














本文作者:
吕冬冬,云知声超算平台架构师,负责云知声大规模分布式机器学习平台架构设计与新功能演进,负责深度学习算法应用优化与 AI 模型加速。研究领域包括大规模集群调度、高性能计算、分布式文件存储、分布式缓存等。云原生开源社区爱好者。JuiceFS社区版多个重要特性贡献者。
云知声从一家专注于语音及语言处理的技术公司,现在技术栈已经发展到具备图像、自然语言处理、信号等全栈式的 AI 能力,是国内头部人工智能独角兽企业。公司拥抱云计算,在智慧医疗、智慧酒店、智慧教育等方面都有相应的解决方案。
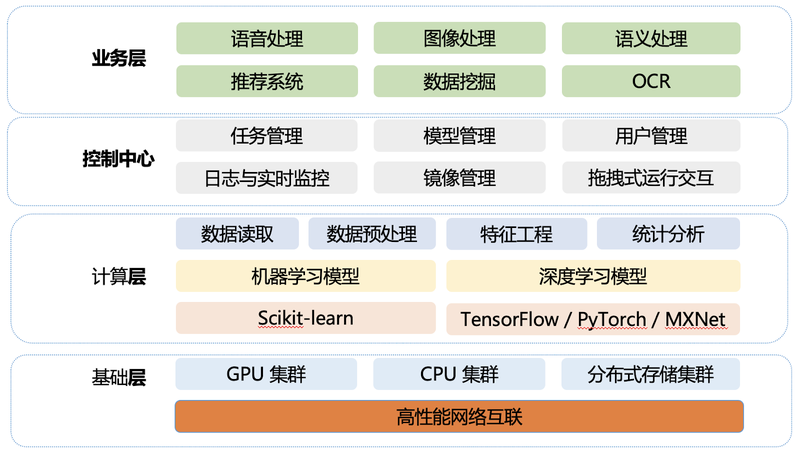
Atlas 是云知声的底层基础技术平台,支撑着云知声所有模型的迭代:
第一层是业务层,主要是公司的业务如语音处理、图像处理、自然语言处理等。
第二层是控制中心,从数据生产、数据接入到模型发布都可以一站式完成。
第三层是核心的计算层,主要支持深度学习,以及数据预处理。
最底层是基础架构层,主要是由 GPU 集群、CPU 集群以及分布式存储构成,所有的机器都是用 100Gbps 的 InfiniBand 高速网互联。
01 存储场景与需求
云知声初期的建设目标就是要建成一站式的 AI 平台,包含 AI 模型的生产,数据预处理,模型开发,模型训练以及最后模型的上线。
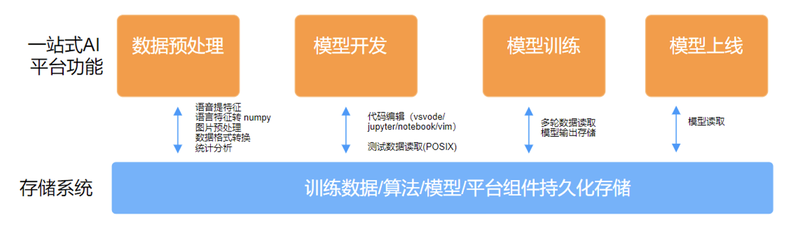
如上图所示,每个步骤都需要跟数据交互,其中数据预处理和模型训练需要比较大的 IO。
- 数据预处理,主要是语音处理会提取语音特征,会把语音特征转成 numpy 格式的文件;图像处理的过程中,会对图像做预处理,做训练数据的格式转换;
- 模型开发,主要是算法工程师做代码的编辑,模型算法的调试;
- 模型训练,途中会需要做多轮数据读取,以及模型会输出到相应的存储上,这个步骤所需要的 IO 非常大;在模型上线的时候,服务会去读取存储系统中的模型文件。总结一下我们对存储的需求:
- 能够对接整个模型开发的的全链路,在几个比较核心的功能块中都要能够支持;
- 支持 CPU、GPU 的数据读取的任务;
- 我们的场景主要是语音、文本和图像数据,这些场景的特点是文件大小都比较小,所以要支持小文件场景下的高性能处理。
- 我们的业务场景主要是读多入写少,模型训练的时候大部分是在读取数据,基本不会写入数据。
基于以上这些需求点,我们需要一套高性能可靠的分布式存储系统。
02 云知声存储建设历程
早期的时候,我们的 GPU 只有十几台左右,当时使用 NFS 做了一个小规模的集群。同时在 2016 年引入了 CephFS 的测试环境,当时那个版本的 CephFS 在小文件场景下性能不太好,所以就没有把 CephFS 带入到生产环境。
后来我们继续做了调研,发现 Lustre 在 HPC 领域是最为常用的高性能文件系统。测试表明 Lustre 在规模化的构建以及性能方面表现都不错,于是从2017 年到 2022 年,我们全部是用 Lustre 来承载所有的数据业务。
但是随着使用的 GPU 越来越多,现在有 5.7 亿亿次/秒左右的浮点处理能力,底层存储的 IO 已经跟不上上层计算能力。于是,我们开始探索新的存储,为后续的存储扩容做升级,同时在使用 Lustre 的过程中也遇到了一些问题。
第一:运维方式,Lustre 主要是基于内核的,直接嵌在内核,有时候定位问题会涉及到机器的重启之类的操作;
第二:技术栈,因为我们的云平台的开发主要是以 golang 为主,所以比较偏向于使用与开发语言比较契合的存储。Lustre 使用的是 C 语言,在定制优化方面需要有较多人力精力。
第三:数据的可靠性,Lustre 主要依赖硬件可靠性(比如 RAID 技术),软件层面主要是实现元数据节点和对象跟数据节点的 HA 方案。相比这些,我们还是更希望使用三副本或者是纠删码这类更可靠的软件方案。
第四:多级缓存的功能的需求,在 2021 年的时候,我们用了 Fluid + Alluxio 来作为 Lustre 的分布式加速,Alluxio 能够较好的为我们的集群做计算提速,减轻底层存储的压力。但是我们一直在探索希望直接从存储系统来进行客户端缓存,这样操作对用户来说能够更加透明一点。
在 2021 年的时候 JuiceFS 刚开源时,我们就对它的特性做了调研。
第一,产品特性:JuiceFS 支持 POSIX 接口,能够以 HostPath 的方式去挂载,这种方式跟我们在使用 NAS 的方式是一模一样的,用户在使用时基本不用做任何改变;JuiceFS 元数据以及对象存储,都有比较多的可选方案,像Redis、 TiKV在AI领域是比较合适的。底层 Ceph、MinIO 还有一些公有云的对象存储用户都可以自行选择。
第二,上层调度:JuiceFS 除了支持 HostPath,同时也是支持CSI 驱动方式,能够以更加云原生的方式让用户去接入相应的存储。
第三,业务框架适配:POSIX 接口适配深度学习框架。第四,运维:元数据引擎以及对象存储,业界方案都比较成熟,选择也比较多,而且 JuiceFS 有元数据自动备份以及回收站功能。JuiceFS 与业务比较契合,因此我们进行了 POC 测试。
测试环境如上图所示,结果发现 Lustre 跟 JuiceFS 来相比,由于JuiceFS 直接用到了内核页缓存,相比 Lustre 直接访问机械盘,性能有很大提升(如下图所示,越小越好)。
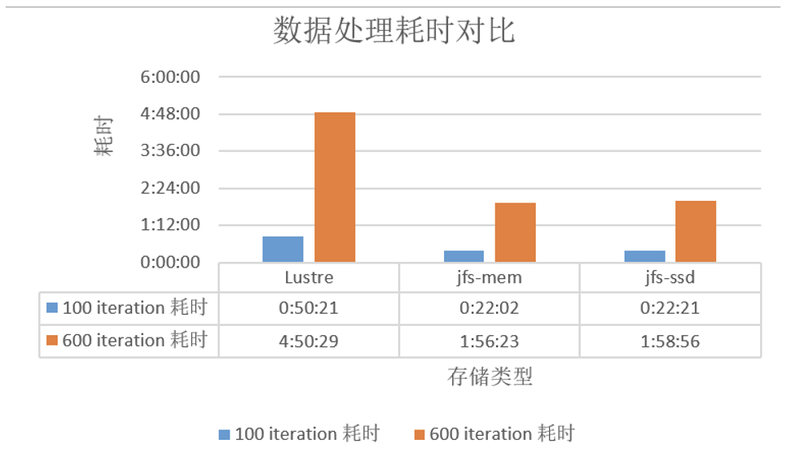
经过了 POC 测试,我们决定把JuiceFS 带入生产环境。目前整个Atlas 的集群所有 GPU 的计算节点,以及所有的开发调试节点,都安装了 JuiceFS 客户端。
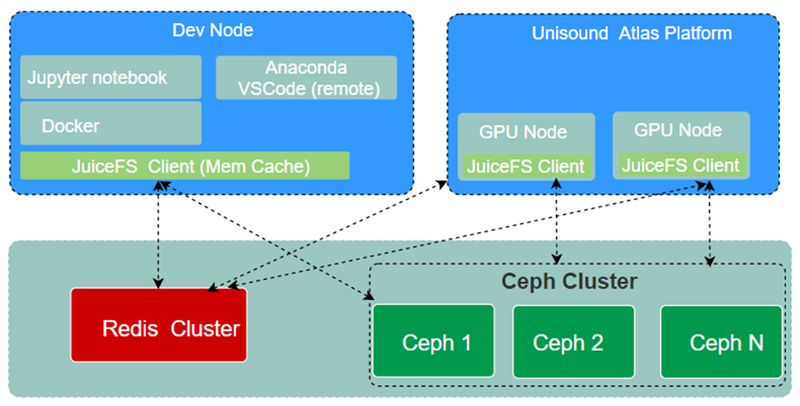
JuiceFS 直接对接redis 集群和ceph,计算节点大部分用的 HostPath 方式接入。同时 Atlas 集群也部署了 JuiceFS CSI Driver,用户可以以云原生的方式接入。
03 JuiceFS 在 Atlas 的使用方式
为了保证数据的安全性,超算平台上的每个组归属于不同的目录,每个目录下是各自组内或者部门内的成员,不同组之间的目录是不可见的。
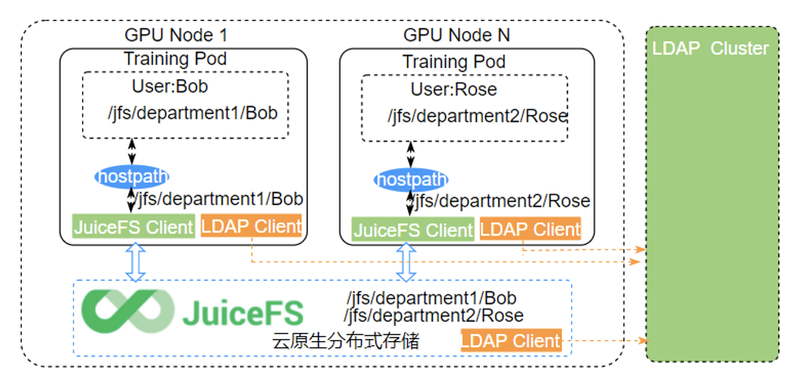
目录的权限是基于 Linux 的权限管控机制。用户在 Atlas 集群提交训练任务的时候,集群的任务提交工具会自动读取系统上用户的 UID 与 GID 信息,然后将其注入用户提交的任务 Pod 的 SecurityContext 字段,则 Atlas 集群上运行的容器 Pod 内所有容器的进程运行的 UID 与存储系统上的信息一致,保证权限不越界。
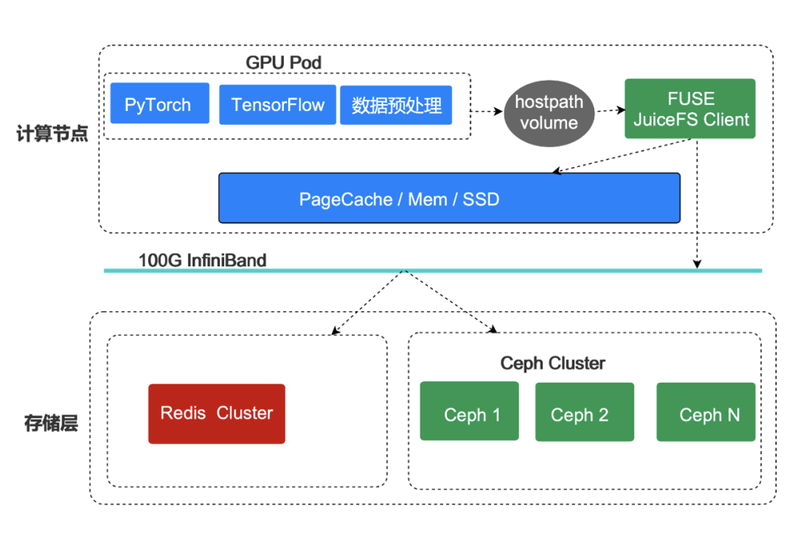
节点访问 JuiceFS,实现了多级缓存:
- 第一级:缓存就是内存的页缓存。
- 第二级:所有的计算节点的多块 SSD,提供二级的加速能力。
- 第三级:使用 Ceph。如果 3 块 1t 的 SSD 还是不能支撑用户的数据,那它会从 Ceph 读取。
2021 年初的时候,云知声和 JuiceFS 团队一起把 JuiceFSRuntime 集成到 Fluid 上面。因为以裸机的方式去用缓存,我们发现用户对缓存的可见性比较不好,缓存的清理全部是系统自动做的,用户的可控性没那么高,所以才会把 JuiceFS 集成到 Fluid 。
Fluid 会启动 JuiceFS 相关的组件,包括 FUSE 和 Worker Pod。其中 FUSE Pod 提供了 JuiceFS 客户端的缓存能力,Worker Pod 则实现了对缓存生命周期的管理,Atlas 平台的 AI 离线训练任务通过与 FUSE Pod 客户端交互,进行 AI 训练数据的读取。
通过 Fluid 提供的缓存调度能力以及数据集的可观测性,平台的用户可以通过亲和调度将缓存部署在特定的计算节点上,同时用户能够直观的看到缓存的使用情况(例如缓存数据集的大小、缓存的百分比、缓存的容量等)。
04 JuiceFS 的建设实践
目前 Atlas 不能访问公网,是在专用的隔离网内,因此我们全部都是私有化部署。
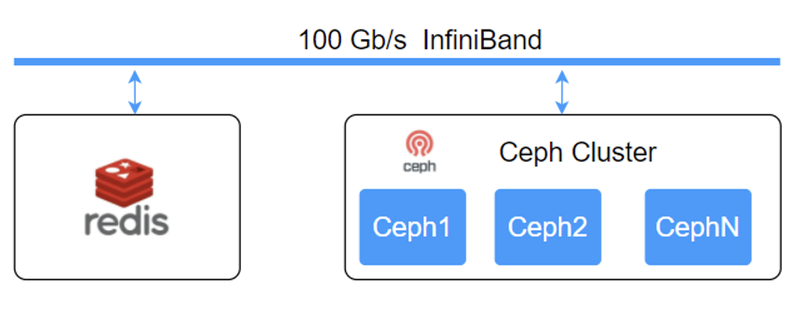
我们生产环境的元数据引擎采用 Redis,2020 年的时候,TiKV 对接到 JuiceFS 还不是很成熟,我们计划首先用 Redis 来做过渡,对象存储的是用 Ceph。Redis 节点的系统盘做了 RAID1,同时 Redis 持久化的数据会定期同步到另一台备份节点上。Redis 的数据持久化我们采用 AOF + RDB 的方案,每秒进行一次数据持久化。
对象存储采用自建的 Ceph 集群,Ceph 集群采用 Cephadm 进行部署,目前生产环境用的是 Octopus 版本。我们当时借鉴了很多业界的方案,对存储器在存储器层面做了一些优化,以及在软件层面也做了相应的调优,主要如下:
服务器层面(参考):
- 42 Cores 256GB 24*18T HDD
- 系统盘: 2* 960G SAS SSD
- BlueStore
- 关闭 NUMA
- 升级 kernel: 5.4.146 开启 io_uring
- Kernel pid max,修改 /proc/sys/kernel/pid_max
Ceph 配置方面:
- Ceph RADOS:直接调用 librados 接口,不走 S3 协议
- Bucket shard
- 关闭 pg 的自动调整功能
- OSD 日志存储(采用 bluestore,建议裸容量配比—— block : block.db : block.wal = 100:1:1,后两者建议采用 SSD 或 NVMe SSD)
- 3 副本
重点提下,要把 Ceph 集群的内核升到比较新的版本,然后开启 io_uring 功能,这样性能会有比较大的提升。在软件方面我们是直接调用了rados 的接口,就不走 S3 协议了,效率会稍微高一点,所有的节点用 100G 的 InfiniBand 高速网络去做互联。
云知声环境中 JuiceFS 对接的对象存储是 Ceph RADOS,JuiceFS 采用 librados 与 Ceph 进行交互,因此需要重新编译 JuiceFS 客户端,建议 librados 的版本要跟 Ceph 的对应,这点要注意一下。如果用 CSI Driver 的时候,在 PV/PVC 的创建,会读取 /etc/ceph/ceph.conf 也要注意版本的支持。
完善的监控体系
现在整个链路比较长了,底层有元数据引擎集群、Ceph 对象存储集群,还有上层的客户端以及业务,每层都要有相应的监控方案。
客户端节点,我们主要是做日志的收集,需要注意的是各个挂载点 JuiceFS 客户端日志要做汇聚,error 告警,避免日志将系统磁盘打爆或者节点无法写。
各个 JuiceFS 客户端也要有相应的监控手段,比如查看各挂载点的 .stat 文件和日志观察指标是否正常,然后看看 Redis 跟 Ceph 集群的 IO 与日志,要保证整个链路都是可控的,这样定位问题就比较方便。
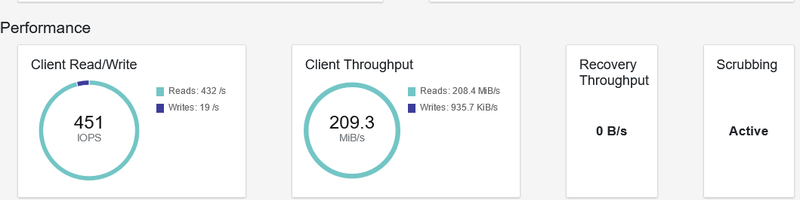
上图是 Ceph 的监控图,因为我们的客户端节点用的是 SSD 的缓存,现在数据基本不会读取到 Ceph,大部分是缓存在读取,所以 Ceph 的流量不大。
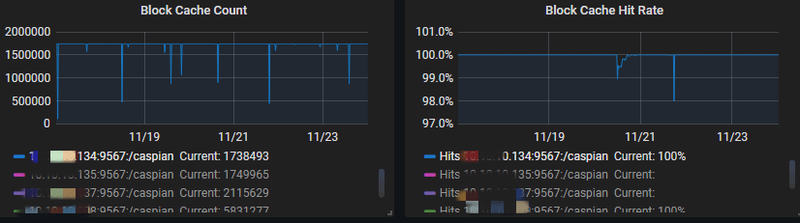
上图是 JuiceFS 监控上截取的数据,可以看到节点的基本百分百至百分之九十几都能够命中,缓存命中率还是比较高的,大部分数据还是在走缓存的。
参与JuiceFS 社区建设
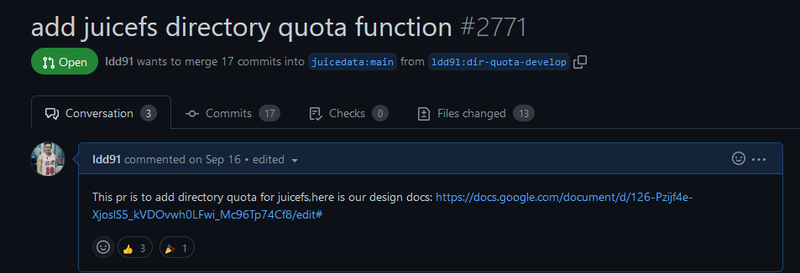
云知声在使用 JuiceFS 社区版的过程中,一直积极参与社区建设。在 2021 年和 JuiceData 团队合作开发了上文中提到的 Fluid JuiceFS Runtime。近期, 我们发现社区版基于目录的配额还没有开发,于是在前几个月我们开发了一个版本,对目录的文件数跟文件大小做了限制, PR 目前已经提交,现在也正在跟 JuiceFS 社区一起进行合并的工作。
05 JuiceFS 在 Atlas 的使用场景与收益
JuiceFS 客户端多级缓存目前主要应用在我们的文字识别、语音降噪以及语音识别场景。由于 AI 模型训练的数据读取特点是读多写少,我们充分利用 JuiceFS 客户端的缓存带来 IO 读取的加速收益。
收益一:加速 AI 模型训练
1)语音降噪测试
降噪场景模型的测试中使用的是散文件,每个数据都是 wav 格式,小于 100k 的语音小文件,在降噪场景我们测试了数据 dataload 阶段的 I/O 数据,JuiceFS 客户端节点的内存缓存为 512G,在 500h 规模的数据下、以 40 的 batch size 进行测试。
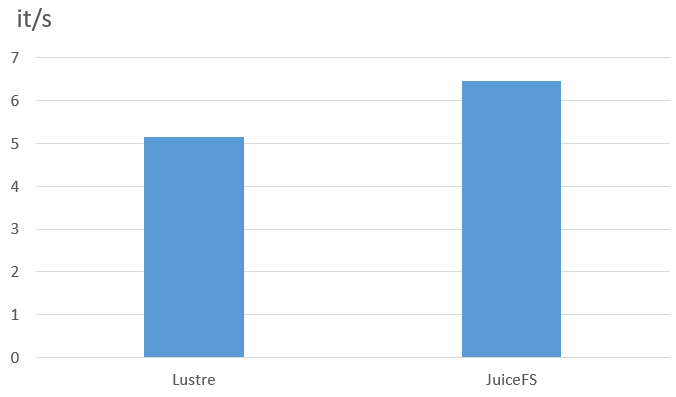
从测试结果来看,单从数据读取效率上,在 wav 小文件方面,JuiceFS 为 6.45 it/s,而 Lustre 为 5.15 it/s,性能提升 25%。JuiceFS 有效加速了我们端到端的模型训练,整体缩短了模型的产出时间。
2)文字识别场景
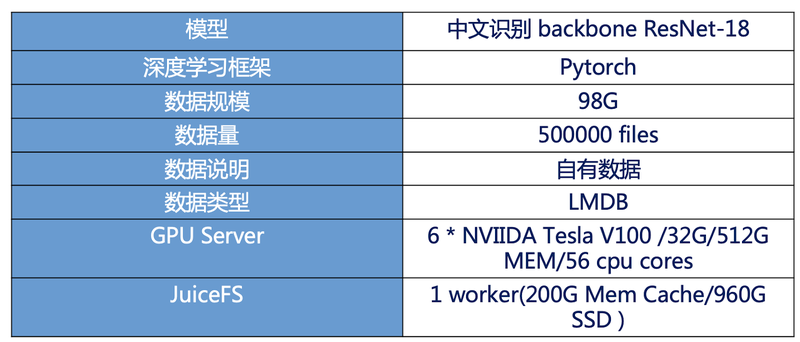
在文字识别场景中,模型为 CRNN backbone 为 MobileNet v2 ,测试环境如下:
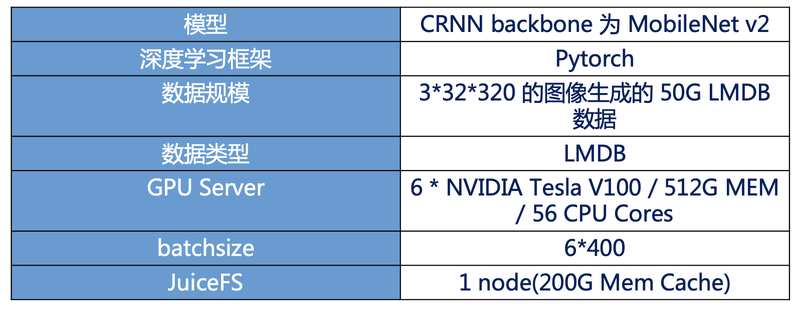
生成了一个 LMDB 的大数据文件,这时候 IO 对带宽的要求比较高,而不是对小文件的性能要求。200G 内存缓存是能支撑整个数据的,所以我们没有走底层的存储,而是直接从客户端读取,整体性能也有比较大的提升。
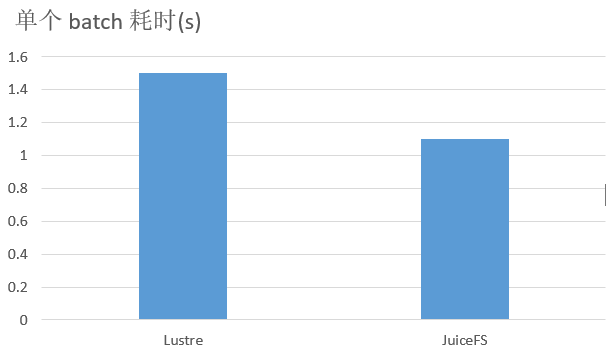
在这个测试中,主要做了 JuiceFS 跟 Lustre 的速度对比,从实验的结果来看从 Lustre 读每个 batch 耗时 1.5s,从 JuiceFS 读每个 batch 耗时为 1.1s,提升36%。从模型收敛的时间来看,从 Lustre 的 96 小时下降到 JuiceFS 的 86 小时,使用 JuiceFS 能够将 CRNN 模型的产出时间缩短 10 小时。
模型调试与数据处理
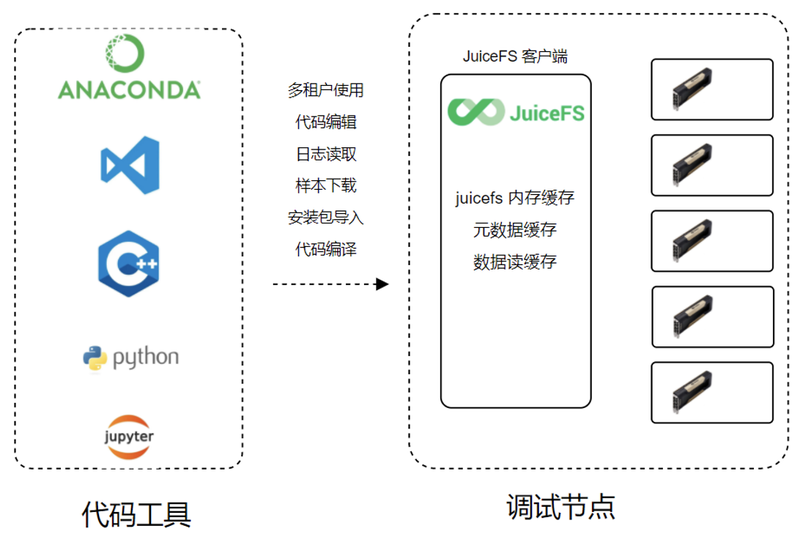
做代码调试时,多个用户会同时在一台调试机上去运行模型测试,以及代码的遍历,当时统计了大部分用户是会使用一些远程的 IDE,连接到调试节点,然后构建自己的虚拟环境,会把大量的安装包提前安装在Lustre上。
大部分都是几十k 或者几百k 的小文件,要把这些包导入在我们内存上。之前使用 Lustre 时,因为用户太多了所以需求吞吐较高,同时对小文件性能要求比较高,发现效果不是很好,在 import 包时会比较卡,导致代码调试的时候比较慢,整体效率比较低。
后来使用了JuiceFS 客户端的缓存,在第一次编译时也比较慢,但第二次的编译时因为数据已经全部落在缓存上,速度和效率就比较高了,代码跳转也就比较快,代码提示 import 也比较快。用户测试后大概有 2~4 倍的速度提升。
06 结语
从 Lustre 到JuiceFS
从 2017 年到 2021 的时候,我们用 Lustre 也是比较稳定的,集群存储量少于 50% 的时候,软件的稳定性都是比较高的。
Lustre 作为老牌 HPC 领域的存储系统,为许多全球最大的超算系统提供动力,具有多年的生产环境经验。其具有符合 POSIX 标准、支持各种高性能低时延的网络,允许 RDMA 访问的优点,适用于传统 HPC 领域的高性能计算,跟深度学习的接口是契合的,所有的业务都是不需要做代码修改。但是也有一些缺点:
第一,Lustre 无法支持云原生 CSI Driver。
第二,Lustre 对运维人员的要求比较高,因为全部是以 C 语言写的,有时候出一些 Bug 无法快速解决,整体社区的开放性和活跃度不是很高。
JuiceFS 有这样一些特点:
第一,JuiceFS 是一款云原生领域的分布式存储系统产品,提供了 CSI Driver 以及 Fluid 等方式使用能够更好地与 Kubernetes 进行结合。
第二,JuiceFS 的部署方案比较灵活,元数据引擎可选性高,对象存储如果用户网络允许,其实对接到公有云的对象存储会更好。
第三,在存储扩容运维方面较为简单。完全兼容 POSIX 标准使得深度学习的应用可以无缝迁移,但是由于后端对象存储的特点,使得 JuiceFS 在随机写方面会有较高的延迟。
第四,JuiceFS 支持本地缓存、内核页缓存,实现了冷热数据的分层和加速。这一点是我们比较看重的,在我们的业务场景是比较合适的,但是在随机写的时候就不太合适。社区版本目前分布式缓存的功能也还不提供。
后续规划
- 元数据引擎升级,TiKV 适合在 1 亿以上文件数量(最多可以支撑到百亿级文件),对性能以及数据安全都有较高要求的场景,目前我们已经完成了 TiKV 的内部测试也在积极跟进社区的进展,后续要将元数据引擎迁移到 TiKV。
- 目录配额优化,目前已经把基础版本的功能合入到了JuiceFS 社区版本,也跟 JuiceFS 社区进行了讨论,在一些场景上有些性能还需要优化。
- 希望去做一些 Nonroot 的功能,现在所有的节点都是 root 权限能访问所有的数据,权限太大我们希望只在特定节点去开放 root 的权限。
- 最后也会去看看社区这边的话是否有 QoS 的方案,比如基于 UID 或者 GID 的限速。
