














JuiceFS 是一款针对云原生环境设计的共享文件系统,支持所有类型数据的管理、分析、归档和备份,被广泛应用于大数据、人工智能、日志收集等场景。JuiceFS 支持多端数据共享,可以直接作为 Milvus 底层的共享存储。本文详细介绍了如何基于 JuiceFS 共享存储搭建 Milvus 分布式集群。
JuiceFS 介绍
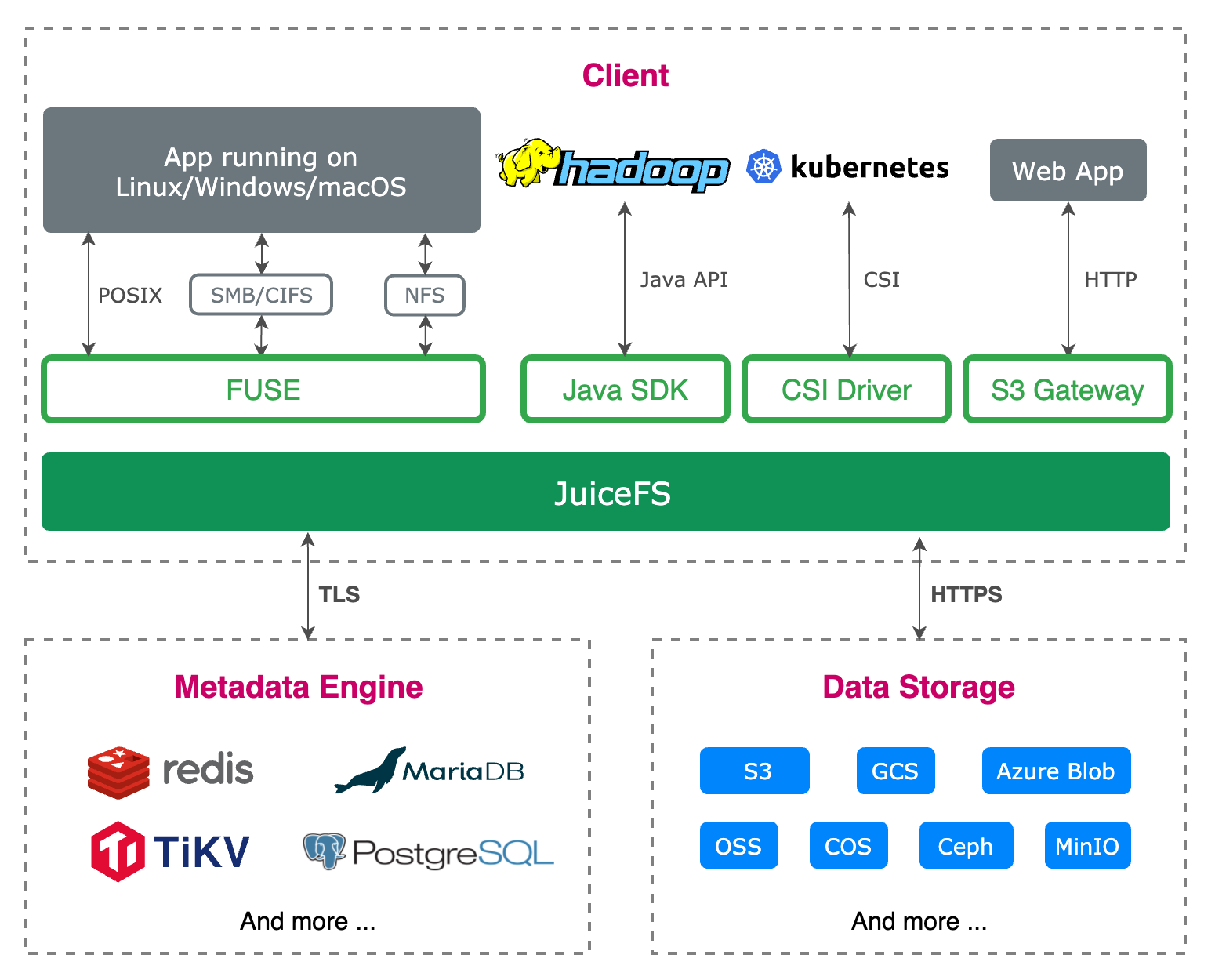
JuiceFS 是一款基于云原生环境设计的高性能开源 POSIX 文件系统。在数据和所对应的元数据分别持久化至对象存储和 Redis 后,JuiceFS 将作为无状态的中间件,使得不同应用能够以标准的文件系统接口无缝对接,从而实现数据共享。JuiceFS 依靠 Redis 来存储文件的元数据。Redis 是一个开源的内存数据库,可以保障元数据操作的原子性和高性能。所有文件的数据通过客户端存储到对象存储中,架构图如下:
Milvus 介绍
Milvus 是一款开源的向量相似度搜索引擎,可与多种 AI 模型相结合。Milvus 提供向量化的非结构数据检索服务,目前广泛应用于图像处理、计算机视觉、自然语言处理、语音识别、推荐系统以及新药研发等领域。
Milvus 适用于多种场景,与深度学习相融合的架构如下图所示:
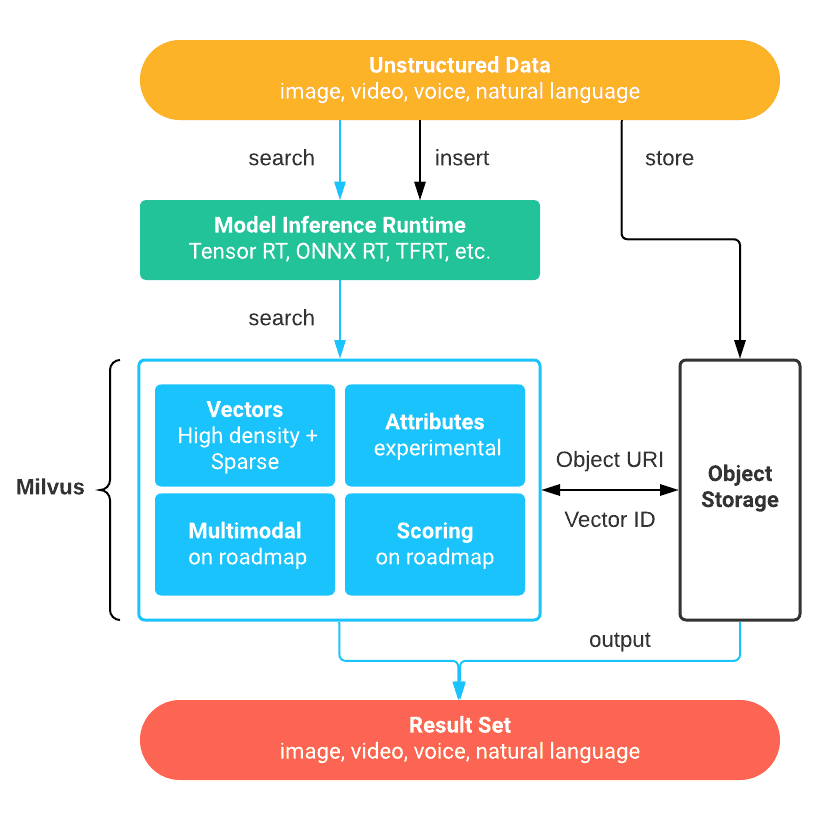
采用 Milvus 的数据处理流程包括以下几个步骤:
- 与深度学习模型相结合,将非结构化数据转化为特征向量;
- 将特征向量存储到 Milvus 并建立索引;
- 返回向量相似性搜索结果。
基本架构
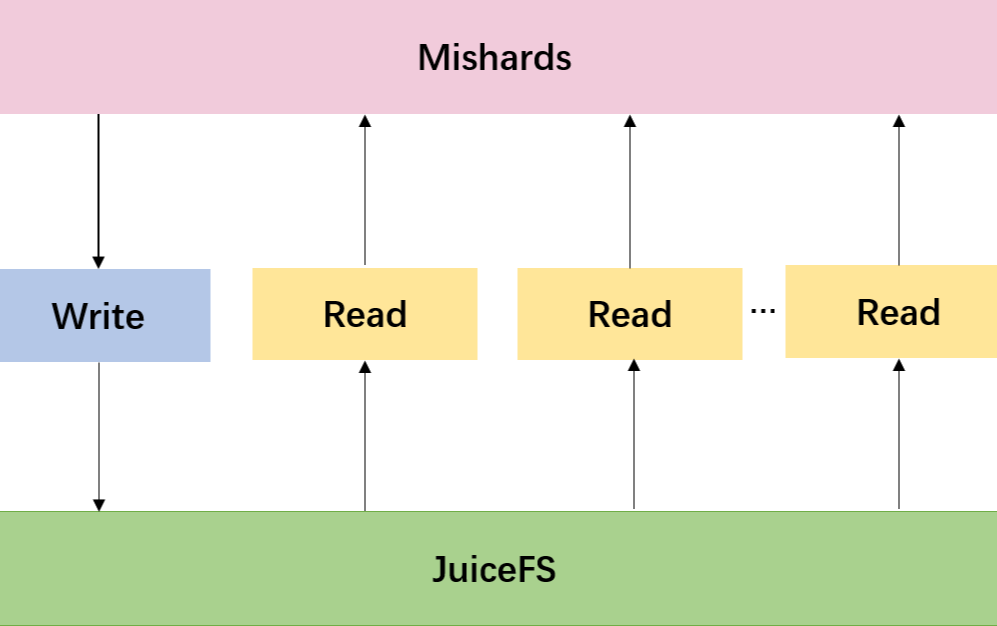
结合 JuiceFS 搭建 Milvus 分布式集群的架构如下图所示,其中 Mishards 负责将上游请求拆分并路由到内部各细分子服务。插入数据时,Mishards 会将请求分配到 Milvus 写节点上,通过写节点将插入的数据存储到 JuiceFS 中;读取数据时,Mishards 就会通过 Milvus 读节点从 JuiceFS 中读取数据到内存中进行处理,最后将处理结果进行汇总,返回给上游。
搭建步骤
1. 安装并启动 MySQL 服务
MySQL 服务只需要在集群中任意一台设备上启动即可,具体参考 Milvus 文档:使用 MySQL 管理元数据。
2. 安装 JuiceFS
本文中选择的是 JuiceFS 的预编译版本,用户可以直接下载,详细安装过程参考 JuiceFS 安装教程。JuiceFS 需要先安装 Redis,如果你使用的是公有云,建议直接使用公有云托管的 Redis 服务。JuiceFS 也需要配置对象存储(详细步骤参考文章),文中使用的是 Azure Blob Storage。JuiceFS 现已支持所有主流的对象存储,用户可自行选择适合的对象存储服务。
配置好 Redis 服务及对象存储之后,需要格式化一个新的文件系统,然后将 JuiceFS 挂载到本地目录中:
$ export AZURE_STORAGE_CONNECTION_STRING="DefaultEndpointsProtocol=https;AccountName=XXX;AccountKey=XXX;EndpointSuffix=core.windows.net"
$ ./juicefs format \
--storage wasb \
--bucket https://<container> \
... \
localhost test # 格式化
$ ./juicefs mount -d localhost ~/jfs # 挂载注:如果 Redis 服务不在本地,需要将 localhost 替换成如下完整地址:redis://user:password@host:6379/1。
如下图所示,成功安装 JuiceFS 后,即可得到共享存储的路径 /root/jfs。

3. 启动 Milvus
集群中的每一台设备均需要安装 Milvus,并分别为不同设备上的 Milvus 配置读写权限。其中仅可将一台设备中的 Milvus 配置为写入,其余均为只读。首先,在 Milvus 的系统配置文件 server_config.yaml 中,配置 cluster 区域和 general 区域的参数。
cluster 区域
| 参数 | 说明 | 参数设置 |
|---|---|---|
enable | 是否开启集群模式 | true |
role | 节点的运行模式 | rw (ro) |
general 区域
| 参数 | 说明 | 参数设置 |
|---|---|---|
meta_uri | 元数据存储的 URI。使用 MySQL(Milvus 分布式版本)作为元数据的存储后端。URI 格式为 mysql://username:password@host:port/database。 | mysql://root:milvusroot@host:3306/milvus |
Milvus 安装过程中,/root/jfs/milvus/db 映射是已配置完成的 JuiceFS 共享存储路径。
sudo docker run -d --name milvus_gpu_1.0.0 --gpus all \
-p 19530:19530 \
-p 19121:19121 \
-v /root/jfs/milvus/db:/var/lib/milvus/db \ # /root/jfs/milvus/db 为共享存储的路径
-v /home/$USER/milvus/conf:/var/lib/milvus/conf \
-v /home/$USER/milvus/logs:/var/lib/milvus/logs \
-v /home/$USER/milvus/wal:/var/lib/milvus/wal \
milvusdb/milvus:1.0.0-gpu-d030521-1ea92e安装完成后,启动 Milvus,并检验 Milvus 是否启动成功。
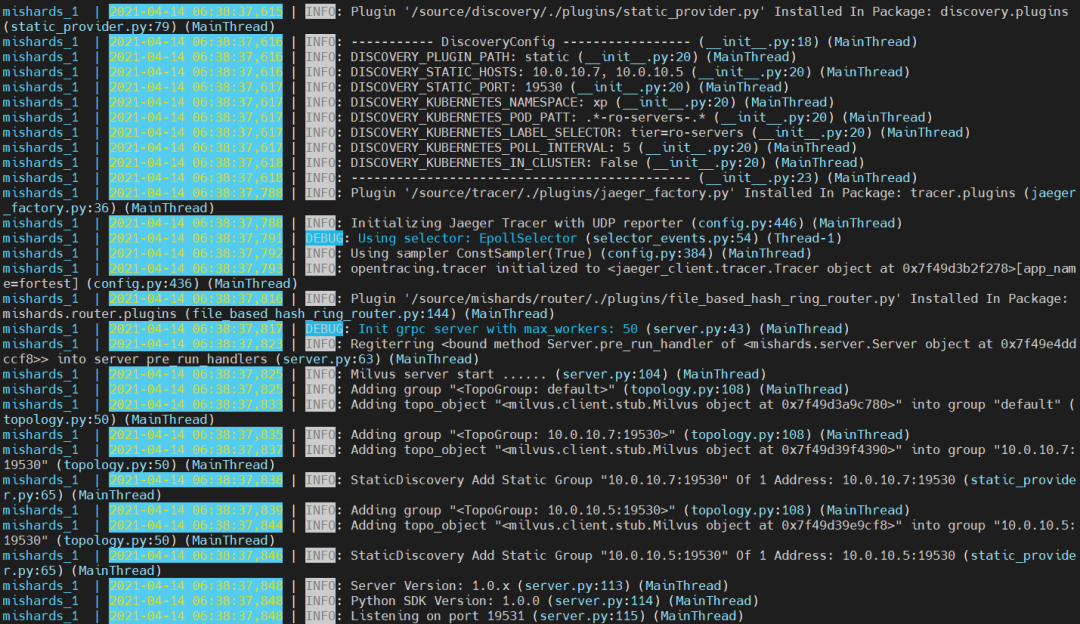
最后,参考 GitHub 中教程,在集群中任意一台设备上启动 Mishards 服务。下图表示 Mishards 启动成功。
共享存储方案通常使用 Network-attached Storage(NAS)系统实现,常用的协议包括 Network File System(NFS)、Server Message Block(SMB) 等。公有云上一般也会提供兼容这些协议的托管存储服务,例如 Amazon Elastic File System(EFS)。
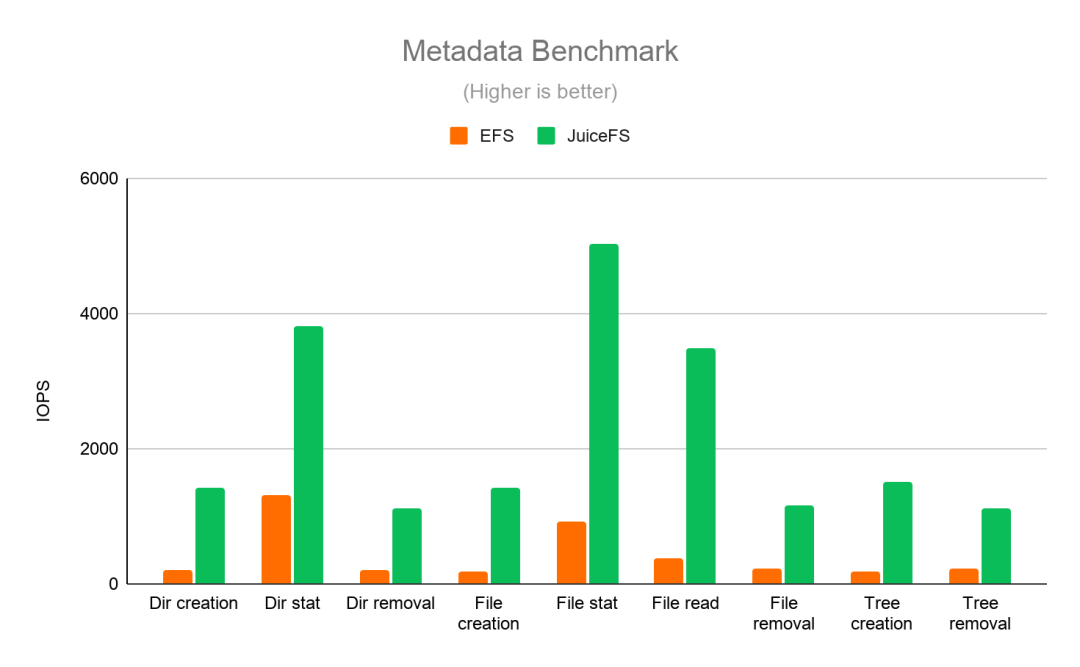
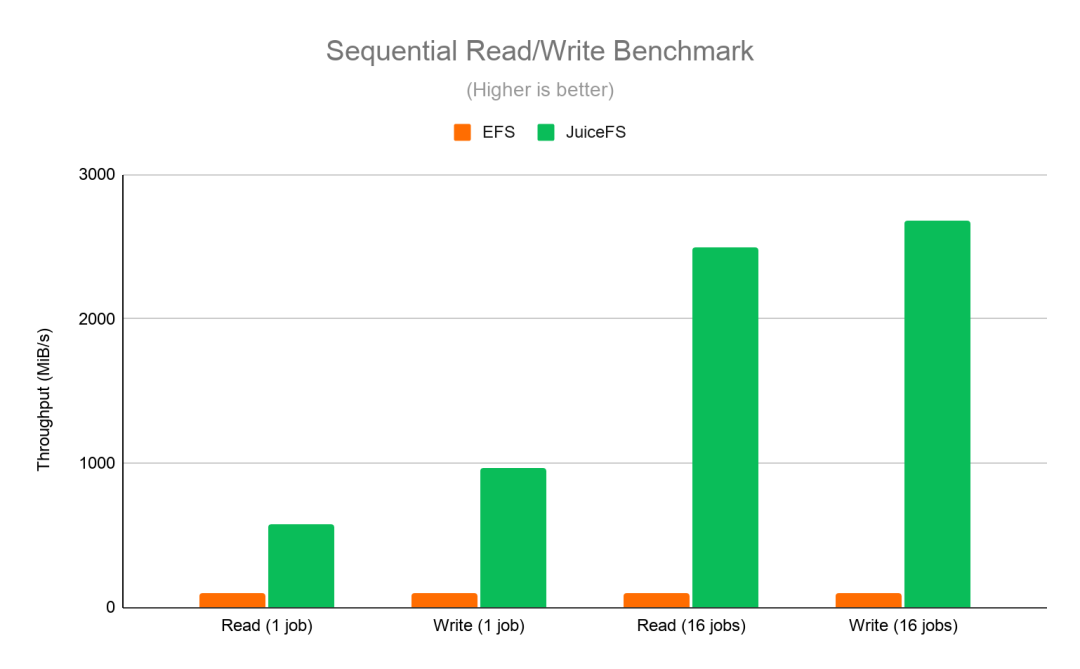
区别于传统的 NAS 系统,JuiceFS 基于 Filesystem in Userspace(FUSE)实现,数据读写都直接发生在应用端,因此能进一步降低访问延迟。此外,JuiceFS 还提供一些 NAS 系统不具备的特性,如数据压缩、数据缓存等,性能也有大幅提升。在与 EFS 的对比测试中,JuiceFS 表现出了较大优势。如图 1 所示,在原数据操作性能上,JuiceFS 的表现明显优于 EFS,差距最大时 JuiceFS 的性能可优于 EFS 十倍之多。图 2 记录了在顺序写与顺序读测试中 JuiceFS 与 EFS 的 I/O 吞吐性能数据:无论在单任务或是多任务的测试中,JuiceFS 相比 EFS 都有较大的性能提升。
除了 JuiceFS 与 EFS 的对比测试,我们还测试了结合 JuiceFS 搭建的 Milvus 分布式集群的第一次检索时间。第一次检索时间指将新导入的数据从磁盘加载到内存的耗时。将 100 万条 128 维的数据以每 10 万条为单位分批插入,每间隔 1 至 8 秒进行检索,测试结果显示平均检索时间为 0.032 秒,表明从磁盘加载到内存的耗时较少。上述测试证明了 JuiceFS 作为共享存储设备的稳定性,基于 JuiceFS 搭建 Milvus 分布式集群能兼顾高性能和弹性存储容量。
作者介绍
- 贾晶晶,Zilliz 数据工程师,毕业于西安交通大学电信学部。加入到 Zilliz 之后的主要工作内容为数据预处理、AI 模型部署以及与 Milvus 相关的技术调研。
- 高昌健,Juicedata 解决方案架构师,十年互联网行业从业经历,曾在知乎、即刻、小红书多个团队担任架构师职位,专注于分布式系统、大数据、AI 领域的技术研究。
