














背景
海量且优质的数据集是一个好的 AI 模型的基石之一,如何存储、管理这些数据集,以及在模型训练时提升 I/O 效率一直都是 AI 平台工程师和算法科学家特别关注的事情。不论是单机训练还是分布式训练,I/O 的性能都会显著影响整体 pipeline 的效率,甚至是最终的模型质量。
我们也逐渐看到容器化成为 AI 训练的趋势,利用容器可以快速弹性伸缩的特点,结合公有云的资源池,能够最大化资源利用率,为企业大大节约成本。因此也就诞生了类似 Kubeflow 和 Volcano 这样的开源组件,帮助用户在 Kubernetes 上管理 AI 任务。Kubernetes 自 1.15 开始新增了 Scheduling Framework,社区也基于这个新的调度框架优化了很多针对 AI 训练场景的问题。前面提到的训练数据管理问题在 Kubernetes 上依然存在,甚至放大了这个需求,因为计算不再是在固定的几台机器上进行,数据需要智能地跟随计算「流动」(或者反过来)。
最后,不管是算法科学家日常实验,还是正式训练模型,POSIX 接口依然是一个很强烈的需求,虽然主流的框架或者算法库基本都支持对象存储接口但 POSIX 仍然是「第一公民」。一些操作系统的高级特性(如 page cache)也是只有 POSIX 接口才具备的。
AI 平台整体架构

上面是一个常见的 AI 平台架构图。存储系统目前使用比较多的就是对象存储和 HDFS,这里之所以还会用到 HDFS 有多种原因,比如平台部署在机房没有对象存储,训练数据集预处理是在大数据平台等。计算资源混合了 CPU 实例和 GPU 实例,和大数据平台不一样的地方在于,AI 平台的资源天生就是异构的,因此怎么合理高效利用这些异构资源一直是个业界难题。调度器前面已经介绍到,Kubernetes 是目前主流的组件,结合各种 Job Operator、Volcano、调度插件可以最大程度上发挥 Kubernetes 的能力。Pipeline 是很重要的一个部分,AI 任务并不只是由模型训练这一个步骤组成,还包括数据预处理、特征工程、模型验证、模型评估、模型上线等多个环节,因此 Pipeline 管理也是非常重要的。最后就是算法科学家接触最多的深度学习框架,这些框架目前都有自己的使用群体,很多模型优化会基于某种框架进行(比如 TensorFlow 的 XLA),但也有和框架无关的(比如 TVM)。
本文的关注点在于最底层的存储层,在保持上层组件不变的情况下,如何优化存储层的 I/O 效率。这部分包括但不限于数据缓存、预读、并发读、调度优化等策略,JuiceFS 便是这样一个存储层的增强组件,能够大幅提升 I/O 效率,下面会详细介绍。
JuiceFS 简介
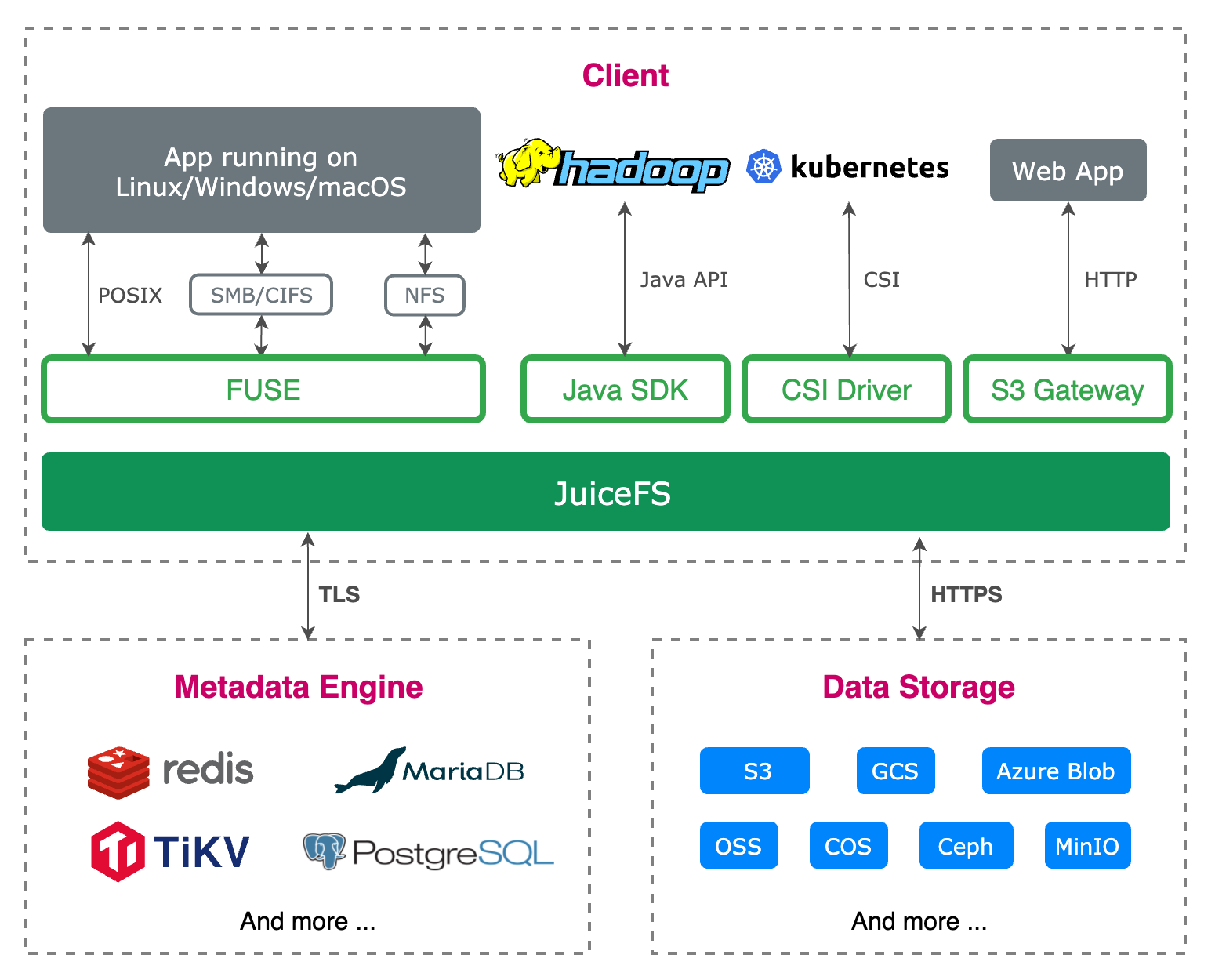
JuiceFS 是一个面向云原生环境设计的高性能开源分布式文件系统,完全兼容 POSIX、HDFS、S3 接口,适用于大数据、AI 模型训练、Kubernetes 共享存储、海量数据归档管理等场景。
当通过 JuiceFS 客户端读取数据时,这些数据将会智能地缓存到应用配置的本地缓存路径(可能是内存,也可能是磁盘),同时元数据也会缓存到客户端节点本地内存中。对于 AI 模型训练场景来说,第一个 epoch 完成之后后续的计算都可以直接从缓存中获取训练数据,极大地提升了训练效率。
JuiceFS 也具有预读、并发读取数据的能力,保证每个 mini-batch 的生成效率,提前准备好数据。
此外 JuiceFS 还提供标准的 Kubernetes CSI Driver,应用可以把 JuiceFS 文件系统作为一个共享的 Persistent Volume(PV)同时挂载到多个容器中。
得益于以上特性的支持,算法科学家可以很轻松地管理训练数据,就像访问本地存储一样,无需修改框架进行专门的适配,训练效率也能得到一定的保障。
测试方案
为了验证使用 JuiceFS 以后模型训练的效果,我们选取常见的 ResNet50 模型以及 ImageNet 数据集,训练任务使用了 DLPerf 项目提供的脚本,对应的深度学习框架是 PyTorch。训练节点配置了 8 块 NVIDIA A100 显卡。
作为对比,我们将公有云上的对象存储作为基准线(通过类 S3FS 的方式进行访问),同时和开源项目 Alluxio 进行比较,分别测试了 1 机 1 卡、1 机 4 卡、1 机 8 卡不同配置下的训练效率(即每秒处理的样本数)。
不论是 JuiceFS 还是 Alluxio,训练数据集都提前预热到了内存中,数据集约占用 160G 空间。JuiceFS 提供了 warmup 子命令可以很方便地进行数据集的缓存预热,只需指定需要预热的目录或者文件列表即可。
测试方法是每种配置都跑多轮训练,每轮只跑 1 个 epoch,将每轮的统计结果汇总,在排除一些可能的异常数据以后,计算得出整体的训练效率。
JuiceFS 配置选项说明
AI 模型训练场景的 I/O 模式是典型的只读模式,即只会对数据集产生读请求,不会修改数据。因此为了最大化 I/O 效率,可以适当调整一些配置选项(如缓存相关配置),下面详细介绍几个重要的 JuiceFS 配置选项。
元数据缓存
在内核中可以缓存三种元数据:属性(attribute)、文件项(entry)和目录项(direntry),它们可以通过如下三个选项控制缓存时间:
--attr-cache value 属性缓存过期时间;单位为秒 (默认: 1)
--entry-cache value 文件项缓存过期时间;单位为秒 (默认: 1)
--dir-entry-cache value 目录项缓存过期时间;单位为秒 (默认: 1)默认元数据在内核中只缓存 1 秒钟,可以根据训练时长适当增大缓存时间,如 2 小时(7200 秒)。
当打开一个文件时(即 open() 请求),为了保证一致性,JuiceFS 默认都会请求元数据引擎以获取最新的元信息。由于数据集都是只读的,因此可以适当调整处理策略,设置检查文件是否更新的间隔时间,如果时间没有到达设定的值,则不需要访问元数据引擎,可以大幅提升打开文件的性能。相关配置选项是:
--open-cache value 打开的文件的缓存过期时间(0 代表关闭这个特性);单位为秒 (默认: 0)数据缓存
对于已经读过的文件,内核会把它的内容自动缓存下来,下次再打开的时候,如果文件没有被更新(即 mtime 没有更新),就可以直接从内核中的缓存(page cache)读获得最好的性能。因此当第一个 epoch 运行完毕,如果计算节点的内存足够,那大部分数据集可能都已经缓存到 page cache 中,这样之后的 epoch 将可以不需要经过 JuiceFS 读取数据,性能也能大幅提升。这个特性已经默认在 0.15.2 及以上版本的 JuiceFS 中开启,不需要做任何配置。
除了内核中的数据缓存,JuiceFS 还支持将数据缓存到本地文件系统中,可以是基于硬盘、SSD 或者内存的任意本地文件系统。本地缓存可以通过以下选项来调整:
--cache-dir value 本地缓存目录路径;使用冒号隔离多个路径 (默认: "$HOME/.juicefs/cache" 或 "/var/jfsCache")
--cache-size value 缓存对象的总大小;单位为 MiB (默认: 1024)
--free-space-ratio value 最小剩余空间比例 (默认: 0.1)
--cache-partial-only 仅缓存随机小块读 (默认: false)例如要将数据缓存到内存中有两种方式,一种是将 --cache-dir 设置为 memory,另一种是将其设置为 /dev/shm。这两种方式的区别是前者在重新挂载 JuiceFS 文件系统之后缓存数据就清空了,而后者还会保留,性能上两者没有太大差别。下面是将数据缓存到 /dev/shm/jfscache 并且限定最多使用 300GiB 内存的示例:
--cache-dir /dev/shm/jfscache --cache-size 307200JuiceFS 也支持将数据缓存到多个路径,默认会采用轮询的方式写入缓存数据,多个路径通过冒号分隔,例如:
--cache-dir /data1:/data2:/data3Alluxio 配置选项说明
Alluxio 的所有组件(如 master、worker、FUSE)都是部署在同一个节点,使用的版本是 2.5.0-2。具体配置如下:
配置项设定值alluxio.master.journal.typeUFSalluxio.user.block.size.bytes.default32MBalluxio.user.local.reader.chunk.size.bytes32MBalluxio.user.metadata.cache.enabledtruealluxio.user.metadata.cache.expiration.time2dayalluxio.user.streaming.reader.chunk.size.bytes32MBalluxio.worker.network.reader.buffer.size128MB
此外 Alluxio FUSE 启动时指定的挂载选项是:kernel_cache,ro,max_read=131072,attr_timeout=7200,entry_timeout=7200,nonempty。
测试结果
测试结果包含两个场景,一种使用了内核的 page cache,另一种没有使用。前面提到测试方法是每种配置跑多轮训练,当跑完第一轮以后,后续的测试都有可能直接从 page cache 中读取数据。因此我们设计了第二种场景,来测试没有 page cache 时的训练效率(比如模型训练的第一个 epoch),这种场景能更真实反映底层存储系统的实际性能。
对于第一种场景,JuiceFS 不需要额外配置即可有效利用内核的 page cache,但是对象存储和 Alluxio 的默认配置都不支持这个特性,需要单独进行设置。
需要特别注意的是,我们在测试对象存储的过程中曾经尝试过开启 S3FS 的本地缓存特性,希望达到类似 JuiceFS 和 Alluxio 的缓存效果。但是实际测试时发现即使已经全量预热缓存,以及无论用多少块显卡,1 个 epoch 都无法在 1 天内跑完,甚至比没有缓存时更慢。因此以下测试结果中的「对象存储」未包含开启本地缓存以后的数据。
下图是两个场景的测试结果(「w/o PC」表示没有 page cache):
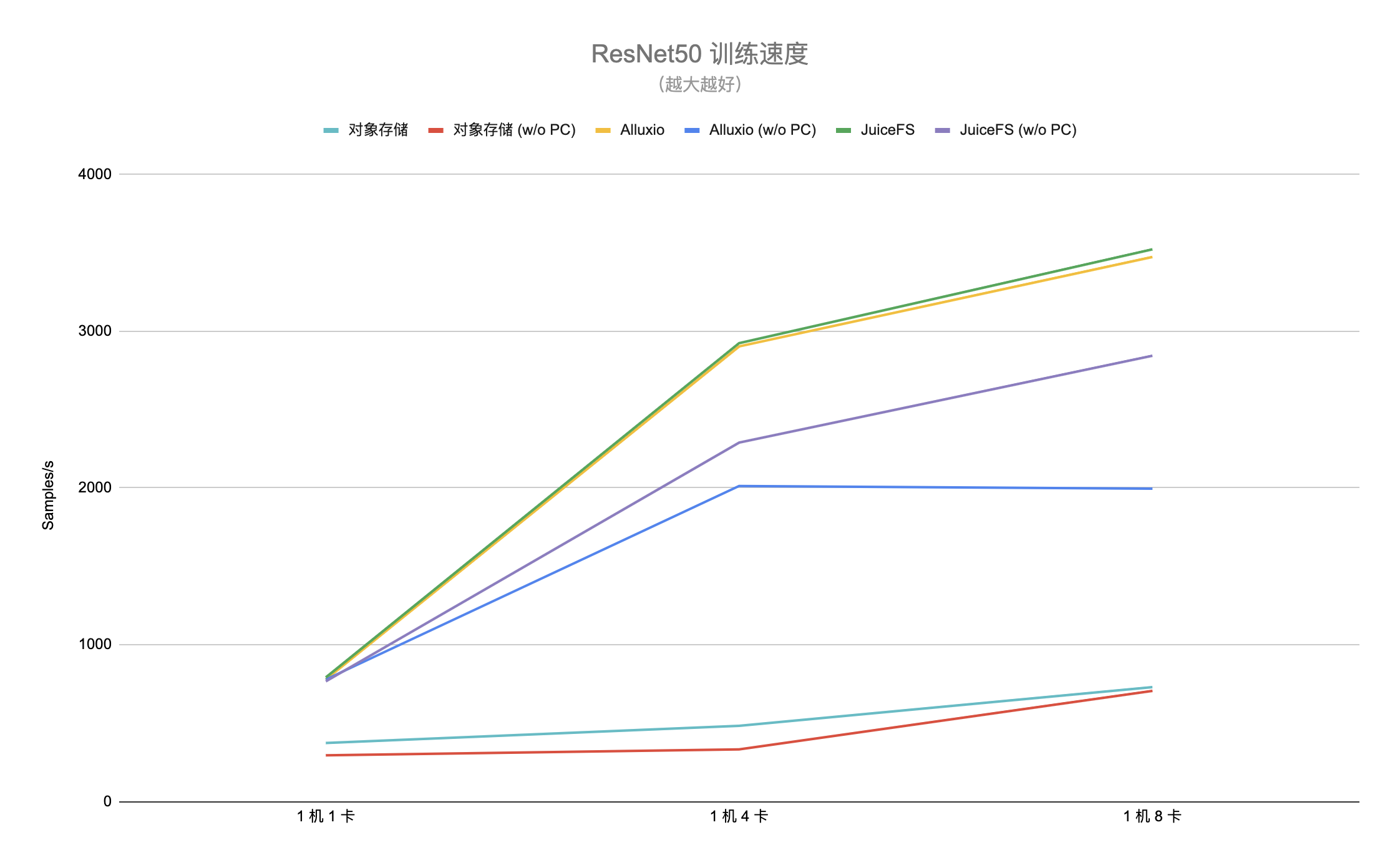
得益于元数据缓存和数据缓存,可以看到不管是在哪种场景下,JuiceFS 相比对象存储平均都能达到 4 倍以上的性能提升,最多能有接近 7 倍的性能差距。同时由于对象存储的访问方式没有有效利用内核的 page cache,因此它在这两种场景的性能差距不大。另外在完整的端到端模型训练测试中,因为对象存储的训练效率太低,跑到指定模型精度所需时间过长,在生产环境中基本属于不可用状态。
对比 Alluxio,在有 page cache 的第一种场景中与 JuiceFS 差别不大。在没有 page cache 只有内存缓存的第二种场景中 JuiceFS 平均提升 20% 左右的性能,特别是在 1 机 8 卡的配置下,差距进一步加大,达到了 43% 左右的性能差异。Alluxio 在 1 机 8 卡配置下的性能相比 1 机 4 卡没有提升,没法充分利用多卡的计算能力。
GPU 资源是一种比较昂贵的资源,因此 I/O 效率的差异也能间接体现到计算资源的成本上,越是能高效利用计算资源才越能整体降低 TCO。
总结及展望
本文介绍了在 AI 模型训练中如何充分利用 JuiceFS 的特性来为训练提速,相比直接从对象存储读取数据集,通过 JuiceFS 可以带来最多 7 倍的性能提升。在多卡训练的场景上也能保持一定的线性加速比,为分布式训练奠定了基础。
未来 JuiceFS 还会在 AI 场景探索更多方向,例如进一步提升 I/O 效率、海量小文件存储、数据与计算的亲和性、与 Job Operator 的结合、与 Kubernetes 调度框架或社区调度器的结合等等。欢迎大家积极参与到 JuiceFS 开源社区中来,共同建设云原生 AI 场景的存储基石。
