














时至今日,容器化技术可谓是遍地开花。Docker 从最初的众星捧月,到现在也已经是优秀替代品辈出,Kubernetes、Podman、LXC、containerd 等技术名词越来越频繁的出现在大众视野。但不论技术如何更迭,容器化技术的底层逻辑尚未变化,数据持久化始终是容器化技术不得不认真对待的重要事项。
容器与数据持久化
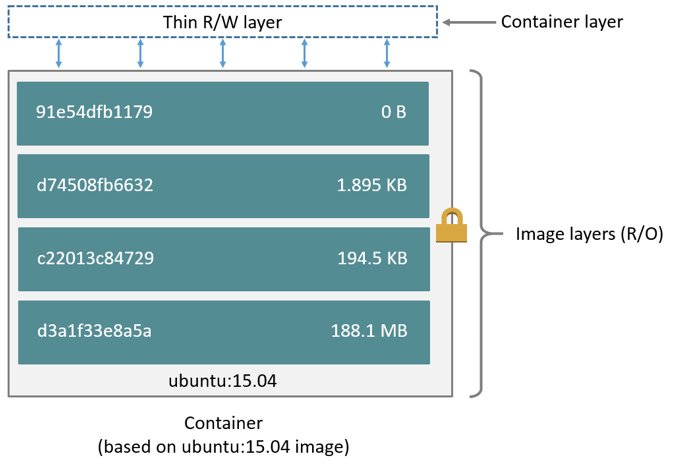
我们知道,Docker 容器是分层存储的,如以下架构图所示,镜像由一系列只读层组成,容器的最上层是一个读写层,数据可以从任何一层直接读取,改写数据则需要先从只读层拷贝到读写层,即 copy-on-write 机制。这种数据读写机制可以提供很高的空间利用率,但在性能上势必低于原生文件系统,而且容器存储层是易失性的,随着容器被销毁,读写层上保存的数据也会一并删除。
使用容器存储程序在运行期间生成的无需长期存储的数据是很合适的,但对数写密集型的应用,比如数据库,以及那些需要长期保存的数据或需要在多个容器之间共享的数据,就必须该用持久可靠的方式来存储数据。
对于 Docker、Podman 等容器化技术,数据持久化不外乎使用卷(Volume)或绑定挂载(bind mounts)。
卷(Volume)
卷(Volume)是容器化技术首推的数据持久化方式,以 Docker 为例,卷由 Docker 进程管理,外部程序无法直接对其进行读写,这样的封闭性可以在一定程度上提升存储的安全性。卷通过 Docker CLI 或 Docker API 进行创建、读写、迁移或删除等管理操作,能够安全地供多个容器共享使用。
绑定挂载(bind mounts)
绑定挂载(bind mounts)是将宿主机(Host)的目录映射在容器中指定的目录,如此一来就等同于把容器产生的数据直接存储在宿主机上了,它是容器与宿主机之间共享数据很便捷的一种方式。不过绑定挂载的目录在容器外是透明的,可能会被其他进程访问,所以要注意妥善管理。
从 Docker 官方文档 可以了解到卷与绑定挂载这两种方式的区别,简单来说就是卷因其特有的格式决定了它更容易管理和迁移,也便于在多个容器之间共享,在 Mac 或 Windows 环境下比绑定挂载的性能更好等。当然,脱离场景讨论优势是没有意义的,客观来说这两种基本的数据持久化方式在不同的场景下都有其独特的优势。
数据持久化的挑战
卷和绑定挂载解决了容器的数据持久化问题,但随着时间的推移,持久化在宿主机上的数据势必又会出现一些新的挑战:
- 宿主机存储扩容的挑战
- 数据跨平台共享的挑战
- 数据异地容灾的挑战
- 大规模数据上云的性能挑战
- 数据迁移的挑战
不难理解,数据持久化存储在宿主机,或早或晚总会面临存储扩容的问题。即便是预先规划的计算集群短时间内没有存储容量不足的问题,可能又会有其他方面的挑战,比如数据需要在不同的地区、不同的云计算平台之间流转处理,抑或是需要对持久化的数据做异地容灾、异地迁移,诸如此类的需求往往是伴随着数据的产生同时出现的,通过“拉专线”、“异地建立同样规模的集群”等方式可以解决大部分问题,但这显然会成倍增加人力和财力的成本投入。
是否有更简单、更灵活、更经济的数据持久化方案呢?
用 JuiceFS 持久化容器数据
JuiceFS 是开源的高性能共享文件系统,可将几乎所有对象存储接入本地作为海量本地磁盘使用,亦可同时在跨平台、跨地区的不同主机上同时挂载读写。它采用“数据”与“元数据”分离存储的架构,使用基于云的对象存储和数据库,即可在任意数量联网的主机上共享挂载读写。
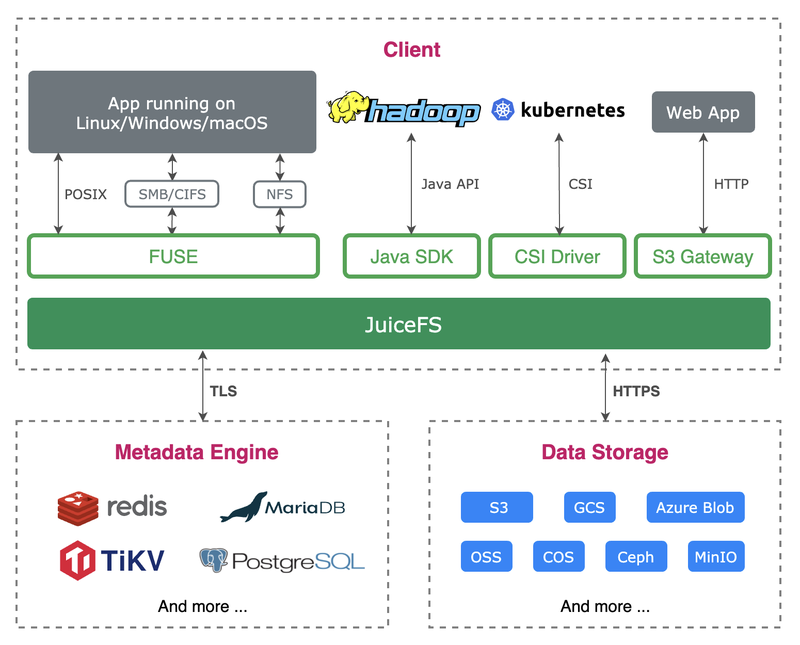
在容器化方面,JuiceFS 可以很容易地通过绑定挂载的方式把基于云的海量存储映射到容器,而对于纯容器化的应用场景,JuiceFS 提供了 Docker 卷插件 (Volume Plugin),轻松创建基于 JuiceFS 的存储卷,以供容器、容器之间、容器之外任意位置使用和共享数据。
接下来让我们一起了解一下使用 JuiceFS 为容器做数据持久化的两种方式。但在开始之前,还有需要一些准备工作。
准备工作
前面已经提到,JuiceFS 采用数据与元数据分离存储的架构,数据通常存储在对象存储,元数据存储在独立的数据库中。不论是直接在操作系统上使用,还是在容器中使用,创建 JuiceFS 文件系统都需要提前准备对象存储和数据库。
在底层存储方面,JuiceFS 采用了可插拔式的设计,也就是说,数据存储方面不但可以选择几乎所有的对象存储,还可以使用本地磁盘或基于 WebDAV、SFTP 等协议的文件存储。元数据存储方面除了可以选择 Redis、TiKV、MySQL、PostgreSQL 等基于网络的数据库,还可以选择 SQLite 这种单机数据库。总之,在底层存储方面,用户可以根据场景需要灵活搭配,既可以选择云计算平台提供的服务,也可以自行搭建服务。
考虑到文件系统的性能和网络延时,特别是对于需要在容器之间、服务器之间、抑或是云计算平台之间共享数据的情况,对象存储和数据库应该尽量靠近使用文件系统的位置。比如,你的 Docker 运行在亚马逊 EC2 上,那么选择亚马逊的 S3 和数据库创建 JuiceFS 文件系统来使用,就能更大程度的提升读写效率和稳定性,也能在一定程度上减免资源消费。
为了便于演示,我们假设准备了以下云计算资源:
云服务器
- 系统:Ubuntu Server 20.04 x86_64
- IP:123.3.18.3
对象存储
- 类型:s3
- Bucket endpoint: https://myjfs.s3.amazonaws.com
- Access Key: mykey
- Secret Key: mysecret
Redis 数据库
- 地址:redis://mydb.cache.amazonaws.com:6379
- 密码:mypassword
使用挂载绑定
挂载绑定是将宿主机上的目录映射到容器,当使用 JuiceFS 存储时,就是将挂载到宿主机上的 JuiceFS 目录映射到容器中。
在创建 JuiceFS 文件系统时,我们可以使用宿主机上的客户端,也可以使用 JuiceFS 官方的客户端镜像。简单起见,我们在宿主机上进行文件系统的创建操作,首先使用一键安装脚本安装 JuiceFS 社区版客户端:
curl -sSL https://d.juicefs.com/install | sh -然后使用准备好的对象存储和数据库创建一个名为 myjfs 的文件系统,安全起见,把相关的密码写入环境变量:
export ACCESS_KEY=mykey
export SECRET_KEY=mysecret
export META_PASSWORD=mypassword密码写入环境变量不但更安全,而且在格式化文件系统的时候的命令选项也更少,创建文件系统:
juicefs format --storage s3 \
--bucket https://myjfs.s3.amazonaws.com \
redis://mydb.cache.amazonaws.com/1 myjfs文件系统创建完毕,紧接着就可以把它挂在到服务器上:
export META_PASSWORD=mypassword
sudo juicefs mount redis://mydb.cache.amazonaws.com/1 /mnt/myjfs -d挂载完毕,/mnt/myjfs 就是 JuiceFS 文件系统的存储入口,所有存入的文件都会以特定的格式存储到我们设置的对象存储,相关的元数据会存入我们设置的数据库。现在,我们可以直接把 /mnt/myjfs 或其中的任意子目录映射到 Docker 容器作为持久化存储来使用。
例如,我们创建一个 MySQL 数据库容器,把宿主机上的 /mnt/myjfs/mysql 作为数据库的持久化存储:
sudo docker run --name mysql -d \
-v /mnt/myjfs/mysql:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=my-secret-pw \
mysql:8这样一来,所有数据库相关数据都会保存到 JuiceFS 中,因为是绑定挂载,我们在宿主机上可以在 /mnt/myjfs/mysql 中实时查看到数据库产生的内容。当然,因为数据库目录对宿主机透明可见,这势必存在一些安全隐患,为此,我们可以使用存储卷。
使用存储卷
JuiceFS 提供的 Docker 卷插件(Volume Plugin)可以让我们非常方便的创建 JuiceFS 文件系统并在上面创建基于云的存储卷,不过这种方式只适用于 Docker 环境,其他容器化技术无法使用。
安装卷插件
sudo docker plugin install juicedata/juicefs --alias juicefs创建存储卷
使用 JucieFS 卷插件创建存储卷相比之下要简单很多,重复使用 -o 选项指定文件系统的信息即可,以下命令会创建一个名为 myjfs 的 JuiceFS 文件系统,并在它上面创建一个名为 myjfs 的存储卷。
sudo docker volume create -d juicefs \
-o name=myjfs \
-o metaurl=redis://:[email protected]/1 \
-o storage=s3 \
-o bucket=https://myjfs.s3.amazonaws.com \
-o access-key=mykey \
-o secret-key=mysecret \
myjfs使用存储卷
接下来我们把 myjfs 存储卷挂载给容器,沿用前面 MySQL 数据库容器的例子,命令如下:
sudo docker run --name mysql -d \
-v myjfs:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=my-secret-pw \
mysql:8这样一来,数据库产生的所有数据都会存储到名为 myjfs 的 JuiceFS 文件系统中。
故障排查
如果在使用 JuiceFS Docker Volume Plugin 时遇到异常,可以参考官网文档进行排查。
存储卷与 JuiceFS 的关系
当使用 JuiceFS 卷插件创建存储卷时,本质上就是把一个 JuiceFS 文件系统创建模拟成一个存储卷。我们知道,一个 JuiceFS 文件系统是由一个对象存储 Bucket 和一个数据库 database 组成的。在卷插件看来,这个 Bucket 和 database 组成的文件系统会以一个存储卷的形式为容器提供持久化存储,所有存储到卷插件的数据,都会存储在 JuiceFS 文件系统中。
因为只是把 JuiceFS 文件系统模拟成为一个存储卷,文件系统本身并没有发生任何改变,所以这个文件系统与直接用 JuiceFS 客户端创建的没有任何区别,你可以在任何安装了 JuiceFS 客户端的设备上进行挂载和读写。以前面创建的 myjfs 存储卷为例,可以在宿主机或任何其他计算机上挂载读写它关联的文件系统:
export META_PASSWORD=mypassword
sudo juicefs mount redis://mydb.cache.amazonaws.com/1 /mnt/myjfs -d挂载以后,在 /mnt/myjfs 上看到的内容与 mysql 容器 /var/lib/mysql 目录中看到的是完全一致的,而且不论是容器外还是容器内的,写入的数据在所有挂载点上是可以实时看到且内容一致的。
创建多个存储卷
现在我们已经知道,一个存储卷对应着一个 JuiceFS 文件系统,而一个文件系统是由一个 Bucket 和一个 database 组成。当需要创建多个存储卷时,就需额外准备一套 bucekt 和 database。
提示:可以使用同一个对象存储 Bucket 创建多个 JuiceFS 文件系统,只要确保文件系统名称彼此不同即可。
在前面我们已经使用 Redis 的 1 号数据库创建了一个名为 myjfs 的文件系统,它会在对象存储 Bucket 上创建 myjfs 子目录存储数据。现在我们可以使用 2 号数据库再创建一个名为 fs2 的存储卷:
sudo docker volume create -d juicefs \
-o name=fs2 \
-o metaurl=redis://:[email protected]/2 \
-o storage=s3 \
-o bucket=https://myjfs.s3.amazonaws.com \
-o access-key=mykey \
-o secret-key=mysecret \
fs2虽然新创建的存储卷使用了同一个 Bucket,但由于文件系统名称不同,JuiceFS 会在 Bucket 下创建独立的 fs2 目录来存储数据,因此不会与前面的 myjfs 发生冲突,只要确保每个文件系统使用独立的 database 即可。
共享、容灾和迁移
数据在容器内和容器外皆可透明读写的特性,使得在 JuiceFS 上的持久化数据非常容易被共享和迁移。只要确保组成文件系统的对象存储和数据库均可通过网络访问,那么就可以在任何安装了 JuiceFS 客户端的主机上挂载读写。
比如一个容器部署在亚马逊云,另一个容器部署在阿里云,当需要在两个容器上共享一份数据时,只需用相同的 Bucket 和 Database 在两端创建基于 JuiceFS 的存储卷即可。我们知道,本质上一个存储卷就是一个 JuiceFS 文件系统,进一步地,因为 JuiceFS 文件系统支持在任意数量的设备上同时共享挂载,所以我们可以根据实际的业务需要,在任意平台、任意数量的容器上共享使用同一个 JuiceFS 存储卷。
以此类推,JuiceFS 这种在任意位置皆可共享挂载的特性,使得用户可以灵活的调整数据容灾和动态迁移的策略。
写在最后
本文从 Docker、Podman 等容器化技术的数据持久化原理和需求入手,介绍了使用 JuiceFS 作为容器数据持久化的方法,通过分析原理和使用举例,以期能够帮助读者更好的理解和上手使用。
