














ClickHouse 结合 JuiceFS 一直是一个热门的组合,社区中有多篇实践案例。今天的文章来自美国公司 Altinity,一家提供 ClickHouse 商业服务的企业,作者是 Vitaliy Zakaznikov,他尝试了这个组合并公开了过程中使用的代码。原文有两篇文章,“Squeezing JuiceFS with ClickHouse (Part 1): Setting Things Up in Kubernetes”、“Squeezing JuiceFS with ClickHouse (Part 2): Bringing The Two Together”
JuiceFS 是一个兼容 POSIX 的文件系统,能够在 S3 对象存储上运行。作为一个分布式且云原生的文件系统,它具备多种功能,包括数据一致性、传输与静态加密、BSD 和 POSIX 文件锁,以及数据压缩。
所有使用 S3 的应用都需适应其对象存储。对于像 ClickHouse 这样的复杂应用,将表数据存储在 S3 上较为困难,且原生的 S3 支持还存在一些问题。因此,如果用户不希望应用程序直接处理 S3 存储的细节,JuiceFS 将是一个非常理想的选择。特别是在用户的基础设施中已经集成了 JuiceFS 和 ClickHouse 的情况下,将两者结合使用将是自然而然的选择。
在这篇文章中,我们将详细介绍在 Kubernetes 中,配置基于 S3 的 JuiceFS 的过程,以及如何利用它作为存储介质来存放 ClickHouse MergeTree 表的数据。在一切设置完成后,我们探讨使用 JuiceFS 和 ClickHouse 结合时用户所能期望的性能及可能面临的问题。
将 JuiceFS 与 ClickHouse 结合使用的想法已经有一段时间了。早在2021年,JuiceFS 就发表了一篇名为《ClickHouse 存算分离架构探索》的博客,探讨了将 JuiceFS 用作 ClickHouse MergeTree 表的存储解决方案,此外还有更近期的文章《低成本读写分离:Jerry 构建的主从 ClickHouse 架构》。
我们打算亲自进行尝试。不过,直接管理运行 ClickHouse 和 JuiceFS 的服务器相当复杂。因此,我们选择使用 Kubernetes。具体来说,我们会结合使用 clickhouse-operator 和 JuiceFS CSI(Container Storage Interface) Driver,这将简化我们为集群 PVC 的设置工作,即设置 JuiceFS 的 StorageClass。
01 在 Kubernetes 中配置 S3 和 JuiceFS
部署 Kubernetes 集群
对于这次测试,我选择了一种经济且对开发者友好的配置。我们将在 Hetzner Cloud上 部署 Kubernetes,并使用 Wasabi S3 对象存储。
我将使用 hetzner-k3s 工具快速搭建一个低成本的 Kubernetes 集群。设置过程与 Low-Cost ClickHouse clusters using Hetzner Cloud with Altinity.Cloud Anywhere 文章中描述的相同。
首先,下载并安装 hetzner-k3s 工具。
curl -fsSLO "https://github.com/janosmiko/hetzner-k3s/releases/latest/download/hetzner-k3s_`uname -s`_`uname -m`.deb"
sudo dpkg -i "hetzner-k3s_`uname -s`_`uname -m`.deb"
hetzner-k3s -v
hetzner-k3s version v0.1.9
Kubernetes 集群配置如下:使用位于美国东部(US Ashburn, VA)的 CPX31 服务器,它提供 4 个虚拟 CPU 和 8GB RAM。对于 S3,使用位于美国东部 1 区的 Wasabi S3 存储桶。
以下是我的 k3s_cluster.yaml 文件。请使用你的 Hetzner 项目 API 令牌以及公钥和私钥 SSH 密钥。
---
hetzner_token: <YOUR HETZNER PROJECT API TOKEN>
cluster_name: clickhouse-cloud
kubeconfig_path: "kubeconfig"
k3s_version: v1.29.4+k3s1
public_ssh_key_path: "/home/user/.ssh/<YOUR PUBLIC SSH KEY>.pub"
private_ssh_key_path: "/home/user/.ssh/<YOUR PRIVATE SSH KEY>"
image: "ubuntu-22.04"
verify_host_key: false
location: ash
schedule_workloads_on_masters: false
masters:
instance_type: cpx31
instance_count: 1
worker_node_pools:
- name: clickhouse
instance_type: cpx31
instance_count: 3
现在,我将使用以下命令创建我的 Kubernetes 集群:
hetzner-k3s create-cluster -c k3s_cluster.yaml
在集群设置完成后,检查所有节点是否都已启动并正常工作。请记住将 kubectl 指向我们集群的 kubeconfig 文件,该文件为集群创建,并位于与 k3s_cluster.yaml 相同的目录中。
kubectl --kubeconfig ./kubeconfig get nodes
NAME STATUS ROLES AGE VERSION
clickhouse-cloud-cpx31-master1 Ready control-plane,etcd,master 2m32s v1.29.4+k3s1
clickhouse-cloud-cpx31-pool-clickhouse-worker1 Ready <none> 2m20s v1.29.4+k3s1
clickhouse-cloud-cpx31-pool-clickhouse-worker2 Ready <none> 2m21s v1.29.4+k3s1
clickhouse-cloud-cpx31-pool-clickhouse-worker3 Ready <none> 2m22s v1.29.4+k3s1
安装 JuiceFS CSI Driver
在 Kubernetes 中使用 JuiceFS 的最佳方式是使用 JuiceFS CSI 驱动程序。该驱动程序允许我们通过定义 PVC 来创建 PV ,ClickHouse 将使用这些卷来存储数据,并为在 Kubernetes 上运行的应用程序提供了一种标准的存储暴露方式。我将使用 kubectl 方式来安装这个驱动程序。
kubectl --kubeconfig kubeconfig apply -f https://raw.githubusercontent.com/juicedata/juicefs-csi-driver/master/deploy/k8s.yaml
serviceaccount/juicefs-csi-controller-sa created
serviceaccount/juicefs-csi-dashboard-sa created
serviceaccount/juicefs-csi-node-sa created
clusterrole.rbac.authorization.k8s.io/juicefs-csi-dashboard-role created
clusterrole.rbac.authorization.k8s.io/juicefs-csi-external-node-service-role created
clusterrole.rbac.authorization.k8s.io/juicefs-external-provisioner-role created
clusterrolebinding.rbac.authorization.k8s.io/juicefs-csi-dashboard-rolebinding created
clusterrolebinding.rbac.authorization.k8s.io/juicefs-csi-node-service-binding created
clusterrolebinding.rbac.authorization.k8s.io/juicefs-csi-provisioner-binding created
service/juicefs-csi-dashboard created
deployment.apps/juicefs-csi-dashboard created
statefulset.apps/juicefs-csi-controller created
daemonset.apps/juicefs-csi-node created
csidriver.storage.k8s.io/csi.juicefs.com created
验证安装:
kubectl --kubeconfig kubeconfig -n kube-system get pods -l app.kubernetes.io/name=juicefs-csi-driver
NAME READY STATUS RESTARTS AGE
juicefs-csi-controller-0 4/4 Running 0 45s
juicefs-csi-controller-1 4/4 Running 0 34s
juicefs-csi-dashboard-58d9c54877-jrphl 1/1 Running 0 45s
juicefs-csi-node-7tsr8 3/3 Running 0 44s
juicefs-csi-node-mmxbk 3/3 Running 0 44s
juicefs-csi-node-njftm 3/3 Running 0 44s
juicefs-csi-node-rnkmz 3/3 Running 0 44s
创建 JuiceFS 元数据引擎 Redis 集群
在安装了 JuiceFS CSI 驱动程序后,我们需要设置一个元数据存储,因为 JuiceFS 使用了数据与元数据分离的架构,其中数据是呈现给用户的文件内容,元数据则是描述文件及文件系统本身的信息,如文件属性、文件系统结构、文件内容到 S3 对象的映射等。元数据存储可以使用不同的数据库来实现。我将创建一个简单的 Redis 集群。关于选择元数据存储的更多信息,请参见 JuiceFS 元数据引擎指南。
首先,让我们创建一个服务。
---
apiVersion: v1
kind: Service
metadata:
name: redis-service
namespace: redis
labels:
app: redis
spec:
ports:
- port: 6379
clusterIP: None
selector:
app: redis
接下来,我们需要创建简单的配置文件,这些文件将支持 Redis 主节点和从节点。
---
apiVersion: v1
kind: ConfigMap
metadata:
name: redis-config
namespace: redis
labels:
app: redis
data:
master.conf: |
maxmemory 1024mb
maxmemory-policy allkeys-lru
maxclients 20000
timeout 300
appendonly no
dbfilename dump.rdb
dir /data
secondary.conf: |
slaveof redis-0.redis.redis 6379
maxmemory 1024mb
maxmemory-policy allkeys-lru
maxclients 20000
timeout 300
dir /data
我将使用 StatefulSet 来定义 Redis 集群。需要注意的是,主节点和从节点将有不同的配置,其中 Pod 的序号索引用来确定主节点和从节点。在这次测试中,我们可以只使用 1 个副本,并且只为 /data 和 /etc 文件夹使用 10Gi 的卷。
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: redis
namespace: redis
spec:
serviceName: "redis-service"
replicas: 1
selector:
matchLabels:
app: redis
template:
metadata:
labels:
app: redis
spec:
initContainers:
- name: init-redis
image: redis:7.2.4
command:
- bash
- "-c"
- |
set -ex
# Generate redis server-id from pod ordinal index.
[[ `hostname` =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
# Copy appropriate redis config files from config-map to respective directories.
if [[ $ordinal -eq 0 ]]; then
cp /mnt/master.conf /etc/redis-config.conf
else
cp /mnt/slave.conf /etc/redis-config.conf
fi
volumeMounts:
- name: redis-claim
mountPath: /etc
- name: config-map
mountPath: /mnt/
containers:
- name: redis
image: redis:7.2.4
ports:
- containerPort: 6379
name: redis
command:
- redis-server
- "/etc/redis-config.conf"
volumeMounts:
- name: redis-data
mountPath: /data
- name: redis-claim
mountPath: /etc
volumes:
- name: config-map
configMap:
name: redis-config
volumeClaimTemplates:
- metadata:
name: redis-claim
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 10Gi
- metadata:
name: redis-data
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 10Gi
我还将为其创建一个专用的命名空间:
kubectl --kubeconfig kubeconfig create namespace redis
namespace/redis created
现在,可以创建 Redis 集群了。
kubectl --kubeconfig kubeconfig apply -n redis -f redis_cluster.yaml
service/redis-service created
configmap/redis-config created
statefulset.apps/redis created
让我们一起检查一下创建的资源。
kubectl --kubeconfig kubeconfig get configmap -n redis
NAME DATA AGE
kube-root-ca.crt 1 3m22s
redis-config 2 57s
kubectl --kubeconfig kubeconfig get svc -n redis
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
redis-service ClusterIP None <none> 6379/TCP 88s
kubectl --kubeconfig kubeconfig get statefulset -n redis
NAME READY AGE
redis 1/1 96s
kubectl --kubeconfig kubeconfig get pods -n redis
NAME READY STATUS RESTARTS AGE
redis-0 1/1 Running 0 115s
kubectl --kubeconfig kubeconfig get pvc -n redis
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
redis-claim-redis-0 Bound pvc-0d4c5dba-67f0-43df-a8e4-d44575e0bc1b 10Gi RWO hcloud-volumes <unset> 3m57s
redis-data-redis-0 Bound pvc-fc763f30-397f-455f-bd7e-c49db7a8d36e 10Gi RWO hcloud-volumes <unset> 3m57s
我们可以通过直接访问主节点进行检查。
kubectl --kubeconfig kubeconfig exec -it redis-0 -c redis -n redis -- /bin/bash
bash-5.2# redis-cli
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:5c09f7cf01eadafe8120d2c0862cb6c69b43c438
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
我们的元数据引擎已经就绪!
创建 JuiceFS 数据存储
之后,需要为 JuiceFS 创建一个数据存储。首先,我们需要定义一些秘钥,这些秘钥将用来指定我们的 S3 桶的凭证,然后再定义数据存储。 这是我的 juicefs-sc.yaml 文件。你需要指定你的桶、访问和秘钥。
---
apiVersion: v1
kind: Secret
metadata:
name: juicefs-secret
namespace: default
labels:
juicefs.com/validate-secret: "true"
type: Opaque
stringData:
name: ten-pb-fs
metaurl: redis://redis-service.redis:6379/1
storage: s3
bucket: https://<BUCKET>.s3.<REGION>.wasabisys.com
access-key: <ACCESS_KEY>
secret-key: <SECRET_KEY>
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: juicefs
provisioner: csi.juicefs.com
parameters:
csi.storage.k8s.io/provisioner-secret-name: juicefs-secret
csi.storage.k8s.io/provisioner-secret-namespace: default
csi.storage.k8s.io/node-publish-secret-name: juicefs-secret
csi.storage.k8s.io/node-publish-secret-namespace: default
按照以下步骤创建数据存储。
kubectl --kubeconfig kubeconfig apply -f juicefs-sc.yaml
secret/juicefs-secret created
storageclass.storage.k8s.io/juicefs created
现在检查一下,数据存储是否已经准备好了。
测试 JuiceFS
在为 JuiceFS 定义了一个数据存储后,我们现在可以通过定义一个 PVC 来测试它,然后我们可以在我们的测试应用程序的容器中使用它。 这是我的 juicefs-pvc-sc.yaml 文件,它使用了新的 juicefs StorageClass。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: juicefs-pvc
namespace: default
spec:
accessModes:
- ReadWriteMany
volumeMode: Filesystem
storageClassName: juicefs
resources:
requests:
storage: 10P
让我们应用它。
kubectl --kubeconfig kubeconfig apply -f juicefs-pvc-sc.yaml
persistentvolumeclaim/juicefs-pvc created
通过使用以下的 juicefs-app.yaml 文件创建一个简单的 pod 来进行测试。
apiVersion: v1
kind: Pod
metadata:
name: juicefs-app
namespace: default
spec:
containers:
- name: juicefs-app
image: centos
command:
- sleep
- "infinity"
volumeMounts:
- mountPath: /data
name: data
volumes:
- name: data
persistentVolumeClaim:
claimName: juicefs-pvc
启动 pod 并检查 /data 是否成功挂载。
kubectl --kubeconfig kubeconfig apply -f juicefs-app.yaml
pod/juicefs-app created
kubectl --kubeconfig kubeconfig exec -it -n default juicefs-app -- /bin/bash
[root@juicefs-app /]# ls /data
[root@juicefs-app /]#
我们的 pod 中已经挂载了 /data。JuiceFS 已经可以使用了!
运行 JuiceFS 提供的基准测试
将 JuiceFS 客户端安装到容器中,然后运行基准测试以检查文件系统是否按预期工作。
curl -sSL https://d.juicefs.com/install | sh -
运行只使用1个线程的基准测试。
juicefs bench -p 1 /data
Write big blocks: 1024/1024 [==============================================================] 96.9/s used: 10.566310616s
Read big blocks: 1024/1024 [==============================================================] 39.9/s used: 25.661374375s
Write small blocks: 100/100 [==============================================================] 11.0/s used: 9.059618651s
Read small blocks: 100/100 [==============================================================] 755.4/s used: 132.409568ms
Stat small files: 100/100 [==============================================================] 2566.2/s used: 39.04321ms
Benchmark finished!
BlockSize: 1 MiB, BigFileSize: 1024 MiB, SmallFileSize: 128 KiB, SmallFileCount: 100, NumThreads: 1
+------------------+----------------+---------------+
| ITEM | VALUE | COST |
+------------------+----------------+---------------+
| Write big file | 96.91 MiB/s | 10.57 s/file |
| Read big file | 39.91 MiB/s | 25.66 s/file |
| Write small file | 11.0 files/s | 90.59 ms/file |
| Read small file | 758.5 files/s | 1.32 ms/file |
| Stat file | 2604.5 files/s | 0.38 ms/file |
+------------------+----------------+---------------+
运行 4 线程的基准测试。
juicefs bench -p 4 /data
Write big blocks: 4096/4096 [==============================================================] 267.1/s used: 15.333303679s
Read big blocks: 4096/4096 [==============================================================] 112.3/s used: 36.469782933s
Write small blocks: 400/400 [==============================================================] 16.5/s used: 24.257067969s
Read small blocks: 400/400 [==============================================================] 2392.4/s used: 167.231047ms
Stat small files: 400/400 [==============================================================] 10742.0/s used: 37.281491ms
Benchmark finished!
BlockSize: 1 MiB, BigFileSize: 1024 MiB, SmallFileSize: 128 KiB, SmallFileCount: 100, NumThreads: 4
+------------------+-----------------+----------------+
| ITEM | VALUE | COST |
+------------------+-----------------+----------------+
| Write big file | 267.14 MiB/s | 15.33 s/file |
| Read big file | 112.32 MiB/s | 36.47 s/file |
| Write small file | 16.5 files/s | 242.56 ms/file |
| Read small file | 2401.8 files/s | 1.67 ms/file |
| Stat file | 10901.5 files/s | 0.37 ms/file |
+------------------+-----------------+----------------+
让我们将并行度提高到 4 倍,并使用 16 个线程重新运行基准测试。
juicefs bench -p 16 /data
Write big blocks: 16384/16384 [==============================================================] 307.2/s used: 53.335911256s
Read big blocks: 16384/16384 [==============================================================] 331.4/s used: 49.440177355s
Write small blocks: 1600/1600 [==============================================================] 48.9/s used: 32.723927882s
Read small blocks: 1600/1600 [==============================================================] 3181.2/s used: 503.016108ms
Stat small files: 1600/1600 [==============================================================] 9822.4/s used: 162.940025ms
Benchmark finished!
BlockSize: 1 MiB, BigFileSize: 1024 MiB, SmallFileSize: 128 KiB, SmallFileCount: 100, NumThreads: 16
+------------------+----------------+----------------+
| ITEM | VALUE | COST |
+------------------+----------------+----------------+
| Write big file | 307.19 MiB/s | 53.34 s/file |
| Read big file | 331.39 MiB/s | 49.44 s/file |
| Write small file | 48.9 files/s | 327.23 ms/file |
| Read small file | 3184.9 files/s | 5.02 ms/file |
| Stat file | 9852.3 files/s | 1.62 ms/file |
+------------------+----------------+----------------+
基准测试显示,JuiceFS 文件系统正常工作,并且随着工作线程数的增加,写入和读取速度也有所提升。
02 JuiceFS + ClickHouse MergeTree
我们现在准备将 JuiceFS 与 ClickHouse 结合使用。我们将使用 Altinity 的 clickhouse-operator 将 JuiceFS 与 ClickHouse 结合起来。我们将研究如何配置并使用 JuiceFS 磁盘用于 MergeTree 表,并将其简单的写入和读取性能与 ClickHouse 标准的非缓存和缓存 S3 磁盘进行比较,同时探讨可能出现的问题。
创建 ClickHouse 集群
在 Kubernetes 环境中创建 ClickHouse 集群之前,我们需要安装 clickhouse-operator。安装 clickhouse-operator 很简单,只需运行以下命令。我使用的版本是 0.23.5。
kubectl --kubeconfig kubeconfig apply -f https://raw.githubusercontent.com/Altinity/clickhouse-operator/release-0.23.5/deploy/operator/clickhouse-operator-install-bundle.yaml
我将使用下方的 clickhouse_cluster.yaml 文件来定义 ClickHouse 集群。它配置了一个包含所有磁盘和卷的 storage.xml 配置文件。更多细节可查阅 ClickHouse 文档中关于 External Disks for Storing Data 的部分。
鉴于我们将 JuiceFS 作为一个标准文件夹挂载,我们定义 JuiceFS 磁盘为本地磁盘,并将数据存放在 juicefs-data 文件夹中。
<clickhouse>
<storage_configuration>
<disks>
<juicefs>
<type>local</type>
<path>/juicefs-disk/juicefs-data/</path>
</juicefs>
</disks>
</storage_configuration>
</clickhouse>
这个磁盘对应于下面定义的卷挂载路径 /juicefs-disk/。
volumeMounts:
- name: juicefs-storage-vc-template
mountPath: /juicefs-disk
juicefs-storage-vc-template 是一个卷声明模板,它使用了我们为JuiceFS创建的 juicefs StorageClass。
volumeClaimTemplates:
- name: juicefs-storage-vc-template
spec:
accessModes:
- ReadWriteOnce
volumeMode: Filesystem
storageClassName: juicefs
resources:
requests:
storage: 10P
这是完整的 clickhouse_cluster.yaml 定义。
apiVersion: "clickhouse.altinity.com/v1"
kind: "ClickHouseInstallation"
metadata:
name: "ch-juicefs"
spec:
configuration:
files:
storage.xml: |
<clickhouse>
<storage_configuration>
<disks>
<s3>
<type>s3</type>
<endpoint>https://BUCKET.s3.REGION.wasabisys.com/s3-data/{replica}/</endpoint>
<access_key_id>ACCESS_KEY</access_key_id>
<secret_access_key>SECRET_KEY</secret_access_key>
</s3>
<s3_cache>
<type>cache</type>
<disk>s3</disk>
<path>/s3_cache/</path>
<max_size>10Gi</max_size>
</s3_cache>
<juicefs>
<type>local</type>
<path>/juicefs-disk/juicefs-data/</path>
</juicefs>
</disks>
<policies>
<s3>
<volumes>
<main>
<disk>s3</disk>
</main>
</volumes>
</s3>
<s3_cache>
<volumes>
<main>
<disk>s3_cache</disk>
</main>
</volumes>
</s3_cache>
<juicefs>
<volumes>
<main>
<disk>juicefs</disk>
</main>
</volumes>
</juicefs>
</policies>
</storage_configuration>
</clickhouse>
clusters:
- name: "ch-juicefs"
templates:
podTemplate: pod-template-with-volumes
layout:
shardsCount: 1
replicasCount: 1
templates:
podTemplates:
- name: pod-template-with-volumes
spec:
containers:
- name: clickhouse
image: altinity/clickhouse-server:23.8.11.29.altinitystable
volumeMounts:
- name: data-storage-vc-template
mountPath: /var/lib/clickhouse
- name: log-storage-vc-template
mountPath: /var/log/clickhouse-server
- name: juicefs-storage-vc-template
mountPath: /juicefs-disk
volumeClaimTemplates:
- name: juicefs-storage-vc-template
spec:
accessModes:
- ReadWriteOnce
volumeMode: Filesystem
storageClassName: juicefs
resources:
requests:
storage: 10P
- name: data-storage-vc-template
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Gi
- name: log-storage-vc-template
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
为了简化操作,我选择了一个只有一个分片和副本的集群。现在,让我们应用 clickhouse_cluster.yaml 来创建这个集群。
kubectl --kubeconfig kubeconfig apply -f clickhouse_cluster.yaml
clickhouseinstallation.clickhouse.altinity.com/ch-juicefs created
创建集群后,我们可以进入 ClickHouse 服务器的 pod 并启动 clickhouse-client 来检查可用的磁盘。
kubectl --kubeconfig kubeconfig exec -it -n default chi-ch-juicefs-ch-juicefs-0-0-0 -- /bin/bash
然后可以启动 clickhouse-client。
Clickhouse-client
在 clickhouse-client 中,可以使用以下查询来检查可用的磁盘。
SELECT * FROM system.disks
┌─name─────┬─path──────────────────────────┬───────────free_space─┬──────────total_space─┬─────unreserved_space─┬─keep_free_space─┬─type──┬─is_encrypted─┬─is_read_only─┬─is_write_once─┬─is_remote─┬─is_broken─┬─cache_path─┐
│ default │ /var/lib/clickhouse/ │ 64848461824 │ 105089261568 │ 64848461824 │ 0 │ local │ 0 │ 0 │ 0 │ 0 │ 0 │ │
│ juicefs │ /juicefs-disk/juicefs-data/ │ 1125830005723136 │ 1125830005731328 │ 1125830005723136 │ 0 │ local │ 0 │ 0 │ 0 │ 0 │ 0 │ │
│ s3 │ /var/lib/clickhouse/disks/s3/ │ 18446744073709551615 │ 18446744073709551615 │ 18446744073709551615 │ 0 │ s3 │ 0 │ 0 │ 0 │ 1 │ 0 │ │
│ s3_cache │ /var/lib/clickhouse/disks/s3/ │ 18446744073709551615 │ 18446744073709551615 │ 18446744073709551615 │ 0 │ s3 │ 0 │ 0 │ 0 │ 1 │ 0 │ /s3_cache/ │
└──────────┴───────────────────────────────┴──────────────────────┴──────────────────────┴──────────────────────┴─────────────────┴───────┴──────────────┴──────────────┴───────────────┴───────────┴───────────┴────────────┘
现在有了四种磁盘类型:默认、juicefs、s3 和 s3_cache ,我们可以创建不同的 MergeTree 表来检验每种磁盘类型的性能。
加载测试数据集
对于基本性能测试,我将使用包含13亿条记录的 NYC taxi rides dataset ,该数据集可以通过我们的公共 S3 桶获得。
首先将整个数据集复制到 chi-ch-juicefs-ch-juicefs-0-0-0 pod 中的 /var/lib/clickhouse/user_files 文件夹,这样稍后我就可以使用 file() 表函数将其加载到使用不同磁盘的表中。
cd /var/lib/clickhouse/user_files
mkdir -p datasets/tripdata
cd datasets/tripdata
aws --no-sign-request s3 cp --recursive s3://altinity-clickhouse-data/nyc_taxi_rides/data/tripdata .
数据集加载完成后,我们可以开始创建 MergeTree 表了。
创建 MergeTree
我将创建三个不同的表,每个磁盘一个,分别命名为 tripdata_juicefs、tripdata_s3、tripdata_s3_cache。下面是 CREATE TABLE 查询的模板,其中 <NAME> 可以是 juicefs、s3 或 s3_cache。
CREATE TABLE IF NOT EXISTS tripdata_<NAME> (
pickup_date Date DEFAULT toDate(pickup_datetime) CODEC(Delta, LZ4),
id UInt64,
vendor_id String,
pickup_datetime DateTime CODEC(Delta, LZ4),
dropoff_datetime DateTime,
passenger_count UInt8,
trip_distance Float32,
pickup_longitude Float32,
pickup_latitude Float32,
rate_code_id String,
store_and_fwd_flag String,
dropoff_longitude Float32,
dropoff_latitude Float32,
payment_type LowCardinality(String),
fare_amount Float32,
extra String,
mta_tax Float32,
tip_amount Float32,
tolls_amount Float32,
improvement_surcharge Float32,
total_amount Float32,
pickup_location_id UInt16,
dropoff_location_id UInt16,
junk1 String,
junk2 String)
ENGINE = MergeTree
PARTITION BY toYYYYMM(pickup_date)
ORDER BY (vendor_id, pickup_location_id, pickup_datetime)
SETTINGS storage_policy='<NAME>';
这里有一些关于表定义的简短示例。
CREATE TABLE IF NOT EXISTS tripdata_juicefs (
...
SETTINGS storage_policy='juicefs';
CREATE TABLE IF NOT EXISTS tripdata_s3 (
...
SETTINGS storage_policy='s3';
CREATE TABLE IF NOT EXISTS tripdata_s3_cache (
...
SETTINGS storage_policy='s3_cache';
```
检查表是否已成功创建。
```bash
SHOW TABLES
┌─name──────────────┐
│ tripdata_juicefs │
| tripdata_s3 |
│ tripdata_s3_cache │
└───────────────────┘
写性能
数据集加载完毕,数据表创建完成后,我们就可以开始比较 JuiceFS 与标准无缓存 S3 以及有缓存 S3 磁盘的性能差异了。
让我们将数据集插入到 tripdata_juicefs 表中。
INSERT INTO tripdata_juicefs
SELECT * FROM file('datasets/tripdata/data-*.csv.gz',
'CSVWithNames',
'pickup_date Date, id UInt64, vendor_id String, tpep_pickup_datetime DateTime, tpep_dropoff_datetime DateTime, passenger_count UInt8, trip_distance Float32, pickup_longitude Float32, pickup_latitude Float32, rate_code_id String, store_and_fwd_flag String, dropoff_longitude Float32, dropoff_latitude Float32, payment_type LowCardinality(String), fare_amount Float32, extra String, mta_tax Float32, tip_amount Float32, tolls_amount Float32, improvement_surcharge Float32, total_amount Float32, pickup_location_id UInt16, dropoff_location_id UInt16, junk1 String, junk2 String',
'gzip')
settings max_threads=8, max_insert_threads=8, input_format_parallel_parsing=0;
0 rows in set. Elapsed: 1159.444 sec. Processed 1.31 billion rows, 39.98 GB (1.13 million rows/s., 34.48 MB/s.)
现在,让我们 对 tripdata_s3 表,做相同的操作.
INSERT INTO tripdata_s3
SELECT * FROM file('datasets/tripdata/data-*.csv.gz',
'CSVWithNames',
'pickup_date Date, id UInt64, vendor_id String, tpep_pickup_datetime DateTime, tpep_dropoff_datetime DateTime, passenger_count UInt8, trip_distance Float32, pickup_longitude Float32, pickup_latitude Float32, rate_code_id String, store_and_fwd_flag String, dropoff_longitude Float32, dropoff_latitude Float32, payment_type LowCardinality(String), fare_amount Float32, extra String, mta_tax Float32, tip_amount Float32, tolls_amount Float32, improvement_surcharge Float32, total_amount Float32, pickup_location_id UInt16, dropoff_location_id UInt16, junk1 String, junk2 String',
'gzip')
settings max_threads=8, max_insert_threads=8, input_format_parallel_parsing=0;
0 rows in set. Elapsed: 1098.654 sec. Processed 1.31 billion rows, 39.98 GB (1.19 million rows/s., 36.39 MB/s.)
最后,我们完成 tripdata_s3_cache 表的设置。
INSERT INTO tripdata_s3_cache
SELECT * FROM file('datasets/tripdata/data-*.csv.gz',
'CSVWithNames',
'pickup_date Date, id UInt64, vendor_id String, tpep_pickup_datetime DateTime, tpep_dropoff_datetime DateTime, passenger_count UInt8, trip_distance Float32, pickup_longitude Float32, pickup_latitude Float32, rate_code_id String, store_and_fwd_flag String, dropoff_longitude Float32, dropoff_latitude Float32, payment_type LowCardinality(String), fare_amount Float32, extra String, mta_tax Float32, tip_amount Float32, tolls_amount Float32, improvement_surcharge Float32, total_amount Float32, pickup_location_id UInt16, dropoff_location_id UInt16, junk1 String, junk2 String',
'gzip')
settings max_threads=8, max_insert_threads=8, input_format_parallel_parsing=0;
0 rows in set. Elapsed: 1090.200 sec. Processed 1.31 billion rows, 39.98 GB (1.20 million rows/s., 36.67 MB/s.)
让我们完成写入性能的数据图表。
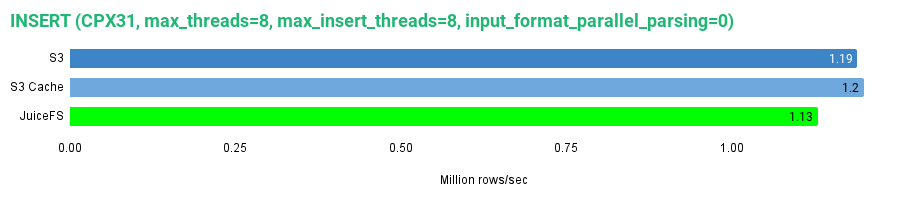
如图所示,在我们特定的测试环境中,写入 JuiceFS 磁盘的速度略慢于写入 S3 以及 S3 缓存磁盘,但差距并不显著。我们达到了每秒 113 万行的写入速度。接下来,让我们看看读取性能。 读性能 我们可以通过选择测试表中的所有行来读取整个数据集,从而检查读取性能。考虑到某些磁盘会使用缓存,我们将对每个磁盘连续执行五次查询。
让我们从 JuiceFS 开始,读取 tripdata_juicefs 表中的所有数据。
SELECT * FROM tripdata_juicefs FORMAT Null SETTINGS max_threads = 8, max_insert_threads = 8, input_format_parallel_parsing = 0;
我获得了以下结果:
0 rows in set. Elapsed: 172.750 sec. Processed 1.31 billion rows, 114.15 GB (7.59 million rows/s., 660.76 MB/s.)
Peak memory usage: 103.08 MiB.
0 rows in set. Elapsed: 94.315 sec. Processed 1.31 billion rows, 114.15 GB (13.90 million rows/s., 1.21 GB/s.)
Peak memory usage: 153.77 MiB.
0 rows in set. Elapsed: 76.713 sec. Processed 1.31 billion rows, 114.15 GB (17.09 million rows/s., 1.49 GB/s.)
Peak memory usage: 151.27 MiB.
0 rows in set. Elapsed: 73.887 sec. Processed 1.31 billion rows, 114.15 GB (17.74 million rows/s., 1.54 GB/s.)
Peak memory usage: 149.49 MiB.
0 rows in set. Elapsed: 74.713 sec. Processed 1.31 billion rows, 114.15 GB (17.55 million rows/s., 1.53 GB/s.)
Peak memory usage: 151.51 MiB.
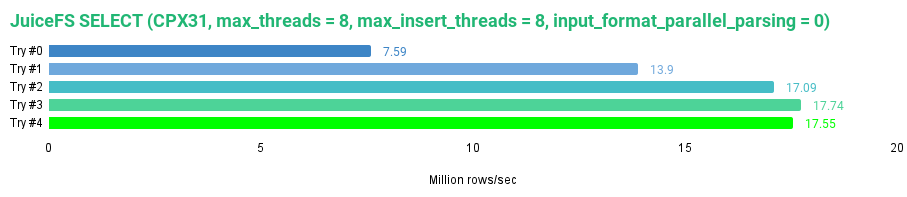
从上述 JuiceFS 的数据中我们可以看出,JuiceFS 确实能够缓存数据以便于后续读取时提供更快的访问速度,达到了最高读取速度1.53 GB/s,对于我们的数据集而言,是每秒 1755 万行。JuiceFS 缓存的默认设置是 100 GB,并使用 2-random 策略进行数据块的淘汰。
现在,让我们对 tripdata_s3 表执行相同的操作。
SELECT * FROM tripdata_s3 FORMAT Null SETTINGS max_threads = 8, max_insert_threads = 8, input_format_parallel_parsing = 0;
以下是我的结果:
0 rows in set. Elapsed: 256.445 sec. Processed 1.31 billion rows, 114.15 GB (5.11 million rows/s., 445.11 MB/s.)
Peak memory usage: 220.41 MiB.
0 rows in set. Elapsed: 176.409 sec. Processed 1.31 billion rows, 114.15 GB (7.43 million rows/s., 647.05 MB/s.)
Peak memory usage: 280.11 MiB.
0 rows in set. Elapsed: 195.219 sec. Processed 1.31 billion rows, 114.15 GB (6.72 million rows/s., 584.71 MB/s.)
Peak memory usage: 282.05 MiB.
0 rows in set. Elapsed: 252.489 sec. Processed 1.31 billion rows, 114.15 GB (5.19 million rows/s., 452.08 MB/s.)
Peak memory usage: 281.88 MiB.
0 rows in set. Elapsed: 238.748 sec. Processed 1.31 billion rows, 114.15 GB (5.49 million rows/s., 478.10 MB/s.)
Peak memory usage: 279.51 MiB.
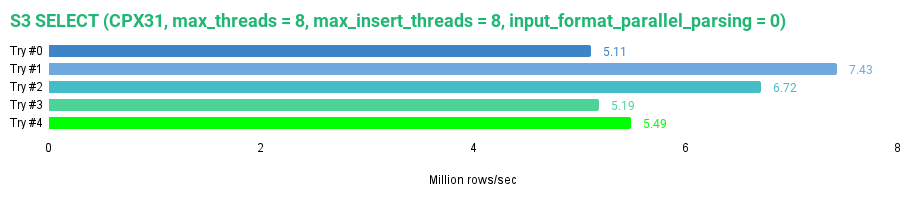
S3 磁盘不使用任何缓存,因此每次查询都需要通过 S3 API 调用来读取整个数据集。从读取速度的不一致性可以看出这一点,速度范围从 445 MB/s 到 647 MB/s,或者是 511 万到7 43 万行/秒。由于 JuiceFS 默认使用缓存,因此它的速度比无缓存的 S3 磁盘要快。
最后,让我们从 tripdata_s3_cache 中读取所有数据。
SELECT * FROM tripdata_s3_cache FORMAT Null SETTINGS max_threads = 8, max_insert_threads = 8, input_format_parallel_parsing = 0;
这是我获得的结果:
0 rows in set. Elapsed: 252.166 sec. Processed 1.31 billion rows, 114.15 GB (5.20 million rows/s., 452.66 MB/s.)
Peak memory usage: 4.12 GiB.
0 rows in set. Elapsed: 155.952 sec. Processed 1.31 billion rows, 114.15 GB (8.41 million rows/s., 731.93 MB/s.)
Peak memory usage: 7.94 GiB.
0 rows in set. Elapsed: 144.535 sec. Processed 1.31 billion rows, 114.15 GB (9.07 million rows/s., 789.75 MB/s.)
Peak memory usage: 8.40 GiB.
0 rows in set. Elapsed: 141.699 sec. Processed 1.31 billion rows, 114.15 GB (9.25 million rows/s., 805.55 MB/s.)
Peak memory usage: 8.58 GiB.
0 rows in set. Elapsed: 142.764 sec. Processed 1.31 billion rows, 114.15 GB (9.18 million rows/s., 799.54 MB/s.)
Peak memory usage: 8.53 GiB.
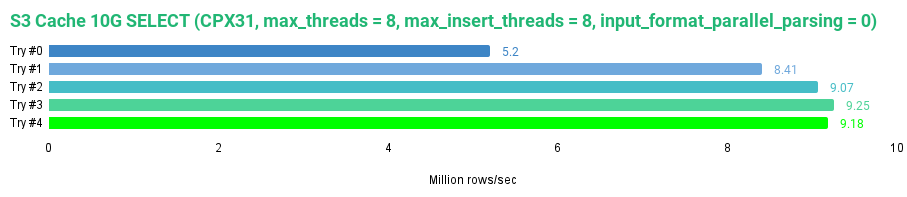
与无缓存的 S3 磁盘相比,s3_cache 磁盘提高了性能。我们达到了 805MB/s 的速度,相当于每秒处理 925 万行。然而,这仍然慢于默认设置下的 JuiceFS。
现在,让我们再试一次使用 s3_cache 磁盘,但这次我们将缓存大小设置为 50GB,而不是最初的 10GB。我们通过修改 s3_cache 磁盘的定义来实现这一点。
<s3_cache>
<type>cache</type>
<disk>s3</disk>
<path>/s3_cache/</path>
<max_size>50Gi</max_size>
</s3_cache>
在修改了 clickhouse_cluster.yaml 并重新应用之后,这将重启容器和服务器,接着我们可以执行 SELECT 查询。
SELECT * FROM tripdata_s3_cache FORMAT Null SETTINGS max_threads = 8, max_insert_threads = 8, input_format_parallel_parsing = 0;
当缓存设置为 50GB 时,结果如下:
0 rows in set. Elapsed: 643.662 sec. Processed 1.31 billion rows, 114.15 GB (2.04 million rows/s., 177.34 MB/s.)
Peak memory usage: 4.23 GiB.
0 rows in set. Elapsed: 51.423 sec. Processed 1.31 billion rows, 114.15 GB (25.49 million rows/s., 2.22 GB/s.)
Peak memory usage: 417.64 MiB.
0 rows in set. Elapsed: 51.678 sec. Processed 1.31 billion rows, 114.15 GB (25.37 million rows/s., 2.21 GB/s.)
Peak memory usage: 416.17 MiB.
0 rows in set. Elapsed: 50.358 sec. Processed 1.31 billion rows, 114.15 GB (26.03 million rows/s., 2.27 GB/s.)
Peak memory usage: 418.08 MiB.
0 rows in set. Elapsed: 51.055 sec. Processed 1.31 billion rows, 114.15 GB (25.68 million rows/s., 2.24 GB/s.)
Peak memory usage: 410.55 MiB.
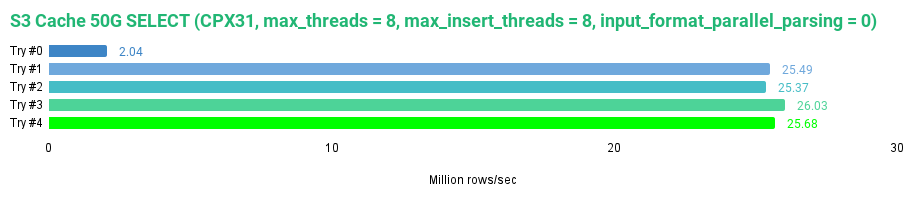
在比较不同缓存大小的 S3 磁盘时,我们发现当缓存大小为 50GB 时,整个数据集可以被缓存,其读取速度比 10GB 缓存快了将近 1GB/s。对于 S3 磁盘而言,选择更大的缓存显然是更理想的选择。在我们的测试中,使用 50GB 的缓存比使用 JuiceFS 的默认设置具有更快的读取性能。
编者注:作者使用的是默认设置,调优 JuiceFS 挂载参数后,性能可能会进一步提升。
现在,我们可以比较我们测试过的所有磁盘的整体平均读取性能。
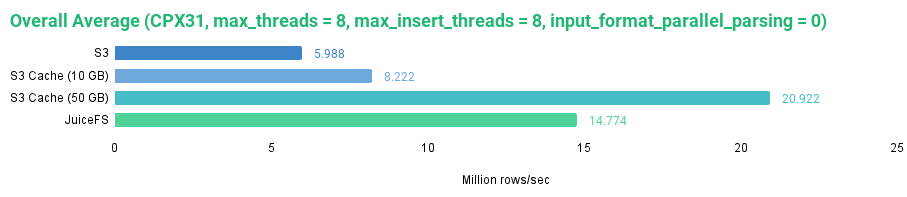
如图所示,JuiceFS 在默认设置下表现相当不错。它的速度快于没有缓存的 S3 磁盘和 10GB 缓存的 S3 磁盘,但慢于 50GB 缓存的 S3 磁盘。
潜在问题
虽然我们已经实现了JuiceFS 与 ClickHouse 的结合,但这是一个测试环境,在生产环境中使用它仍然面临挑战。以下是一些可能出现的问题:
- 管理 JuiceFS 的元数据存储增加了复杂性。
- 在本地磁盘的路径中不展开宏(Marcros)。因此,如果你想在不同的路径上为每个副本保留数据,以便在移除副本时容易清理孤立数据,每个副本必须有一个自定义的存储配置文件。
- ClickHouse 不支持本地磁盘的零拷贝复制,这意味着每个副本都会创建一个重复的副本。
- 从 23.5 版本开始,ClickHouse 不再支持本地类型磁盘的缓存,因此你只能依赖 JuiceFS 的缓存。
- 使用 JuiceFS 和 ClickHouse 的整体可靠性需要进行测试。
上述五点中的三点与 ClickHouse 相关,可进一步在 ClickHouse 中改进,例如为本地磁盘的路径支持宏展开,为已实现复制的磁盘提供零拷贝复制的通用支持,以及恢复对 ClickHouse 作为本地磁盘(实际上是通过分布式文件系统挂载的磁盘)的缓存支持。
03 结论
目前,我们对将 JuiceFS 与 ClickHouse 结合使用的探索暂告一段落。在 Kubernetes 中部署JuiceFS 虽然简单,但部署独立的元数据存储增加了复杂性。然而,一旦一切就绪,使用clickhouse-operator 来管理 CSI 驱动非常简单直接。由于 JuiceFS 磁盘可以当作本地磁盘使用,ClickHouse 的配置也非常简单。磁盘的整体性能很好,我们没有进行性能优化,仅使用了默认设置。
将 S3 存储作为与 POSIX 兼容的文件系统使用的想法非常吸引人,因为它能让任何应用程序无缝集成 S3 存储。但是,没有元数据存储,S3 上的数据将无法被访问,这使得元数据存储成为了基础设施的关键组成部分。如果我们没有元数据存储,那么所有的数据也将丢失。但是,在 S3 上使用 ClickHouse 时,也需要依赖本地元数据来映射 S3 中的对象,因此元数据存储必不可缺。使用 JuiceFS 和 ClickHouse 的整体可靠性还需要进一步验证,我们需要找到应对潜在问题的办法。我们已经证明了集成 ClickHouse 与 JuiceFS 的可行性,JuiceFS 非常值得进一步探索。
