














中科院计算所在建设大模型训练与推理平台过程中,模型规模与数据集数量呈爆发式增长。最初采用简单的裸机存储方案,但很快面临数据孤岛、重复冗余、管理混乱和资源利用不均等问题,于是升级到了 NFS 系统。然而,随着使用强度增加,NFS 的瓶颈日益凸显:高峰期训练任务严重延迟甚至完全停滞,多用户并发时系统性能断崖式下降,存储扩容困难且缺乏有效的数据一致性保障。这些问题严重影响到了实验室研究人员的使用,迫使我们寻求更先进的存储方案。
经过对多种开源存储系统的评估对比,我们选择了 JuiceFS 。我们的架构采用 Redis 进行高性能元数据管理,同时构建了自有 MinIO 集群作为底层对象存储,这一架构完美解决了模型训练场景中的数据读写瓶颈、元数据访问延迟以及计算资源之间的存储互通问题。
01 大模型训推平台存储需求
我们的平台是面向实验室内部的大模型训练与推理一体化平台,核心功能聚焦于模型、数据集和用户代码的统一管理。在资源调度方面,平台通过 Kubernetes 对实验室内所有服务器的计算资源进行集中管理与分配,提升整体算力利用效率。同时,平台还提供模型相关的服务能力,如内置模型评估列表,并支持将模型一键部署为应用服务,方便实验室内的师生共享与调用。
首先,平台需具备存储模型文件与数据集文件的基础功能。在此基础上,我们更期望能实现模型文件与数据集文件的快速使用。在项目初期,我们曾采用一种尚不成熟的方案,即在启动容器(Pod)时,通过克隆方式将模型文件复制到容器内以启动容器。然而,由于平台主要面向大模型存储,模型文件体积庞大,导致该流程效率低下。
其二,支持 Container Storage Interface(CSI),平台底层采用 K8s 架构,若缺乏 CSI 支持,诸多 K8s 特性将无法使用,可能引发运维难题,甚至需要额外进行配置工作
此外,平台还需支持 POSIX 协议。目前,多数深度学习处理框架,如 Transformer 和 TensorFlow,均基于 POSIX 协议构建。若平台不支持该协议,则需自行实现存储协议层,这将增加开发复杂度与工作量。
最后,存储配额管理。实验室的存储资源有限,若不对用户存储进行限制,单个用户可能过度占用存储空间,导致资源迅速耗尽。同时,缺乏配额管理也将影响对未来存储需求的准确评估与合理规划。
02 平台存储面临的挑战及优化历程
早期存储架构及问题
项目初期,鉴于底层采用 K8s 架构,存储版本管理借鉴了 Hugging Face 的模式,选用 Git 进行管理,涵盖分支与版本控制。然而,实践过程中发现,该方案存在明显弊端。实验室的学生与教师群体,尤其是学生,对 Git 操作不够熟悉,导致使用过程中问题频发。

在存储架构设计上,最初采用了极为简单的方案:启动 Pod 时挂载本地磁盘,通过 K8s PVC 实现磁盘挂载。此方案的优势在于速度快,但缺陷同样突出。由于众多同学同时使用,Pod 可能分布于不同节点,每个节点均需同步模型文件,造成大量资源浪费。
NFS 方案尝试及局限
为解决上述问题,我们引入了 Network File System(NFS)替代纯硬盘方案。NFS 作为成熟方案,具有搭建简便的优点,尤其契合实验室运营团队规模较小的实际情况。同时,NFS 获得了官方 K8s CSI 的支持,进一步提升了其吸引力。
在项目初期,NFS 方案表现尚可。当时平台仅在组内小范围使用,用户数量少,训练与微调任务不多,模型数据量也有限。但随着项目逐步完善,进入全实验室内测阶段,用户数量激增,模型与数据量大幅增加,NFS 方案的局限性逐渐显现。
一方面,大模型文件数量增多,磁盘占用率持续攀升。由于采用本地磁盘,扩容操作繁琐复杂。另一方面,使用 NFS 需自行管理存储,增加了管理难度。更为关键的是,随着用户数量的增加,性能瓶颈问题凸显,模型训练与推理速度显著变慢。例如,原本仅需几十小时即可完成的模型训练任务,在用户数量增多后,耗时大幅延长,甚至出现一个周末过去仍未训练完成的情况。
此外,NFS 缺乏分布式支持,也未找到理想的分布式解决方案。若强行实现,只能复制 NFS 实例,这不仅无法解决单点故障问题,反而可能因服务器宕机导致整个集群存储瘫痪。
03 JuiceFS 方案引入及优势
为解决上述问题,我们对 JuiceFS 进行了深入调研,并最终选定其作为新的存储方案。JuiceFS 采用数据与元数据分离存储的架构。文件数据本身会被切分保存在对象存储,而元数据则可以保存在 Redis、MySQL、TiKV、SQLite 等多种数据库中,用户可以根据场景与性能要求进行选择。
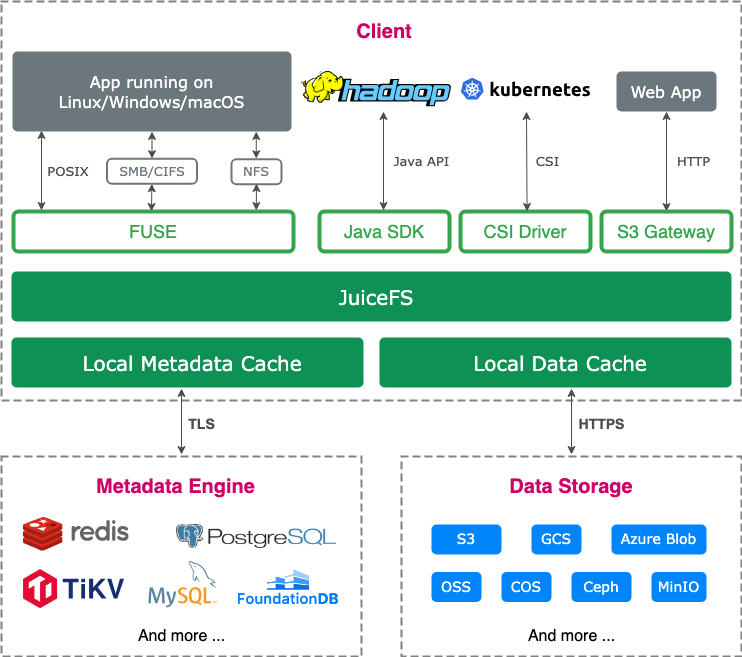
在底层对象存储选择上,实验室内部此前已搭建了 MinIO 集群,且运维团队对 MinIO 较为熟悉,因此未进行过多调研,便直接采用。同时,考虑到 Redis 搭建便捷且实验室内部已有 Redis 集群,可直接复用,故选用 Redis 作为元数据引擎。

然而,在后续使用过程中,我们发现自行维护对象存储面临诸多困难。运维团队在存储管理方面经验不足,导致各类问题频发。鉴于此,我们计划在未来对存储架构进行优化升级:将自行搭建的 MinIO 集群替换为商业对象存储服务,以提升存储的稳定性与可靠性;将 Redis 升级为 TiKV,以增强分布式存储能力与性能表现。
JuiceFS 的优势
我们之所以选择 JuiceFS,主要基于以下几个关键因素:
- 高性能与弹性存储:这是我们极为看重的一点。高性能存储能够显著提升模型的推理与训练速度,从而优化整体业务处理效率,满足平台对高效运算的需求。
- 简单易用与分布式架构:JuiceFS 使用简便,降低了使用门槛与运维复杂度。作为分布式文件系统,它有效规避了单点故障风险,保障了存储系统的稳定性和可靠性,为业务连续性提供了有力支撑。
- K8s 支持:与底层 K8s 架构深度兼容,便于在容器化环境中进行部署与管理,提升了资源调度与应用的灵活性。
- POSIX 支持:遵循 POSIX 协议,与大多数深度学习框架(如 Transformer、TensorFlow 等)无缝适配,避免了协议层面的适配难题,简化了开发流程。
- 配额管理:提供精细化的存储配额管理功能,可对用户存储空间进行合理限制,防止个别用户过度占用存储资源,保障了存储资源的公平分配与有效利用。
JuiceFS 的实用功能
在 JuiceFS 的实际使用过程中,我们发现了诸多超出预期的实用功能,为平台运营与用户体验带来了显著提升:
- 缓存预热功能:在部署阶段,我们利用 JuiceFS 的缓存预热功能,将常用的大模型数据提前加载到常用计算节点的缓存中。如此一来,当同学使用这些计算节点进行模型推理或训练时,能够直接从缓存中快速读取数据,大幅缩短数据加载时间,显著提升任务执行效率。
- 快速克隆功能:JuiceFS 支持通过元数据克隆实现快速数据复制。鉴于我们内部存在将存储在文件系统中的文件克隆到实际存储的同步机制,该功能有效满足了快速数据复制的需求,提高了数据同步效率,降低了数据迁移成本。
- 与 Prometheus 和 Grafana 的监控集成:JuiceFS 具备与 Prometheus 和 Grafana 监控系统的集成能力,使我们能够轻松将其接入现有的监控体系。通过统一的监控平台,我们可以实时、全面地掌握存储系统的运行状态、性能指标等关键信息,便于及时发现并解决潜在问题,保障系统稳定运行。
- 回收站功能:以往使用 NFS 时,曾出现学生误删工作代码且因未做异步备份而无法找回的尴尬情况。JuiceFS 的回收站功能有效解决了这一问题,当用户误删文件时,文件会暂时存放在回收站中,在一定时间内可进行恢复操作,避免了因误删导致的数据丢失风险,保障了用户数据的安全性与完整性。
- 控制台功能:JuiceFS 控制台提供了对所有区域中与 JuiceFS 相关的 PV(持久化卷)和 PVC(持久化卷声明)的集中管理功能。通过控制台,运维人员可以方便地查看、监控和管理存储资源,简化了运维流程,提高了管理效率。
- SDK 支持:早在 JuiceFS SDK 商业版上线之初,我们便予以关注。后续,我们计划针对 SDK 开展相关尝试,探索其在业务场景中的更多应用可能性,以进一步挖掘 JuiceFS 的潜力,为平台发展注入新的动力。
JuiceFS 部署实践
在开发环境中,我们采用 Helm 进行 JuiceFS 的部署。Helm 的部署方式极为简便,仅需修改 values.yaml 配置文件,即可实现一键部署,且在部署过程中基本未遭遇明显阻碍。
不过,在部署过程中仍遇到一个小问题。由于实验室内部服务器集群处于内网环境,禁止直接连接外网,我们搭建了内网镜像仓库用于存储 JuiceFS 镜像。然而,在修改 values.yaml 文件后进行部署时,发现部署失败。经排查,系统在尝试拉取 juicefs.mount 镜像文件时出现问题,推测此镜像拉取需要额外配置。随后,我们在官方配置文档中找到定制化镜像的相关说明,通过使用定制化镜像成功解决了部署问题。
使用 JuiceFS 的收益
缓存与模型预热 为加速模型推理过程,我们启用了 JuiceFS 的缓存和模型预热功能。在模型推理任务执行前,提前将相关数据预热至缓存中。当实际推理任务启动时,系统可直接从缓存中读取数据,避免了频繁从底层存储读取数据带来的性能损耗,显著提升了推理效率。
目录配额管理 我们为实验室的每位学生和教师分配了独立的目录配额。通过这种精细化的配额管理,有效控制了每个账号的存储资源使用量,防止个别用户过度占用存储空间,确保了存储资源的公平分配与合理利用。同时,基于目录配额,我们计划在内部构建类似于算力资源的计费体系,依据用户对存储资源的占用情况进行费用核算,以实现资源的精细化管理。
只读模式设置 对于部分官方模型文件,为保障其完整性与安全性,我们设置了只读模式。在该模式下,学生无法对这些模型文件进行修改操作,避免了因误操作或恶意修改导致模型文件损坏或数据泄露的风险。
控制台功能启用 启用 JuiceFS 控制台后,运维人员能够实时监控训练过程中所有 PV(持久化卷)和 PVC(持久化卷声明)的状态。通过控制台,运维人员可以直观地查看存储资源的使用情况、性能指标等信息,及时发现并解决潜在问题,为存储系统的稳定运行提供了有力保障。
动态配置与存储细分 在存储架构设计上,我们首先挂载一个大的动态存储卷,然后在底层将其细分至每个学生和教师。这种动态配置方式能够根据实际需求灵活分配存储资源,提高了存储资源的利用率,同时也便于对不同用户的存储使用情况进行独立管理和监控。
04 未来展望
当前存储架构中,底层采用对象存储,并划分为两个 S3 桶:S3 桶 1 和 S3 桶 2。其中,git 和 git lfs 文件存储在 S3 桶 1 中。JuiceFS 会定期从 S3 桶 1 同步文件,以确保数据的实时性和一致性。
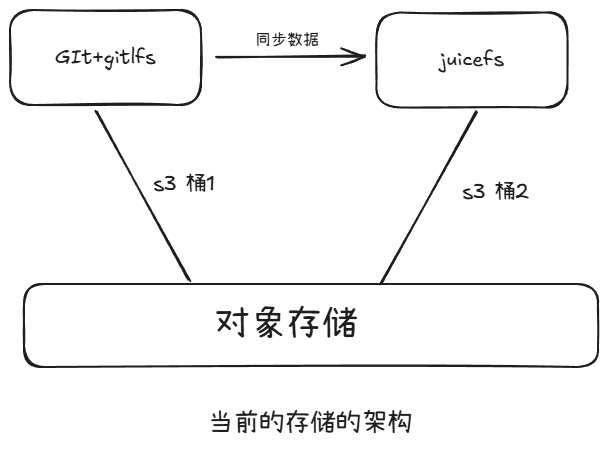
这样的架构我们也是遇到了一些问题:
- 存储冗余:由于采用上述同步机制,同一个大文件可能会在存储系统中保存两份,导致存储空间被大量占用,增加了存储成本。
- Git 仓库可拓展性弱:实验室使用的开源 GitLab 仓库在可拓展性方面存在不足。例如,在创建 Git 用户时,不仅需要在自身的用户表中创建用户信息,还需在开源 GitLab 中再次创建用户,操作流程繁琐,增加了管理成本。
- 大文件同步效率低:以往架构中,JuiceFS 从 Git 仓库同步大文件时采用 git 克隆方式,这种方式在处理大模型文件时效率极低,导致同步过程缓慢,影响了整体业务处理效率。
未来我们准备去做一些优化以解决上述问题和优化我们的平台使用:
优化文件同步机制 针对大文件同步效率低的问题,我们计划对开源 Git 服务端进行自定义开发,构建一个统一的文件处理中间层。在该中间层中,利用 JuiceFS 的元数据克隆功能实现文件同步。相较于传统的 git 克隆方式,元数据克隆能够显著提高同步速度,快速完成模型文件的同步任务,提升整体业务流程的效率。
SDK 定制开发 为进一步提升用户体验,我们计划对 SDK 进行定制开发,重点针对 Git 客户端或 Transformer 库进行优化。通过集成 JuiceFS 的快速克隆功能,使实验室的老师和同学即便使用自有计算资源,也能够快速在自己的机器上获取并使用模型文件和数据集文件。
增强权限管理功能 目前,社区版 JuiceFS 似乎不支持存储文件的权限管理。为满足实验室对数据安全和管理的严格要求,我们希望在未来能够对 JuiceFS 进行二次开发,实现更完善的权限管理功能。通过精细化的权限控制,确保不同用户对存储资源的访问和操作符合其权限范围,保障数据的安全性和隐私性。
