升传输效率,降低 CPU 消耗。
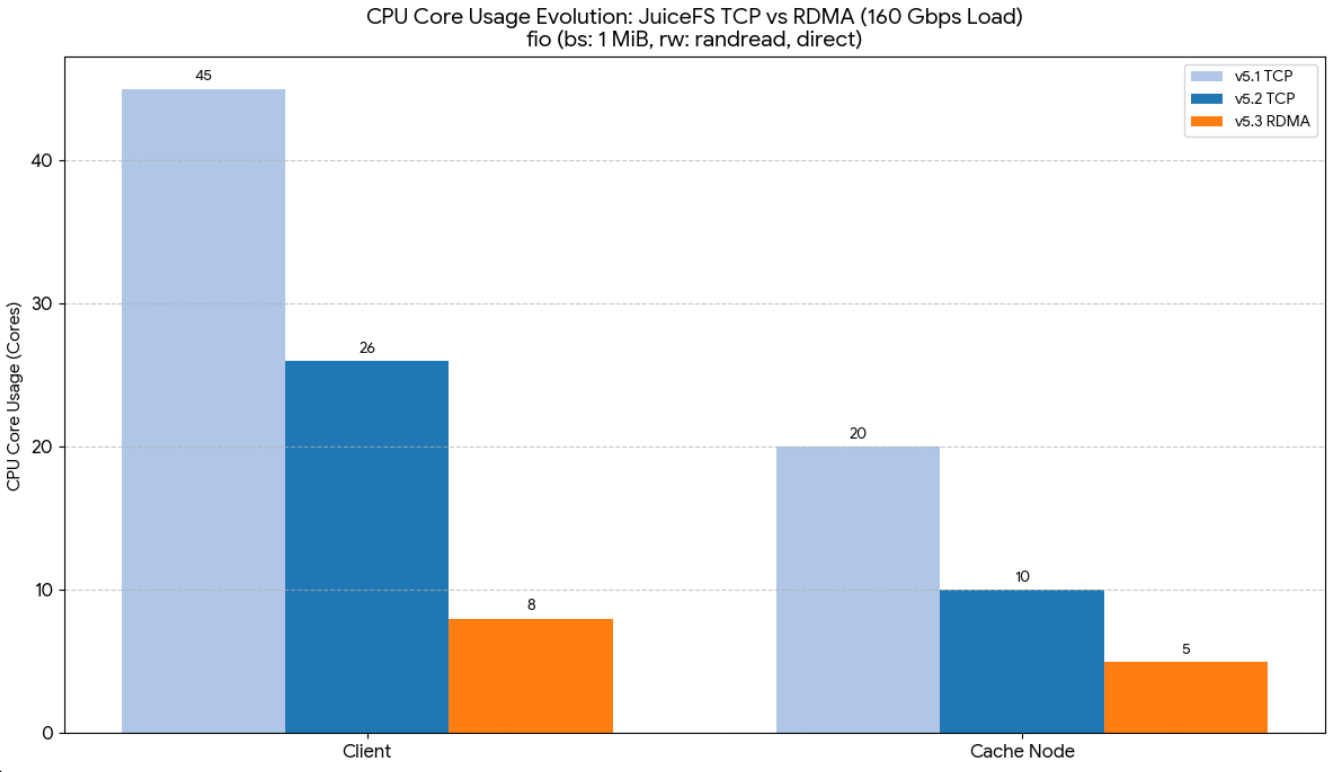
我们使用了 160 Gbps 网卡进行 1MB 随机读测试,比较了 5.1、 5.2(使用 TCP 网络) 和 5.3 版本(RDMA),并观察了 CPU 占用情况。测试表明,RDMA 有效降低了 CPU 占用。在 5.2 版本中,CPU 占用了近 50%;而在 5.3 版本中,通过 RDMA 优化,CPU 占用降至约 1/3。客户端和缓存节点的 CPU 占用分别降至 8 核和 5 核,带宽达到了 20 GiB/s。
在以往的测试中,我们发现 TCP 在 200G 网卡下虽然稳定运行,但要完全拉满带宽仍有困难,通常只能达到 85-90% 的带宽利用率。对于需要更高带宽(如 400G 网卡)的客户,TCP 无法满足需求,而 RDMA 能够更容易地发挥硬件带宽上限,提供更优的传输效率。
如果用户的硬件支持 RDMA 且存在高带宽需求(如网卡大于 100G),同时希望降低 CPU 占用,那么 RDMA 是值得尝试的技术。目前,我们的 RDMA 功能处于公测阶段,尚未在生产环境中广泛部署。
03 可写镜像增强
最初,镜像集群主要用于企业产品中的只读镜像。随着用户提出在镜像中写入临时文件(如训练数据)等需求,我们为此提供了可写镜像功能。
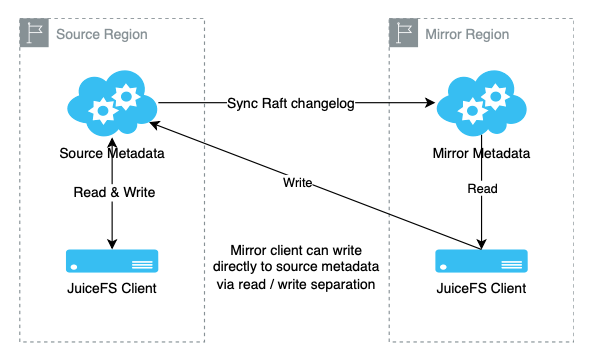
镜像客户端在实现时采用了读写分离机制。客户端在读取数据时优先从镜像集群获取,以降低延迟;而写入数据时,仍然需要写入源集群,以确保数据一致性。通过元数据版本号的记录与对比,我们确保了镜像客户端和源集群客户端看到的数据保持强一致性。
为了提升可用性,我们在 5.3 版本引入了回退机制,即当镜像不可用时,客户端的读请求能自动回退到源集群,从而保证业务连续性,避免镜像集群故障导致的业务中断。我们还优化了多镜像环境的部署。原先,镜像端需要部署两个热备节点以确保高可用性。现在,通过改进的回退功能,部署一个镜像节点也能实现类似的效果,确保业务连续性并降低成本,尤其适用于需要多个镜像的用户。
通过这一改进,我们不仅降低了硬件成本,还在高可用性和低成本之间找到了平衡。对于那些在多个地点部署镜像的用户,减少元数据副本的同时进一步降低了总体成本。
04 简化运维管理,提升灵活性:为导入对象提供跨桶数据缓存
在 JuiceFS 中,用户可以使用 import 命令将对象存储中的现有文件导入并统一管理。这对于已经存储大量数据(如几十 PB)的用户来说十分便捷。但在之前版本中,这一功能仅支持为同一数据桶中的对象提供缓存,意味着导入的对象必须与现有文件系统数据处于同一个桶内。这一限制在实际使用中带来了一定局限性。
在 5.3 版本中,我们对该功能进行了改进。现在,用户可以为任何导入的对象提供缓存能力,无论这些对象是否来自同一数据桶。这样,用户可以更加灵活地管理不同数据桶中的对象,避免了对数据桶的严格限制,从而提升了数据管理的自由度。
此外,以前如果用户将数据分布在多个桶中,想要为这些桶中的数据提供缓存能力,需要为每个桶新建一个文件系统。而在 5.3 版本中,用户只需创建一个文件系统(volume),便可统一管理多个桶的数据,并为所有桶提供缓存能力。
05 其他重要优化
Trace 功能
我们新增了 trace 功能,这是 Go 语言本身提供的一个特性。通过这个功能,资深用户可以进行追踪和性能分析,获得更多信息,帮助我们快速定位问题。
回收站恢复
在之前的版本中,特别是在多分区的情况下,有时回收站记录的路径不完整,导致恢复时出现异常,未能恢复到预期位置。为了解决这个问题,在 5.3 版本中,在删除文件时,我们会记录文件的原始路径,确保恢复时能够提供更可靠的恢复能力。
Python SDK 改进
在前几个版本中,我们发布了 Python SDK,它提供了基础的读写功能,方便 Python 用户与我们的系统对接。在 5.3 版本中,我们不仅加强了基础读写功能,还增加了对运维子命令的支持。例如,用户可以直接通过 SDK 调用 juicefs info 或 warmup 等命令,而不需要依赖外部系统命令。这不仅简化了编码工作,并且避免了频繁调用外部命令时可能产生的性能瓶颈。
Windows 客户端
我们在之前版本中推出了 Windows 客户端 Beta 版本,并已获得不少用户反馈。经过改进,当前版本在挂载的可靠性、性能以及与 Linux 系统的兼容性上都有了显著提升。未来,我们计划进一步完善 Windows 客户端,为依赖 Windows 的用户提供更接近 Linux 的体验。
06 小结
相较于昂贵的专用硬件,JuiceFS 通过灵活地利用云上或客户现有的存储资源,帮助用户在应对数据增长时平衡性能与成本。在 5.3 版本中,通过优化元数据分区架构,单文件系统可支持超过 5,000 亿个文件。首次引入的 RDMA 技术显著提升了分布式缓存带宽和数据访问效率,减少了 CPU 占用,进一步优化了系统性能。此外,我们还优化了可写镜像、缓存等多项功能,提升了大规模集群的性能和运维效率,优化用户体验。
云服务用户现已可以直接在线体验 JuiceFS 企业版 5.3,私有部署用户可通过官方渠道获得升级支持。我们将继续专注于高性能存储解决方案,和企业一起应对数据量的持续增长所带来的挑战。
如果你在存储架构设计、成本控制或性能优化中遇到过问题,或有相关实践心得,欢迎在评论区留言。
