














在早期阶段,vivo AI 计算平台使用 GlusterFS 作为底层存储基座。随着数据规模的扩大和多种业务场景的接入,开始出现性能、维护等问题。为此,vivo 转而采用了自研的轩辕文件系统,该系统是基于 JuiceFS 开源版本开发的一款分布式文件存储方案。
本文将介绍 vivo 轩辕文件系统在 JuiceFS 基础之上开发的新特性。以及 vivo 针对一些关键场景,如样本数据读取速度慢和检查点写入环节的优化措施。此外,文章还将介绍 vivo 的技术规划包括 FUSE、 元数据引擎及 RDMA 通信等方面,希望能为在大规模 AI 场景使用 JuiceFS 的用户提供参考与启发。01 计算平台引入轩辕文件存储的背景
01 计算平台引入轩辕文件存储的背景
最初,vivo 的 AI 计算平台 使用 GlusterFS ,并由该团队自行维护。在使用过程中,团队遇到了一些问题。一是处理小文件时速度变得非常缓慢;二是当需要对 GlusterFS 进行机器扩容和数据平衡时,对业务产生了较大的影响。
随后,由于早期集群容量已满且未进行扩容,计算团队选择搭建了新的集群。然而,这导致了多个集群需要维护,从而增加了管理的复杂度。此外,作为平台方,他们在存储方面的投入人力有限,因此难以进行新特性开发。
他们了解到我们互联网部门正在研发文件存储解决方案,经过深入交流和测试。最终,他们决定将其数据存储迁移至我们的轩辕文件存储系统。
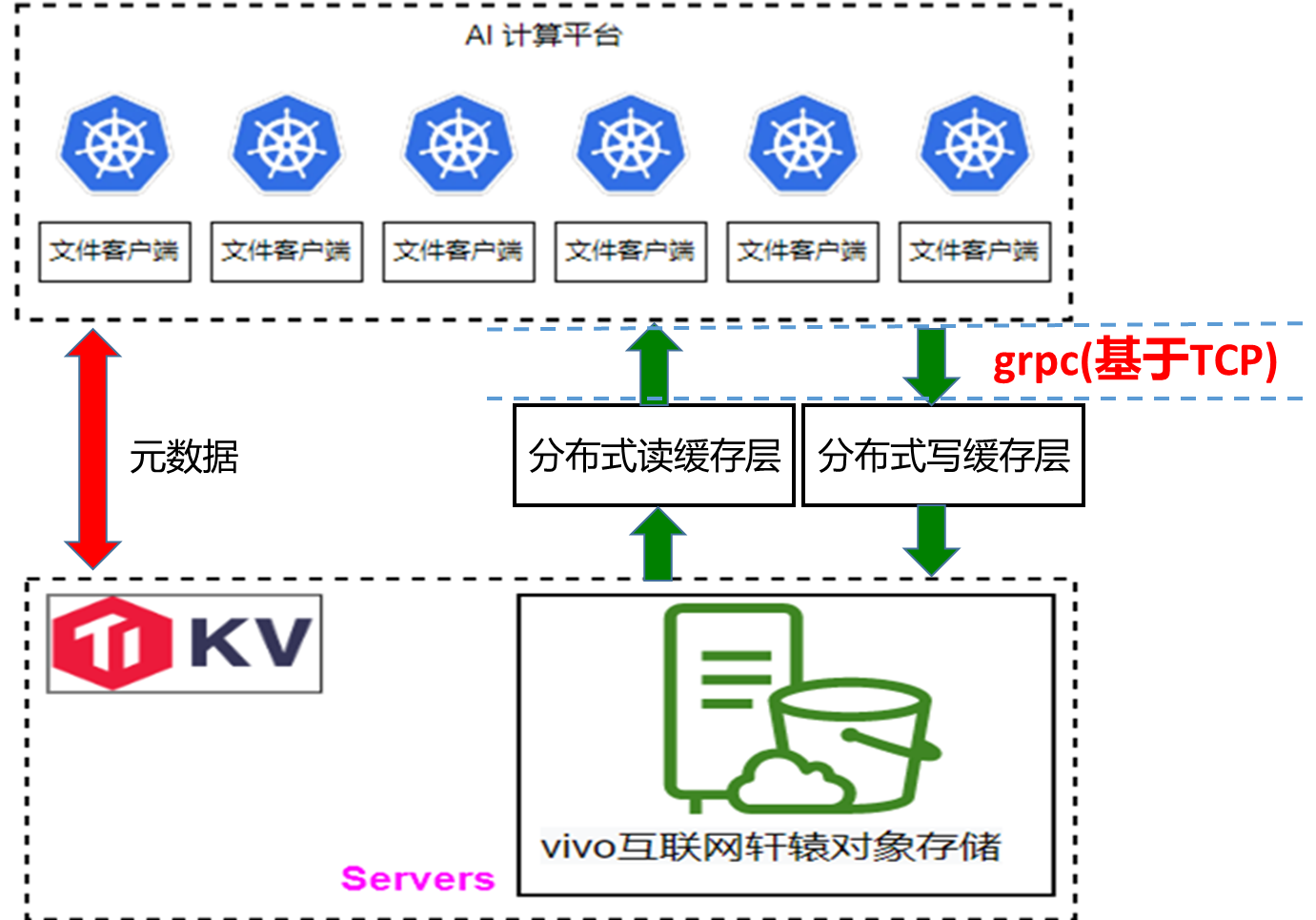
轩辕文件系统基于 JuiceFS 开源版,进行了二次开发,支持多种标准访问协议,包括 POSIX、HDFS 以及 Windows 上的 CIFS 协议。此外,我们还提供了文件恢复功能,该功能参考了商用解决方案,能够按照原路径进行数据恢复。
同时,我们的系统支持客户端热升级,这一功能在开源版本中也已经实现。另外,我们还支持用户名权限管理,默认使用本地 uid/gid 进行鉴权。在此基础上,我们还参考 JuiceFS 企业版实现了用户名鉴权功能。
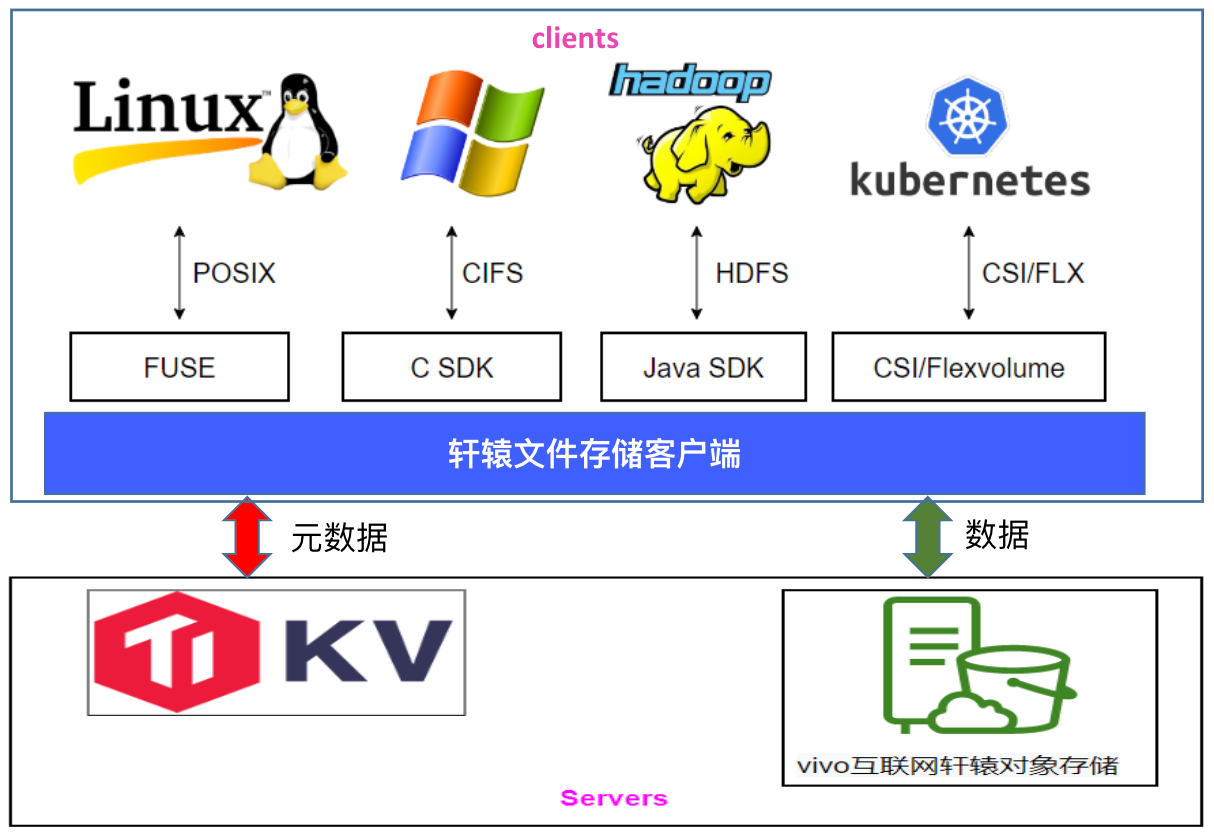
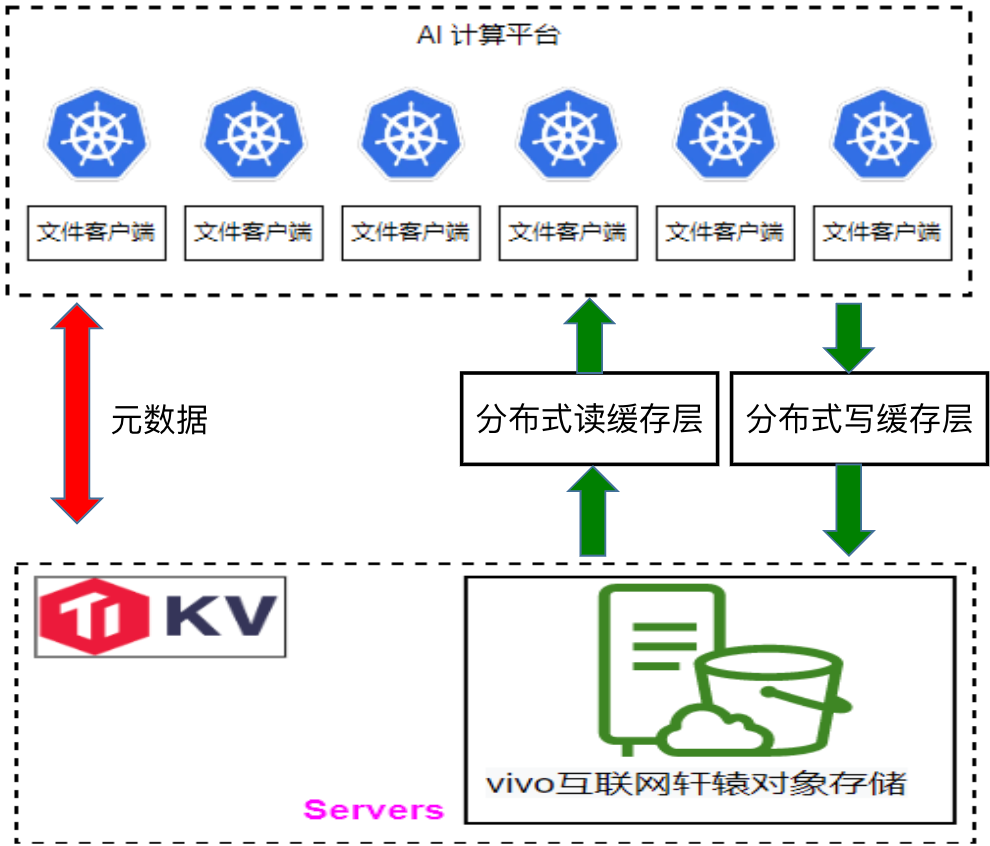
下图是轩辕文件系统的架构图,与 JuiceFS 类似。在底层基座方面,我们使用 TikV 存储元数据,而数据则存储在我们自研的对象存储系统中。特别值得一提的是,在 Windows 场景下,我们在 Samba 中开发了一个插件,该插件直接调用 JuiceFS API,从而为用户提供了一个在 Windows 上访问我们文件存储的通道。
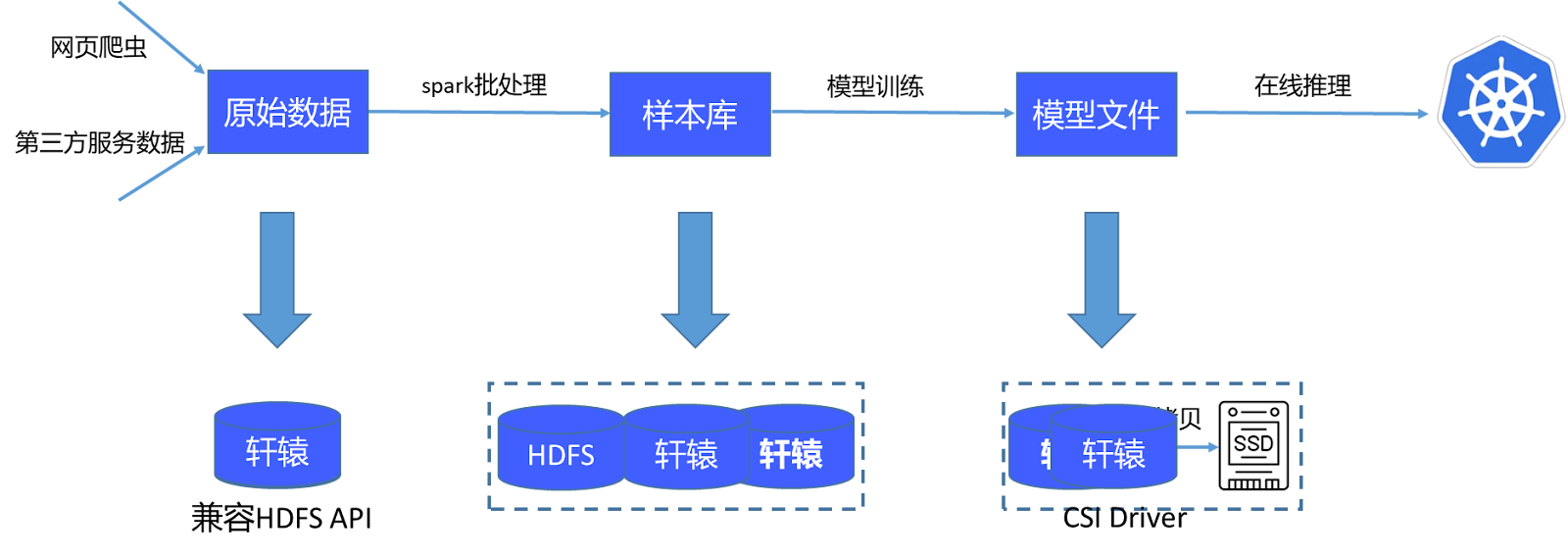
目前的 AI 计算平台存储流程如下:首先获取原始数据并通过一个包含 4 万个批处理任务的系统进行处理,生成样本库。这些样本库随后在 GPU 上训练,产生模型文件,这些模型文件被传输至在线系统用于推理。原始数据及处理后的样本库直接存储在轩辕文件系统中,由于其兼容 HDFS API,Spark 可以直接处理这些数据。模型文件也保存在轩辕中,并通过其提供的CSI插件,使在线推理系统能直接挂载并读取这些文件。
02 存储性能优化
训练阶段涉及存储的主要有两个重要方面:样本读和训练过程中的检查点( checkpoint) 保存。

环节1:加速样本读
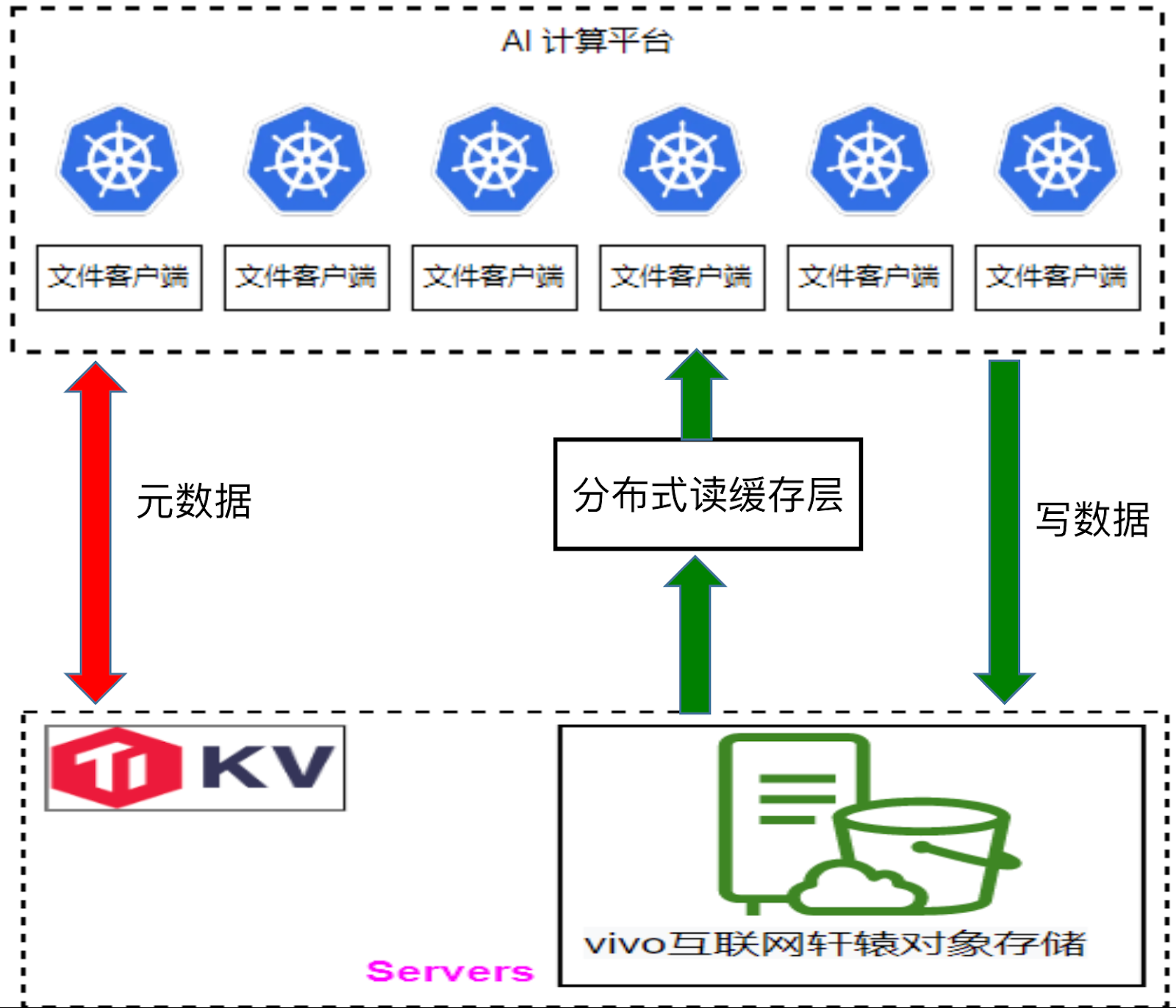
为了提升样本加载的速度,我们开发了一个分布式读缓存层。在训练模型前,我们借助JuiceFS 提供的 warm up 功能,优先将本次训练所需的数据预加载至读缓存层。通过这种方式,训练数据可以直接从读缓存层获取,而无需从对象存储系统中拉取。通常情况下,直接从对象存储中读取数据需要花费十几至几十毫秒,但通过读缓存层则可将读取时间缩短至 10 毫秒以内,从而进显著提高了数据加载到 GPU的 速度。
环节2:检查点 (Checkpoint) 写入
在检查点写入方面,我们参考了百度的方案。具体而言,检查点数据首先被写入一个临时缓存区域(我们称之为“协管”区域,但此处可能指的是某种形式的中间缓存或暂存区),然后再逐步刷新到对象存储中。在这个过程中,我们也采用了单副本模式,因为检查点本身就是每隔一段时间保存的,即使某个时间段的检查点丢失,对整体训练的影响也是有限的。当然,我们也制定了一些策略来确保关键数据的安全性,并非所有数据都会进入这个中间缓存区域。通常,只有检查点文件和训练阶段的日志文件会被写入。如果训练中断,检查点文件可以从这个中间缓存区域中读取。
此外,当数据被写入并刷新到对象存储中时,我们并不会立即从检查点缓存中清除这些数据。因为训练过程中随时可能中断,如果此时检查点缓存中的数据被清除,而需要从对象存储中重新拉取,将会耗费较长时间。因此,我们设置了一个 TTL(生存时间)机制。例如,如果检查点数据每小时刷新一次到对象存储中,我们可以将 TTL 设置为 1.5 小时。这样,即使训练中断,我们也能确保检查点缓存中有一个最新的备份可供使用。
在开发写缓存的过程中,我们遇到了一个挑战。由于我们的客户端与写缓存之间的通信采用 gRPC 协议,该协议在数据反序列化时会重新申请内存以存储解析后的数据。在特定时间段内,如果写操作非常集中(例如在几十秒内),会导致大量的内存申请和释放。由于我们使用的是 Go 语言开发,其垃圾回收(GC)机制在这种情况下表现较慢,可能会导致写缓存的内存耗尽。
为了解决这个问题,我们调研了其他数据反序列化的方案。最终,我们采用了 Facebook 的 flatterbuffer 方案。与 gRPC 的 Pb 反序列化不同,flatterbuffer 在反序列化后可以直接使用数据,无需额外的解析步骤。通过这种方式,我们减少了内存的使用,与 Pb 相比,内存节省达到了 50%。同时,我们也对写性能进行了测试,发现使用 flatterbuffer 后,写性能提升了20%
环节3:在线推理,模型加载流量大
在用户进行在线推理时,我们注意到模型下载产生的流量极大,有时甚至会占满对象存储网关的带宽。深入分析这个场景后,我们发现存在众多实例,每个实例都会独立地将完整模型加载到内存中,并且这些实例几乎是同时开始加载模型的,这一行为造成了巨大的流量压力。
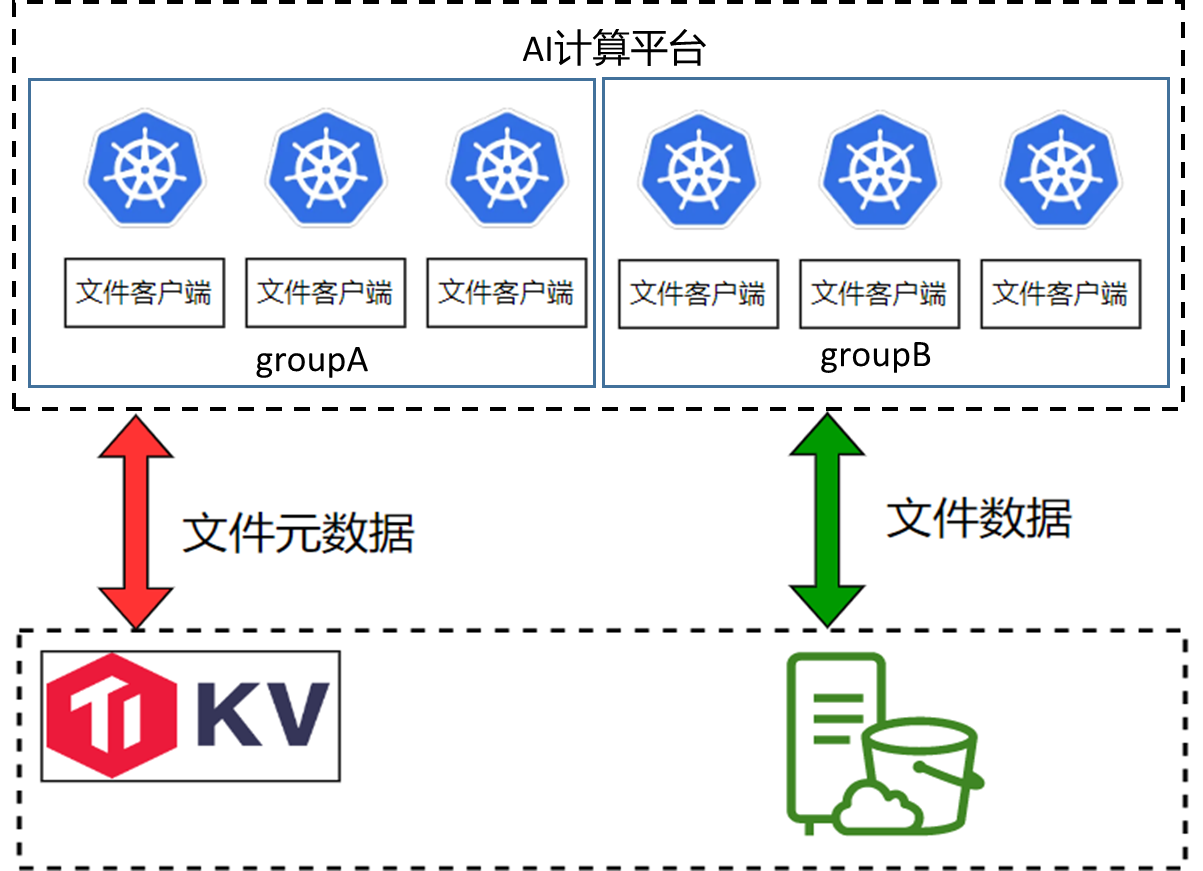
为解决此问题,我们借鉴了商业解决方案,采用了在 Pod 中实施逻辑分组的方法。在这种策略下,每个分组仅从底层存储读取一份完整模型,而分组内的各个节点则读取模型的部分文件,并通过节点间的数据共享(类似于 P2P 方式)来减少总体流量需求。这种方法显著降低了对底层对象存储带宽的占用,有效缓解了流量压力。
03 技术规划
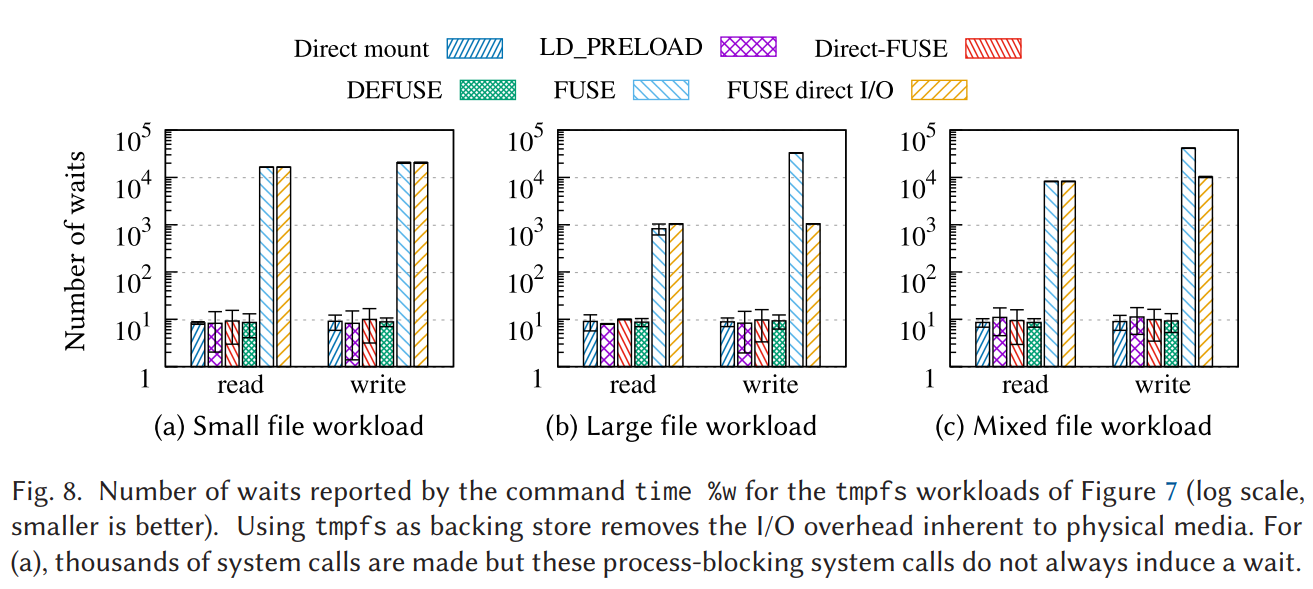
libc 调用绕过 FUSE 内核,提升读写性能 下面这份图表来源于 ACM 期刊中的一篇论文。文中指出,在使用 FUSE 挂载时,请求的处理流程会先从用户态转移到内核态,然后再返回用户态。在这个流程中,上下文切换所带来的消耗是相当巨大的。
柱状图较高的部分代表原生的 FUSE,而柱状图较低的部分则代表经过优化的方案。
- 小文件场景:原生的 FUSE 相较于优化方案,其上下文次数切换的数量差距达到了 1000 倍;
- 大文件场景:原生的 FUSE 与优化方案之间的上下文次数切换的数量差距约为 100 倍;
- 混合负载场景:同样显示出了巨大的上下文次数切换的数量差异。
在论文中提到,链路消耗的主要来源是上下文切换。因此,我们计划在 FUSE 这一层进行优化,主要针对元数据和小文件场景。目前,我们正在进行方案选型工作。
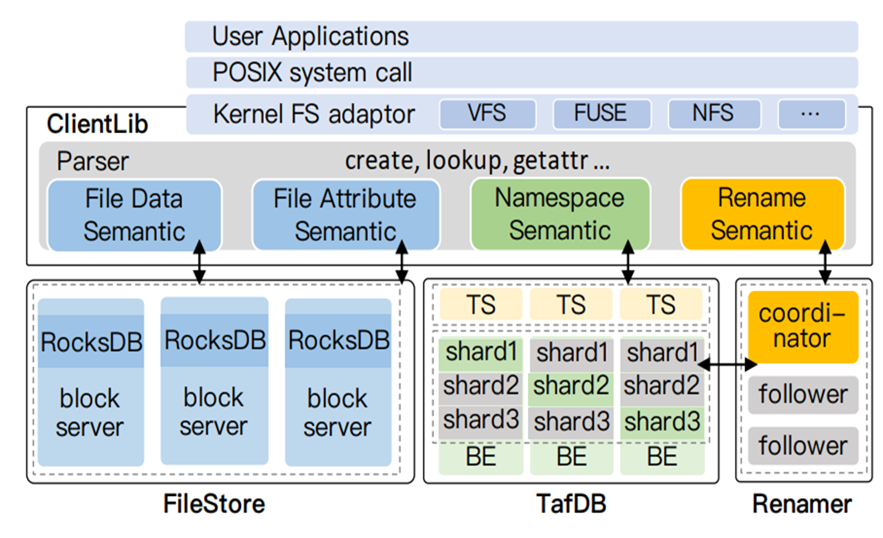
自研元数据引擎,文件语义下沉
我们还计划开发一个自己的元数据引擎。当前,我们使用的元数据引擎是基于 TiKV 的,但 TiKV 并不具备文件语义,所有的文件语义都是在客户端实现的。这给我们的特性开发工作带来了极大的不便。
同时,当多个节点同时写入一个 key 时,事务冲突也会非常频繁。近期,我们还遇到了进程会突然卡住的问题,持续时间从几分钟到十几分钟不等。这个问题一直未能得到解决。
另外,TiKV PD 组件为主节点 Active 模式,请求上 10 万后,时延上升明显,PD 节点(112核)CPU 使用率接近饱和。因此,我们正在尝试一些方案来降低主节点的 CPU 利用率,以观察是否能改善耗时问题。我们参考了一些论文,如百度的 CFS 论文,将所有的元数据操作尽量变成单机事务,以减少分布式事务的开销。
缓存层实现 RDMA
通信关于我们机房的 GPU 节点,它们目前使用的是 RDMA 网络。与缓存层的通信仍然使用 TCP 协议。我们有规划开发一个基于 RDMA 的通信方式,以实现客户端与缓存之间的低延迟、低 CPU 消耗的通信。
通过观察客户端的火焰图,我们发现 RPC 通信的耗时仍然非常明显。虽然写缓存的处理数据只需要一两毫秒,但客户端将数据上传到整个链路的耗时可能达到五六毫秒,甚至十毫秒。在客户端 CPU 非常繁忙的情况下,这个时间可能会达到二三十毫秒。而 RDMA 本身并不怎么消耗 CPU,内存消耗也比较少,因此我们认为这是一个值得尝试的解决方案。
