














在上篇文章 《OSS太慢?看我们怎么提速10倍!》中提到,JuiceFS 可以提高 OSS 在大数据场景下的性能 10 倍,当时有朋友在朋友圈建议我们用 JuiceFS 和类似的对象存储加速方案做一下比较。在花了一个月时间准备之后,有一些阶段性成果跟大家分享一下。
调查了常见的对象存储加速方案后,选择了另外 2 种方案与 JuiceFS 做对比。分别是阿里 EMR 的 JindoFS 和某开源缓存系统·( 下文简称 A-FS)。 其中 JindoFS 和 JuiceFS 为了提高性能,均可以自己管理文件格式,将文件重新切分后存储于 OSS 上,JindoFS 是 block 模式,JuiceFS 是优化模式。缓存 A-FS 直接是将文件存储在 OSS 上。
那么这 3 种方案的具体效果怎么样呢?本文就基于 TPC-DS 测试来比较一下。
测试环境
由于 JindoFS 是 EMR 的内部服务,还没找到在外部集群部署它的方法,因此选择了 阿里云 EMR-3.28.0 为基础环境,在其中部署其他两个缓存系统。JindoFS、A-FS 和 JuiceFS 的元数据均使用 HA 方案部署。详细的集群配置、软件版本和配置参数,附在本文的最后。
元数据性能
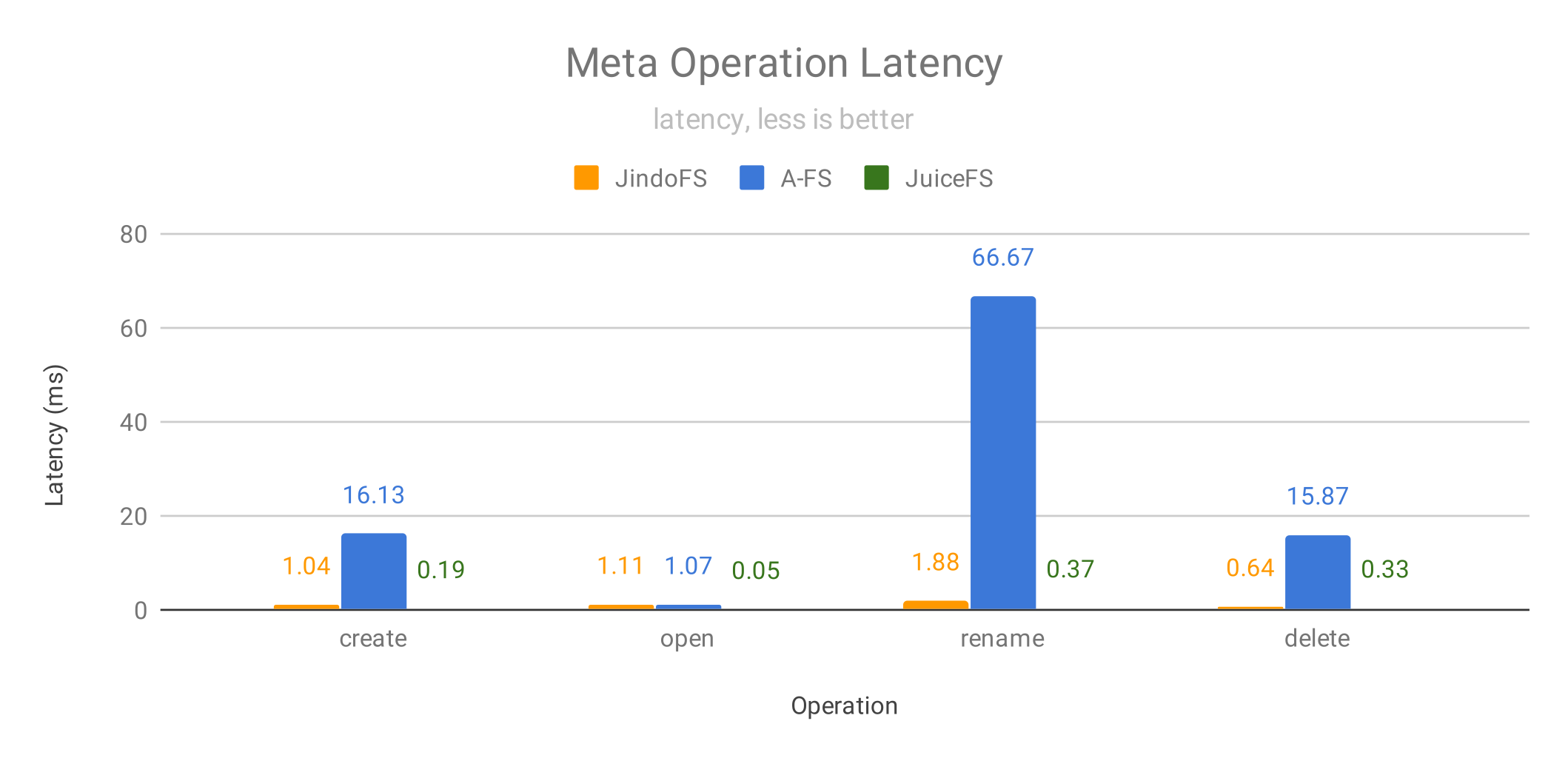
在文件的元数据操作上,由于 JindoFS 和 JuiceFS 均使用独立元数据管理,不需要和 OSS 同步,所以性能均远超 A-FS 。JuiceFS 又比 JindoFS 领先很多,尤其在 open 文件上,这得益于文件的元数据缓存。
缓存全部数据
此测试所用的缓存盘为 ESSD 云盘。盘总容量足够缓存下所有数据,先看一下在数据完全缓存在磁盘上的表现。下图是在缓存空间足够,所有查询跑 3 遍的结果。
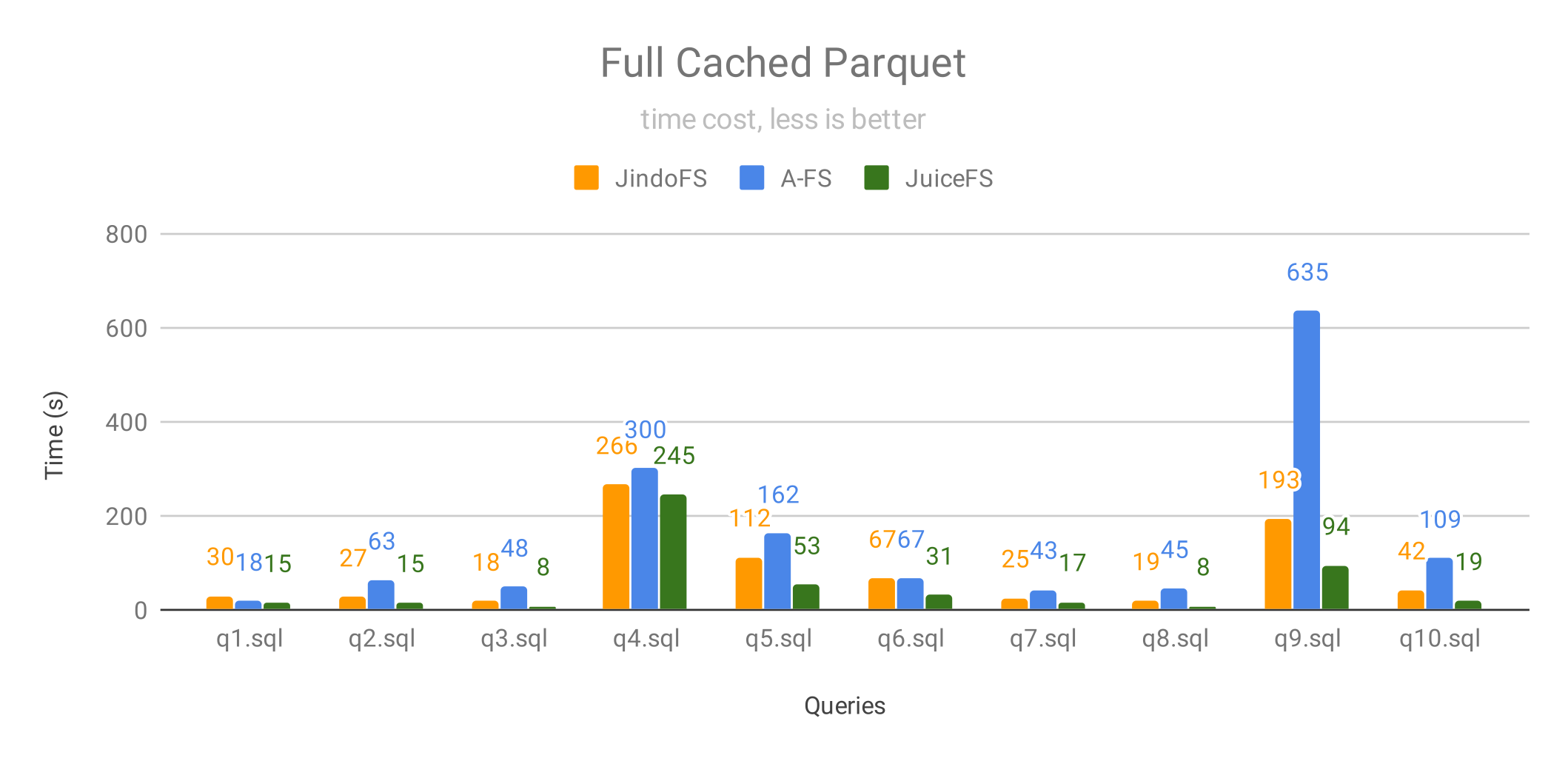
当全部 Parquet 格式的数据都被缓存到 ESSD 云盘时,JuiceFS 在所有测试中都是最快的,其中:
- 70% 的查询 JuiceFS 的性能是 JindoFS 的 2 倍以上;
- 40% 的查询 JuiceFS 的性能是 A-FS 的 5 倍以上,40% 的查询性能是 A-FS 的 2~5倍。
缓存部分数据(模拟真实场景)
在生产环境中,受限于成本等因素,很难将所有数据完全缓存在磁盘上。为了更好的模拟真实生产环境,我们将缓存大小统一设置为总共 30G,每个 worker 节点 10G,理论上最多能缓存 30% 的 Text,85% 的 Parquet,100% 的 ORC。A-FS 另外还可以设置内存缓存,为了更好的模拟真实场景,将内存缓存设置为磁盘缓存的 10%,即每个 worker 节点 1G 内存缓存。此外,这三者都能够利用操作系统的剩余内存作为磁盘上数据的系统缓存。
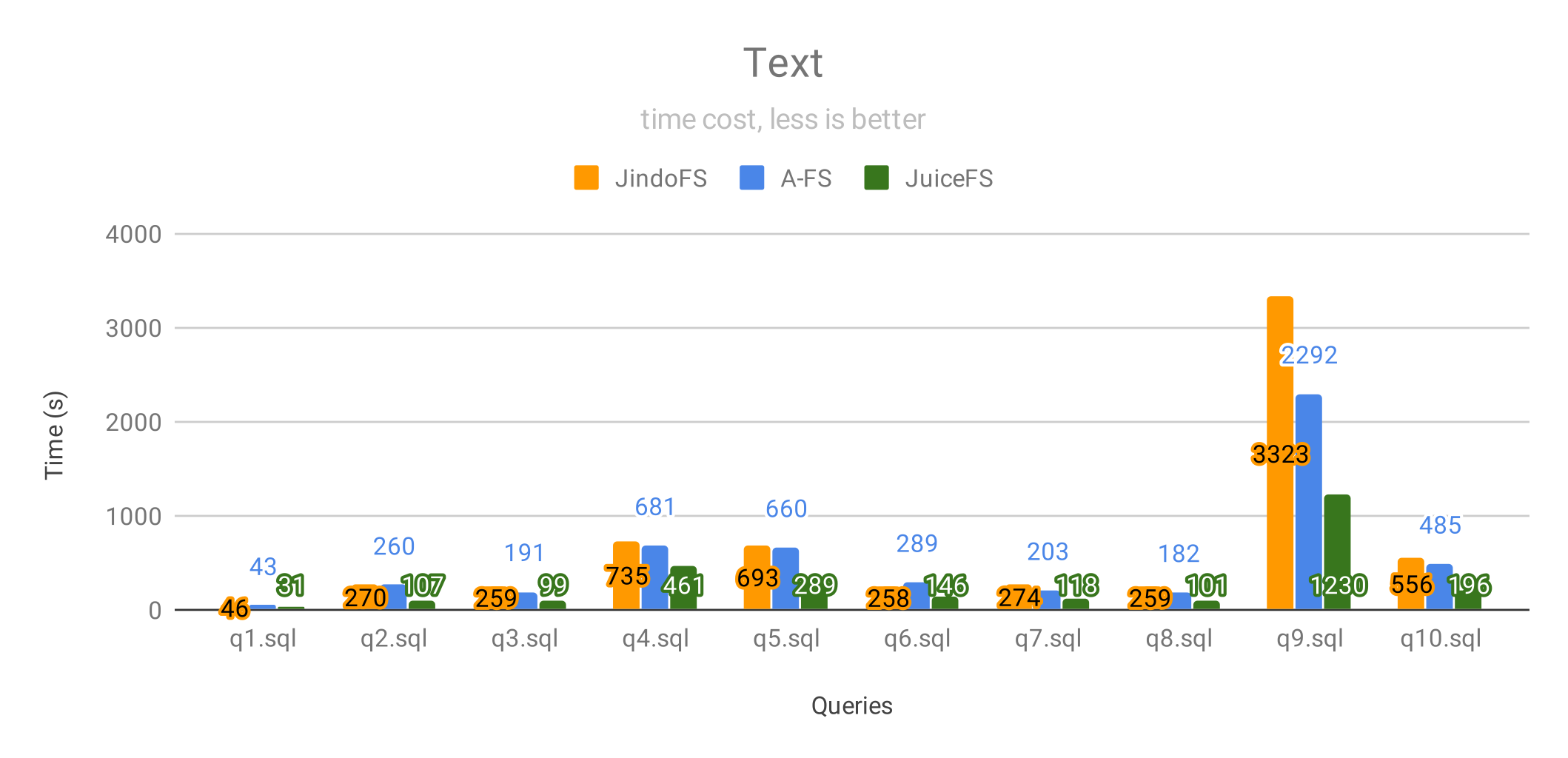
以上是查询文本格式数据的结果,JuiceFS 依然是所有测试中性能最好的,其中:
- 70% 的查询 JuiceFS 的性能是 JindoFS 的 2 倍以上;
- 40% 的查询 JuiceFS 的性能是 A-FS 的 2 倍以上。
JuiceFS 能够更快地加速文本数据的访问,是因为:
- JuiceFS 对顺序读做了大量优化,能够更智能地从 OSS 预加载数据;
- JuiceFS 能够高效地压缩文本数据,节省带宽(此处测试使用 LZ4 压缩算法)。
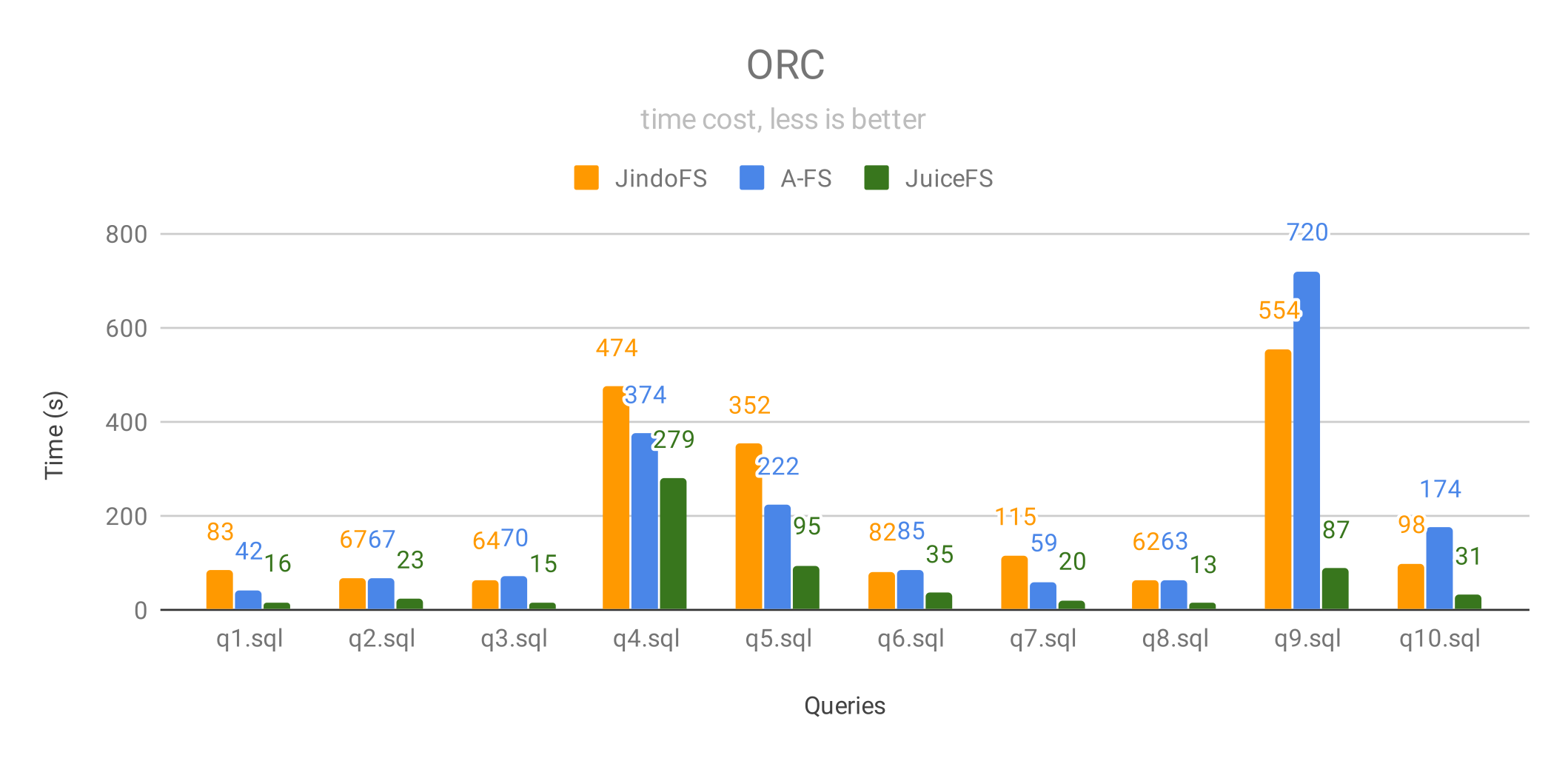
当查询 ORC 格式的数据时,JuiceFS 依然在所有测试中都是最快的,性能优势更明显,其中:
- 30% 的查询 JuiceFS 的性能是 JindoFS 的 5 倍以上,40% 的查询性能是 JindoFS 的 3~5倍;
- 20% 的查询 JuiceFS 的性能是 A-FS 的 5 倍以上,30% 的查询性能是 A-FS 的 3~5倍。
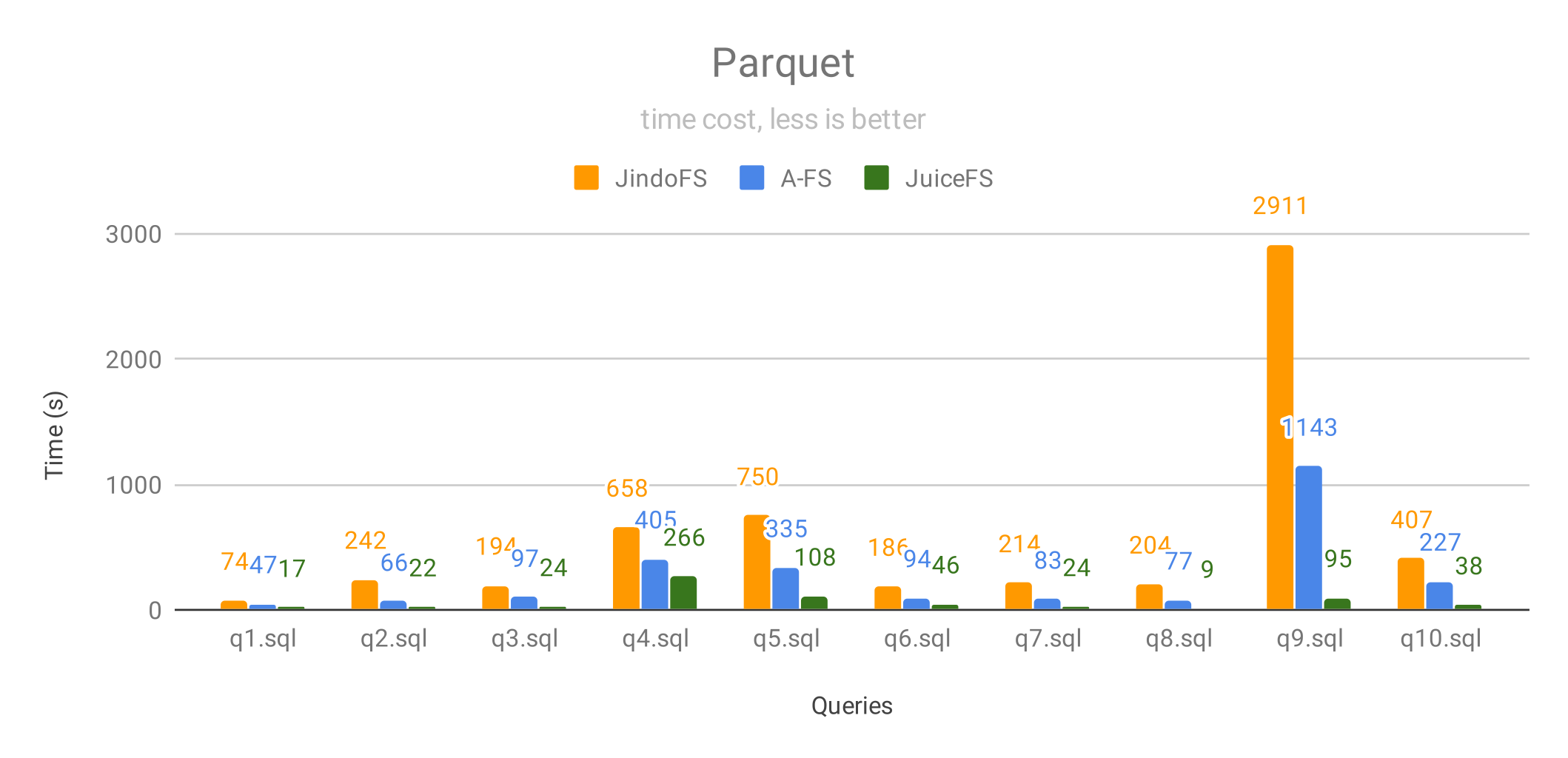
当查询 Parquet 格式的数据时,JuiceFS 在所有测试中都大幅领先其他两个方案,性能优势进一步拉大,其中:
- 40% 的查询 JuiceFS 的性能是 JindoFS 的 10 倍以上,30% 的查询性能是 JindoFS 的 5~10 倍。其中 q9 性能提升高达 30 倍;
- 30% 的查询 JuiceFS 的性能是 A-FS 的 5 倍以上,40% 的查询性能是 A-FS 的 3~5倍。其中 q9 性能提升高达 12 倍。
从以上3种常用的数据格式的对比测试中可以看出,在缓存空间不足的时候,JuiceFS 的性能大幅领先于 JindoFS 和 A-FS。这是因为:
- JuiceFS 使用更小的缓存粒度(默认 4M ),能够更高效地利用缓存空间,同时也有更高效的置换效率;
- 对于 ORC 和 Parquet 这种列式存储格式,通过高效的索引能够跳过大量不需要的数据,大大节省IO,同时访问方式也变得随机,对底层存储的随机访问性能有更高的要求。JuiceFS 针对此做了大量的优化,在缓存容量不足的情况下,可以只 cache 住经常随机读数据(此部分数据通常很少,比如文件 footer),顺序读的数据就不 cache,节省缓存空间;
- 测试中所用的 Spark 2.4,对 分区后的小文件调度时不会考虑缓存位置信息,导致经常要跨网络才能读到缓存数据。此时 JuiceFS 客户端会通过内部的 P2P 网络来访问缓存数据,大幅提高缓存命中率和性能。
数据写入
我们通过 Spark 来做数据写入测试,写入 39GB 文本格式的数据,具体的 SQL 语句如下:
insert overwrite table store_sales select * from store_sales;
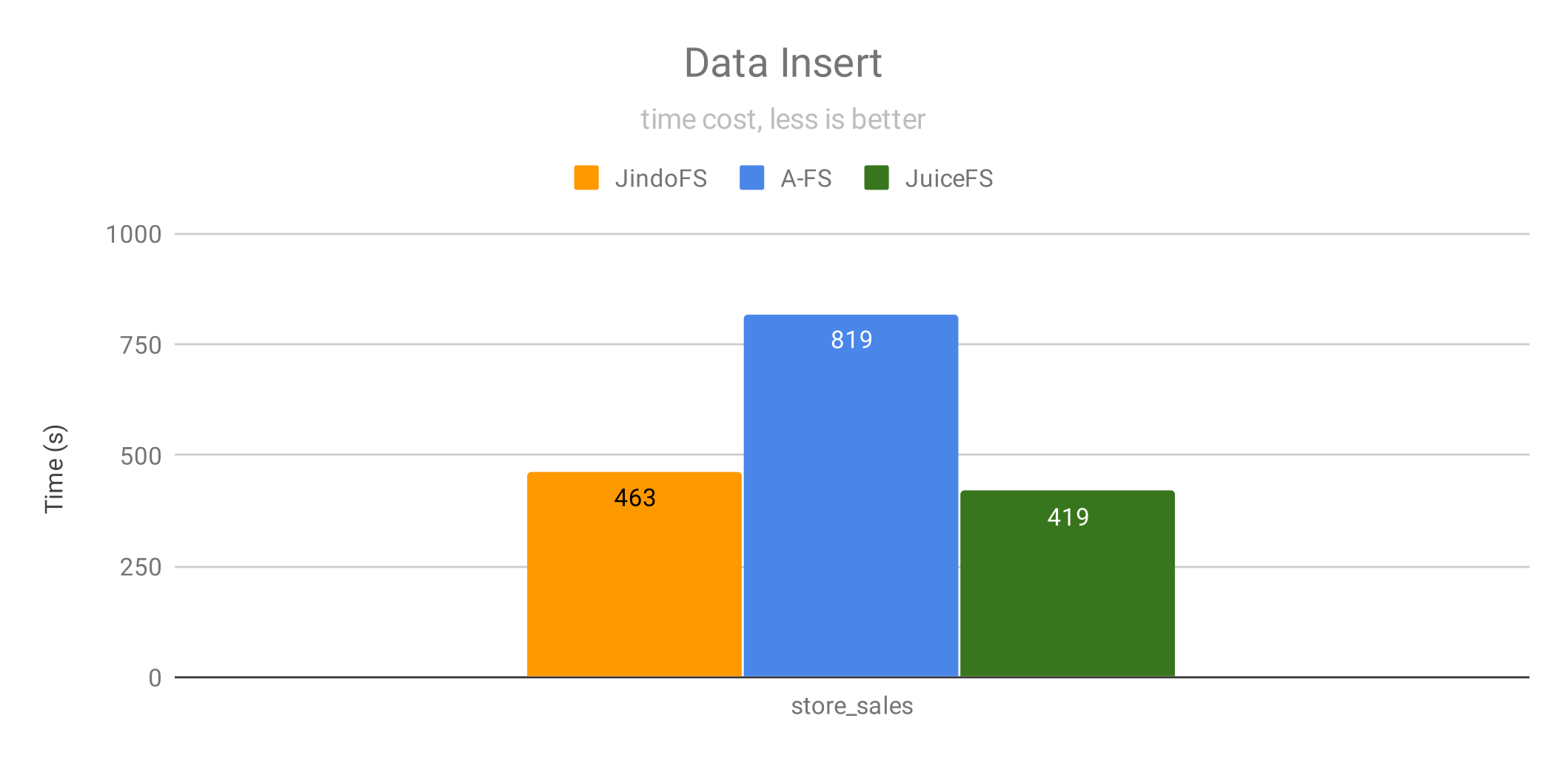
在写入性能上,JuiceFS 比 JindoFS 快 10%,比 A-FS 快 95% 。这个测试中,插入数据的表没有做分区。
JindoFS 和 JuiceFS 均使用自己的元数据,所以写完数据后最后的 rename 过程是原子的,不存在数据拷贝。而 A-FS 需要和 OSS 保持同步,因此 rename 过程仍然存在 OSS 的数据拷贝问题,速度比较慢。针对这个问题,A-FS 建议使用异步数据写入(甚至要等 rename 完成之后)的方式来避免数据拷贝,但这违背了 commit 阶段要完整数据持久化的语义,会引入数据丢失的风险,因此没有采用这个优化技巧。
FUSE 客户端
这三个缓存系统都提供了 FUSE 客户端来简化数据访问,尤其对于机器学习等场景非常有帮助。我们尝试了 A-FS 和 JindoFS 的最新版 FUSE 客户端,都可以按照官方文档顺利挂载,但是在做完整的性能测试时发现,在 A-FS 上没能跑完完整性能测试,另外他们在数据持久化方面也使用了不同的策略(A-FS 和 JindoFS 都是异步写入数据到 OSS,有数据丢失风险),没办法做对等的性能比较。相比较而言,JuiceFS 的 FUSE 客户端比其他两个早 3 年发布,在兼容性等方面都更成熟,等日后 A-FS 和 JindoFS 的 FUSE 客户端更成熟了再做比较分析。
总结
通过对以上 3 个缓存加速方案的全面比较,JuiceFS 在元数据性能、顺序读写性能、随机读性能、FUSE 客户端等方面全面胜出,具有压倒性的优势。同时,JuiceFS 作为跨云的的全托管服务,对所有的对象存储都有类似的加速效果。如果想进一步了解 JuiceFS 的技术细节,或者想评估 JuiceFS 对你实际工作负载的真实加速效果,请跟我们联系。
