














在 Kubernetes 的架构体系中,计算与存储是分离的,这给数据密集型的深度学习作业带来较高的网络 IO 开销。为了解决该问题,我们基于 JuiceFS 在开源项目 Paddle Operator 中实现了样本缓存组件,大幅提升了云上飞桨分布式训练作业的执行效率。
- JuiceFS:https://github.com/juicedata/juicefs
- PaddlePaddle:https://www.paddlepaddle.org.cn/
- Paddle Operator:https://github.com/PaddleFlow/paddle-operator
背景介绍
由于云计算平台具有高可扩展性、高可靠性、廉价性等特点,越来越多的机器学习任务运行在 Kubernetes 集群上。因此我们开源了 Paddle Operator 项目,通过提供 PaddleJob 自定义资源,让云上用户可以很方便地在 Kubernetes 集群使用飞桨(PaddlePaddle)深度学习框架运行模型训练作业。
然而,在深度学习整个 pipeline 中,样本数据的准备工作也是非常重要的一环。目前云上深度学习模型训练的常规方案主要采用手动或脚本的方式准备数据,这种方案比较繁琐且会带来诸多问题。比如将 HDFS 里的数据复制到计算集群本地,然而数据会不断更新,需要定期的同步数据,这个过程的管理成本较高;或者将数据导入到远程对象存储,通过制作 PV 和 PVC 来访问样本数据,从而模型训练作业就需要访问远程存储来获取样本数据,这就带来较高的网络 IO 开销。
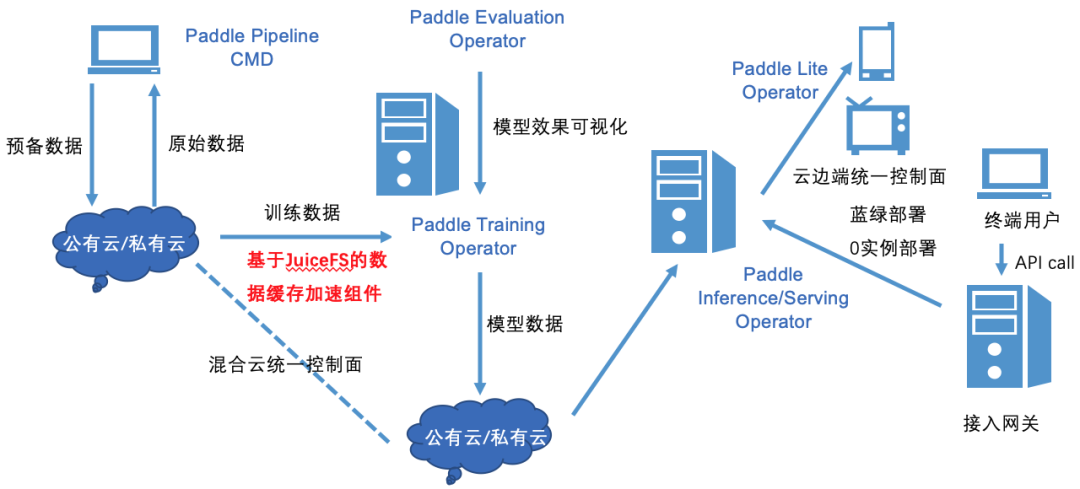
为了方便云上用户管理样本数据,加速云上飞桨框架分布式训练作业,我们与 JuiceFS 社区合作,联合推出了面向飞桨框架的样本缓存与管理方案,该方案期望达到如下目标:
- 数据集及其管理操作的自定义资源抽象。将样本数据集及其管理操作抽象成 Kubernetes 的自定义资源,屏蔽数据操作的底层细节,减轻用户心智负担。用户可以很方便地通过操作自定义资源对象来管理数据,包括数据同步、数据预热、清理缓存、淘汰历史数据等,同时也支持定时任务。
- 基于JuiceFS加速远程数据访问。JuiceFS 是一款面向云环境设计的高性能共享文件系统,其在数据组织管理和访问性能上进行了大量针对性的优化。基于 JuiceFS 实现样本数据缓存引擎,能够提供高效的文件访问性能。
- 充分利用本地存储,缓存加速模型训练。要能够充分利用计算集群本地存储,比如内存和磁盘,来缓存热点样本数据集,并配合缓存亲和性调度,在用户无感知的情况下,智能地将作业调度到有缓存的节点上。这样就不用反复访问远程存储,从而加速模型训练速度,一定程度上也能提升GPU资源的利用率。
- 统一数据接口,支持多种存储后端。样本缓存组件要能够支持多种存储后端,并且能提供统一的 POSIX 协议接口,用户无需在模型开发和训练阶段使用不同的数据访问接口,降低模型开发成本。同时样本缓存组件也要能够支持从多个不同的存储源导入数据,适配用户现有的数据存储状态。
面临的挑战
然而,在 Kubernetes 的架构体系中,计算与存储是分离的,这种架构给上诉目标的实现带来了些挑战,主要体现在如下几点:
- Kubernetes 调度器是缓存无感知的,也就是说kube-scheduler并没有针对本地缓存数据的调度策略,因此模型训练作业未必能调度到有缓存的节点,从而导致缓存无法重用。如何实现缓存亲和性调度,协同编排训练作业与缓存数据,是我们面临的首要问题。
- 在数据并行的分布式训练任务中,单机往往存放不下所有的样本数据,因此样本数据是要能够以分区的形式分散缓存在各计算节点上。然而,我们知道负责管理自定义资源的控制器(Controller Manager)不一定运行在缓存节点上,如何通过自定义控制器来管理分布式的缓存数据,也是实现该方案时要考虑的难点问题。
- 除了前述两点,如何结合飞桨框架合理地对样本数据进行分发和预热,提高本地缓存命中率,减少作业访问远程数据的次数,从而提高作业执行效率,这还需要进一步的探索。
针对上述问题,我们在开源项目 Paddle Operator 中提供了样本缓存组件,较好地解决了这些挑战,下文将详细阐述我们的解决方案。
整体设计方案
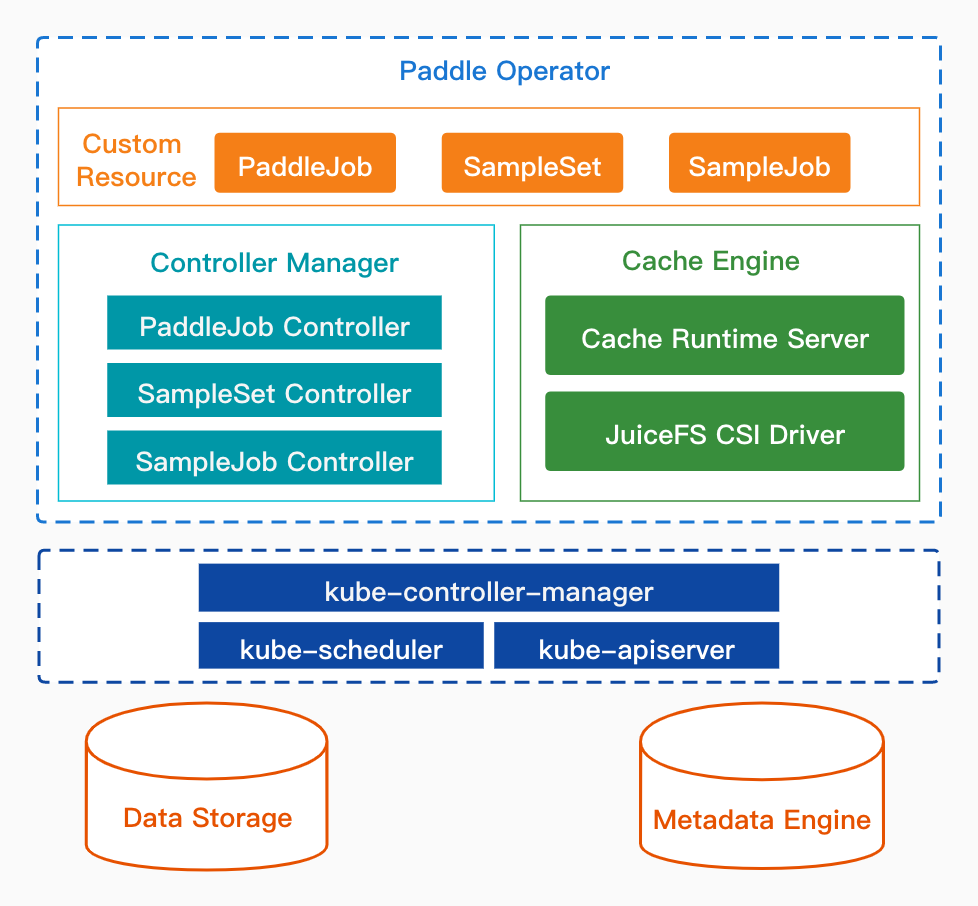
上图是Paddle Operator的整体架构,其构建在Kubernetes上,包含如下三个主要部分:
1.自定义API资源(Custom Resource)
Paddle Operator 定义了三个 CRD,用户可编写和修改对应的YAML文件来管理训练作业和样本数据集。
- PaddleJob 是飞桨分布式训练作业的抽象,它将 Parameter Server(参数服务器)和 Collective(集合通信)两种分布式深度学习架构模式统一到一个 CRD 中,用户通过创建 PaddleJob 可以很方便地在 Kubernetes 集群运行分布式训练作业。
- SampleSet 是样本数据集的抽象,数据可以来自远程对象存储、HDFS 或 Ceph 等分布式文件系统,并且可以指定缓存数据的分区数、使用的缓存引擎、 多级缓存目录等配置。
- SampleJob 定义了些样本数据集的管理作业,包括数据同步、数据预热、清除缓存、淘汰历史旧数据等操作,支持用户设置各个数据操作命令的参数, 同时还支持以定时任务的方式运行数据管理作业。
2.自定义控制器(Controller Manager)
控制器在 Kubernetes 的 Operator 框架中是用来监听 API 对象的变化(比如创建、修改、删除等),然后以此来决定实际要执行的具体工作。
- PaddleJob Controller 负责管理 PaddleJob 的生命周期,比如创建参数服务器和训练节点的 Pod,并维护工作节点的副本数等。
- SampleSet Controller 负责管理 SampleSet 的生命周期,其中包括创建 PV/PVC 等资源对象、创建缓存运行时服务、给缓存节点打标签等工作。
- SampleJob Controller 负责管理 SampleJob 的生命周期,通过请求缓存运行时服务的接口,触发缓存引擎异步执行数据管理操作,并获取执行结果。
3.缓存引擎(Cache Engine)
缓存引擎由缓存运行时服务(Cache Runtime Server)和 JuiceFS 存储插件(JuiceFS CSI Driver)两部分组成,提供了样本数据存储、缓存、管理的功能。
- Cache Runtime Server 负责样本数据的管理工作,接收来自 SampleSet Controller 和 SampleJob Controller 的数据操作请求,并调用 JuiceFS 客户端完成相关操作执行。
- JuiceFS CSI Driver 是 JuiceFS 社区提供的 CSI 插件,负责样本数据的存储与缓存工作,将样本数据缓存到集群本地并将数据挂载进 PaddleJob 的训练节点。
JuiceFS存储插件:https://github.com/juicedata/juicefs-csi-driver
难点突破与优化
在上述的整体架构中,Cache Runtime Server 是非常重要的一个组件,它由 Kubernetes 原生的 API 资源 StatefulSet 实现,在每个缓存节点上都会运行该服务,其承担了缓存数据分区管理等工作,也是解决难点问题的突破口。下图是用户创建 SampleSet 后,Paddle Operator 对 PaddleJob 完成缓存亲和性调度的大概流程。
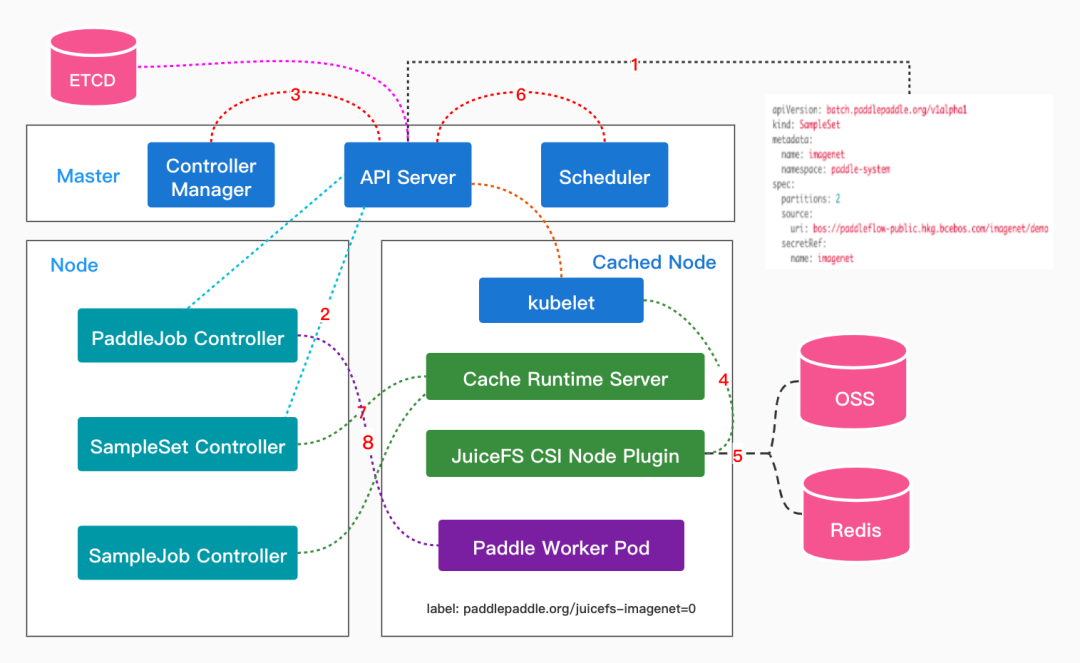
当用户创建 SampleSet 后,SampleSet Controller 就会根据 SampleSet 中的配置创建出 PV 和 PVC。在 PV 和 PVC 完成绑定后,SampleSet Controller 则会将 PVC 添加到 Runtime Pod 模板中,并创建出指定分区数的 Cache Runtime Server。在 Cache Runtime Server 成功调度到相应节点后,SampleSet Controller 则会对该节点做标记,且标记中还带有缓存的分区数。这样等下次用户提交PaddleJob 时,Paddle Controller 会自动地给 Paddle Worker Pod 添加 nodeAffinity 和 PVC 字段,这样调度器(Scheduler)就能将 Paddle Worker 调度到指定的缓存分区节点上,这即实现了对模型训练作业的缓存亲和性调度。
值得一提的是,在该调度方案中,Paddle 框架的训练节点能够做到与缓存分区一一对应的,这能够最大程度上地利用本地缓存的优势。当然,该方案同时也支持对 PaddleJob 的扩缩容,当 PaddleJob 的副本数大于 SampleSet 的分区数时(这也是可以调整的),PaddleJob Controller 并不会对多出来 Paddle Worker 做 nodeAffinity 限制,这些 Paddle Worker 还可以通过挂载的 Volume 访问远程存储来获取样本数据。
解决了缓存亲和性调度的问题,我们还面临着 SampleSet/SampleJob Controller 如何管理分布式样本缓存数据集,如何合理地做分布式预热的挑战。使用 JuiceFS CSI 存储插件可以解决样本数据存储与缓存的问题,但由于 Kubernetes CSI 插件提供的接口有限(只提供了与 Volume 挂载相关的接口),所以需要有额外的数据管理服务驻守在缓存节点,即:Cache Runtime Server。
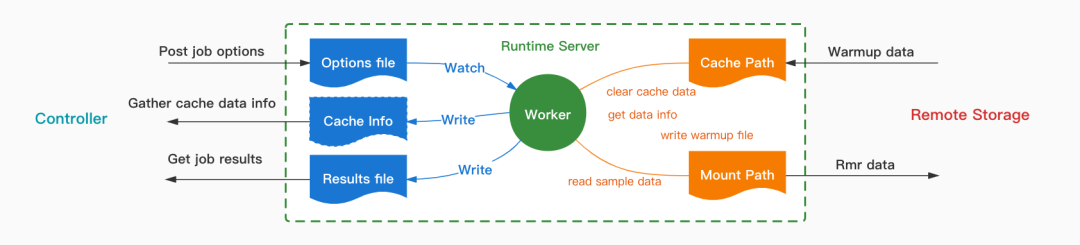
上图是 Cache Runtime Server 内部工作流程示意图,其中封装了 JuiceFS 客户端的可执行文件。Runtime Server 提供了三种类型的接口,它们的作用分别是:
- 上传数据操作命令的参数
- 获取数据操作命令的结果
- 获取样本数据集及其缓存的状态。
Server 在接收到 Controller 上传的命令参数后,会将参数写到指定路径,然后会触发 Worker 进程异步地执行相关操作命令,并将命令执行结果写到结果路径,然后 Controller 可以通过调用相关接口获取数据管理作业的执行结果。
数据同步、清理缓存、淘汰旧数据这三个操作比较容易实现,而数据预热操作的实现相对会复杂些。因为,当样本数据量比较大时,单机储存无法缓存所有数据,这时就要考虑对数据进行分区预热和缓存。为了最大化利用本地缓存和存储资源,我们期望对数据预热的策略要与飞桨框架读取样本数据的接口保持一致。
因此,对于 WarmupJob 我们目前实现了两种预热策略:Sequence 和 Random,分别对应飞桨框架 SequenceSampler 和 DistributedBatchSampler 两个数据采样 API。JuiceFS 的 Warmup 命令支持通过 --file 参数指定需要预热的文件路径,故将 0 号 Runtime Server 作为 Master,负责给各个分区节点分发待预热的数据,即可实现根据用户指定的策略对样本数据进行分布式预热的功能。
至此,难点问题基本都得以解决,该方案将缓存引擎与飞桨框架紧密结合,充分利用了本地缓存来加速云上飞桨的分布式训练作业。
使用示例
下面我们通过训练 ResNet50 模型的例子来简要说明下如何使用 Paddle Operator,您只需要准备两个 YAML 配置文件,即可轻松地在 Kubernetes 集群上完成复杂的分布式深度学习任务。第一步是编写 SampleSet 的 YAML 文件,并指定远程数据源,如下:
apiVersion: batch.paddlepaddle.org/v1alpha1
kind: SampleSet
metadata:
name: imagenet
namespace: paddle-system
spec:
# 分区数,一个Kubernetes节点表示一个分区
partitions: 2
source:
uri: bos://paddleflow-public.hkg.bcebos.com/imagenet
secretRef:
name: imagenet通过 kubectl apply -f 命令可以创建该样本数据集,您还可以查看样本数据集及其缓存的状态:
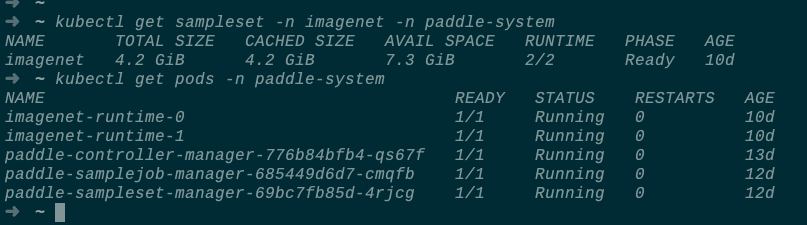
等 SampleSet 的状态为 Ready 后,您就可以通过编写如下的 PaddleJob 来完成 ResNet50 模型的训练了:
apiVersion: batch.paddlepaddle.org/v1
kind: PaddleJob
metadata:
name: resnet
spec:
# 指定要使用的 SampleSet
sampleSetRef:
name: imagenet
mountPath: /data
worker:
replicas: 2
template:
spec:
containers:
- name: resnet
image: registry.baidubce.com/paddle-operator/demo-resnet:v1
command:
- python
args:
- "-m"
- "paddle.distributed.launch"
- "./tools/train.py"
- "-c"
- "./config/ResNet50.yaml"
resources:
limits:
nvidia.com/gpu: 2更多的使用文档可以参考Paddle Operator。
性能测试
为了验证 Paddle Operator 样本缓存加速方案的实际效果,我们选取了常规的 ResNet50 模型以及 ImageNet 数据集来进行性能测试,并使用了 PaddleClas 项目中提供的模型实现代码。具体的实验配置如下:
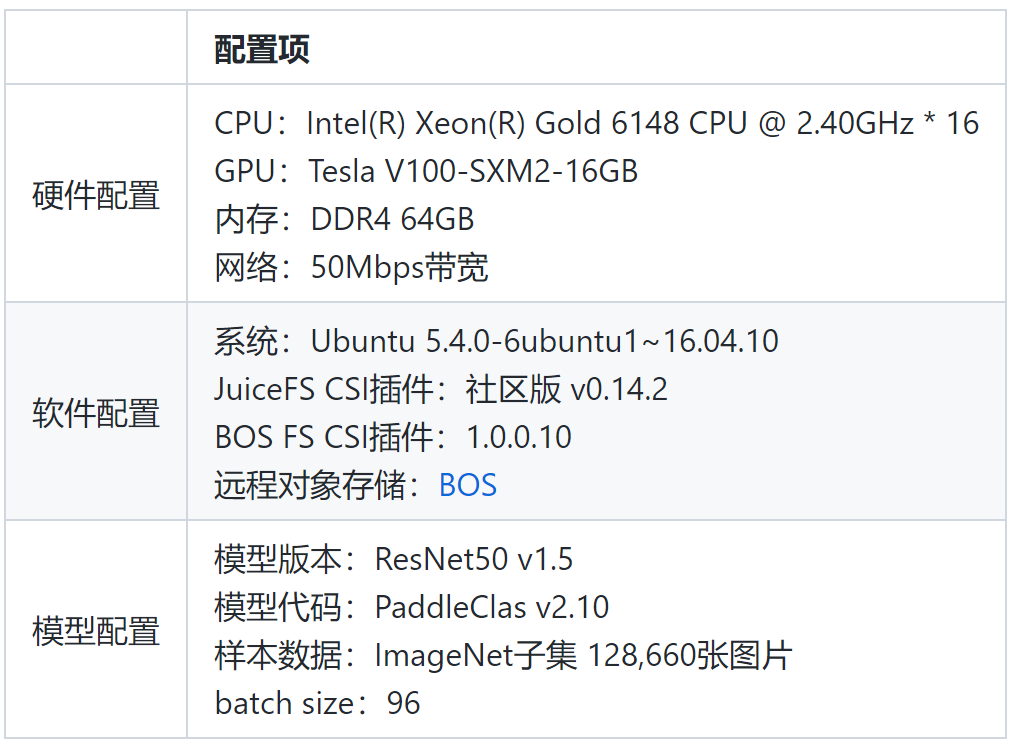
基于以上配置,我们做了两组实验。
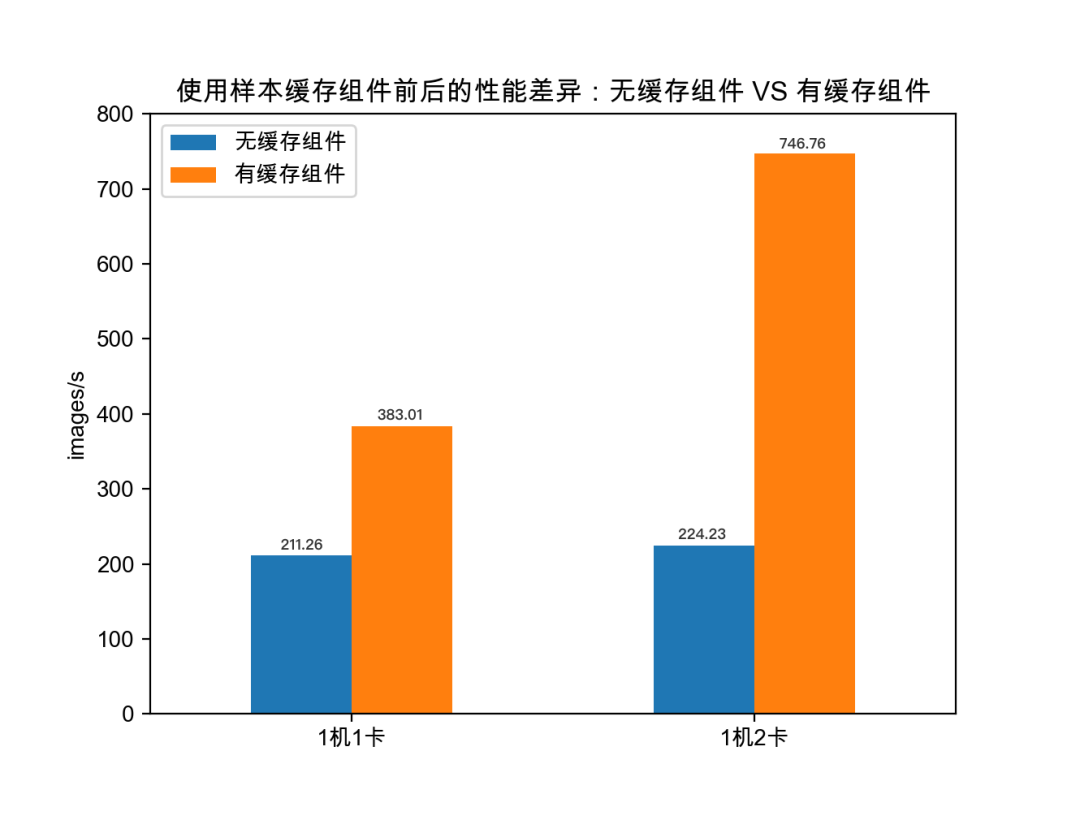
第一组实验对比了样本数据缓存前后的性能差异,从而验证了使用样本缓存组件来加速云上飞桨训练作业的必要性。
如上图,在样本数据缓存到训练节点前,1机1卡和1机2卡的训练速度分别为 211.26 和224.23 images/s;在样本数据得以缓存到本地后,1 机 1 卡和 1 机 2 卡的训练速度分别为383.01和746.76 images/s。可以看出,在计算与存储分离的 Kubernetes 集群里,由于带宽有限(本实验的带宽为 50Mbps),训练作业的主要性能瓶颈在于远程样本数据 IO 上。带宽的瓶颈并不能通过调大训练作业的并行度来解决,并行度越高,算力浪费越为严重。
因此,使用样本缓存组件提前将数据预热到训练集群本地,可以大幅加速云上飞桨训练作业的执行效率。在本组实验中,1 机 1 卡训练效率提升了 81.3%,1 机 2 卡的训练速度提升了 233%。
此外,使用样本缓存组件预热数据后,1 机 1 卡 383.01 images/s的训练速度与直接在宿主机上的测试结果一致,也就是说,缓存引擎本身基本上没有带来性能损耗。
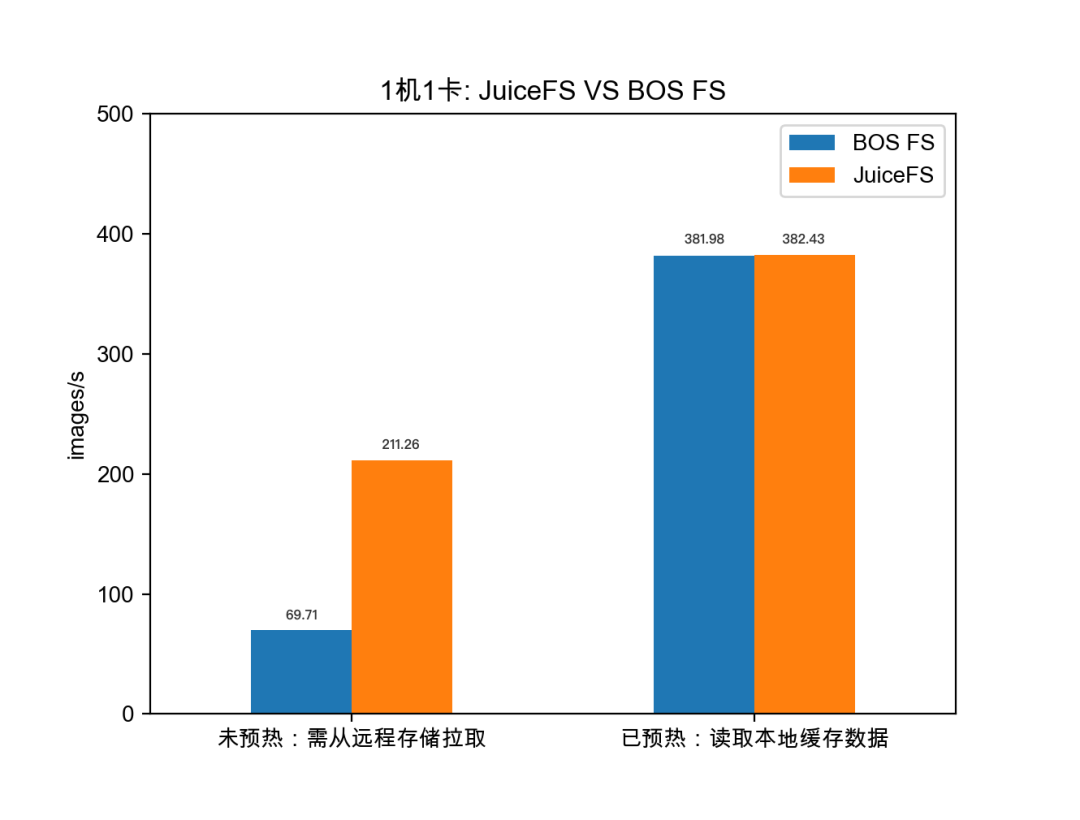
第二组实验对比了使用1机1卡时样本数据预热前后 JuiceFS 与 BOS FS 的性能差异,相比于 BOS FS,JuiceFS 在访问远程小文件的场景下具有更优的性能表现。
如上图,在样本数据预热到本地前,需要通过 CSI 插件访问远程对象存储(如BOS)中的样本数据,使用 BOS FS CSI 插件与 JuiceFS CSI 插件的训练速度分别是 69.71和211.26 images/s;在样本数据得以缓存在本地后,使用 BOS FS CSI 插件与JuiceFS CSI 插件的训练速度分别是 381.98 和 382.43 images/s,性能基本没有差异。
由此可以看出,在访问远程小文件的场景下,JuiceFS 相比 BOS FS 有近 3 倍的性能提升。两者的性能差异可能与 JuiceFS 的文件存储格式和 BOS FS 的实现有关,这有待进一步验证。除了性能上的考量,JuiceFS 提供的文件系统挂载服务更加稳定,功能完善且易用,这也是优先选择 JuiceFS 作为底层缓存引擎的重要原因。
总结及展望
样本数据的准备工作是深度学习 pipeline 中的重要一环,本文总结了在云上管理样本数据并加速其访问效率所面临的挑战,在文章的第 3 和第 4 节我们给出了这些问题的详细解决方案。进一步地,我们对 Paddle Operator 的样本缓存方案进行了性能测试,实验结果表明该方案能大幅加速云上飞桨的模型训练作业。现该方案已在 Paddle Operator 项目中开源,欢迎大家来体验并使用。
在后续的工作中,我们将继续完善样本数据管理功能,提供更多的数据管理策略,并进一步加强 Operator 与飞桨框架的协同优化工作。除了离线训练的场景,我们也在探索 Operator 支持在线学习场景的解决方案,如您对这些工作也很感兴趣,欢迎参与进来一起讨论、开发。
