














好未来,前身学而思,于 2010 年在美国纽约证券交易所上市。公司积极将大模型研究应用于教学产品中,近期推出了数学领域的千亿级大模型。
在大模型的背景下,存储系统需处理巨量数据和复杂文件操作,要求支持高并发和高吞吐量。此外,还需应对版本管理、模型训练性能优化和多云分发的挑战。
为解决这些问题,团队基于 JuiceFS 开发了一个模型仓库,支持用户训练过程存储 checkpoint,并且控制面支持用户从各个云环境上传并统一管理模型。通过 JuiceFS CSI 组件,好未来将模型仓库挂载到各个集群中,大模型文件挂载配置只需 1-3 分钟,使得 AI 应用弹性变得更加容易。
此外,通过实施权限控制、克隆备份等策略,有效减少了用户误操作的损失并提高了数据安全性。目前好未来在多云多地部署了两套元数据和数据仓库;对象存储的使用规模达 6TB,存储超过 100 个模型。
01 大模型背景下模型仓库的挑战
在以往传统的 DevOps 研发流程中,我们通常以容器镜像为交付物,即由 Docker Builder 构建出一个镜像,然后通过 docker push 命令将其推送至 Docker Hub 或其他镜像仓库中。客户端的数据面则会通过 Docker 的方式,从中心镜像仓库拉取镜像至本地,这一过程中可能会采用一些加速手段以提高效率。
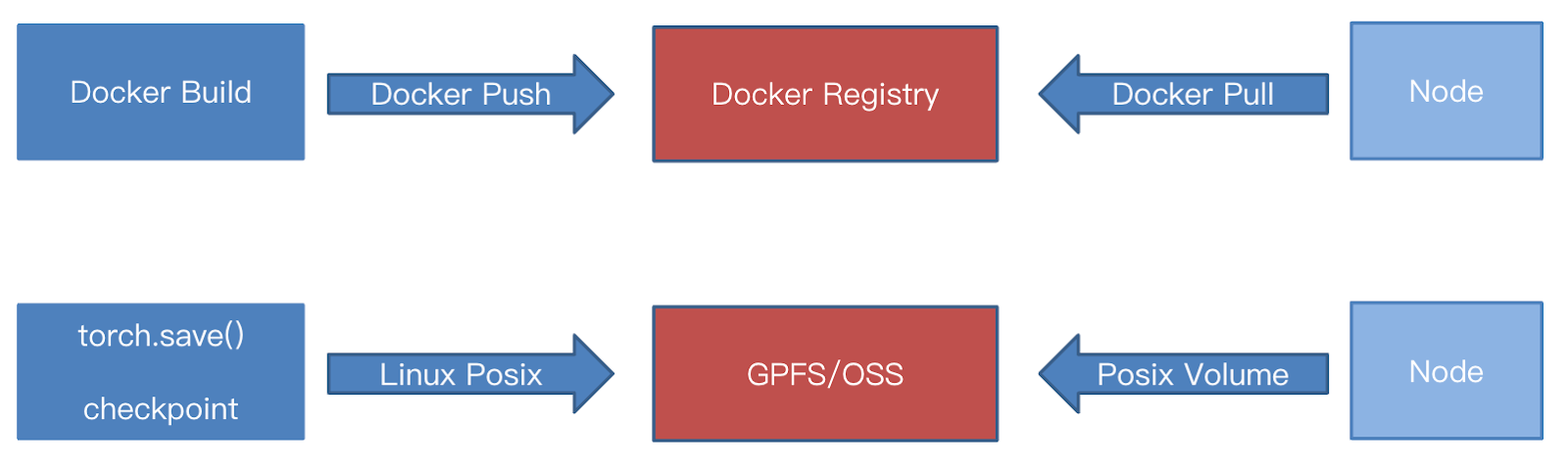
到 AI 场景时,情况就有所不同了。以训练任务为例,它可能会使用 Torch Save、Megatron save_checkpoint或其他方式生成一个序列化的文件,这个文件随后会以 Linux POSIX 方式写入到存储中,这个存储可以是对象存储(如阿里云的 OSS)或文件系统(如 GPFS 或 NFS)。简而言之,训练任务通过写文件系统的方式,将模型写入到远程存储中,从而实现了模型的上传。整个过程中还包含一些评估步骤,但在此我们略去不谈,以精简描述整个流程。与传统 IT 交付中仅仅涉及镜像的推送和拉取不同,AI 场景需要处理更大规模的数据和更复杂的文件操作,对存储系统的要求更为苛刻,常常需要高并发和高吞吐量的支持。
到了推理阶段,在容器的场景下,需要通过 CSI 方式去挂载 NFS 或者 GPFS 系统或对象存储系统来达到将远程的模型拉取到容器场景中。从表面上看,这个流程似乎并无问题,也能够正常工作。然而,在实际运行过程中,我们还是发现了不少明显的问题。
-
首要问题是缺乏版本管理。对于传统的容器镜像,我们有明确的交付物和版本信息,包括上传者、大小等详细信息。然而,在模型仓库中,由于模型通常是以 Linux 文件系统的方式存储的(文件或文件夹形式),因此缺乏版本管理和元数据信息,如上传者、修改者等。
-
其次,模型仓库无法实现加速和多云分发。在 Docker 场景中,我们可以使用如 Dragonfly 等工具进行加速。但是,在使用 NFS、GFS 或 OSS 等存储系统时,却缺乏一个有效的加速方案。同时,也无法实现多云分发。以 NFS 为例,它基本上是闭环于一个 IDC 内部的,无法实现跨 IDC 甚至跨云的挂载。即使能够实现挂载,其速度也会非常慢,因此我们可以认为它无法实现多云分发。
-
最后,安全性差。在推理场景下,整个模型仓库需要挂载到容器中。如果客户端的挂载权限过大(例如挂载了一个包含大量模型的目录),就可能导致模型泄露或误删除的问题。特别是当挂载方式为可读可写时,客户端甚至有可能删除模型文件。
由此衍生出不同场景对模型仓库的存储需求。
训练场景的存储需求:
- 模型下载与处理:在算法建模阶段,需要下载并可能转换及切分各种模型,这包括开源模型、参考模型或自设计的网络结构。例如,进行模型的 TP(Tensor Parallelism)和 PP(Pipeline Parallelism)切分。
- 高性能读写:训练阶段要求存储系统具备极高的读写吞吐能力,以便存储大规模的 checkpoint 文件。这些文件可能非常庞大,如单个 checkpoint 文件大小接近 1TB。
推理场景的存储需求:
- 模型版本管理与服务化:当模型更新至新版本时,需要进行版本发布和审批流程。此外,在模型服务化过程中,可能需要频繁地扩展或收缩使用的 GPU 资源,这通常在夜间进行资源释放,在白天进行资源扩展。
- 高读吞吐性能:由于白天需频繁拉取模型副本以应对资源扩展,存储系统需支持高效的读操作,确保快速响应模型拉取需求。
此外,从管理者角度存在以下需求:
- 团队级模型管理:模型仓库应支持按团队进行模型的隔离管理,确保不同团队之间模型的隐私和独立性。
- 详尽的版本控制:存储系统应能清晰记录模型的迭代时间、版本用途等元信息,支持模型的上传、下载、审计和分享功能。
02 存储选型:如何在成本、性能、稳定性之间取舍?
核心考量点
首先,要降低对云厂商的依赖,确保技术方案在自建 IDC 以及多个云厂商之间保持一致性和统一性;
其次,成本也是一个重要的考量因素。虽然资金充足可以支持更好的解决方案,但成本效益分析同样重要。我们需要综合考虑各种存储方案的成本,包括本地磁盘、GPFS 以及对象存储(如 OSS)等;
第三,性能是关键因素。根据之前的背景介绍,模型仓库的读写性能都有较高要求。因此,我们需要在单个 IDC 或单个云上实现模型读写流量的闭环,以确保高性能;
最后,稳定性也是不可忽视的因素。我们不会为了支撑模型仓库而引入过高的运维复杂度。因此,对组件的繁杂程度和稳定性都有很高的要求。
主要技术选型对比
Fluid + Alluxio + OSS:该方案在前几年已经相对成熟并受到广泛关注。它融合了云原生的编排能力和对象存储的加速能力,实现了多云技术上的统一。无论是在阿里云、腾讯云还是自建的 IDC 中,都能采用这一方案。此外,该方案在社区的应用也相当广泛。
然而,它也存在一些不足。例如,它无法与 Ceph Rados 进行结合,这在我们集团内部是一个已有的技术栈。同时,该方案的运维复杂度较高,组件较多且资源消耗较大。对于大文件的读取速度,该方案的表现也并不理想。此外,客户端的稳定性也有待进一步验证。
GPFS:它是一个商业并行文件系统,读写性能强劲,且我们集团已经购买了这一产品。此外,GPFS 在处理海量小文件方面也具有显著优势。然而,它的劣势同样明显。首先,它无法实现多云同步,这意味着我们在 IDC 购买的 GPU 无法在其他云上再购买一套 GPFS,成本高昂。其次,GPFS 的容量价格也非常昂贵,是 OSS 的好几倍。
CephFS:我们集团内对该技术有一定的技术沉淀和优势。然而,它同样无法实现多云同步,运营成本较高。
JuiceFS:它的优势在于支持多云同步,运维简单,组件较少且观测性较好。成本方面,它基本上只有对象存储的费用,除了元数据管理外,没有其他额外成本。此外,JuiceFS 既可以在云上搭配对象存储使用,也可以在 IDC 搭配 Ceph Rados 使用。综合考虑以上因素,我们选择了 JuiceFS 作为支持大模型模型仓库的底层存储系统。
03 好未来模型仓库实践方案
训练场景中模型仓库读写设计: 单云训练
首先,聚焦于训练场景中的模型仓库读写设置。我们采用单云训练策略,即在单一云平台上进行模型训练,而非跨多云进行,这主要考虑到实际操作中的可行性和效率。
针对训练场景下的读写需求,我们制定了以下方案:我们将大量 GPU 机器上冗余的 NVMe 磁盘组成一个 ceph 集群,使用 JuiceFS 对接 Rodos, 从而实现 ceph 集群的读写操作。 在模型训练过程中,模型会以 JuiceFS CSI 方式挂载一个盘。当需要执行 checkpoint 存储或加载时,将直接对 Rodos 进行读写操作。经实测,在大模型训练过程中,checkpoint 写入速度可达到 15GB/s。
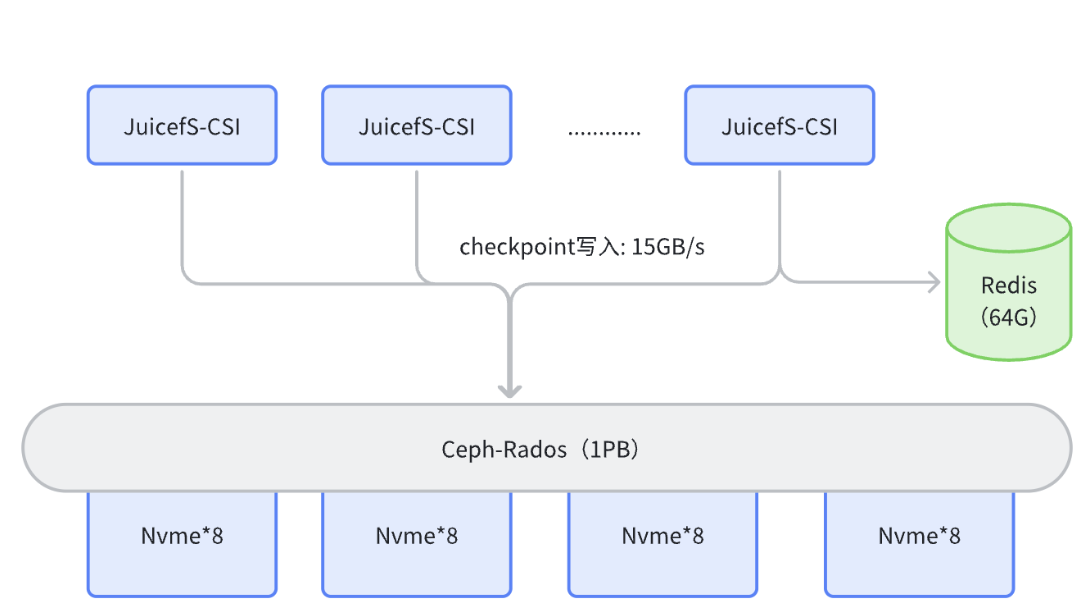
在元数据管理方面,我们选择了 Redis。相较于 OceanBase 或 TiKV 等复杂元数据管理引擎,我们选择 redis 主要出于以下考虑:我们仅将其用于大文件的存储,而每个文件的大小可能达到数 GB。因此,我们判断其数据量相对较小,无需采用复杂的元数据管理引擎,以减轻运维负担。
推理场景中模型仓库读写设计: 多云推理
与训练场景不同,推理资源通常分布在多云平台上,如阿里云、腾讯云等。在这些云平台上,我们不会购买大量的 NVMe 机器,因为云上本身具备对象存储能力。因此,我们采用了 JuiceFS 的经典模式,即 JuiceFS 加上 Redis,与云厂商的对象存储组成一个集群。在推理过程中,模型文件以只读方式挂载,以避免程序对其进行修改。此外,我们还设计了一个面向多云环境的间歇性同步方案,以确保模型能够同步到所有云的 JuiceFS 上。
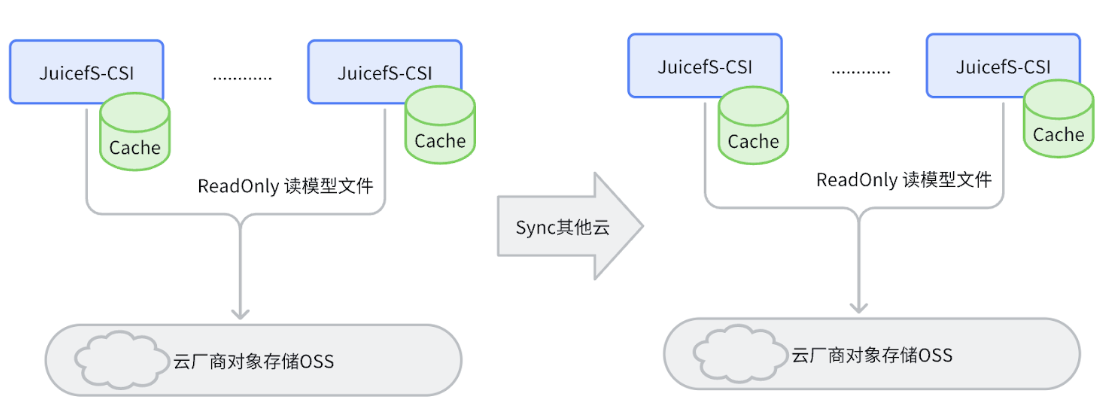
在面对某些挑战时,当需要在白天大规模扩容推理服务时,以扩容 HPA(Horizontal Pod Autoscaler)为例,这种定点扩容会导致大量推理服务同时启动,并需要迅速读取大量的模型文件。这种情况下,如果没有本地缓存的支持,带宽消耗将极为巨大。
为了应对这一挑战,我们采用了 “warm up” 策略。即在定时扩容之前,通过预热的方式将即将被读取的模型文件预先加载到缓存中。这样做可以显著提升扩容的弹性速度,确保推理服务能够迅速启动并投入运行。
管理端:模型仓库上传与下载的设计
管理端主要聚焦于上传和下载功能。我们自主开发了一个客户端,该客户端支持通过 S3 协议上传模型文件。S3 网关会接收并转化这些请求,然后与元数据系统进行交互,如 Redis 等。
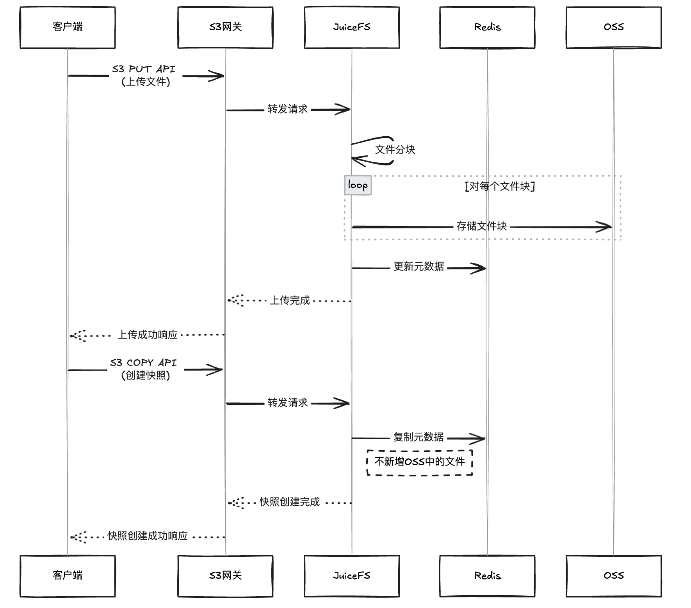
在我们的应用场景中,还有一项重要的设计是对相同文件进行去重处理。我们采用了类似于 Docker 镜像仓库的设计思路,即为每个文件计算 MD5 值。如果两个文件的 MD5 值相同,则不会进行重复上传。这一设计不仅节省了存储空间,还提高了上传效率。
此外,在更新模型时,我们还会保留一些快照。使用 JuiceFS 快照功能复制文件时,它并不会在 OSS 中新增文件,而只是在元数据中进行记录。这种方式使得我们在进行模型更新和快照保留时更加便捷高效。
04 未来展望
按需同步多云的模型仓库:我们目前的做法是采取定期批量同步的方式,将 JuiceFS 在某个云上的集群数据进行同步。然而,这种做法相对简单粗暴,可能无法满足未来对于数据同步的更高需求。因此,我们计划进行改进,实现一个标记型的同步系统。该系统将能够识别需要同步的区域,并在收到模型上传事件后,自动将这些数据同步到多云平台上。此外,我们还将引入一些 warm up 策略,以优化数据同步的过程,提高同步效率和准确性。
扩展单机 cache 和分布式 cache:我们目前单机使用了3T MVME的 cache 方式,在短期内来看,这种方式的容量还是相对充足的。然而,从长远来看,为了满足更大的数据存储和访问需求,我们将基于一致性哈希的原理,在客户端自主研发一个分布式 cache 组件。这个组件将能够更大程度地提升开启的容量和命中率,从而满足未来对于数据存储和访问的更高要求。
