














在生物信息学研究领域,NextFlow 是一款主流数据分析工具,广泛应用于多种研究项目。MemVerge,内存融合基础架构厂商,其公有云计算平台产品 Memory Machine Cloud (MMCloud) 无缝集成了 NextFlow,为生物信息学家提供了自动化的高性能计算、checkpoint/restore 功能和云主机选型优化,使他们无需适应新的复杂基础设施管理环境。
执行 NextFlow Pipeline 的关键之一是共享存储,其面临的主要挑战包括:首先,需要处理具有 不同 I/O 需求的任务,这涉及到大文件和海量小文件的操作;其次,因为大多数任务脚本仅支持文件协议,所以对 POSIX 的兼容性是必需的;此外,在一个工作流中,任务的执行顺序依赖于它们之间的相互关系,使得任务的即时状态变得至关重要。
在详细评估了 NFS、S3FS、EFS 和 FusionFS 等多种存储解决方案之后,MemVerge 最终选择了 JuiceFS。JuiceFS 不仅确保了高性能的共享存储解决方案,特别是在处理大量小文件场景中表现出色,在我们的测试中平均每分钟写入小文件的数量是 S3FS的5倍。与此同时,JuiceFS 还具备成本更低的优势。
01 云上使用 NextFlow 的存储痛点
NextFlow + Memverge
在生物信息学行业中, NextFlow 是一款被广泛使用的工作流管理工具。虽然起源于西班牙,但它在美国拥有最大的用户群,英国、德国和西班牙也有大量用户。NextFlow 以其出色的工作流管理功能而闻名,能自动化处理复杂的计算流程,显著简化了操作的复杂性。
NextFlow 本身不提供资源管理和调度功能,需要依赖第三方调度器来执行每一个计算任务。同时,缓存机制对 NextFlow 来说至关重要。一些科研项目,常需频繁访问存储于远程服务如 S3 的公共数据资源。如果每次都直接从 S3 加载数据,将大幅降低效率。因此,NextFlow 利用如 MemVerge 提供的调度器的共享存储功能对数据进行缓存,从而提升数据访问速度,优化整体计算性能。
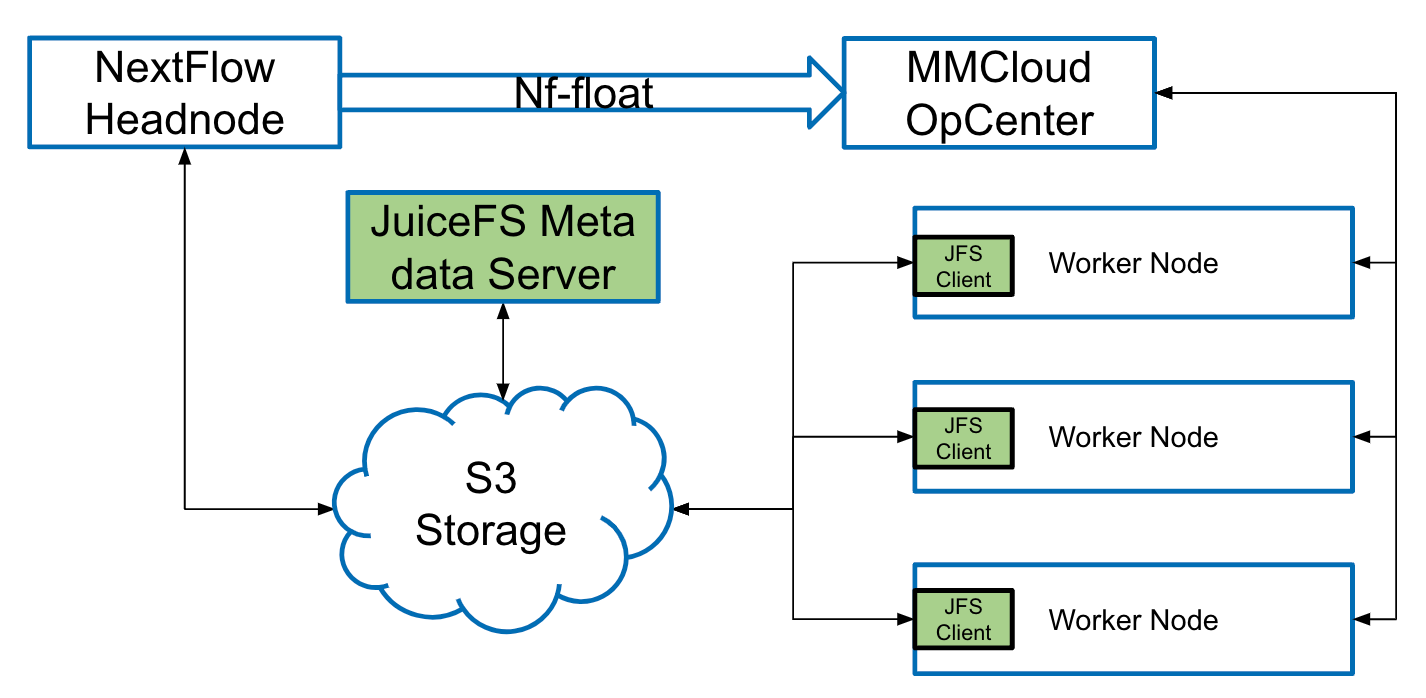
为进一步提升 NextFlow 的效率,我们开发了“nf-float”的开源插件。此插件将 NextFlow 与 MemVerge 的 Memory Machine Cloud(MMCloud) 连接,使得 NextFlow 所有的任务调度通过 MMCloud OpCenter 控制中心来进行。在 OpCenter,我们与云资源供应商如 AWS 、阿里云等,利用云原生 API 精确分配和使用资源。为每个任务动态配置新的云主机实例,并监控任务执行和资源使用,确保效率和成本的最优化。了解更多关于 Memverge + Nextflow 的方案详情。
使用 NextFlow 的存储挑战
在 NextFlow 的架构中,共享存储是其最为关键的机制,它不只追踪每个任务的执行状态以确保整个流程的顺畅,也负责数据共享,使得一个任务的输出可以直接转为另一个任务的输入,从而加速了数据在任务间的流动和交互。所以我们对共享存储做了较多的尝试,以下是我们对共享存储的要求:
-
性能:考虑到共享存储直接影响整个流程的执行效率,其性能必须达到高标准。如果存储响应慢,将拖延任务执行并显著降低整体流程速度,从而造成瓶颈;
-
可扩展性:鉴于不同流程之间及同一流程内部任务对数据的需求存在显著差异,共享存储必须具备优秀的可扩展性,以应对不同的数据容量需求,确保资源使用的高效性;
-
POSIX 兼容性:大多数生物信息学任务都基于 POSIX 标准的文件系统接口设计,而且这些任务的开发者通常是科学家而非计算机科学家。他们更喜欢使用直观的文件操作方法处理数据,因此,共享存储系统需要无缝支持 POSIX 接口,以降低技术门槛;
-
成本效益:这是科研机构选择存储方案时必须考虑的因素。特别是在云计算环境中,如何通过优化存储方案来提高性价比,是一个核心考量。因此,控制存储成本显得格外重要。
02 存储方案探索
EFS vs S3FS vs FusionFS vs JuiceFS
在初步尝试阶段,我们曾自建 NFS 服务器作为共享卷使用,但发现其在处理大规模流程时性能明显不足。随后,我们转向 AWS EFS,尽管其性能尚可,但高昂的成本和与对象存储之间数据传输的不便限制了其适用性。
为兼顾性能和兼容性,我们尝试了 S3FS 解决方案,它提供了 POSIX 文件系统接口。然而,S3FS 在处理大量小文件和频繁写操作时性能显著下降,无法满足高性能需求。
部分用户为了追求更高性能,转而使用 Amazon FSx for Lustre 文件系统。虽然 Lustre 在性能上表现出色,但其高昂的成本使得大多数用户难以承担。
为了能够明确这几个方案的具体差异,我们进行了一个 RNAseq 的测试。RNAseq 是一种用于分析细胞中各种 RNA 的表达量的技术,是一个非常复杂的工作流,包含多达 276 个任务。
公有云提供了 on-demand instance 和 spot instance 两种模式。在 spot instance 模式下,MMCloud 会寻找同等价格下性能更佳的机型,从而进一步减少任务耗时。基于这一特性,我们使用 JuiceFS 在这两种模式下进行了测试。
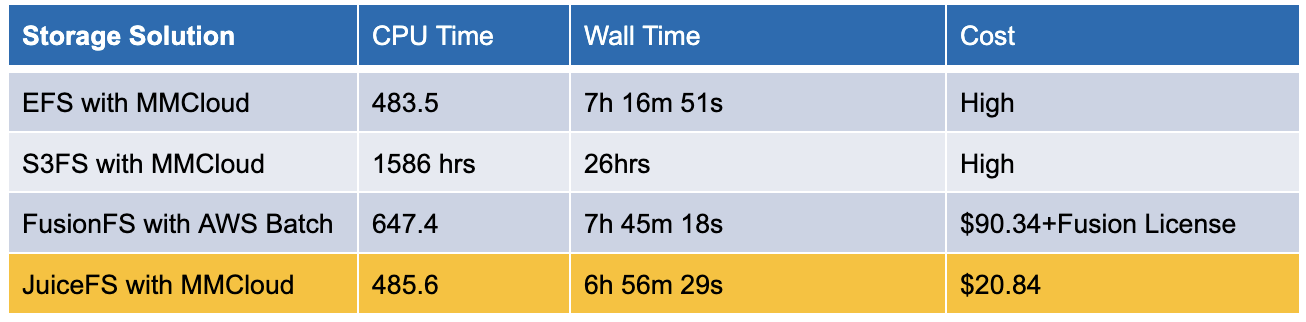
在这个测试中,我们评估了 AWS EFS、S3FS、JuiceFS 以及 FusionFS 的耗时和成本。FusionFS 是 NextFlow 的商业版本提供商 Seqera 为生信研究特别开发的一套分布式文件系统。耗时可参考两个指标,CPU Time,CPU 累计花费的时间总和;Wall Time 代表从任务开始到结束的总运行时间。
-
AWS EFS 集成 MMCloud 方案:整个流程耗时 7 小时完成,但成本较高;
-
S3FS 集成 MMCloud:耗时显著增加至 26 小时,虽然 S3FS 的成本相对较低,但由于运行时间延长,总体成本依然较高;
-
FusionFS 与 AWS Batch 集成:整个流程耗时 7小时 45 分钟,云资源成本高达 90 美元,还需加上 Seqera 的费用;
-
JuiceFS 与 MMCloud 组合:6 小时 56 分钟内完成任务,成本仅为 20 美元,是这组测试中表现最佳的方案。
LOSF 海量小文件写入性能:JuiceFS vs S3FS
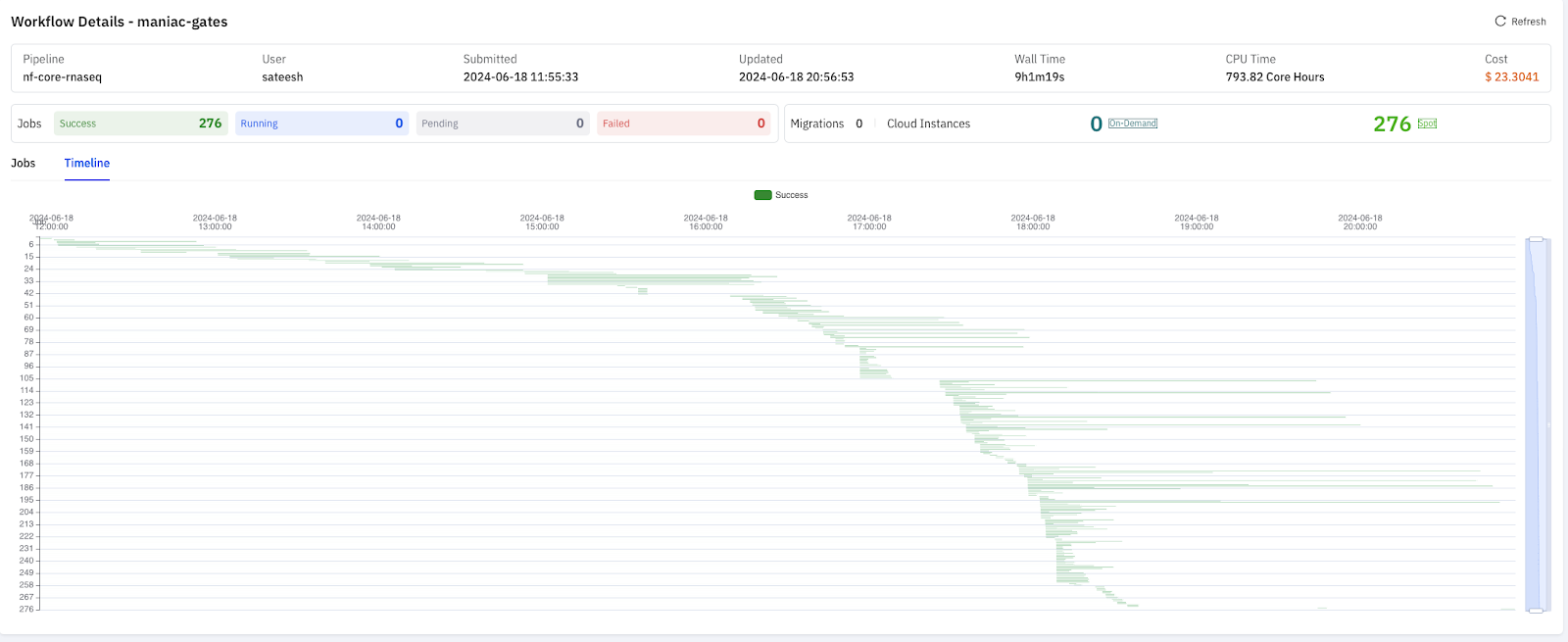
除了整体耗时,为了能了解 S3FS 和 JuiceFS 在测试过程中的差异,我们又进行了一次 RNAseq 的测试,总共有 200 多个任务。如下图所示,每根线均代表了一个任务的执行情况,线段的长度代表任务的耗时。
JuiceFS 在并发处理及相互依赖任务的管理方面表现良好,全程耗时 9 小时,成本仅为 23 美元。
使用 S3FS 时,运行了 9 小时后,整个流程因部分任务长时间无法完成而失败,这时成本已达 37 美元。
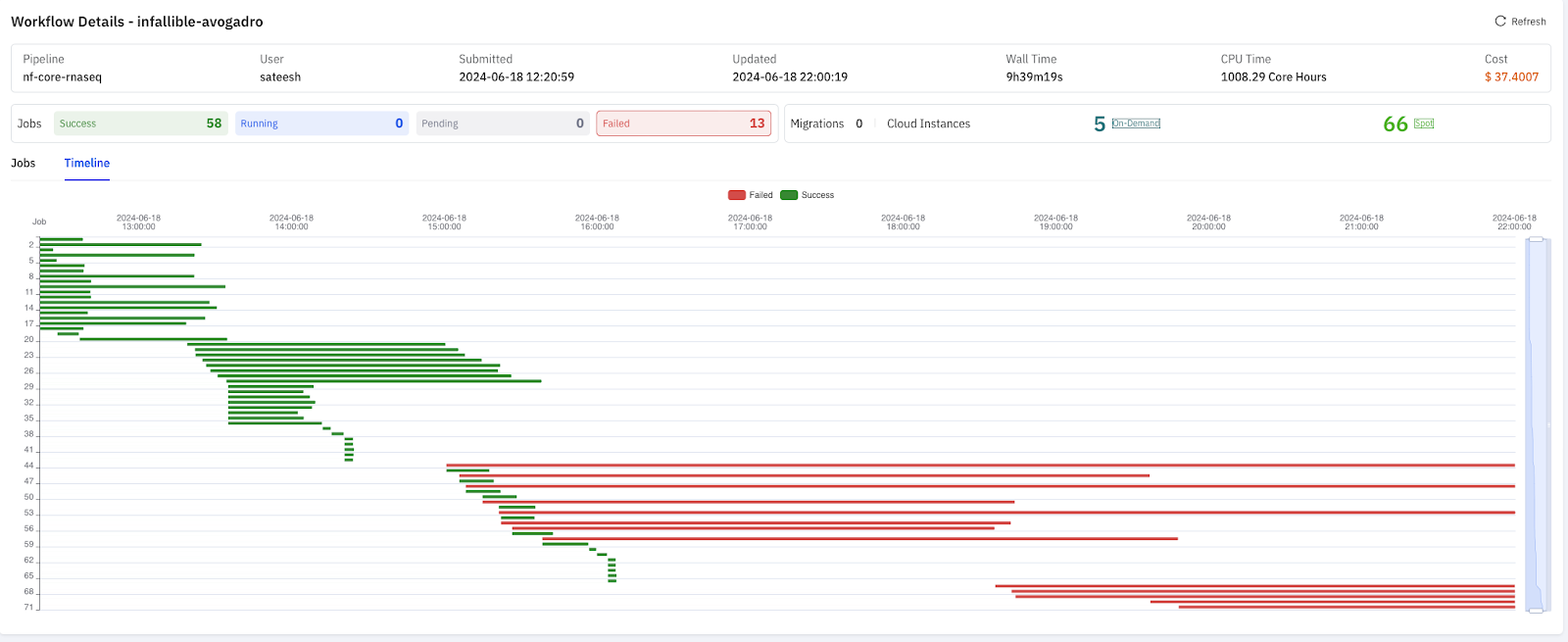
在详细分析 S3FS 的失败任务后,我们发现这些问题主要是由于频繁写入小于 500 字节的小文件引起的。
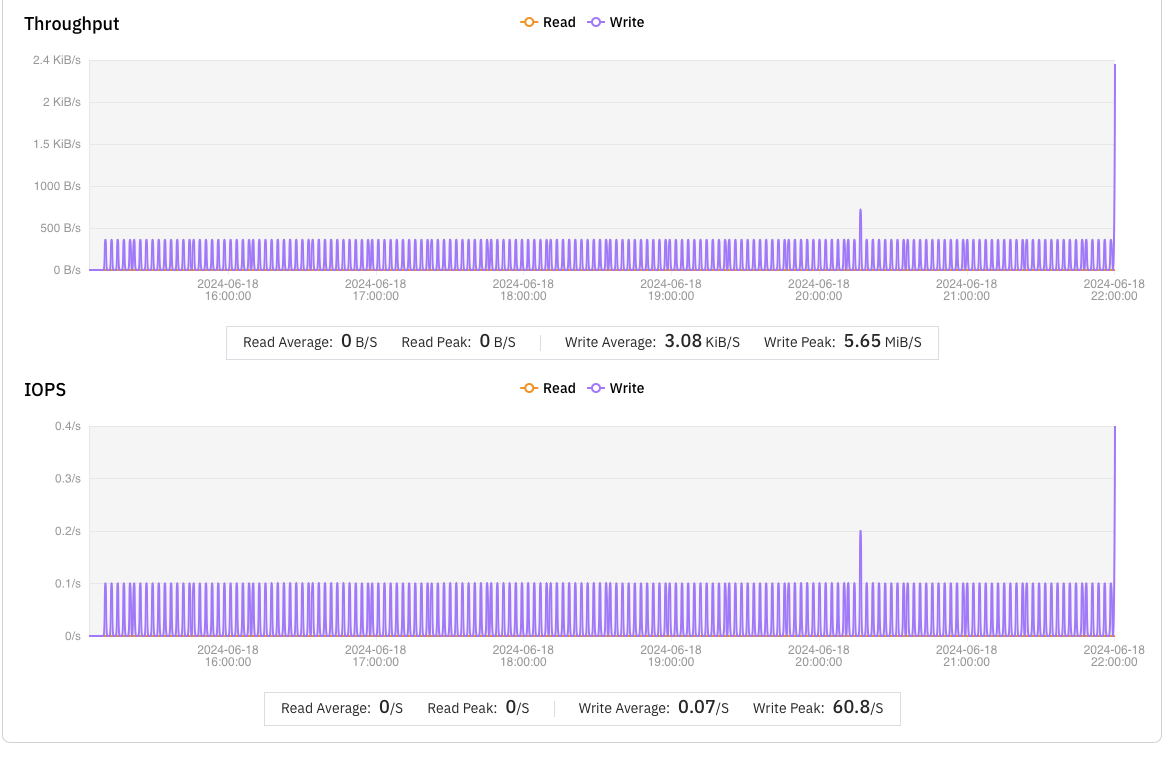
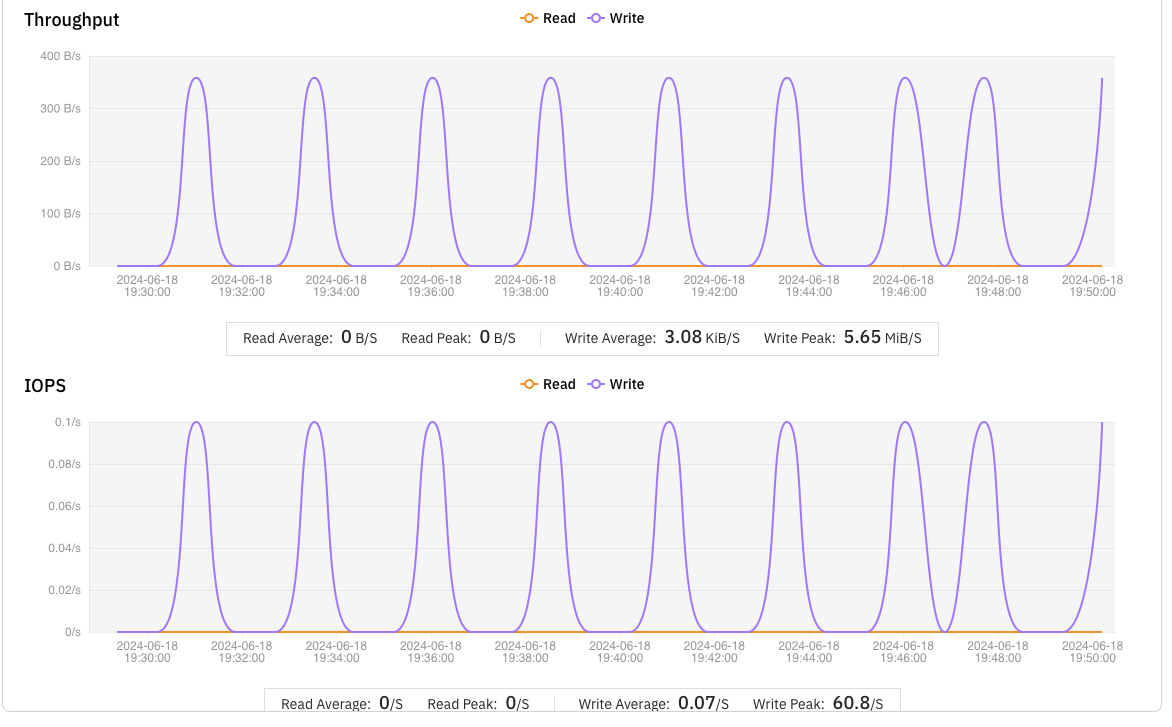
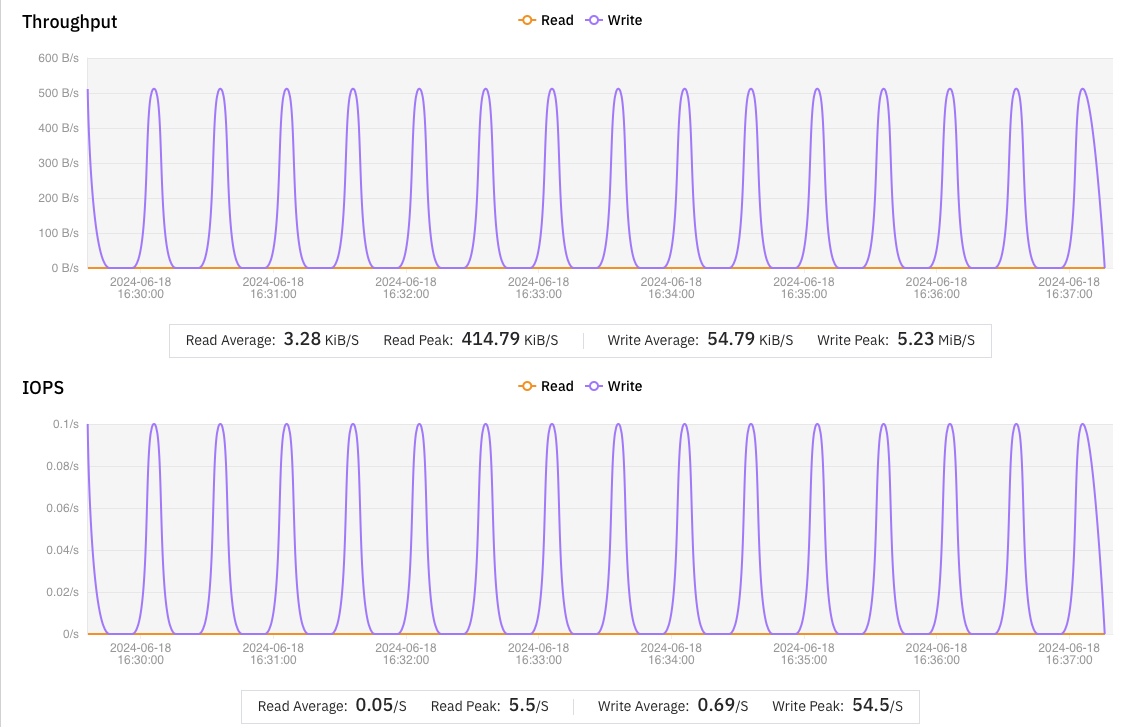
S3FS 在处理此类小文件时效率低下,平均每分钟仅能完成 0.5 个文件,导致大量任务用时过长,进而被 NextFlow 判定为失败任务;相比之下,JuiceFS 每分钟平均能完成 2.5 个小文件的写入,是 S3FS 的 5 倍。
JuiceFS 在性能与成本效益方面的显著优势,因此成为我们的最终选择。在我们的架构中,当 NextFlow 触发任务时,我们利用 OpCenter 机制动态创建一个 JuiceFS 实例。用户需提供对象存储的位置,随后该对象存储将被 OpCenter、NextFlow Headnode 及所有相关方共享,从而全面满足我们的需求。
on-demand 实例 vs spot 实例
公有云提供了 on-demand instance 和 spot instance 两种模式。在 spot instance 模式下,MMCloud 会寻找同等价格下性能更佳的机型,从而进一步减少任务耗时。基于这一特性,我们使用 JuiceFS 在这两种模式下进行了测试。
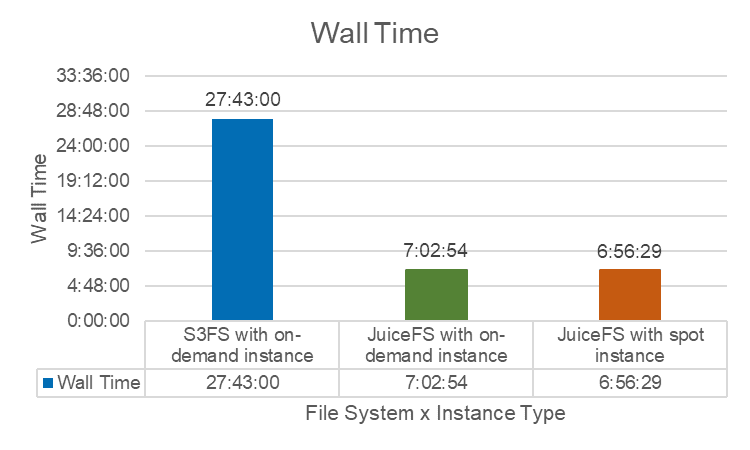
结果如我们预期的相同,JuiceFS 在 MMCloud 的 spot instance 上表现更优;我们也同样测试了 S3FS,耗时远高于 JuiceFS 在两种实例下的表现。
03 未来 JuiceFS 的优化方向
优化数据预处理与传输:目前,许多用户的原始数据集存储在 S3 等对象存储中。在 NextFlow 中,若将共享存储定义为 POSIX 接口,系统可能会自动将 S3 中的数据拷贝到本地共享存储,这一过程(称为数据暂存)往往耗时且低效,因为数据原本就存储在 S3 上,无需额外复制。因此,我们计划引入 S3 接口直接作为 NextFlow 的数据访问界面,从而消除不必要的数据暂存步骤,提高整体流程的效率。
缓存组优化:针对 JuiceFS 云服务及大规模并行任务场景,我们注意到当 NextFlow 流程同时启动大量任务(如 200 个)时,若每个任务都需要独立缓存相同的参考数据,将导致大量重复的数据传输和存储,从而浪费计算资源。为了解决这一问题,我们计划探索实现一种共享缓存机制,确保所有任务能够共享同一套缓存数据,避免每个节点重复缓存相同内容,从而显著提升信息利用效率和整体性能。
挂载点参数优化:在当前的 JuiceFS 挂载过程中,我们主要采用了默认参数配置,这在一定程度上限制了任务性能的最大化。为了进一步提升每个任务的执行效率,我们计划根据任务的具体属性和需求,对 JuiceFS 的参数进行精细化调整和优化。通过定制化的参数配置,我们可以更好地匹配任务的资源需求和执行特点,从而实现性能的最大化提升。
综上所述,我们将围绕数据预处理与传输优化、共享缓存机制的探索以及 JuiceFS 参数的精细化配置等方面展开工作,以期在未来进一步提升 NextFlow 流程的执行效率和性能。
关于 MemVerge
MemVerge,位于美国硅谷,专注于内存技术研发。其产品 MMCloud 利用内存运用专利技术智能调度云资源,显著提高云计算的易用性和资源效率。公司吸引了包括 Intel、NetApp 等行业领先企业的投资。
生物信息学是 MemVerge 主要服务的行业之一,尤其专注于为需要进行大规模遗传分析的企业提供支持。这一领域通常需要高性能计算处理复杂的大数据。面对数据中心建设成本高昂和资源限制的挑战,许多生物信息学公司选择转向云计算平台来执行其计算任务。
MemVerge 的明星客户包括荷兰公司 HZPC,一家在全球土豆遗传研究领域领先的企业;澳大利亚企业 oNKo-innate,在医学界广受赞誉的癌症研究先锋;以及具有百年历史的美国企业 MDI BioScience,该机构专注于研究特定蜥蜴的再生能力,致力于通过基因分析推动人类医学的进步。
