














本案例来自社区一家从事金融科技的用户。该用户在进行数据平台上云时,首个站点采用了与本地数据中心(IDC)相同的架构,在云主机上构建了基于 Hadoop 的技术栈。随着业务的迅速增长和更多站点的上线,该架构面临了一系列挑战,包括块存储成本高昂、Hadoop 组件复杂、弹性能力有限等。此外,为了支持不同的公有云平台,还需要实现快速的计算资源扩展能力。
存储系统进行了一系列改造,从引入对象存储+ EMR 方案到采用 JuiceFS + Kubernetes 进行架构演进。改造后的架构性能与 HDFS 相近,还实现了更高效的资源弹性、以及计算与存储的分离。同时,新架构还带来了约 85% 的存储成本节约和 90% 的维护工作减轻。
01 大数据平台: HDFS vs 对象存储
在探讨大数据场景下的存储解决方案时,Hadoop 常被视为首选方案,其标准存储组件即为 HDFS。然而,随着对象存储的普及,众多企业开始考虑在对象存储上实施大数据场景。因此,对比 HDFS,一种传统的块存储系统 与对象存储的特点与优势,成为了讨论大数据存储方案时的关键议题。
块存储与对象存储
首先,先让我们比较一下这两个方案的底层存储之间的差异: 块存储和对象存储。
块存储在功能上类似于物理机中的硬盘。它通常需要首先被格式化为文件系统,然后才能挂载到主机上。块存储使用 POSIX 协议进行数据访问,它支持高效的随机读写操作。这种存储方式特别适用于需要频繁读写操作的场景,如数据库应用。为了提高单机磁盘的存储效率,可以在系统中挂载多个块存储设备。
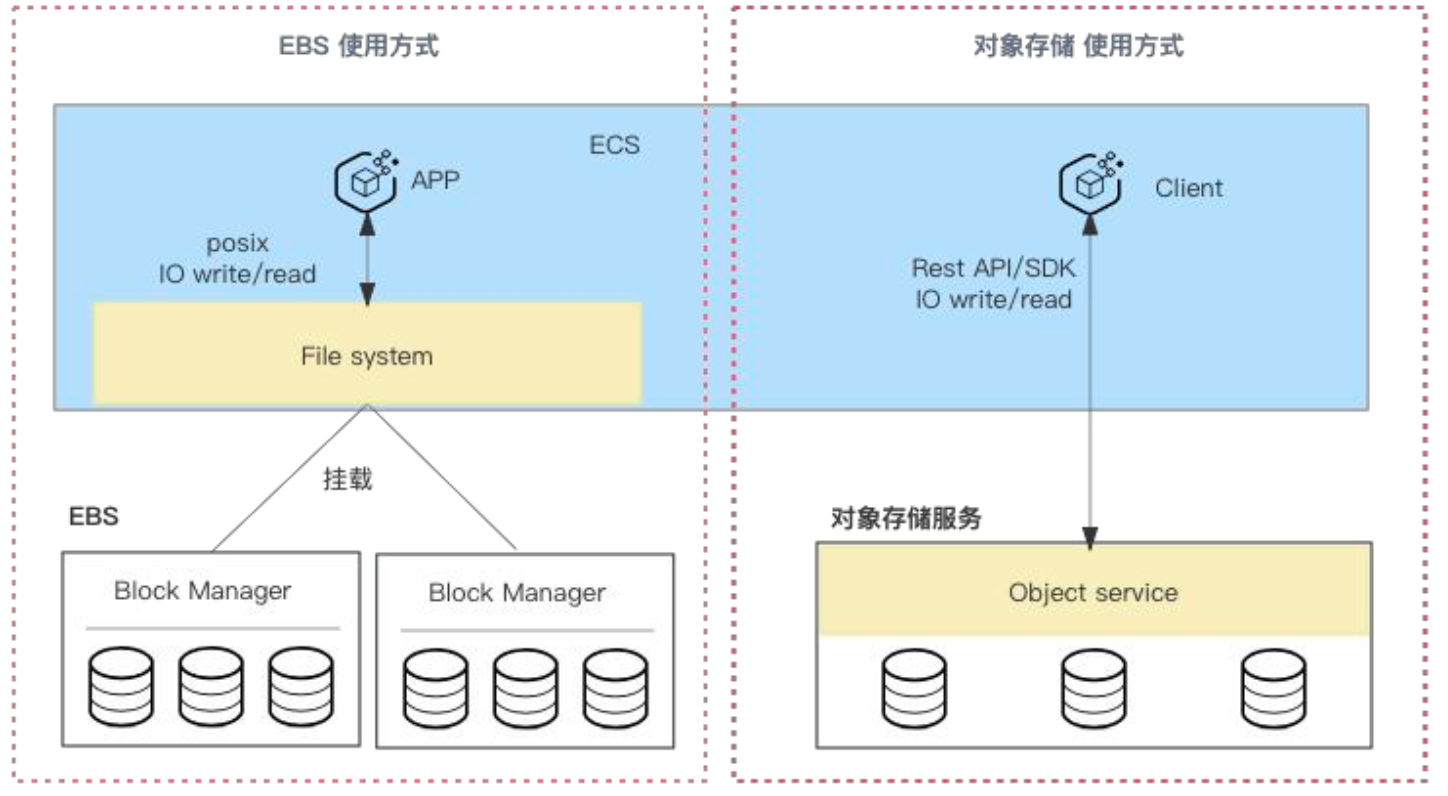
对象存储是一种基于互联网的存储服务,它采用了扁平化的文件组织形式。这种存储类型通过 RESTful API 或 SDK 进行访问,其存储结构类似于键值(Key-Value)对。在这种结构中,'Key'是一个统一资源标识符(URI),用于唯一标识和定位存储的文件,而'Value'则是存储的实际文件,即对象。对象存储的这种设计使得它非常适合存储大量的非结构化数据,如图片、视频文件等,并且可以在任何位置通过网络进行高效访问。
| 对比项 | 块存储 | 对象存储 |
|---|---|---|
| 成本 | 1024元 / TB /月~几万/ TB /月 | 135元/TB/月 |
| 性能 |
以某厂商产品为例: IO: 140MB/S~几GB/S IOPS: 1800~几十万 RT:0.2~3ms 容量 20G~32TB |
以某厂商产品为例: 内外网总上传/下载带宽分别为680MB/S IOPS :10000 RT:ms~几十ms 容量无限 |
| 使用场景 | 适用于OLTP数据库、NoSQL数据库等IO密集型的高性能、低时延业务场景 | 主要应用于基于对象API开发的互联网应用程序的数据存储。如:互联网业务的音视频存储、云相册、个人/企业网盘类应用.因为廉价被广泛使用在大数据存储中 |
架构比较:HDFS vs 对象存储
在大数据场景中,HDFS 和S3的存储架构具有一定的相似之处,但也有明显的差异。
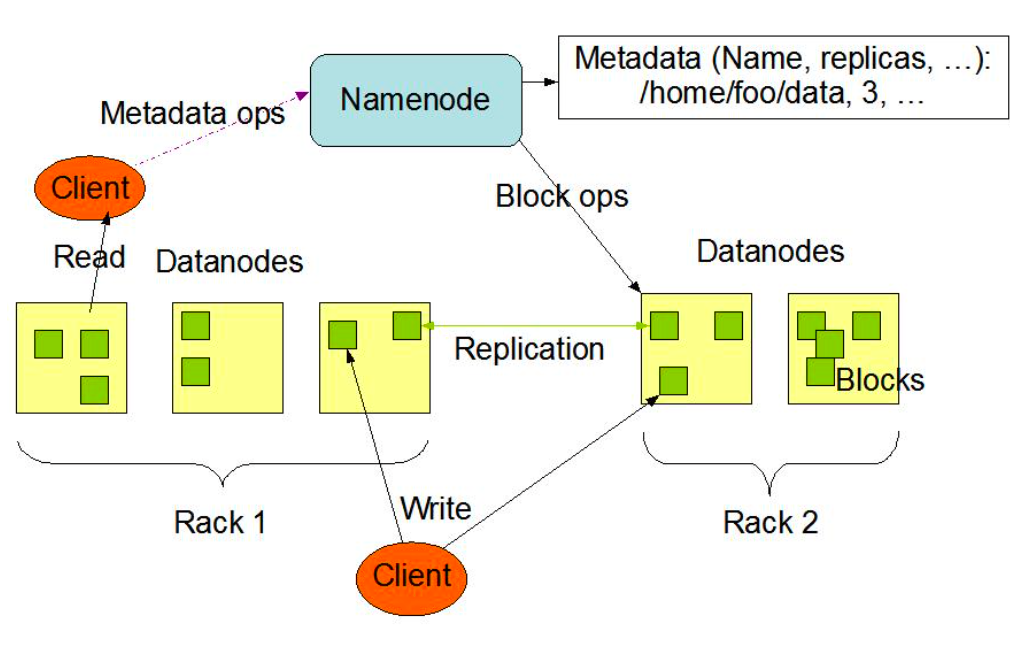
HDFS 由两个关键进程组成:NameNode 和 DataNode。NameNode 负责存储整个文件系统的元数据并管理 DataNode。这些元数据包括文件属性信息(如文件权限、修改时间、文件大小)以及文件与块(block)的映射关系。DataNode 则负责管理具体的数据存储,并响应客户端的读写请求。此外,元数据还包含文件块与 DataNode 之间的映射关系,这是数据存储的核心部分。
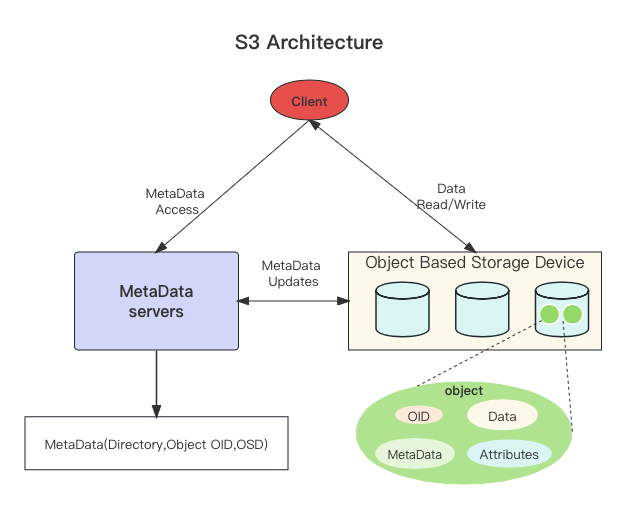
S3 的架构也分为两个主要部分:Metadata Service 和 Object Storage Daemon。Metadata Service 负责管理元数据,这包括目录、对象组织关系以及对象与 Object Storage Device 之间的映射关系。对象存储守护进程负责存储数据本身。S3 的元数据相对简单,通常包括文件的基本属性信息,如修改时间、大小和文件类型等。
性能差异: HDFS vs 对象存储
I/O性能和集群性能:
HDFS的性能受到整个集群的网络带宽、磁盘类型、集群规模以及客户端并发读写操作的影响。HDFS通常以其高吞吐量而著称,这使得它不太容易遇到I/O瓶颈。
相比之下,对象存储的性能取决于具体的服务提供商和技术实现。一般情况下,对象存储的最大吞吐量范围在5Gb/s至16Gb/s之间,最大IOPS在5000到10000之间。对于具有高吞吐需求的数据处理,对象存储可能会遇到性能瓶颈。
元数据操作性能:
在HDFS中,诸如ls、du、count等涉及元数据的操作可以通过Namenode的内存快速计算完成,通常在毫秒到秒级别返回结果。
而在对象存储系统中,元数据服务(MDS)中的元数据通常只包含目录、对象及对象所在的存储设备(OSD)信息。因此,统计一个包含大量对象的目录大小可能需要遍历每个对象的元数据,这些操作可能会非常耗时。
Rename操作的差异:
HDFS在执行重命名(Rename)操作时,由于维护了文件与数据块的映射关系,只需修改内存中的映射关系即可。这使得Rename操作在HDFS中相对快速简便。
在对象存储系统中,常见的操作接口包括PUT、GET、COPY、DELETE和LIST,但通常没有直接的RENAME操作。要实现重命名,需要将其转化为列出(LIST)对象、复制(COPY)到新名称,然后删除(DELETE)旧对象的步骤。尤其当涉及到大量数据时,这个过程可能会相当耗时。
总结这两个存储类型在大数据场景下的优劣势:
- 架构复杂度:
- HDFS:在HDFS中,生产级环境需要配置多个组件,包括NameNode、DataNode、JournalNode、ZKFC(ZooKeeper Failover Controller),以及ZooKeeper等,使得架构相对复杂,需要一定的维护和管理工作;
- 对象存储:对象存储,特别是云服务提供的对象存储,通常对用户而言更加简单。用户无需维护任何底层进程,可以专注于存储使用和数据管理。
- 扩展性:
- HDFS:HDFS的存储容量可以通过增加DataNode节点来扩展,这也有助于提高整个集群的I/O性能。但这需要物理硬件的扩展;
- 对象存储:对象存储通常被视为具有理论上无限的使用空间,在云环境中扩展特别容易,不涉及物理硬件的添加,从而减少了扩容的操作和成本。
- 成本:
- HDFS: 块存储相对昂贵,如果使用机械盘,每 TB数据是1000 元/月。使用一个较低规格的 SSD 盘,每 TB大约是 3000 元/月;
- 对象存储每 TB大约需要 135 元/月。
- 读写性能:
- HDFS:HDFS的读写性能与集群的配置密切相关,包括网络带宽、存储硬件和集群的规模;
- 对象存储:对象存储的性能依赖于服务提供商、并发读写的程度和文件的大小。虽然它通常提供足够的性能,但在某些情况下可能存在性能限制。
- 元数据性能:
- HDFS:在HDFS中,NameNode可以高效处理元数据操作,但这取决于NameNode的内存和处理能力;
- 对象存储:对象存储在处理大量对象的元数据时可能表现出一些劣势,尤其是当需要遍历和统计大量对象的信息时。
02 大数据平台上云挑战与方案
最初采用了与本地数据中心(IDC)一致的架构,在云主机上构建了包括 Hadoop、Hive、Spark 以及自研 IDE 在内的技术栈。在初始阶段,由于业务体量有限且稳定,该方案的成本和维护需求都处于可接受的范围内。
这一架构方案具有多个优势。首先,该方案成熟且稳定,能够有效支持业务运行。其次,它提供了与本地 IDC 相近的基准性能,确保了运行效率。最后,由于 Hadoop 和 Spark 的版本兼容性,该方案在与线下 IDC 或用户端应用集成时,能够保持高度一致性,减少了调试和测试的需要,从而加快了业务上线的速度。
然而,随着数据量的增长,该方案也面临了一些挑战。
- 首先,站点的块存储成本不断上升,对预算构成压力;
- 其次,由于自建平台缺乏弹性计算资源,存储资源的扩展需要手动进行,这增加了管理复杂度;
- 第三,多组件的环境使得运维成本相对较高。因此,为了适应日益增长的业务需求和优化成本,还需要对数据服务中心的架构进行改造。
架构演进1:对象存储 + EMR
首先引入了对象存储。在解决集群弹性问题时,我们引入了 EMR,以适应不同资源使用需求的业务波动。当使用对象存储时,受限于对象存储的性能表现,我们仍然只存储一些低频数据,RT(响应延迟) 敏感任务也不会放在对象存储上。我们会对接 S3、OSS、OBS 和 GPS 等。因为我业务特性要求要能够对接每家云厂商,再往上是每家云厂商的 EMR 集群。最上面是数据开发的 IDE,在构建时,在原来的 IDE 下又做了一个 EMR 适配层,用于适配每家云厂商的 EMR 和对象存储。
在应对数据量增长和业务扩展的挑战时,我们采取了一系列改革措施,优化其数据服务中心的架构:
首先引入对象存储,解决数据存储的弹性问题。这一改变主要针对存储一些低频访问数据,而对于 RT 敏感任务,则选择不在对象存储上处理。我们对接了包括 S3、OSS、OBS 和 GPS 等多种云服务提供商的对象存储服务。
采用 EMR (Elastic MapReduce)提高集群弹性,以适应不同资源使用需求的业务波动。这种做法旨在实现存储与计算的分离,使资源配置更为弹性。EMR 提供了弹性策略配置,可以根据需要定时扩展,或根据集群资源使用率动态调整计算节点。
此外,为了适配每家云厂商提供的 EMR 和对象存储服务,我们在其数据开发的 IDE 下建立了一个额外的 EMR 适配层。这一层的主要作用是确保与不同云服务的兼容性。
这个方案的优势包括:
- 降低了存储成本;
- 实现了存储与计算的分离,资源可弹性配置;
- 具备多云通用性。
该方案也存在一些劣势:
- EMRFS 性能相对较低,本质上未能解决对象存储中缺乏元数据的问题;
- 高适配成本。尽管有些云服务宣称与开源版本兼容,但实际上仍需使用官方 SDK 来解决特定问题,以避免潜在的冲突;
- 运营成本较高,尽管是云服务,但所有进程仍需公司自身处理;
- 弹性能力有限,响应时间可能较长,特别是在有自定义环境变量的情况下。
架构演进2: Kubernetes + JuiceFS
基于此,我们进行了下一轮优化。首先在存储层,选用了 JuiceFS 作为解决方案。JuiceFS 是一种采用“数据”与“元数据”分离存储架构的文件系统,它不仅完全兼容 HDFS 接口,还在元数据操作性能上媲美 HDFS。这样的改进不仅优化了存储效率,还提升了存储系统的可扩展性和性能。
在计算层,采用了运行在 Kubernetes 上的 Spark 解决方案。这一改动使得我们可以完全摒弃对 Hadoop 的依赖,从而大幅减少了部署、适配和运维方面的工作。Kubernetes 提供的是全托管服务,这意味着部署和运维工作都由云服务提供商处理,为我们带来了更高的操作便利性和更低的运维成本。此外,基于 Kubernetes 的服务具有分钟级的弹性伸缩能力,而成本只涉及 ECS(Elastic Compute Service)实例本身,进一步降低了运营支出。
总结 JuiceFS 的优势:
- 性能与 HDFS 相近:有效解决了对象存储在元数据性能方面的问题;
- 开源且维护成本低:除了是开源版本外, JuiceFS 本身没有服务端组件(Serverless),这大大降低了其维护成本;
- 额外成本低:JuiceFS 需要的额外成本主要是元数据引擎,而这通常可以通过云厂商购买的托管服务来实现,成本相对较低;
- 广泛的对象存储适配性:JuiceFS 支持接入几乎所有主流的对象存储服务,这在适配 EMR(Elastic MapReduce)时带来了便利,不需要额外适配工作,仅需适配 JuiceFS。
同时,Spark on Kubernetes(K8s)的优势包括:
- 全托管 Kubernetes 服务:Spark 运行在全托管的 Kubernetes 上,意味着没有部署和运维成本,大大降低了管理的复杂性和成本。
- 资源弹性和灵活性:Kubernetes 提供灵活和快速的资源弹性能力,能够根据实际需求动态扩展和缩减资源。
- 无适配成本:自定义管理镜像使得 Spark on Kubernetes 可以实现全网通用,无需为不同环境进行特别适配,进一步减少了成本。
实现细节:Kubernetes + JuiceFS
JuiceFS on Redis
当存储使用 JuiceFS on Redis 选择时,我们通常会购买云厂家托管的 Redis,这些设备具有高性能且服务稳定性。为确保数据可用性,我们对每条存储数据实施 appendfsync 操作。
Spark-operator
在 Kubernetes 上部署 Spark,我们选择使用 Google 开源的 Spark-operator,而非原生的 Kubernetes spark-submit。Spark-operator 更适合 Kubernetes 环境,提供更大的灵活性,尤其是在二次开发和通过 API 定制时。相比之下,spark-submit 在某些方面受限于 Spark 的内置封装,并且通常需要通过 ingress 对外暴露 Spark-UI。
运行效果:Kubernetes + JuiceFS
数据规模资源配置:
- 整体数据规模约为 100 GB,主要的作业逻辑包括数据聚合和分组排序;
- 资源配置方面,动态分配了 1 到 12 个 executor,每个 executor 的配置为 1 CPU 核心和 4 GB 内存;
- 读写操作都在同一类型的存储上进行。
性能分析:
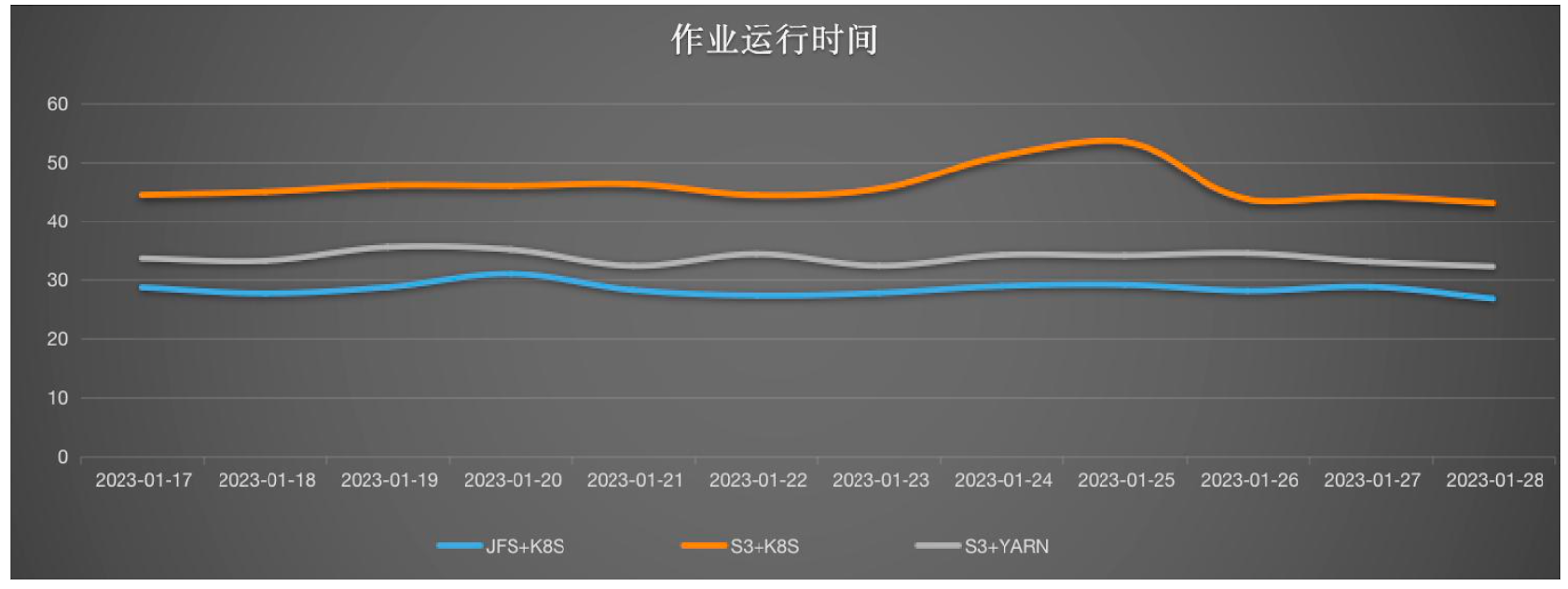
- 使用 Spark on Kubernetes 相比于在 YARN 上运行,性能有所下降,大约降低了 24%;
- 使用 JuiceFS 相比于 S3,性能提升约 60%;
- 尽管 Spark on Kubernetes 的性能较低,但结合 JuiceFS 使用时,整体作业效率仍然高于 S3 加 YARN 的组合。
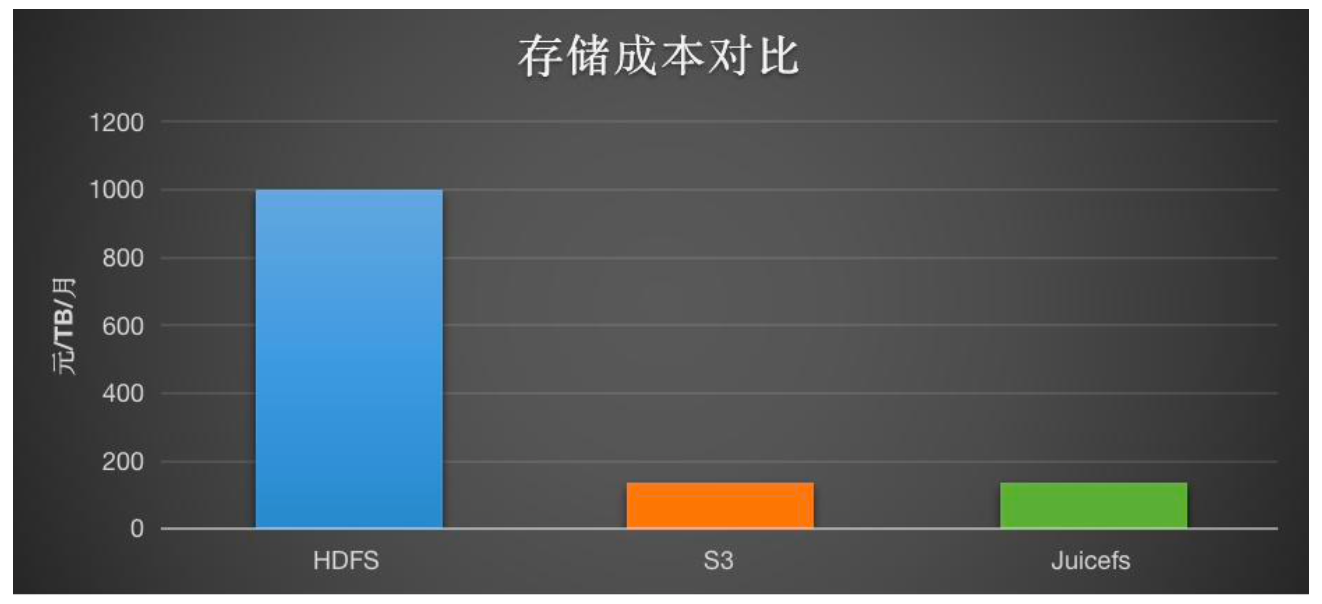
存储成本分析:
- JuiceFS 相比于 HDFS ( 2 副本、70%容量 Buffer、HDD 盘),可以节省约 85% 的成本,这是考虑到使用了 2 副本、70% 容量缓冲和更便宜的 HDD 盘。(块存储每 TB 的成本大约为 1000 元,对象存储的成本约为 135 元)
- 相较于 S3,JuiceFS 的成本略有上升,主要是元数据存储非费用.大约仅增加了 3%。
计算资源成本和效率:
- 目前整个集群在低谷时期的平均资源分配率大约为 50%,而平均使用率约为 65%;
- 由于作业可以弹性扩容,高峰期所需资源的时间从原来的 4 小时降低至 1 小时,这显著提升了对作业资源需求的快速响应能力。
最后一部分是运维成本:
| 自建Hadoop | EMR + 对象存储 | K8S + JuiceFS | |
|---|---|---|---|
| 存储引擎 | HDFS进程(nn,dn,zk,zkfc,jn) 扩缩容 | HDFS进程(nn,dn,zk,zkfc,jn) S3(托管服务) | S3/Redis(托管服务) |
| 计算引擎 | YARN进程(rm,nm) 扩缩容 | YARN进程(rm,nm) 自动扩缩容 | K8S(托管服务) Spark-operator pod |
| Hive元数据 | HMS | HMS | HMS |
| 自建IDE | 全网通用 | 各云适配 | 全网通用 |
03 新架构遇到的问题
JuiceFS 扩缩容问题
初期我们的站点规模较小,数据量大约是 10 TB,对于元数据的存储选择了配置为 2 CPU 核心和 4 GB 内存的 Redis。在数据迁移后,很快我们发现存储空间不足。鉴于单节点扩容需要进行停机操作,我们选择了进行横向扩容。然而,扩容后我们发现新数据并没有写入新的节点。
通过查阅 JuiceFS 的官方文档,我们意识到 JuiceFS 使用 Hash Tag 来保持数据的一致性,仅仅增加节点并不能扩展单个 JuiceFS 实例的元数据容量。
第二个问题是当我们尝试回收之前已经扩容的实例时,触发了 AWS Release 容量保护的问题。这是因为只要集群中有一个节点使用量超过预设值,就无法进行回收。为了解决这个问题,我们首先对内存不足的节点进行了扩展,确保所有节点都在安全的使用阈值以下,然后才进行其他节点的回收。
关于元数据容量估算,结合我们文件平均大小,可以按照每个 Block 大约占用 300 比特进行计算。据此,我们得出了一个元数据占用空间的估算公式:Y (GB) = X (TB) / 10。
04 规划与展望
单桶的带宽限制
在大规模数据处理中,单个存储桶的写入和读取上限可能成为性能瓶颈。为了解决这一问题,JuiceFS 提供了支持多个元数据引擎的能力。
Shuffle 性能差
我们目前使用的是原始的 Shuffle 模式,在部分需要 Shuffle 的作业中,性能可能会显著下降,损失范围在 10% 到 40% 之间。此外,由于 executor 缓存 Shuffle 数据,数据无法及时释放,这也会导致计算资源的浪费。尽管业界通用的 RSS(Remote Shuffle Service)结构复杂且需要额外的资源成本,但考虑到性能提升,这可能是值得探索的方向。
Kubernetes的调度策略
Kubernetes 主要设计用于在线服务(online),在批处理场景中调度较为缓慢。我们现有的 FIFO 调度策略非常简单,不像 YARN 那样提供完善的资源调度策略。这可能导致大作业长时间运行时,小作业无法获得足够的资源。因此,我们考虑使用离线资源调度引擎,如 Volcano 或 YuniKorn,来优化资源分配和调度效率。
通过这些改进,我们期望在保持系统的稳定性和可靠性的同时,提升整体的数据处理能力和效率。
