














JuiceFS 社区聚集了来自各行各业的前沿科技用户。本次分享的案例来源于刻行,一家商用服务机器人领域科技企业。
商用服务机器人指的是我们日常生活中常见的清洁机器人、送餐机器人、仓库机器人等。刻行采用 JuiceFS 来弥补对象存储性能不足等问题。
值得一提的是,前不久社区版 v1.1 中发布的“克隆”功能,已经成功被应用于刻行数据版本管理之中,有效提升仿真训练的效率。
在商用服务机器人领域,后期运维和开发工作至关重要。这包括监控机器人性能、执行定期维护、处理故障、进行软件更新及数据管理等。这些环节产生将产生大量数据,数据处理效率对于降低企业成本和提高工作效率起着决定性作用。刻行专注于后期的运维环节,为机器人企业提供全方位的闭环数据服务,涵盖从数据采集、存储到数据的可视化和仿真训练等多个功能。
01 什么是机器人的数据闭环
本文所指的机器人特指商用服务型机器人,如在商场中常见的自动清洁和送餐机器人。数据闭环是指收集终端用户的软件系统运行数据,以此来优化产品的功能和用户体验。
数据闭环如下图所示,首先,机器人系统会捕捉并上传现场问题相关的数据。这些数据,包括传感器数据以及感知、规划和控制方面的信息,都将被直接采集并用于后续处理。
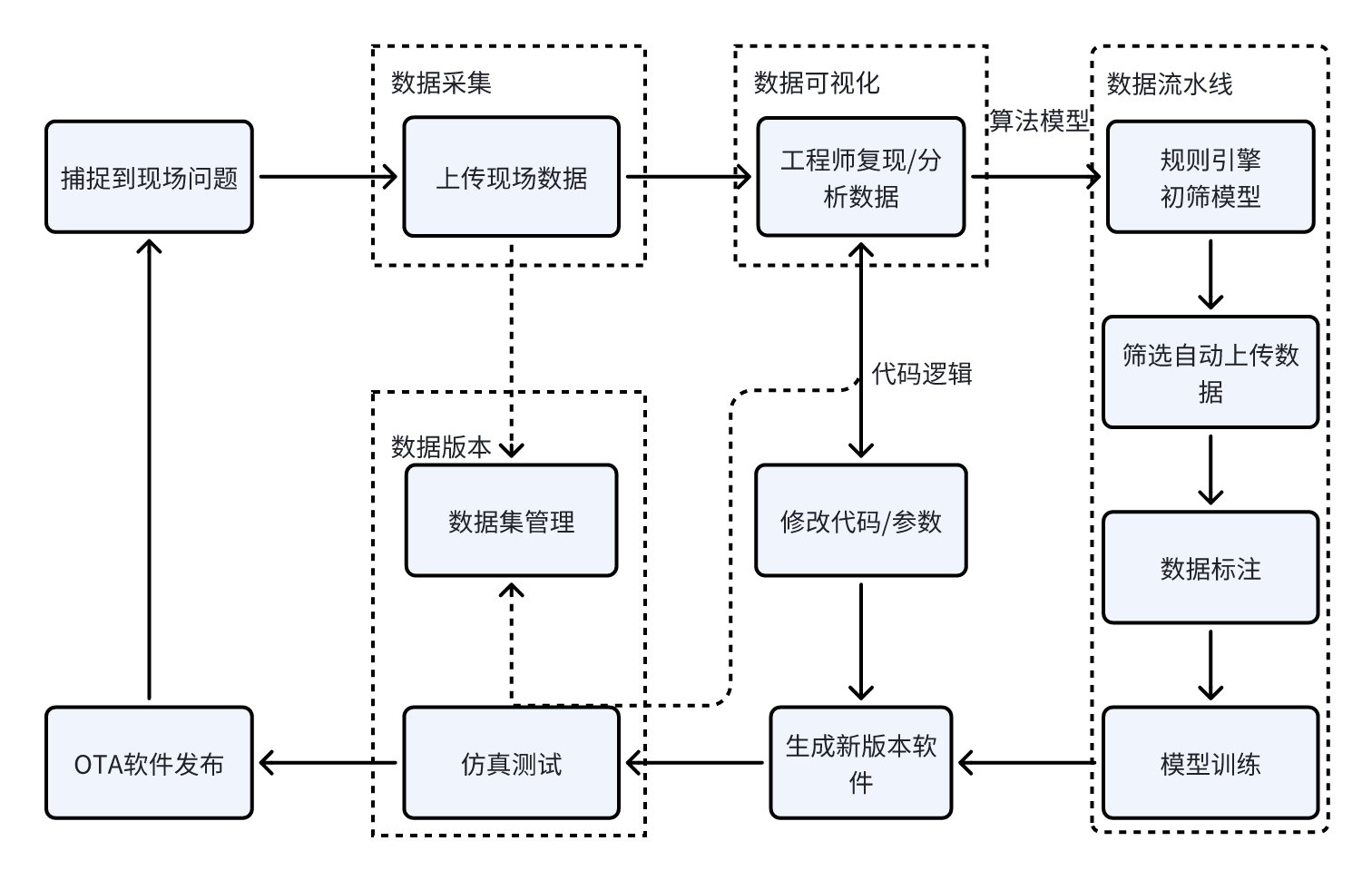
接下来,工程师将着手解决现场问题,首要任务是将前一步骤中采集的数据进行可视化处理。这需要直接访问存储在 JuiceFS 的数据。
解决问题的开发迭代阶段可能涉及机器人系统代码的逻辑优化,或者是算法模型的调整,此时需利用传感器数据进行标注和训练。无论解决方案的类型如何,最终都必须通过仿真测试进行验证,这就要求实现数据的版本化管理。
02 JuiceFS 在不同场景中的实践
数据采集
机器人采集的数据量极大,例如我们服务的一位客户,每日活跃设备数量达到数百台,每次数据采集的持续时间为一分钟,每分钟产生的数据量可达数百兆。因此,每天的数据增量大约是几百 GB。这些数据通常是非结构化的,因此将原始数据直接存储在对象存储中是极为合适的。
然而,对象存储也有局限性。首先,从设计上讲,它会根据键(key)自动进行分区。如果采用连续的前缀,很容易触及其限制的查询次数(QPS)。这一点在众所周知的 OSS 和 S3 等服务中也有所体现,具体限制可以参照它们的官方文档。
此外,若用户希望通过 FUSE 将对象存储用作文件系统,需要注意的是,类似 s3fs 这样的开源工具在性能和兼容性方面表现一般。具体的特性对比可参考 JuiceFS 的文档。
因此,我们正在寻找更优的存储方案,期望它既能提供对象存储的便利性,又能拥有更出色的性能表现。
我们最初接触的工具是开源版的 Alluxio。然而,我们最终没有选择它,主要原因是其对 S3 和FUSE 协议的兼容性不足。以 S3 协议为例,它支持在读取数据时进行范围访问,类似于文件系统的高效操作。最初,Alluxio 并不支持此功能,我本人在 2020 年接触 Alluxio 时,曾提交过一个 PR 来解决这个问题,社区直到 2021 年才将其合并,我们最终决定放弃使用 Alluxio。此外,我们也尝试过自主研发类似的系统。
后来,我们选择使用 JuiceFS。JuiceFS 在设计上有效地规避了对象存储的一些限制。例如,原始数据的查询不依赖于对象存储提供的 API,而是通过自动分散文件到对象存储中来实现。此外,JuiceFS 的社区也非常活跃,开发者们对于问题的响应非常积极,这进一步促使我们采用了这个工具。
值得强调的是数据合规性问题,许多国内的机器人公司和制造业企业在出海时都会面临数据合规性挑战。由于国外的法律和法规通常要求数据必须在本地存储,因此多云架构的使用变得不可避免。JuiceFS 在这方面表现出色,因为它不仅兼容多种对象存储产品,而且非常适合在多云环境中作为存储层使用。因此,对于那些在开发业务时面临类似问题,需要采用多元化架构的企业来说,选择 JuiceFS 可以有效减少由不同存储产品带来的复杂度和挑战。
数据可视化
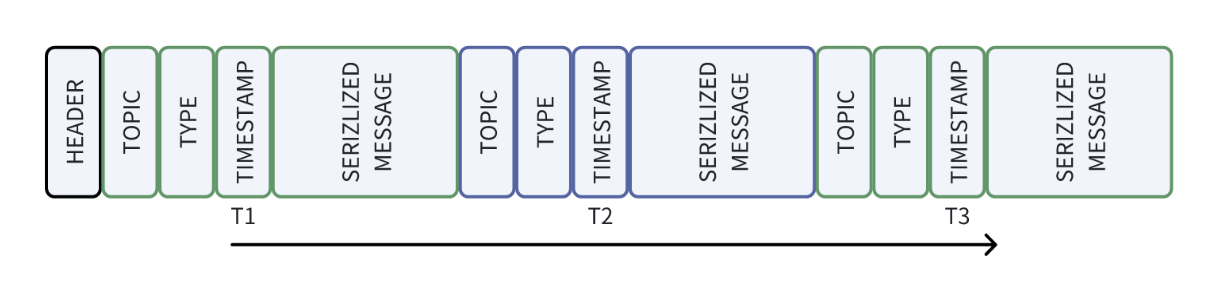
为了让大家理解 JuiceFS 在数据可视化中的重要性,先简单介绍一下机器人行业常见的原始数据存储格式。大多数系统会采用类似于 ROS 或 MCAP 这样的文件格式,这是在机器人系统实际运行过程中记录并存储数据的结构。
下图展示了这一存储结构。首先,会存储一些文件的元数据。接下来是不同类型传感器的 TOPIC,例如激光雷达和摄像头各自对应一个 TOPIC。TYPE 会定义每个 TOPIC 的数据结构,例如激光雷达数据结构通常被称为点云。TIME STAMP 记录了传感器采集数据的时间点。最后,存储的是真实采集到的数据。因此,我们的设备采集的数据实际上按时间顺序保存在系统中。
具体到数据可视化的实际应用场景,运维人员需要响应用户提出的工单。在获得用户授权后,他们会主动向设备发送数据采集请求。随后,所采集的数据需要被迅速访问并可视化处理。在此过程中,JuiceFS 提供的缓存特性起到了关键作用,数据在写入时同时建立缓存,方便在接下来的访问中直接命中缓存,这个设计极大地提高了数据使用的效率。这种高效率的数据处理对于快速解决工单、提升用户体验至关重要。
此外,JuiceFS 在处理数据方面也展现出显著优势。由于原始数据的时序特征,在数据可视化过程中,大量的时序连续数据需要被顺序读取。JuiceFS 提供了预读和预取功能(详见 JuiceFS 缓存文档),这使得计算资源得到了更有效的利用。具体来说,处理当前帧数据时,JuiceFS会自动预读后续帧的数据。这样的机制不仅提高了数据处理的效率,还节省了计算资源,从而使整个数据处理流程更为高效和流畅。
数据流水线
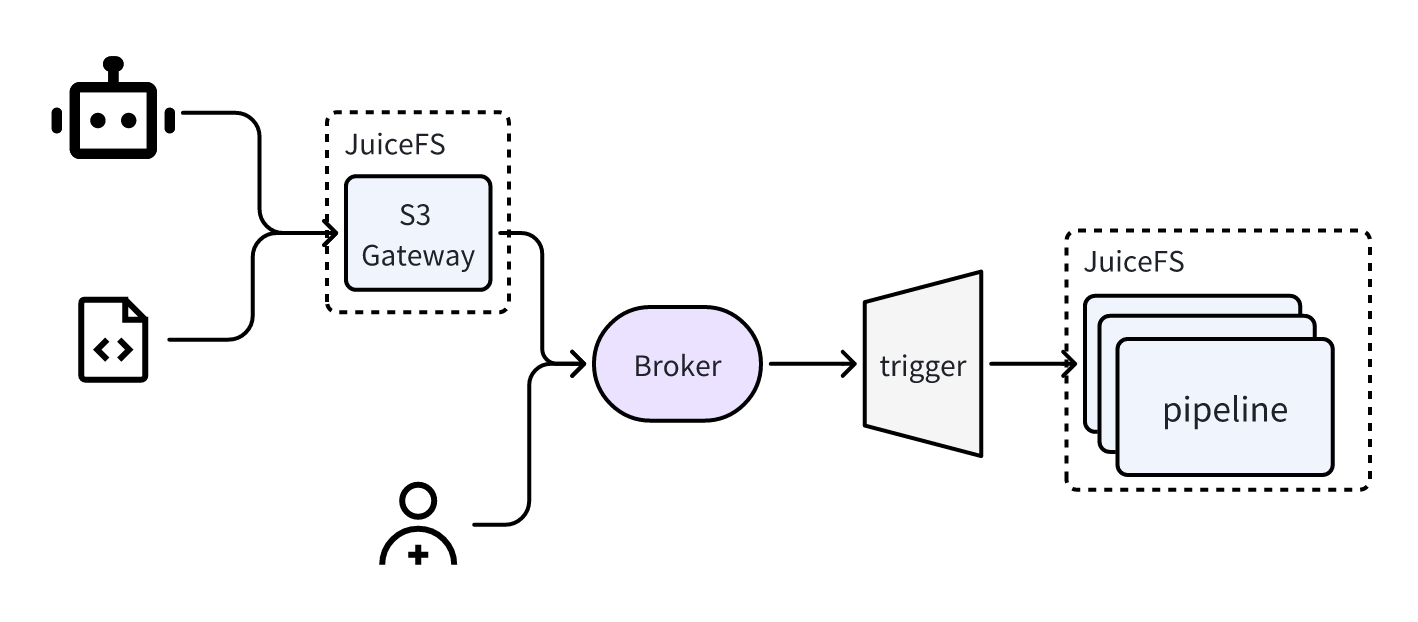
如下图所示,我们首先通过 S3 网关将原始数据和待测试的软件上传至 JuiceFS 。随后,通过设定的统一事件和规则,这些过程可自动或手动触发。在我们的系统中,除了 S3 网关产生的事件外,还整合了内部系统的其他事件。所有的流水线(pipeline)操作均在我们的Kubernetes 集群中执行。对于有兴趣深入了解如何在 Kubernets 集群中使用 JuiceFS 的用户,建议参考 JuiceFS 文档。
数据版本
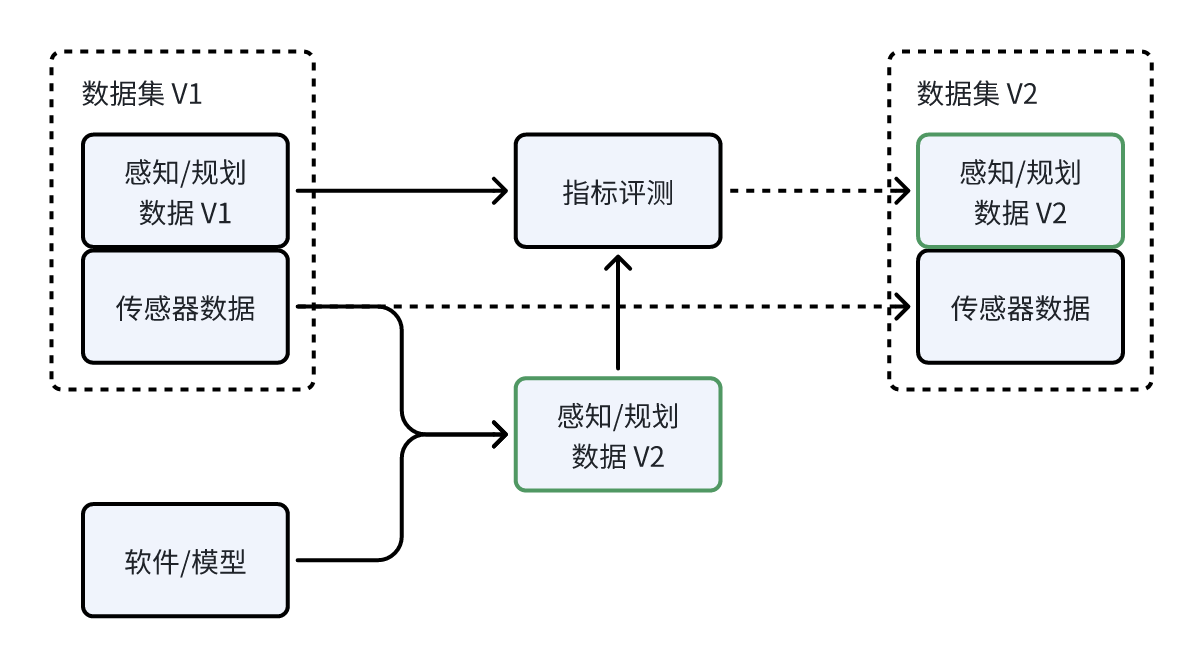
如图所示,每当我们进行软件或模型的迭代仿真测试时,均需借助之前收集的传感器数据。这些数据用于对比规划和感知的结果,并通过特定指标进行评估。此过程的目的是判断哪个结果更为优秀,进而生成新的数据集。这一过程体现了业务层面的数据处理和分析。通过这种方式,我们能够精确地评估各个迭代步骤的效果,确保最终结果的优化和提升。
在具体的执行层面,当我们运行 Python 时,系统首先会指定挂载特定版本的数据。例如,在图示中,系统挂载了最新的 HEAD 数据版本。接着,我们从执行的结果中筛选出更优的数据,以此形成一个新版本。在这个过程中,历史版本的管理依赖于 JuiceFS 提供的克隆功能来实现。如果未来工程师需要对比或回退到某个历史版本,他们可以直接挂载相应的文件版本。 JuiceFS 克隆功能,它只会创建新的元数据而不复制实际的存储数据,这使得整个过程非常高效。这种方式不仅确保了数据版本的灵活管理,还大大减少了存储空间的需求,提高了操作效率。
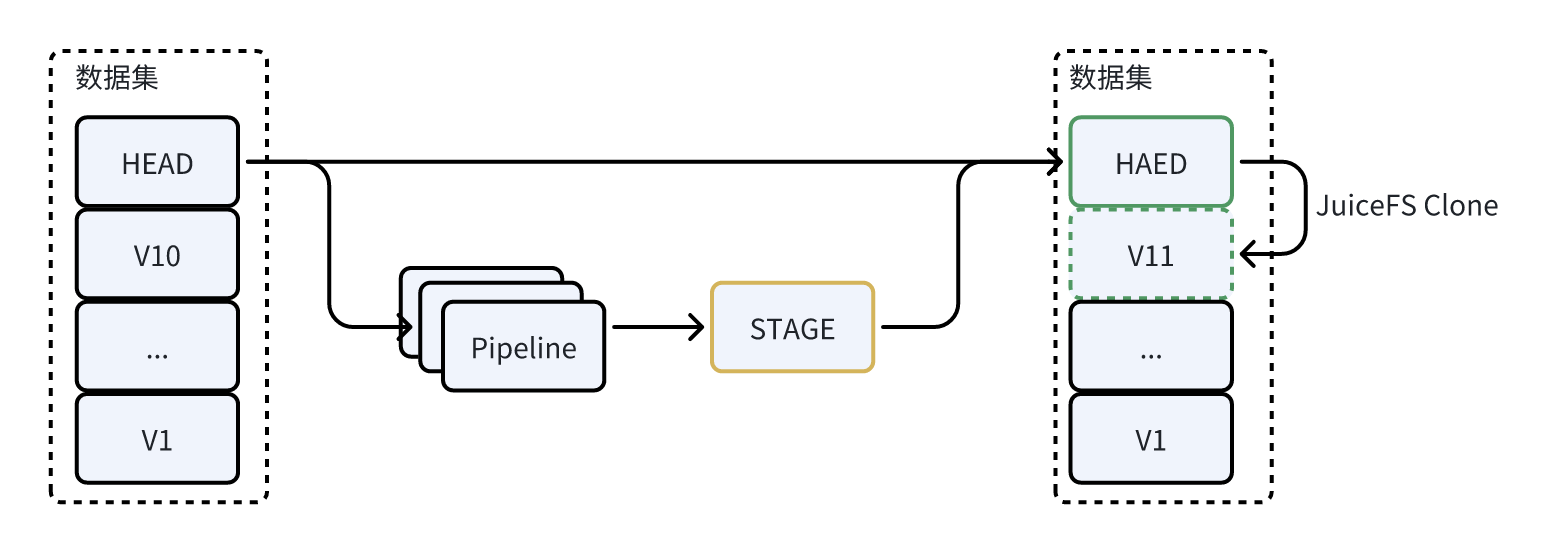
一般,单个数据集包含大约两百个文件,总大小使得克隆操作的完成时间在一秒以内。鉴于版本创建并非频繁进行的操作,这样的性能是完全可以接受的。
此外,JuiceFS 克隆功能在移动或复制数据集时也表现出极高的效率,其使用场景和数据版本管理类似。然而,需要注意的是,克隆功能也有一定的限制,正如文档中所介绍的,它更适用于包含大量小文件、操作频繁的数据集。这种特性使得 JuiceFS 在处理这类特定数据集时尤为高效,而在其他场景下可能需要考虑其限制因素。
最后,我要特别感谢 JuiceFS 团队为我们带来了这样一款卓越的产品,极大地促进了我们数据平台的发展和业务的成功。
关于刻行
刻行是国内人工智能行业场景数据平台的先驱者,通过简化多模态场景智能的研发和运维流程,有效降低技术门槛,致力于解决自动驾驶、机器人、物联网、增强现实等行业在复杂场景数据处理上的高成本和低效率问题。
