














这是一篇使用 JuiceFS 作为 Amazon EMR 存储后端的快速入门文章,JuiceFS 是一个专门为在云端工作而设计的 POSIX 兼容的共享文件系统并且兼容 HDFS。JuiceFS 与自建的 HDFS 相比,可以节省 50% ~ 70% 的成本,同时达到与自建 HDFS接近的性能。
为什么在 Amazon EMR 中使用 JuiceFS?
在 Hadoop 集群中使用 HDFS 是存储计算耦合架构,集群中的每个节点都同时承担计算和存储的职责。在实际业务场景中,数据量的增长通常远远快于计算需求的增长,但是在 Hadoop 存储计算耦合的架构下,扩容必须要求存储和计算同时扩容,自然会带来计算资源利用率的低下。随着存储规模的增大,HDFS 的负载压力越来越高,但又不支持横向扩展,给运维带来很高的复杂度,NameNode 重启、Full GC 等问题会给整个集群带来数十分钟到数小时的不可用,影响业务健康度。
如果将 Hadoop 存储由 HDFS 换成 Amazon S3,在兼容性、一致性、性能、权限管理等方面要一一解决差异。兼容性方面,用户如果想用 EMR 没有内建的计算引擎,可能要自己解决驱动适配的问题;性能方面的下降可能要扩大集群规模;权限管理方式的变化可能要重建整个 ACL 体系。
在 HDFS 和 Amazon S3 之间是否有一个两全其美的方案呢?JuiceFS 正是这样一个低成本弹性伸缩的全托管 HDFS 服务。可以为客户带来和 HDFS 一样的兼容性、一致性和接近的性能,和 Amazon S3 一样的全托管、弹性伸缩、低成本。
什么是 JuiceFS?
JuiceFS 是面向云原生环境设计的分布式文件系统,完全兼容 POSIX 和 HDFS,适用于大数据、机器学习训练、Kubernetes 共享存储、海量数据归档管理场景。支持全球所有公有云服务商,并提供全托管服务,客户无需投入任何运维力量,即刻拥有一个弹性伸缩,并可扩展至 100PB 容量的文件系统。
在下面的这张架构图中可以看出,JuiceFS 已经支持将各种公有云对象存储作为后端数据持久服务,同时也支持了开源对象存储,如 Ceph、MinIO、Swift 等。在 Linux 和 macOS 上提供 FUSE 客户端,在 Windows 系统上也提供原生客户端,都可以将 JuiceFS 的文件系统挂载到系统中,使用体验和本地盘一模一样。在 Hadoop 环境中提供 Java SDK,使用体验和 HDFS 一样。JuiceFS 的元数据服务在所有公有云上都部署了全托管服务,客户不用自己维护任何服务,学习和使用门槛极低。
性能测试
综合性能
TPC-DS 由事务性能管理委员会(TPC)发布,该委员会是目前最知名的数据管理系统评测基准标准化组织。TPC-DS 采用星型、雪花型等多维数据模式。它包含 7 张事实表,17 张纬度表,平均每张表含有 18 列。其工作负载包含 99 个 SQL 查询,覆盖 SQL99 和 2003 的核心部分以及 OLAP。这个测试集包含对大数据集的统计、报表生成、联机查询、数据挖掘等复杂应用,测试用的数据和值是有倾斜的,与真实数据一致。可以说 TPC-DS 是与真实场景非常接近的一个测试集,也是难度较大的一个测试集。
测试环境
- ningxia (cn-northwest-1) region
- 1 Master m5.2xlarge 8 vCore, 32 GiB memory, 128 GB EBS storage
- 3 Core m5d.4xlarge 16 vCore, 64 GiB memory, 600 SSD GB storage
- emr-6.1.0 Hive 3.1.2, Spark 3.0.0, Tez 0.9.2
- Juicefs-hadoop-1.0-beta.jar
- Juicefs专业试用版
- 使用 500GB TPC-DS 数据集 测试。
JuiceFS 参数
juicefs.cache-dir=/mnt*/jfsjuicefs.cache-size=10240Mjuicefs.cache-full-block=false
Hive 测试的结果
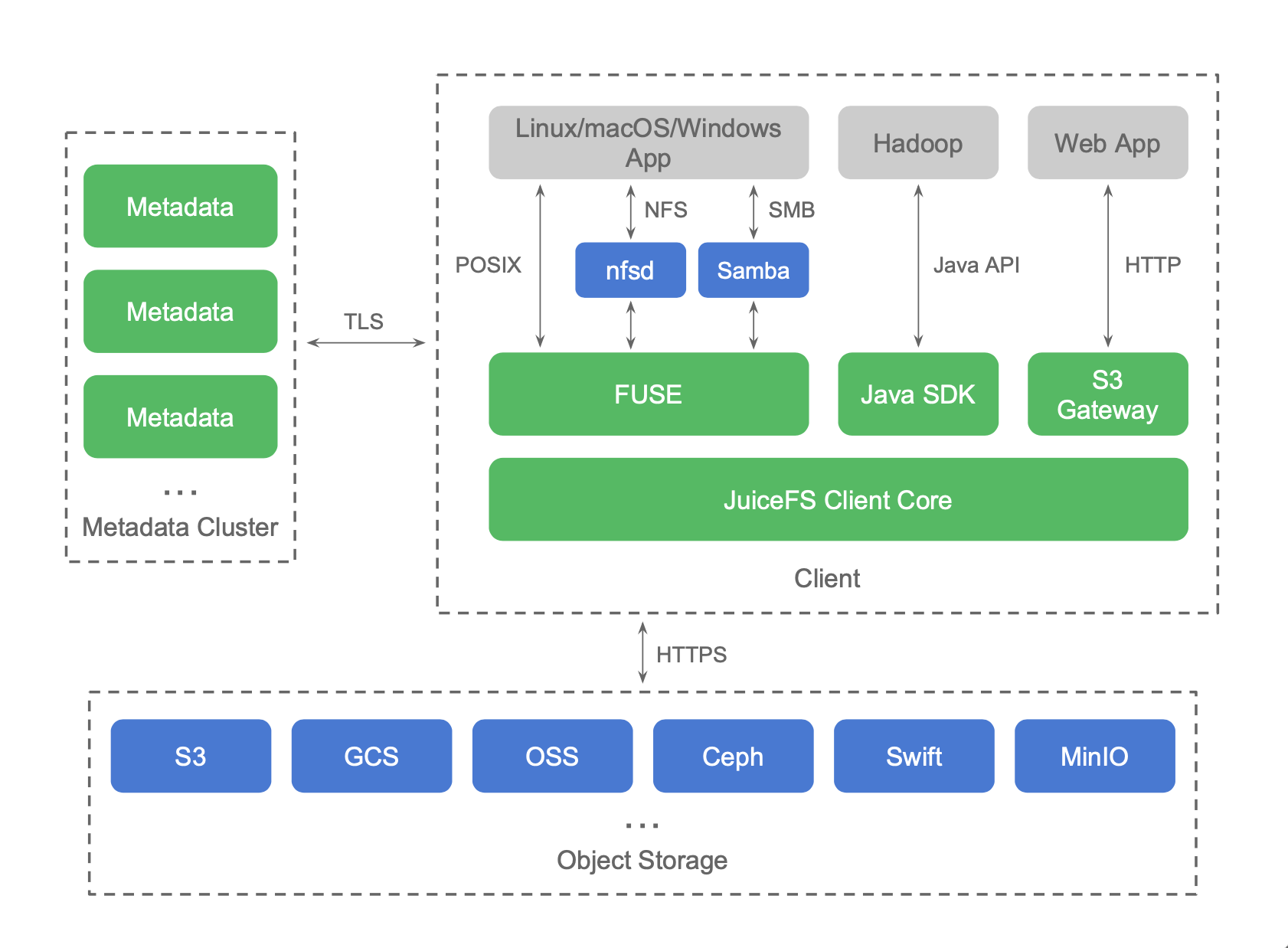
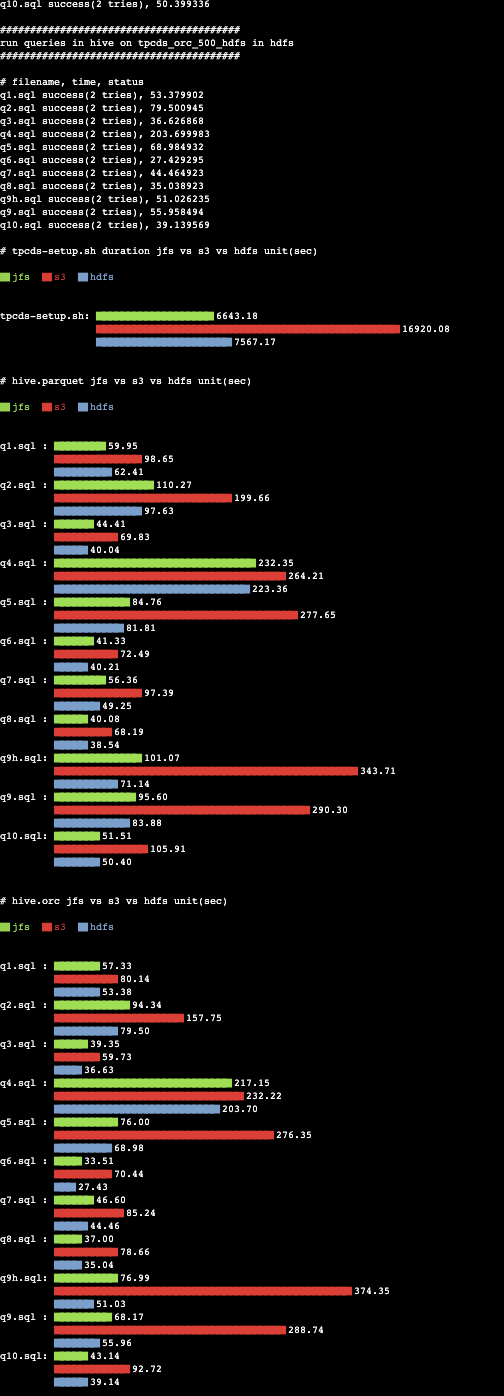
由于完整的测试时间比较长,我们选取了部分测试集作为参考。每个测试脚本均执行2次并取两次的平均值作为测试结果。测试耗时时间越短表面结果越好。其中左图为每条测试脚本所花的绝对时间。右图为以 S3 为基准的相对时间。
Hive on Parquet 测试总时间开销:
- JuiceFS 685.34秒
- HDFS 615.31秒
- S3 1887.99秒
JuiceFS 比 S3 速度提升 175%,比 HDFS 慢 11%。
Hive on ORC 测试总时间开销:
- JuiceFS 789.58秒
- HDFS 695.25秒
- S3 1796.34秒
JuiceFS 比 S3 速度提升 127%,比 HDFS 慢 13%。
写入性能
我们通过 Spark 来做数据写入测试,写入 143.2 GB 文本(未分区)格式的数据,具体的 SQL 语句如下:
CREATE TABLE catalog_sales2 AS SELECT * FROM catalog_sales;
Juicedata 与亚马逊云科技联合开发的解决方案通过 AWS CloudFormation 模板可以在 Amazon EMR 中自动配置好可用的 JuiceFS 环境,并且提供一个 TPC-DS Benchmark 测试程序供使用。上述测试结果均使用该解决方案搭建环境。
如何利用 AWS CloudFormation 在 Amazon EMR 中快速使用 JuiceFS
Github 源代码
https://github.com/aws-samples/amazon-emr-with-juicefs/
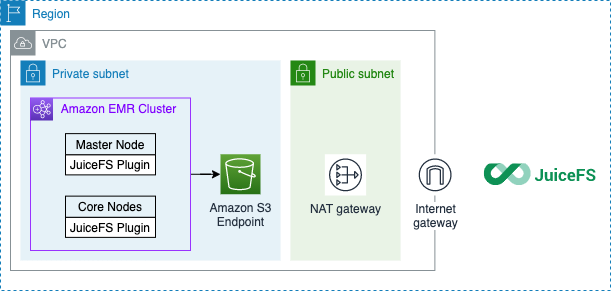
架构图
注意
- EMR 集群需要连接到 JuiceFS 元数据服务。它需要一个 NAT 网关来访问公共互联网。
- EMR 集群的每个节点都需要安装 JuiceFS Hadoop 扩展 JAR 包,才能使用 JuiceFS 作为存储后端。
- JuiceFS 只存储元数据,原始数据仍然存储在您的账户 S3 中。
部署指南
先决条件
- 注册 JuiceFS 账户
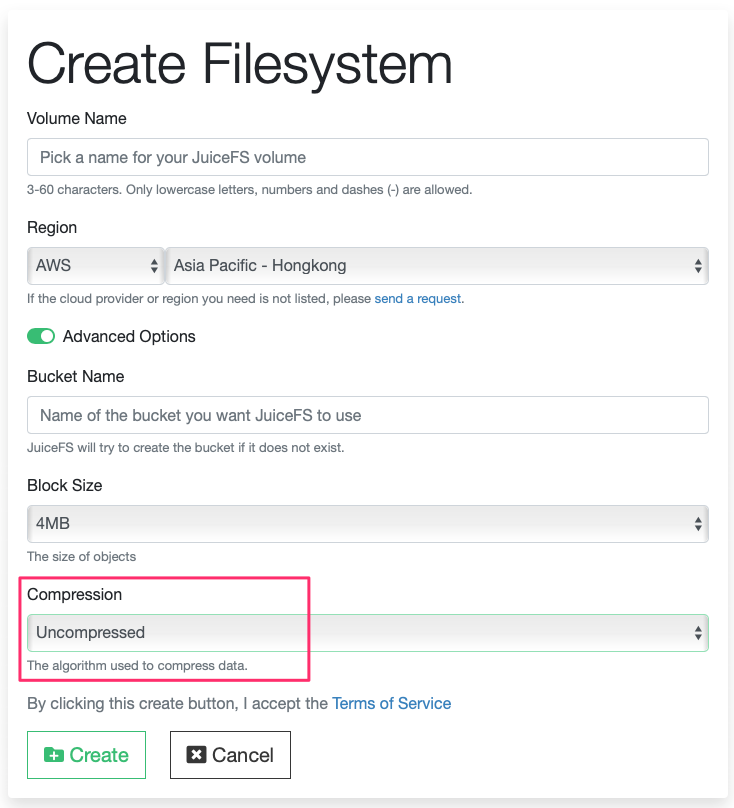
- 在 JuiceFS 控制台上创建一个卷。选择你的 AWS 账户区域,并创建一个新卷。请在 “高级选项” 中将 “压缩” 项改为 Uncompressed
注意:JuiceFS 文件系统默认启用 lz4 算法对数据进行压缩。在大数据分析场景中经常使用 ORC 或者 Parquet 等列存文件格式,查询过程中往往只需要读取文件中的一部分,如果启用压缩算法,则必须读取完整 block 解压后才能获得需要的部分,这样会造成读放大。关闭压缩后,则可以直接读取部分数据
- 从 JuiceFS 控制台获取访问令牌和桶名。
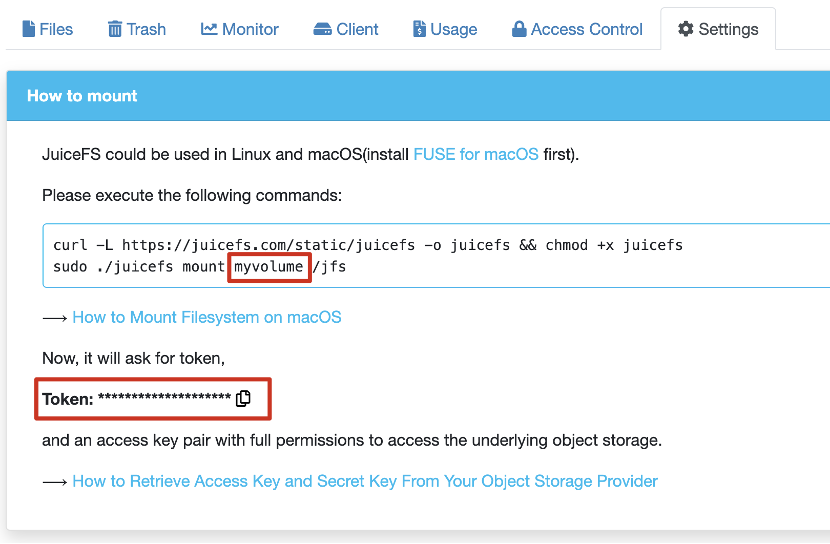
启动 AWS CloudFormation Stack
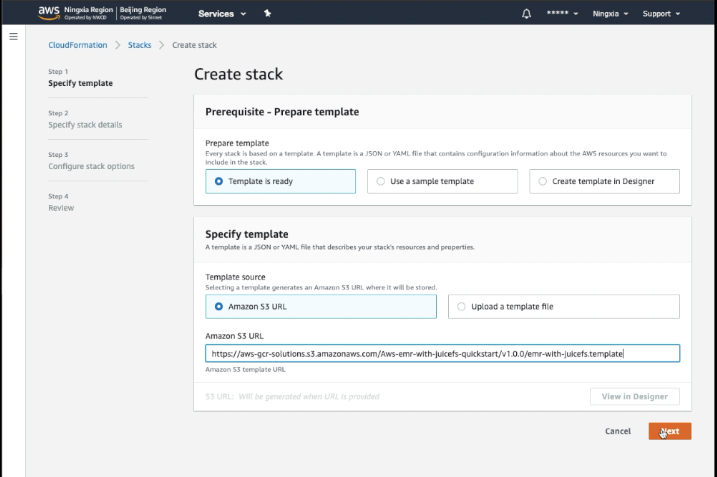
- 填写配置项
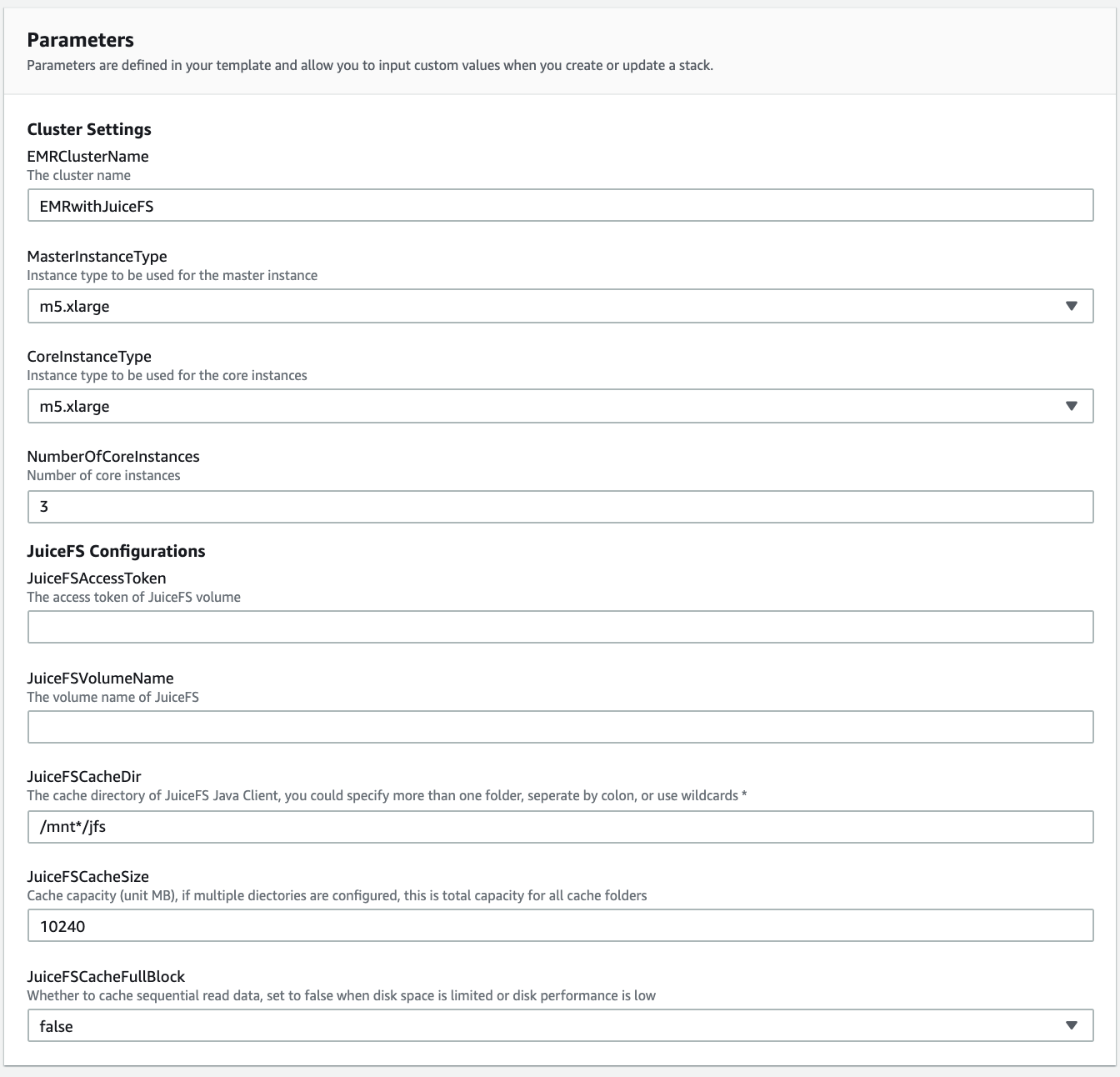
参数说明
| 参数名 | 解释 |
|---|---|
| EMRClusterName | EMR 集群名称 |
| MasterInstanceType | 主节点实例类型 |
| CoreInstanceType | 核心节点类型 |
| NumberOfCoreInstances | 核心节点数量 |
| JuiceFSAccessToken | JuiceFS 访问令牌 |
| JuiceFSVolumeName | JuiceFS 存储卷名称 |
| JuiceFSCacheDir | 本地缓存目录,可以指定多个文件夹,用冒号 : 分隔,也可以使用通配符(比如 * ) |
| JuiceFSCacheSize | 磁盘缓存容量,单位 MB。如果配置多个目录,这是所有缓存目录的空间总和 |
| JuiceFSCacheFullBlock | 是否缓存连续读数据,在磁盘空间有限或者磁盘性能低下的时候,设置为 false |
启动 CloudFormation Stack 完成部署后可以在 EMR 服务中检查你的集群。

进入硬件选项卡。
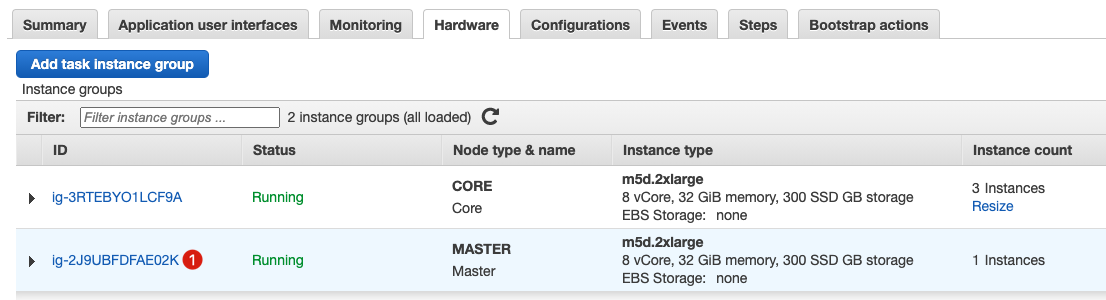
找到你的 Master 节点。
通过 AWS Systems Manager Session Manager 会话管理器连接到主节点。

登录到 Master 节点。
接下来验证集群环境。
$ sudo su hadoop
# JFS_VOL 是一个预制的环境变量,指向您所在的JuiceFS存储卷
$ hadoop fs -ls jfs://${JFS_VOL}/ # 别忘了最后一个“斜线”
$ hadoop fs -mkdir jfs://${JFS_VOL}/hello-world
$ hadoop fs -ls jfs://${JFS_VOL}/
运行 TPC-DS 基准测试
- 通过 AWS Systems Manager Session Manager 会话管理器登录到集群主节点,然后将当前用户改为 hadoop。
$ sudo su hadoop
- 解压 benchmark-sample.zip。
$ cd && unzip benchmark-sample.zip
- 运行 TPC-DS 测试。
$ cd benchmark-sample
$ screen -L
# ./emr-benchmark.py 为 benchmark 测试程序
# 它会生成 TPC-DS 基准的测试数据,并执行测试集(从 q1.sql 到 q10.sql)
# 测试会包含一下部分:
# 1. 生成 TXT 测试数据
# 2. 将 TXT 数据转成 Parquet 格式
# 3. 将 TXT 数据转成 Orc 格式
# 4. 执行 Sql 测试用例并统计 Parquet 和 Orc 格式的耗时
# 支持的参数
# --engine 计算引擎选择 hive 或 spark
# --show-plot-only 只在控制台中显示柱状图
# --cleanup, --no-cleanup 是否在每次测试时清除 benchmark 数据,默认:否
# --gendata, --no-dendata 是否在每次测试时生成数据,默认:是
# --restore 从已有的数据中恢复数据库,此选项需要在 --gendata 打开后才生效
# --scale 数据集大小(例如:100 代表 100GB 数据)
# --jfs 打开 uiceFS benchmark 测试
# --s3 打开 S3 benchmark 测试
# --hdfs 打开 HDFS benchmark 测试
# 请确保机型有足够的空间存储测试数据,例如:500GB 推荐 Core Node 使用 m5d.4xlarge 或以上
# 关于机型存储空间选择请参考 https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-plan-storage.html
$ ./emr-benchmark.py --scale 500 --engine hive --jfs --hdfs --s3 --no-cleanup --gendata
Enter your S3 bucket name for benchmark. Will create it if it doesn\'t exist: (请输入用来存放s3基准测试的桶名,若不存在则会创建一个新的) xxxx
$ cat tpcds-setup-500-duration.2021-01-01_00-00-00.res # 测试结果
$ cat hive-parquet-500-benchmark.2021-01-01_00-00-00.res # 测试结果
$ cat hive-orc-500-benchmark.2021-01-01_00-00-00.res # 测试结果
# 删除数据
$ hadoop fs -rm -r -f jfs://$JFS_VOL/tmp
$ hadoop fs -rm -r -f s3://<your-s3-bucketname-for-benchmark>/tmp
$ hadoop fs -rm -r -f "hdfs://$(hostname)/tmp/tpcds*"
- 注意: AWS Systems Manager Session Manager 会话管理器可能会超时导致终端连接断开,建议使用 screen -L 命令讲会话保持在后台 screen 的日志会保存在当前目录下的 screenlog.0
- 注意:若测试机器一共超过 10vcpu,需要开通 JuiceFS 专业版试用,例如:您有可能会遇到以下错误 juicefs[1234]
: register error: Too many connections - 样例输出
- 删除 Stack
结语
通过测试验证可以看到 JuiceFS 确实是弹性伸缩的全托管 HDFS 服务。可以为客户带来和 HDFS 一样的兼容性、一致性和接近的性能,和 Amazon S3 一样的全托管、弹性伸缩、低成本。
