














云知声 Atlas 团队在 2021 年初开始接触并跟进 JuiceFS 存储,并且在早期已经积累了丰富的 Fluid 使用经验。近期,云知声团队与 Juicedata 团队合作开发了 Fluid JuiceFS 加速引擎,使用户能够更好地在 Kubernetes 环境中使用 JuiceFS 缓存管理能力。本篇文章讲解如何在 Kubernetes 集群中玩转 Fluid + JuiceFS。
背景介绍
Fluid 简介
CNCF Fluid 是一个开源的 Kubernetes 原生的分布式数据集编排和加速引擎,主要服务于云原生场景下的数据密集型应用,例如大数据应用、AI 应用等,关于 Fluid 更多信息可以参考地址。
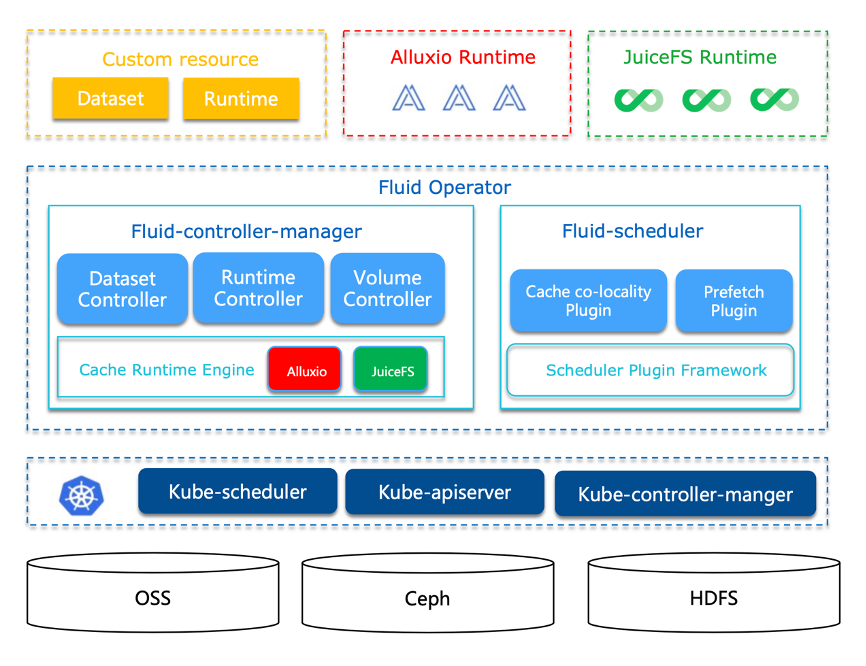
Fluid 不是全存储加速和管理,而是应用使用的数据集加速和管理。Fluid 提供了一种更加云原生的方式对数据集进行管理,通过缓存加速引擎实现将底层存储系统的数据 cache 在计算节点的内存或者硬盘上,解决了计算与存储分离架构中由于数据传输带宽限制以及底层存储带宽与 IOPS 能力限制等问题,导致的 IO 效率不高等问题。Fluid 提供缓存数据调度能力,缓存被纳入 Kubernetes 扩展资源,Kubernetes 在进行任务的调度的时候,能够参考缓存进行调度策略的分配。
Fluid 有 2 个重要的概念:Dataset 与 Runtime。
- Dataset:数据集是逻辑上相关的一组数据的集合,一致的文件特性,会被同一运算引擎使用。
- Runtime:实现数据集安全性,版本管理和数据加速等能力的执行引擎的接口,定义了一系列生命周期的方法。
Fluid 的 Runtime 定义了标准化的接口,Cache Runtime Engine 可以对接多种缓存引擎,提供了用户更灵活的选择,用户能够针对不同的场景与需求,充分利用缓存引擎加速相应的场景应用。
JuiceFS 简介
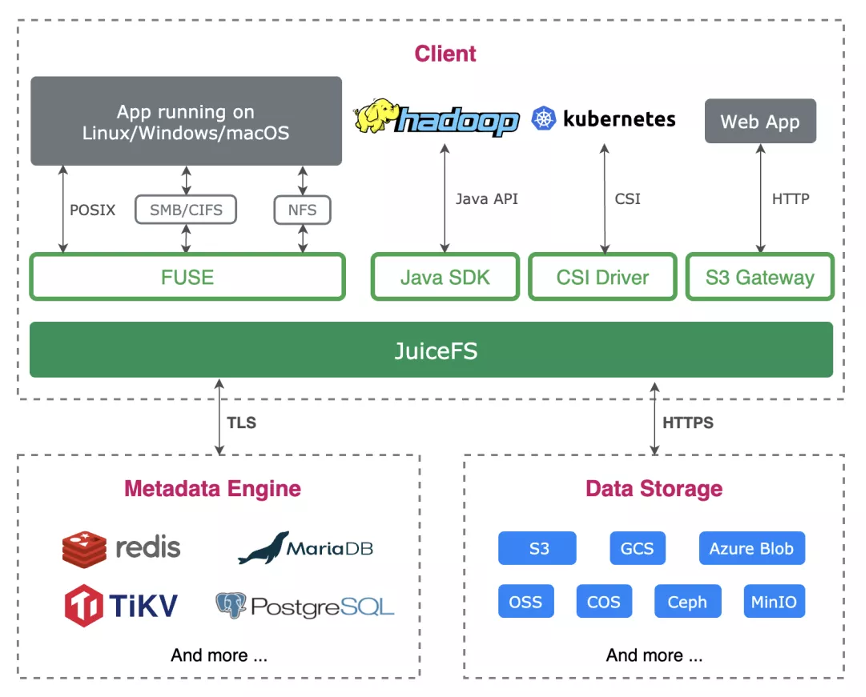
JuiceFS 是一个面向云环境设计的高性能开源分布式文件系统,完全兼容 POSIX、HDFS、S3 接口,适用于大数据、AI 模型训练、Kubernetes 共享存储、海量数据归档管理等场景。
使用 JuiceFS 存储数据,数据本身会被持久化在对象存储(例如,Amazon S3),而数据所对应的元数据可以根据场景需求被持久化在 Redis、MySQL、TiKV 等多种数据库引擎中。JuiceFS 客户端具有数据缓存能力,当通过 JuiceFS 客户端读取数据时,这些数据将会智能地缓存到应用配置的本地缓存路径(可以是内存,也可以是磁盘),同时元数据也会缓存到客户端节点本地内存中。
对于 AI 模型训练场景来说,第一个 epoch 完成之后后续的计算都可以直接从缓存中获取训练数据,极大地提升了训练效率。JuiceFS 也具有预读、并发读取数据的能力,在 AI 训练场景能够保证每个 mini-batch 的生成效率,提前准备好数据。数据预热能够提前将公有云上的数据换到到本地节点,对于 AI 训练场景能够保证申请完 GPU 资源后,即有预热的数据进行运算,为宝贵的 GPU 使用节省了时间。
为什么使用 JuiceFSRuntime
云知声 Atlas 超算平台作为底层基础架构,支持着公司在 AI 各个领域的模型训练与推理服务的开展。云知声很早就开始布局建设业界领先的 GPU/CPU 异构 Atlas 计算平台和分布式文件存储系统,该计算集群可为 AI 计算提供高性能计算和海量数据的存储访问能力。云知声 Atlas 团队在 2021 年初开始接触并跟进 JuiceFS 存储,进行了一系列 POC 测试,在数据可靠性与业务场景的适配,都满足我们目前的需求。
在训练场景我们充分利用 JuiceFS 客户端的缓存能力,为 AI 模型训练做数据加速,但是在使用过程中发现了一些问题:
- 训练 Pod 通过 hostpath 挂载,需要在每个计算节点挂载 JuiceFS 客户端,挂载需要管理员操作,挂载参数固定,不够灵活。
- 用户无法对计算节点客户端的缓存管理,缓存无法手动清理与扩容。
- 缓存数据集无法像 Kubernetes 自定义资源一样能够被 Kubernetes 进行调度。
由于我们在生产环境已经积累了一定的 Fluid 使用经验,所以我们与 Juicedata 团队合作设计并开发了 JuiceFSRuntime,将 Fluid 对数据编排与管理能力和 JuiceFS 的缓存能力结合起来。
什么是 Fluid + JuiceFS(JuiceFSRuntime)
JuiceFSRuntime 是 Fluid 自定义的一种 Runtime,其中可以指定 JuiceFS 的 worker、FUSE 镜像以及相应的缓存参数。其构建方式与 Fluid 其他 Runtime 一致,即通过 CRD 的方式构建,JuiceFSRuntime Controller 监听 JuiceFSRuntime 资源,实现缓存 Pod 的管理。
JuiceFSRuntime 支持数据亲和性调度(nodeAffinity),选择合适的缓存节点,支持 FUSE pod 懒启动,支持用户以 POSIX 接口访问数据,目前只支持一个挂载点。
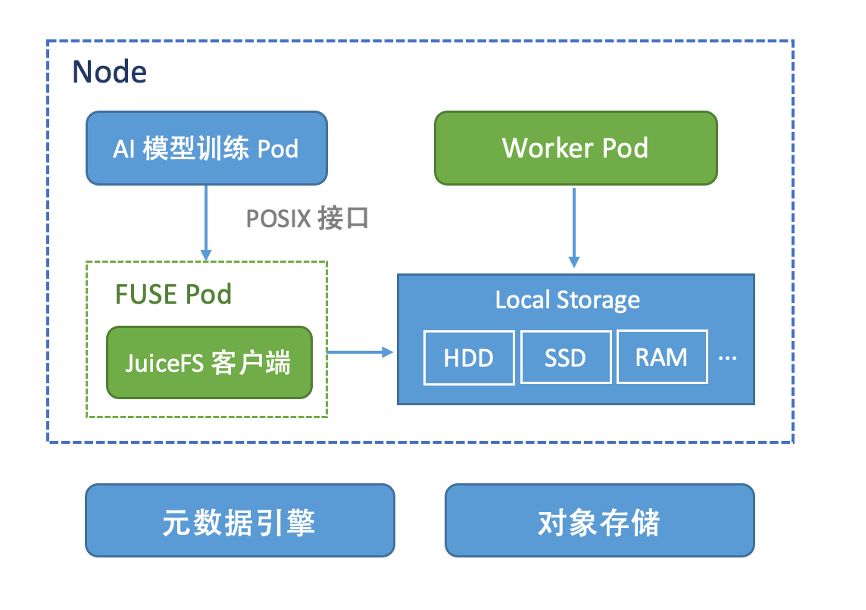
其架构图如上图所示,JuiceFSRuntime 由 FUSE Pod 与 Worker Pod 组成。Worker pod 主要实现缓存的管理,如 Runtime 退出时的缓存清理;FUSE pod 主要负责 JuiceFS 客户端的参数设置及挂载。
如何使用 JuiceFSRunime
下面来看看如何使用 JuiceFSRuntime 进行缓存加速。
前期准备
要使用 JuiceFSRuntime 首先需要准备元数据引擎和对象存储。
构建元数据引擎
用户可以很容易的在云计算平台购买到各种配置的云 Redis 数据库,如果是评估测试可以使用 Docker 快速的在服务器上运行一个 Redis 数据库实例:
$ sudo docker run -d --name redis \
-v redis-data:/data \
-p 6379:6379 \
--restart unless-stopped \
redis redis-server --appendonly yes准备对象存储
和 Redis 数据库一样,几乎所有的公有云计算平台都提供对象存储服务。因为 JuiceFS 支持几乎所有主流平台的对象存储服务,用户可以结合自己的情况进行部署。
这里评估测试使用的是 Docker 运行的 MinIO 实例:
$ sudo docker run -d --name minio \
-p 9000:9000 \
-p 9900:9900 \
-v $PWD/minio-data:/data \
--restart unless-stopped \
minio/minio server /data --console-address ":9900"对象存储初始的 Access Key 和 Secret Key 均为 minioadmin。
下载并安装 Fluid
按照文档步骤安装 Fluid,在 Fluid 的安装 chart values.yaml 中将 runtime.juicefs.enable 设置为 true,并安装 Fluid。确保 Fluid 集群正常运行:
$ kubectl get po -n fluid-system
NAME READY STATUS RESTARTS AGE
csi-nodeplugin-fluid-ctc4l 2/2 Running 0 113s
csi-nodeplugin-fluid-k7cqt 2/2 Running 0 113s
csi-nodeplugin-fluid-x9dfd 2/2 Running 0 113s
dataset-controller-57ddd56b54-9vd86 1/1 Running 0 113s
fluid-webhook-84467465f8-t65mr 1/1 Running 0 113s
juicefsruntime-controller-56df96b75f-qzq8x 1/1 Running 0 113s确保 juicefsruntime-controller、dataset-controller、fluid-webhook 的 pod 以及若干 csi-nodeplugin pod 正常运行。
创建 Dataset
在使用 JuiceFS 之前,需要提供元数据服务(如 Redis)及对象存储服务(如 MinIO)的参数,并创建对应的 secret:
$ kubectl create secret generic jfs-secret \
--from-literal=metaurl=redis://$IP:6379/1 \ # Redis 的地址,IP 为 Redis 所在节点的 IP
--from-literal=access-key=minioadmin \ # 对象存储的 AK
--from-literal=secret-key=minioadmin # 对象存储的 SK创建 Dataset YAML 文件:
cat<<EOF >dataset.yaml
apiVersion: data.fluid.io/v1alpha1
kind: Dataset
metadata:
name: jfsdemo
spec:
mounts:
- name: minio
mountPoint: "juicefs:///demo"
options:
bucket: "<bucket>"
storage: "minio"
encryptOptions:
- name: metaurl
valueFrom:
secretKeyRef:
name: jfs-secret
key: metaurl
- name: access-key
valueFrom:
secretKeyRef:
name: jfs-secret
key: access-key
- name: secret-key
valueFrom:
secretKeyRef:
name: jfs-secret
key: secret-key
EOF由于 JuiceFS 采用的是本地缓存,对应的 Dataset 只支持一个 mount,且 JuiceFS 没有 UFS,mountPoint 中可以指定需要挂载的子目录 (juicefs:/// 为根路径),会作为根目录挂载到容器内。
创建 Dataset 并查看 Dataset 状态:
$ kubectl create -f dataset.yaml
dataset.data.fluid.io/jfsdemo created
$ kubectl get dataset jfsdemo
NAME UFS TOTAL SIZE CACHED CACHE CAPACITY CACHED PERCENTAGE PHASE AGE
jfsdemo NotBound 44s如上所示,status 中的 phase 属性值为 NotBound,这意味着该 Dataset 资源对象目前还未与任何 JuiceFSRuntime 资源对象绑定,接下来,我们将创建一个 JuiceFSRuntime 资源对象。
创建 JuiceFSRuntime
创建 JuiceFSRuntime 的 YAML 文件:
$ cat<<EOF >runtime.yaml
apiVersion: data.fluid.io/v1alpha1
kind: JuiceFSRuntime
metadata:
name: jfsdemo
spec:
replicas: 1
tieredstore:
levels:
- mediumtype: SSD
path: /cache
quota: 40960 # JuiceFS 中 quota 的最小单位是 MiB,所以这里是 40GiB
low: "0.1"
EOF创建并查看 JuiceFSRuntime:
$ kubectl create -f runtime.yaml
juicefsruntime.data.fluid.io/jfsdemo created
$ kubectl get juicefsruntime
NAME WORKER PHASE FUSE PHASE AGE
jfsdemo Ready Ready 72s查看 JuiceFS 相关组件 Pod 的状态:
$ kubectl get po | grep jfs
jfsdemo-worker-mjplw 1/1 Running 0 4m2sJuiceFSRuntime 没有 master 组件,而 FUSE 组件实现了懒启动,会在 pod 使用时再创建。
创建缓存加速作业
创建需要加速的应用,其中 Pod 使用上面创建的 Dataset 的方式为指定同名的 PVC:
$ cat<<EOF >sample.yaml
apiVersion: v1
kind: Pod
metadata:
name: demo-app
spec:
containers:
- name: demo
image: nginx
volumeMounts:
- mountPath: /data
name: demo
volumes:
- name: demo
persistentVolumeClaim:
claimName: jfsdemo
EOF创建 Pod:
$ kubectl create -f sample.yaml
pod/demo-app created查看 pod 状态:
$ kubectl get po | grep demo
demo-app 1/1 Running 0 31s
jfsdemo-fuse-fx7np 1/1 Running 0 31s
jfsdemo-worker-mjplw 1/1 Running 0 10m可以看到 pod 已经创建成功,同时 JuiceFS 的 FUSE 组件也启动成功。
进入 Pod 执行 df -hT 查看缓存目录是否挂载:
$ kubectl exec -it demo-app bash -- df -h
Filesystem Size Used Avail Use% Mounted on
overlay 20G 14G 5.9G 71% /
tmpfs 64M 0 64M 0% /dev
tmpfs 3.9G 0 3.9G 0% /sys/fs/cgroup
JuiceFS:minio 1.0P 7.9M 1.0P 1% /data可以看到这时候缓存目录已经成功挂载了。
接下来,我们在 demo-app 这个 pod 中测试一下写功能:
$ kubectl exec -it demo-app bash
[root@demo-app /]# df
Filesystem 1K-blocks Used Available Use% Mounted on
overlay 20751360 14585944 6165416 71% /
tmpfs 65536 0 65536 0% /dev
tmpfs 3995028 0 3995028 0% /sys/fs/cgroup
JuiceFS:minio 1099511627776 8000 1099511619776 1% /data
/dev/sda2 20751360 14585944 6165416 71% /etc/hosts
shm 65536 0 65536 0% /dev/shm
tmpfs 3995028 12 3995016 1% /run/secrets/kubernetes.io/serviceaccount
tmpfs 3995028 0 3995028 0% /proc/acpi
tmpfs 3995028 0 3995028 0% /proc/scsi
tmpfs 3995028 0 3995028 0% /sys/firmware
[root@demo-app /]#
[root@demo-app /]# cd /data
[root@demo-app data]# echo "hello fluid" > hello.txt
[root@demo-app data]# cat hello.txt
hello fluid最后再来看看缓存功能,在 demo-app 这个 pod 中的挂载目录 /data 中创建一个 1G 的文件,然后再 cp 出来:
$ kubectl exec -it demo-app bash
root@demo-app:~# dd if=/dev/zero of=/data/test.txt count=1024 bs=1M
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 6.55431 s, 164 MB/s
root@demo-app:~# time cp /data/test.txt ./test.txt
real 0m5.014s
user 0m0.003s
sys 0m0.702s
root@demo-app:~# time cp /data/test.txt ./test.txt
real 0m0.602s
user 0m0.004s
sys 0m0.584s从执行结果来看,第一次 cp 用了 5s,此时建立缓存,第二次 cp 的时候由于缓存已经存在,只用了 0.6s。JuiceFS 所提供的强大的缓存能力,使得只要访问某个文件一次,该文件就会被缓存在本地缓存路径中中,所有接下来的重复访问都是从 JuiceFS 中直接获取数据。
后续规划
目前 JuiceFSRuntime 支持的功能并不多,未来我们会继续完善,比如 FUSE Pod 以 Non-root 的方式运行,以及 Dataload 数据预热功能等。
作者简介
- 吕冬冬,云知声超算平台架构师, 负责大规模分布式机器学习平台架构设计与功能研发,负责深度学习算法应用的优化与 AI 模型加速。研究领域包括高性能计算、分布式文件存储、分布式缓存等。
- 朱唯唯,Juicedata 全栈工程师,负责 JuiceFS CSI Driver 的开发和维护,负责 JuiceFS 在云原生领域的发展。
