














AI 模型的训练与推理对存储系统提出了极为严苛的要求,特别是在高吞吐、高并发以及对海量小文件的高效处理方面,已成为三大主要挑战。尽管基于 Lustre 或 GPFS 的并行文件系统具备出色的性能,但其成本高昂、吞吐能力与容量强耦合,可能导致硬件资源的浪费。随着数据规模的急剧增长,这些问题变得更加突出。
我们将通过一个客户从并行文件系统架构迁移至 JuiceFS 的案例,同时利用其闲置资源打造 70GB/s 吞吐,360 TB 缓存池的案例,深入探讨 JuiceFS 如何实现高效的数据处理、低成本存储与灵活的扩展能力。
01 早期存储架构:资源利用不足与高昂的成本
该客户是一家从事大语言模型训练的企业,数据存储在 AWS S3 上,最初通过 AWS FSx for Lustre 提供的并行文件系统访问数据,确保计算资源能够高效地访问存储在 S3 中的数据。FSx 和类似的并行文件系统,如阿里云 CPFS、火山引擎 vePFS 通常提供协议转换、缓存加速以及文件生命周期管理这些功能。
为了支撑大规模的数据处理和计算,客户采购了多台裸金属服务器,每台配备了大量的本地 NVMe 磁盘。然而,这些磁盘长时间处于闲置状态,造成了资源浪费。
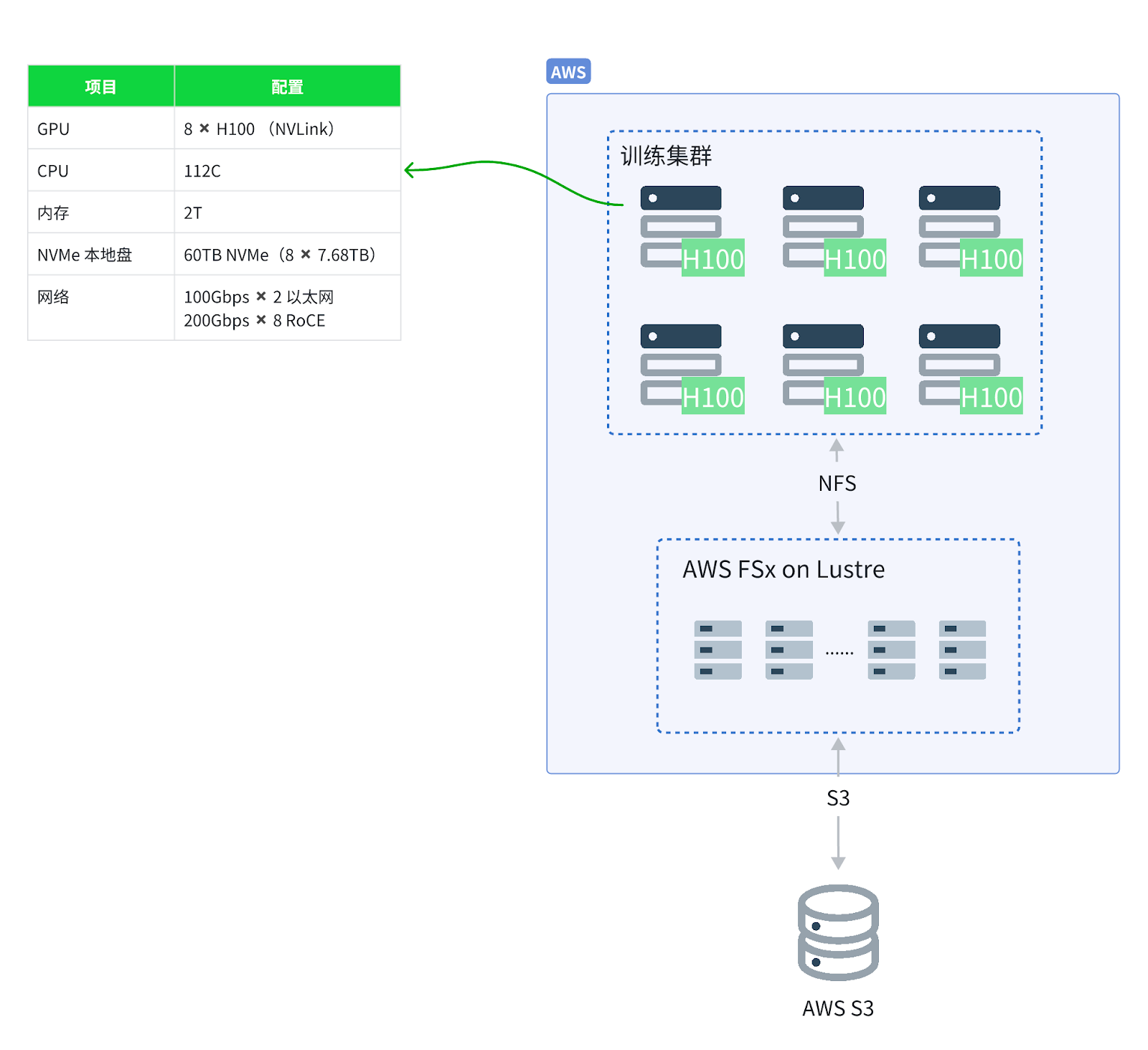
尽管并行文件系统具有优异的性能,但其成本较高,并且吞吐性能与存储容量紧密相关。如果要获得更高的吞吐,必须购买更大容量的存储,这导致了开销的增加。考虑到未来数据量的增长,继续扩展该系统将带来巨大的成本压力。
02 引入 JuiceFS 后的新架构:提升高吞吐与扩展性
在经过充分的技术选型和评估后,该客户决定从原有架构迁移到 JuiceFS,以更好地满足其高吞吐量和扩展性需求。
JuiceFS 架构特点
JuiceFS 采用数据和元数据分离的架构,数据存储于对象存储。企业版通过 Raft 协议构建元数据集群,社区版则支持 Redis、TiKV 等数据库作为元数据引擎。
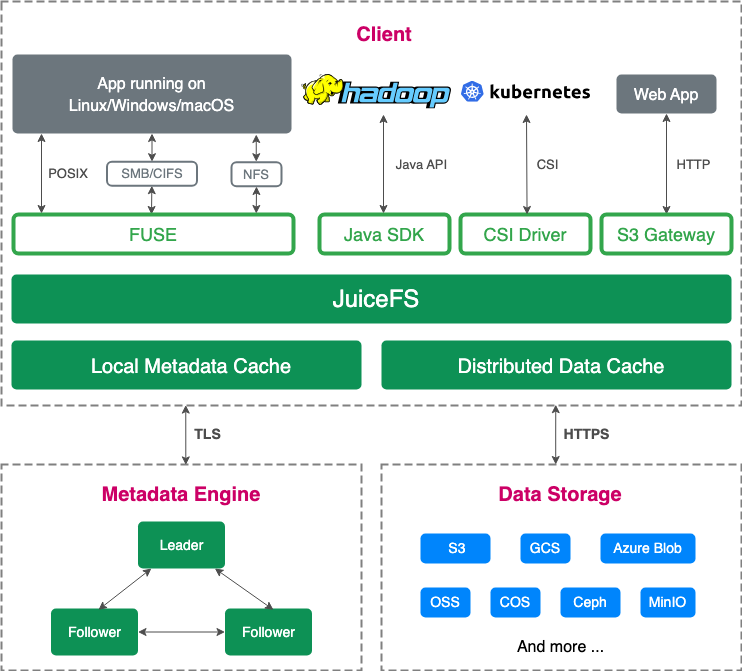
为了提高性能,JuiceFS 将数据切块,每次更新限制为最小的 4MB,从而大幅减少文件写入的浪费,显著提升了在对象存储上的写入效率。初次使用 JuiceFS 的用户可能会担心,数据切块后是否会影响文件的可用性,或是脱离 JuiceFS 产品后,JuiceFS 的分块格式无法被正常读取,造成产品的强绑定。事实上,JuiceFS 设计将对象存储视作本地磁盘使用,避免了与文件系统的紧密耦合,同时解决了对象存储在随机写入效率上的瓶颈。此外,JuiceFS 提供接口支持轻松将数据迁移回 S3 对象存储,避免了对特定存储产品的依赖。
部署方案
与之前的托管文件系统集中式的架构不同,基于 JuiceFS 的新架构利用每个业务节点上的客户端来提供协议转换和缓存加速功能。无论是通过 JuiceFS CSI 与 Kubernetes 集成,还是直接通过主机访问,部署完成后,业务节点便能高效地访问元数据和对象存储,极大提升了存储系统的性能与灵活性。这种架构的优势在于,可以灵活地扩展系统,避免单点故障,同时提升存储和计算资源的利用效率。
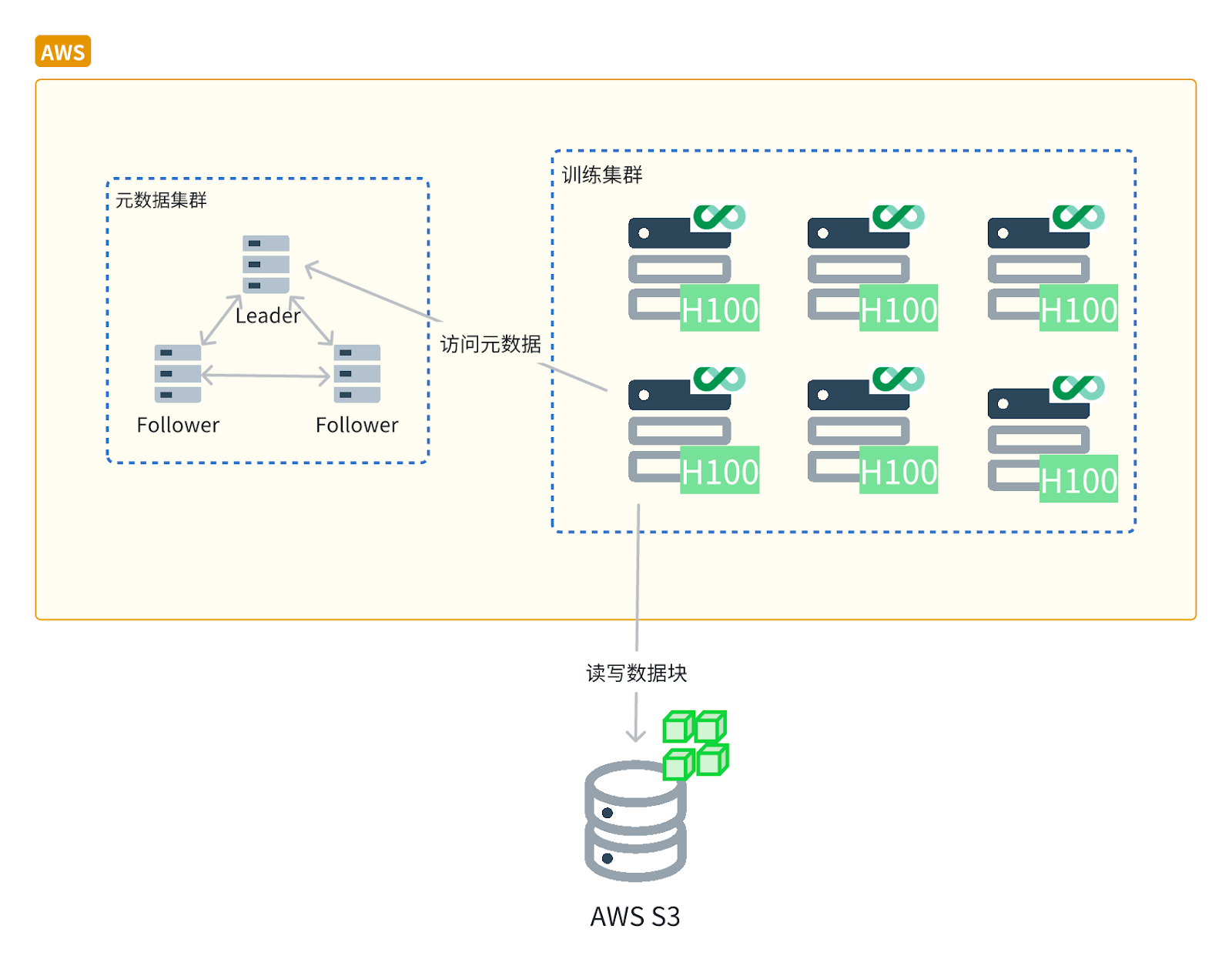
此外,JuiceFS 能够充分利用闲置硬件资源,如 NVMe 本地磁盘和内存。JuiceFS 将这些闲置磁盘整合为一个分布式缓存池,从而提升缓存性能和吞吐能力。对于社区版用户,可以将缓存目录设置到分布式文件系统中,如 BeeGFS 等,以构建分布式缓存层。
最终,使用 JuiceFS,该客户构建了一个 360TB 的分布式缓存池,6 台服务器提供了 600Gbps 的聚合带宽,该缓存池的瞬时吞吐已达到 10GB/s,JuiceFS 在 TCP 网络利用率方面表现出色,100Gbps 以下带宽的利用率可达 95%。若 GPU 节点没有额外磁盘资源,也可利用内存来构建缓存池。
03 JuiceFS 读性能测试
为了评估和展示 JuiceFS 使用分布式缓存后的读性能,我们进行了内部测试,使用了 JuiceFS 企业版 5.2,测试大文件顺序读性能。
测试结果显示,在 100 台机器聚合成的 10Tbps 网络环境下,JuiceFS 分布式缓存的聚合吞吐量达到了 1.23 TB/s,证明在 100Gbps TCP 网络条件下,网络利用率可达到 95%以上;即使在 200Gbps 网络下,利用率也可达到约 70%。本次测试使用 100Gbps 网卡,在 TCP 环境下成功实现了较高的整体聚合吞吐率。
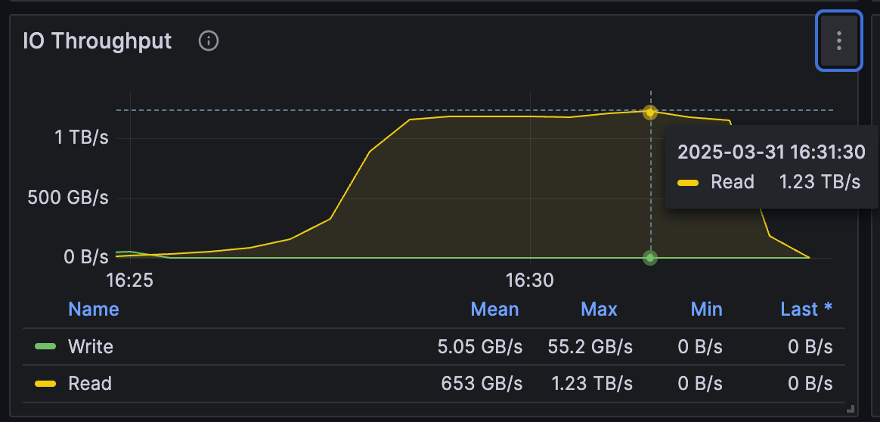
在测试过程中,我们结合了磁盘和内存资源,确保充分利用 100Gbps 网卡的带宽上限,达到每秒 12.5GB 的吞吐量。
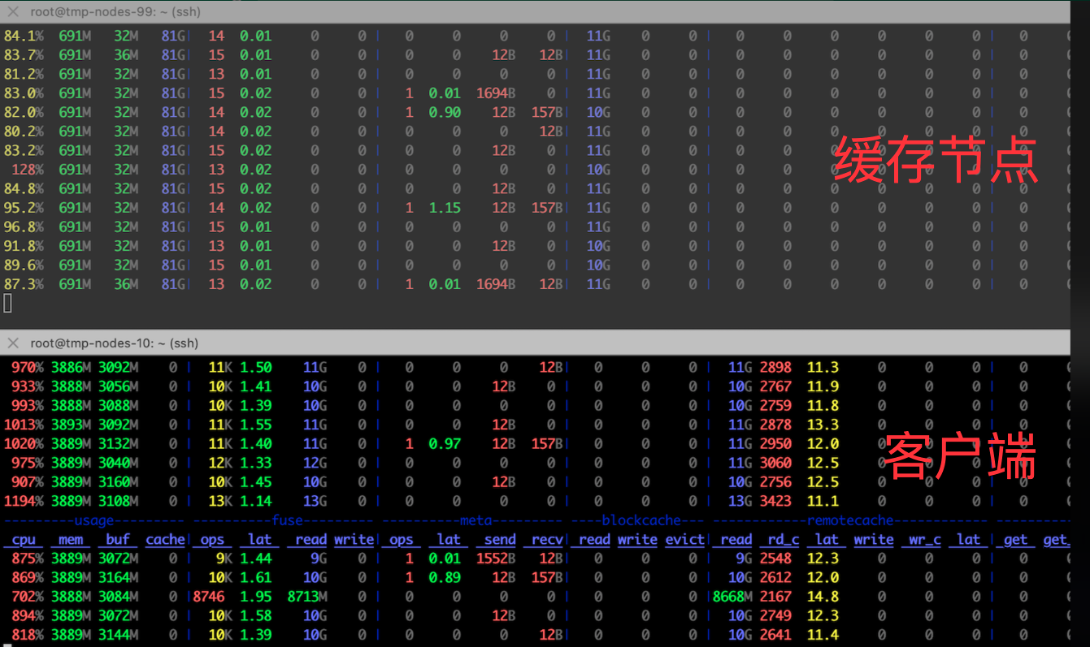
在缓存服务节点的测试中,每秒从本地磁盘读取 11GB 数据并通过网络传输到消费节点时,CPU 消耗不到一个核,平均每提供 10GB/s 带宽,仅消耗一个核。
在客户端节点方面,每 GB/s 的读取仅消耗 0.8 个 CPU 核。如果要充分利用 100Gbps 网卡带宽,使用 JuiceFS FUSE 客户端存储需占用 10 个 CPU 核。TCP 网络对用户来说应用更为广泛,因此,基于 TCP 网络 的优化方案能够广泛适用于多种场景,满足不同需求。
04 总结
本文介绍了 JuiceFS 在 AI 训练与推理场景中的应用。在这些场景中,虽然延迟和 IOPS 重要,但吞吐性能和性价比同样不可忽视。针对传统并行文件系统(PFS)成本高且吞吐量与存储容量绑定的问题,JuiceFS 提供了一种低成本、高效益的解决方案。其通过数据与元数据分离的架构,能够将业务节点上的闲置磁盘、内存和网络资源池化,按需构建高性能的分布式缓存集群,避免了容量绑定的限制。如文中案例所示,采用该方案能够将存储总拥有成本降低近十倍,同时实现高达 TB/s 级别的吞吐量,并保持较低的客户端 CPU 开销。
