














百图生科(BioMap)由百度创始人李彦宏先生联合创立,专注于生命科学领域的人工智能技术。公司推出了全球最大的生命科学 AI 基础模型 xTrimo V3,拥有 2100 亿参数,覆盖蛋白质、DNA、RNA 等多个生命科学领域。
随着生命科学领域数据量的爆发式增长,存储成本日益增加。为了降本增效,百图生科对 Lustre、Alluxio、JuiceFS 等多个存储方案进行评估。综合考虑成本、性能和运维等因素后,最终选择了JuiceFS。
目前,JuiceFS 已成功应用于 finetune 和 inference 场景,存储了数十亿的小文件,读写性能可满足需求。且与原有架构相比,整体存储成本降低了 90%。
01 生命科学领域的存储模式与痛点
大模型时代为生命科学注入了新动力。以药物发现为例,传统研发依赖大量实验筛选,投入高、周期长。而如今,借助大模型加速筛选候选分子,大幅提升了效率与成功率。比如,百图生科推出的 xTrimo 系列模型,参数规模高达 2100 亿,覆盖蛋白质、DNA、RNA 和细胞等领域。
然而,大模型的发展离不开算力、算法和数据三大支柱,其中存储作为底层基础,对性能发挥至关重要。随着生命科学领域数据量的爆发式增长,海量数据的存储与管理成为新的挑战。
- 备份可靠性问题:当数据量达到 TB 甚至 PB 级别(包含约 10 亿个小文件)时,备份过程经常失败。即使备份成功,也需要长达一个月的时间,且一旦发生文件丢失,几乎无法恢复使用。
- 存储成本高:现有系统缺乏智能的冷热数据分离机制,导致所有数据(包括极少访问的冷数据)都存储在昂贵的文件系统中,而非成本更低的对象存储,造成资源浪费。采用传统云存储方案时,企业每年需要承担高达千万级别的存储费用,这给处于快速发展阶段的公司带来了财务负担。
02 存储选型:Lustre vs Alluxio vs JuiceFS
首要目标是实现降本增效,在满足业务对吞吐和延时要求的前提下,有效降低存储成本。其次,需兼顾数据安全与读写性能,确保业务数据的完整性和可用性。此外,考虑到公司运维团队规模较小,存储系统的部署与维护应尽可能简单易行,避免复杂的系统优化工作给运维团队带来过大压力。
基于上述需求,对 Lustre、Alluxio 和 JuiceFS 三款存储系统进行了分析:
Lustre 采用计算资源本地盘(如 SSD)搭建集群,通过多个节点组合实现大容量存储。然而,这种架构后端并非对象存储,无法充分利用对象存储在成本和扩展性方面的优势,因此不符合需求。
Alluxio 主要作为缓存层存在,可将不同文件系统的数据进行集中缓存,实现统一访问。但Alluxio 并不能从根本上解决存储成本高、冷热数据管理困难等问题,因此也未将其作为首选方案。
| Lustre | JuiceFS | Alluxio | |
|---|---|---|---|
| 类型 | 并行分布式文件系统 | 云原生分布式文件系统 | 内存加速虚拟文件系统 |
| 设计目标 | 高性能计算 (HPC) | 云上通用存储 + 兼容性 | 数据本地加速 + 跨云抽象 |
| 核心优势 | 超低延迟、高带宽 | POSIX 兼容 + 弹性扩展 | 缓存加速 + 多后端统一视图 |
| 架构 | 元数据(MDS) + 数据(OSS)分离 | 元数据(独立服务) + 数据(对象存储) | 内存/SSD分层缓存 + 后端存储代理 |
| 数据持久化 | 自身存储集群 | 依赖对象存储(如S3、OSS) | 依赖后端存储 (HDFS、S3 等) |
| 一致性模型 | 强一致性 | 强一致性 | 可配置(强一致或最终一致) |
最终,我们选择了 JuiceFS。其社区活跃度高,能够及时获得技术支持和功能更新,为系统的长期稳定运行提供保障。同时,JuiceFS 原生支持对象存储,充分利用了对象存储的低成本和高扩展性,显著降低了整体存储成本。此外,JuiceFS 部署简单、维护便捷,进一步减轻了运维负担。
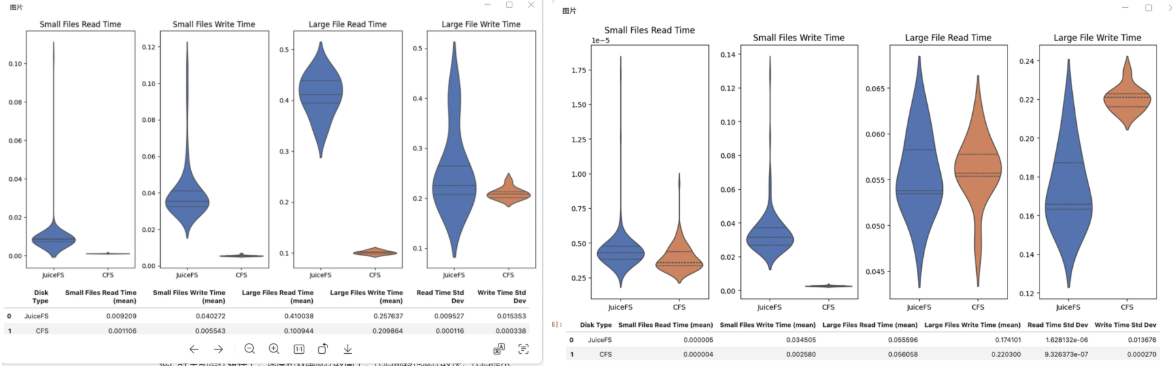
为确保实际应用中的表现,我们进行了测试。功能上,JuiceFS 不仅支持 CSI 与公司使用的 Kubernetes平台无缝集成;而且稳定性良好,易于维护和部署。性能如下图所示,小文件(1K)访问性能:百度 CFS 明显更优;中大文件(10MB+)顺序读写性能:JuiceFS 略胜,尤其在高并发下更具扩展性。测试中使用的元数据引擎为 MySQL,文件规模约为千万级。在下文中,我们将介绍在针对小文件访问性能优化后,JuiceFS 的整体表现已基本达到与百度 CFS 持平的水平。
| 一次读取文件大小 | 并发 | 顺序读速度 - JuiceFS-BOS | 顺序读速度 - CFS | 顺序读 IOPS - JuiceFS-BOS | 顺序读 IOPS - CFS | IO总量 | 顺序写速度 - JuiceFS-BOS | 顺序写速度 - CFS | 顺序写 IOPS - JuiceFS-BOS |
|---|---|---|---|---|---|---|---|---|---|
| 1K | 1 | 68.8MB/s | 1664kB/s | 67.2k | 1626 | 1GB | 53.9MB/s | - | 55.2k |
| 8 | 183MB/s | - | 178k | - | 8GB | 123MB/s | - | 130k | |
| 16 | 175MB/s | 18.2MB/s | 197k | 18k | 16GB | 132MB/s | 15MB/s | 134k | |
| 32 | 136MB/s | - | 160k | - | 32GB | 132MB/s | - | 130k | |
| 64 | 96.5MB/s | - | 110k | - | 23GB | - | - | - | |
| 10M | 1 | 267MB/s | - | 30 | - | 1GB | 991MB/s | - | 94 |
| 8 | 1567MB/s | - | 160 | - | 8GB | 1209MB/s | - | - | |
| 16 | 1749MB/s | 1188MB/s | 160 | 112 | 17GB | 1219MB/s | 1719MB/s | - | |
| 32 | 1769MB/s | - | 162 | - | 34.2GB | 1213MB/s | - | - | |
| 64 | 604MB/s | - | - | - | 68.5GB | - | - | - | |
| 100M | 1 | 284MB/s | - | 2 | - | 1GB | 1191MB/s | - | 1 |
| 8 | 1578MB/s | - | 4 | - | 8GB | 1299MB/s | - | - | |
| 16 | 1655MB/s | 1156MB/s | 17 | - | 17GB | 1299MB/s | 1603MB/s | - | |
| 32 | 1742MB/s | - | 32 | - | 34GB | - | - | - | |
| 64 | 597MB/s | - | - | - | 67GB | 1034MB/s | - | - | |
| 500M | 1 | 311MB/s | - | - | - | 20GB | 1243MB/s | - | - |
| 8 | 1765MB/s | - | - | - | 168GB | 1286MB/s | - | - | |
| 16 | 1956MB/s | 1175MB/s | - | - | 336GB | 1238MB/s | 1738MB/s | - | |
| 32 | 1722MB/s | - | - | - | 671GB | - | - | - | |
| 64 | 534MB/s | - | - | - | 1342GB | - | - | - | |
| 128 | 371MB/s | - | - | - | 899GB | - | - | - |
基于此,决定将数据从 BOS 对象存储向 JuiceFS 进行迁移。尽管这一迁移工作涉及海量数据,任务艰巨,但考虑到 JuiceFS 在降本增效、性能、稳定性等方面的综合优势,我们认为这一投入是值得的。
03 基于 JuiceFS 的存储新架构,成本下降90%
在基于 Kubernetes 构建的平台最初使用基于 SSD 盘组的 NFS 文件系统作为底层存储,整体使用成本相当于对象存储的近 10 倍。引入 JuiceFS 后,数据可直接持久化到如 S3、OSS 等公有云对象存储中,JuiceFS 集群本身开销极小,几乎可忽略。通过这一架构转型,平台成功用对象存储替代原有 SSD 方案,实现了超 90% 的存储成本下降。
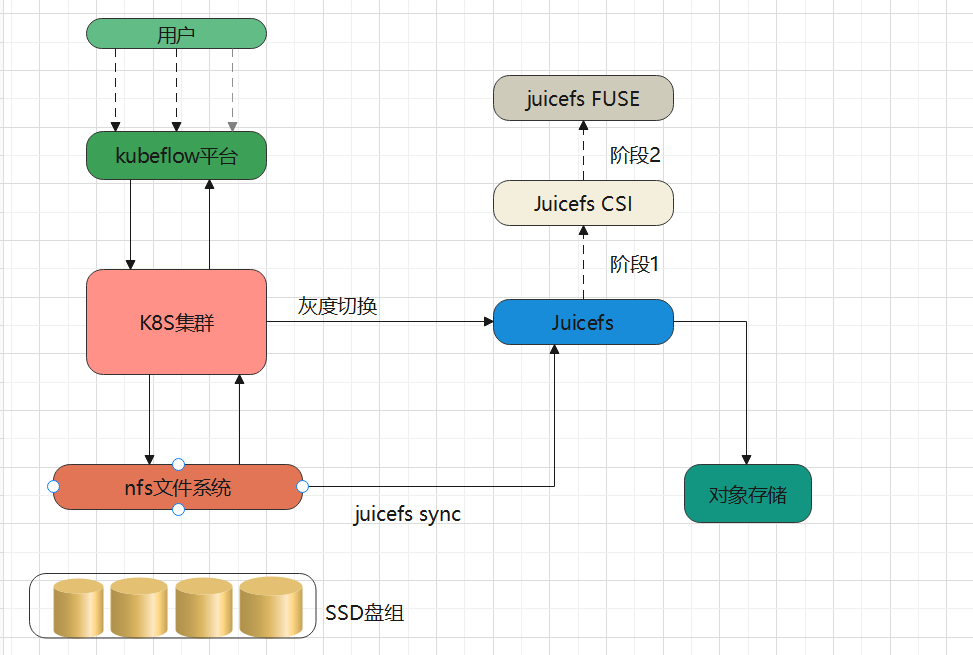
JuiceFS 采用数据与元数据分离存储的架构。文件数据本身会被切分保存在对象存储,而元数据则可以保存在 Redis、MySQL、TiKV、SQLite 等多种数据库中,用户可以根据场景与性能要求进行选择。
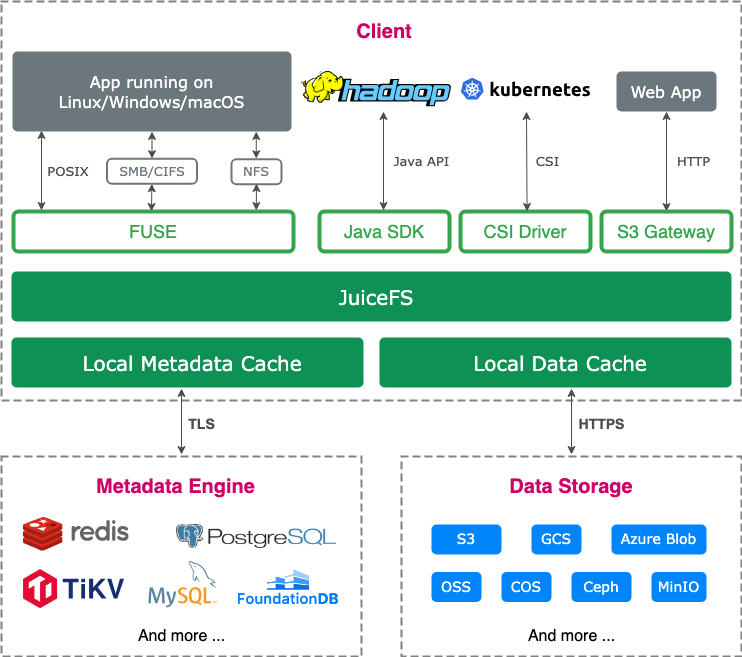
在选择元数据引擎时,最初我们使用了 MySQL,但当文件数量超过 1 亿时,MySQL 的性能会显著下降。最终选择了 TiKV 作为元数据引擎。然而,TiKV 目前只有社区版,没有商业版支持,团队在遇到问题时主要依靠与社区交流和查阅文档来排查问题,这对系统的维护和优化带来了一定的挑战。我们目前平台使用的存储量级达到 PB 级别,文件数量达几十亿个。
上文提到,早期我们曾遇到备份可靠性不足的问题,目前我们通过 JuiceFS 提供的元数据备份机制实现了稳定的元数据备份。同时,为防止误删除数据,还结合 JuiceFS 的回收站功能,进一步提升了数据安全性与可恢复性。
04 JuiceFS 使用实践
数据迁移工具
在迁移过程中,团队最初尝试自行使用 Python 编写多进程多线程代码来提高数据同步速度,但遇到了诸多问题。后来,团队发现了 JuiceFS 提供的 juicefs sync 命令,该命令有效解决了数据同步问题,提高了迁移效率。
存储接入方式优化
团队最初考虑使用 JuiceFS CSI 将数据接入 k8s 平台。CSI 方式具有与云环境兼容性好、便于维护、支持监控 Dashboard 等优点,通过简单的 yaml 部署即可实现存储的快速接入和管理。
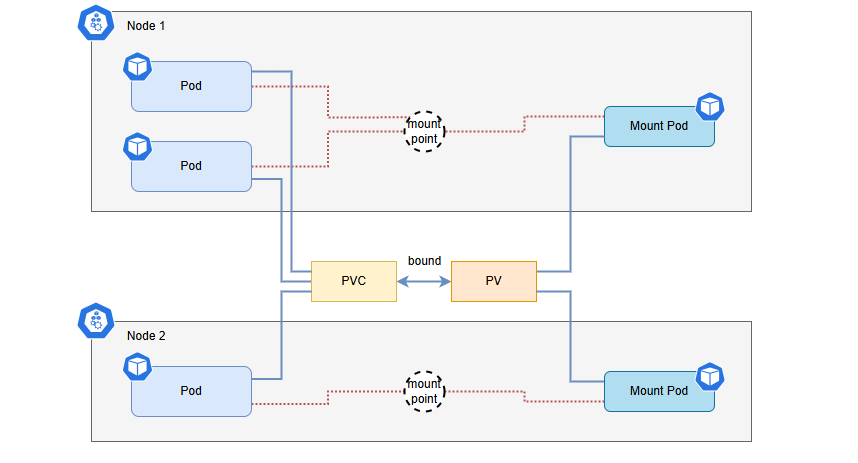
然而,在实际应用中,我们遇到了一些问题:
- 共享 mountpod 配置问题:由于平台中每台节点上的 pod 数量有限,团队希望所有用户共享一个 mountpod。虽然通过参数 volumehandle 可以实现同一节点上不同用户生成的 PVC 携带相同的 volumehandle,但这种配置方式增加了系统的复杂性和管理难度。
- mountpod 预铺与更新问题:使用 CSI 默认方式时,在资源不足的情况下,mountpod 无法正常启动,进而导致业务 pod 出现问题。因此,团队需要提前预铺 mountpod,并设置参数 juicefs-delete-delay: 525600h,以保证业务 pod 结束后 mountpod 不被释放。但在更新 mountpod 资源时,需要各业务配合清理业务 pod、删除旧 mountpod 并启动新 mountpod,操作流程繁琐,且容易出错。
- 稳定性问题:由于本地缓存过大,并且伴随着 PageCache 占用过高,mountpod 经常出现内存溢出(OOM)问题。这导致业务 pod 内部的读写操作受到影响,进而影响了业务的正常运行。
鉴于 CSI 方式存在的问题,团队决定切换至传统的 HostPath 挂载方式,该方式通过将 JuiceFS 挂载到各个节点上,业务 Pod 通过 HostPath 直接使用挂载后的文件系统,相比 CSI 方式更加稳定。然而,这种方式也存在部署相对繁琐、不易于管理和升级等缺点。为了克服这些问题,团队借助自动化工具进行批量部署和管理,提高了操作效率。
编者注:
关于 JuiceFS CSI 的使用,我们推荐使用动态配置,并通过设置同一个 StorageClass 共享 Mount Pod,这样既能兼顾功能性,也便于管理。不建议采用上文中提到的配置相同 volumeHandle 的方式实现共享,该方式可能导致 CSI 的多项高级功能(如平滑升级)无法正常使用。此外,JuiceFS CSI 的平滑升级功能,能够在无需重启业务 Pod 的情况下完成 Mount Pod 升级,进一步提升系统的可用性和维护效率。
针对内核页缓存用量增大导致 Mount Pod OOM 的问题,可以开启客户端主动标记缓存状态(读写完之后立刻淘汰缓存),来降低内存用量。具体参考文档:https://juicefs.com/docs/zh/csi/guide/cache#clean-pagecache
文件复制性能优化
在 JuiceFS 使用过程中,业务反馈 pod 启动速度变慢。经过运维侧和业务侧共同排查,发现耗时主要集中在业务代码的文件复制(cp)操作上。运维团队测试发现,在相同文件数的情况下,JuiceFS 的 cp 性能比 CFS 慢 3 倍以上。由于 cp 操作是单线程的,团队通过使用 juicefs sync 命令增加并发度,有效加快了 cp 过程,并将线上业务涉及 cp 的操作全部替换为 juicefs sync。
包导入与文件读写性能优化
业务在测试过程中还发现,使用 JuiceFS 时包导入速度较慢,小文件读写速度比 CFS 慢 8 倍,大文件读速度比 CFS 慢 4 倍。团队通过增加客户端缓存的方式解决了这一问题,利用 GPU 机器上自带的 NVMe 盘作为客户端读缓存介质。优化后,小文件和大文件的读写性能与 CFS 基本持平,显著提升了业务性能。
05 小结
百图生科通过选用 JuiceFS 并构建基于对象存储的新架构,将整体存储成本降低了 90%。在数据迁移、Kubernetes 接入、性能优化与高并发场景应对等方面,团队积累了丰富经验。此次系统重构不仅显著提升了平台的稳定性、性能与弹性,也为未来规模化发展打下了坚实基础。希望本次实践经验能为更多生命科学与 AI 企业提供参考。
