














作者简介
- 王振华,趣头条大数据总监,趣头条大数据负责人。
- 王海胜,趣头条大数据工程师,10 年互联网工作经验,曾在 eBay、唯品会等公司从事大数据开发相关工作,有丰富的大数据落地经验。
- 高昌健,Juicedata 解决方案架构师,十年互联网行业从业经历,曾在知乎、即刻、小红书多个团队担任架构师职位,专注于分布式系统、大数据、AI 领域的技术研究。
背景
趣头条大数据平台目前有一个近千节点的 HDFS 集群,承载着存储最近几个月热数据的功能,每日新增数据达到了百 TB 规模。日常的 ETL 和 ad-hoc 任务都会依赖这个 HDFS 集群,导致集群负载持续攀升。特别是 ad-hoc 任务,因为趣头条的业务模式需要频繁查询最新的数据,每天大量的 ad-hoc 查询请求进一步加重了 HDFS 集群的压力,也影响了 ad-hoc 查询的性能,长尾现象明显。集群负载高居不下,对很多业务组件的稳定性也造成了影响,如 Flink 任务 checkpoint 失败、Spark 任务 executor 丢失等。
因此需要一种方案使得 ad-hoc 查询尽量不依赖 HDFS 集群的数据,一方面可以降低 HDFS 集群的整体压力,保障日常 ETL 任务的稳定性,另一方面也能减少 ad-hoc 查询耗时的波动,优化长尾现象。
方案设计
趣头条的 ad-hoc 查询主要依靠 Presto 计算引擎,JuiceFS 的 Hadoop SDK 可以无缝集成到 Presto 中,无需改动任何代码,以不侵入业务的方式自动分析每一个查询,将需要频繁读取的数据自动从 HDFS 拷贝至 JuiceFS,后续的 ad-hoc 查询就可以直接获取 JuiceFS 上已有的缓存数据,避免对 HDFS 产生请求,从而降低 HDFS 集群压力。
另外由于 Presto 集群是部署在 Kubernetes 上,有弹性伸缩集群的需求,因此需要能够将缓存数据持久化。如果使用独立的 HDFS 或者某些缓存方案的话,成本会很高,此时 OSS 成为最理想的选择。
整体方案设计如下图所示。绿色部分表示 JuiceFS 的组件,主要包含两部分:JuiceFS 元数据服务(下图中的 JuiceFS Cluster)及 JuiceFS Hadoop SDK(下图与 Presto worker 关联的组件)。
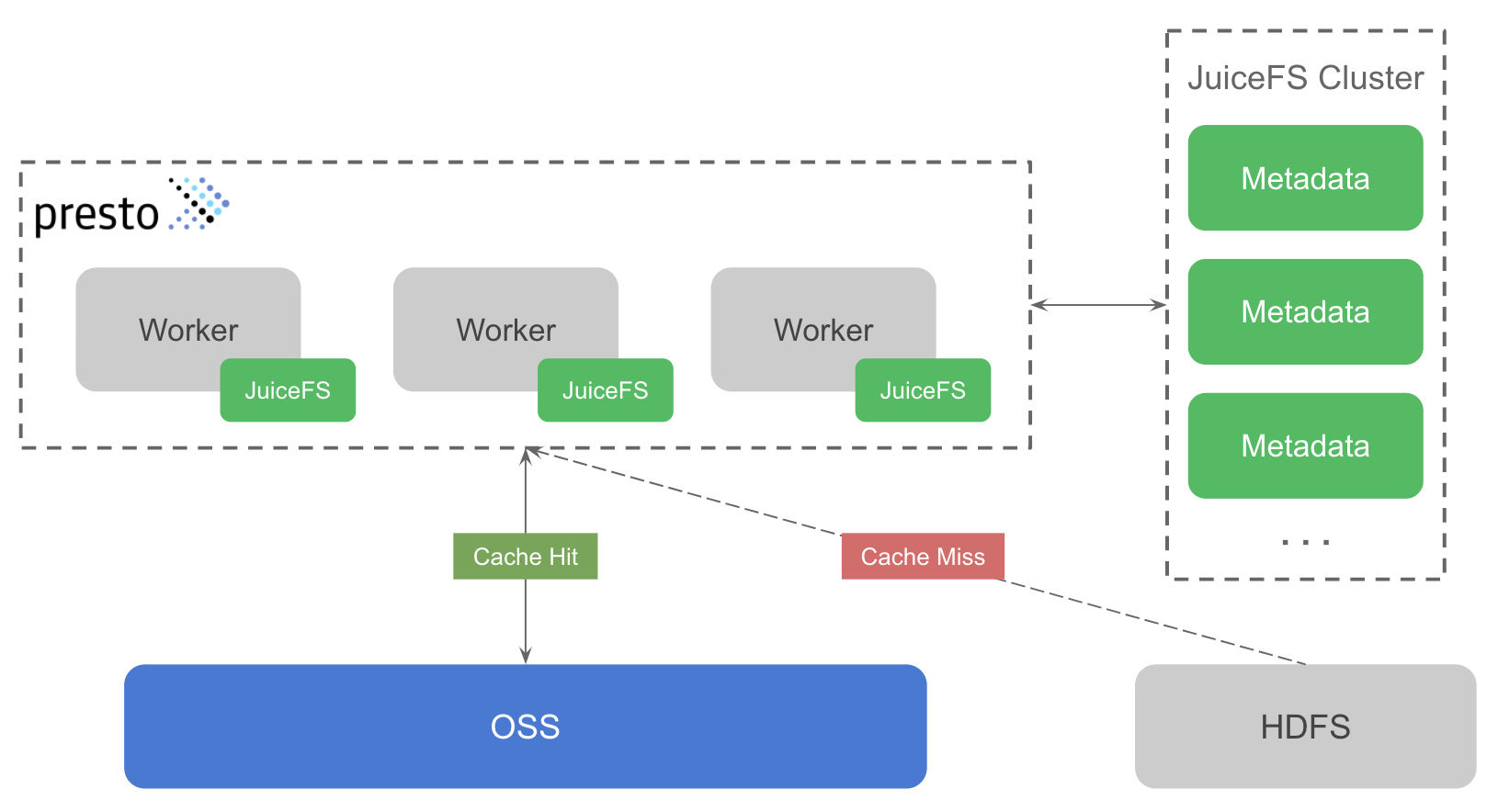
JuiceFS 元数据服务用于管理文件系统中所有文件的元信息,如文件名、目录结构、文件大小、修改时间等。元数据服务是一个分布式集群,基于 Raft 一致性协议,保证元数据强一致性的同时,还能确保集群的可用性。
JuiceFS Hadoop SDK(以下简称 SDK)是一个客户端库,可以无缝集成到所有 Hadoop 生态组件中,这里的方案即是集成到 Presto worker 中。SDK 支持多种使用模式,既可以替代 HDFS 将 JuiceFS 作为大数据平台的底层存储,也可以作为 HDFS 的缓存系统。这个方案使用的便是后一种模式,SDK 支持在不改动 Hive Metastore 的前提下,将 HDFS 中的数据透明缓存到 JuiceFS 中,ad-hoc 查询的数据如果命中缓存将不再需要请求 HDFS。同时 SDK 还能保证 HDFS 与 JuiceFS 间数据的一致性,也就是说当 HDFS 中的数据发生变更时,JuiceFS 这边的缓存数据也能同步更新,不会对业务造成影响。这是通过比较 HDFS 与 JuiceFS 中文件的修改时间(mtime)来实现的,因为 JuiceFS 实现了完整的文件系统功能,所以文件具有 mtime 这个属性,通过比较 mtime 保证了缓存数据的一致性。
为了防止缓存占用过多空间,需要定期清理缓存数据,JuiceFS 支持根据文件的访问时间(atime)来清理 N 天前的数据,之所以选择用 atime 是为了确保那些经常被访问的数据不会被误删除。需要注意的是,很多文件系统为了保证性能都不会实时更新 atime,例如 HDFS 是通过设置 dfs.namenode.accesstime.precision 来控制更新 atime 的时间间隔,默认是最快 1 小时更新 1 次。缓存的建立也有一定的规则,会结合文件的 atime、mtime 和大小这些属性来决定是否缓存,避免缓存一些不必要的数据。
测试方案
为了验证以上方案的整体效果,包括但不限于稳定性、性能、HDFS 集群的负载等,我们将测试流程分为了多个阶段,每个阶段负责收集及验证不同的指标,不同阶段之间可能也会进行数据的横向比较。
测试结果
HDFS 集群负载
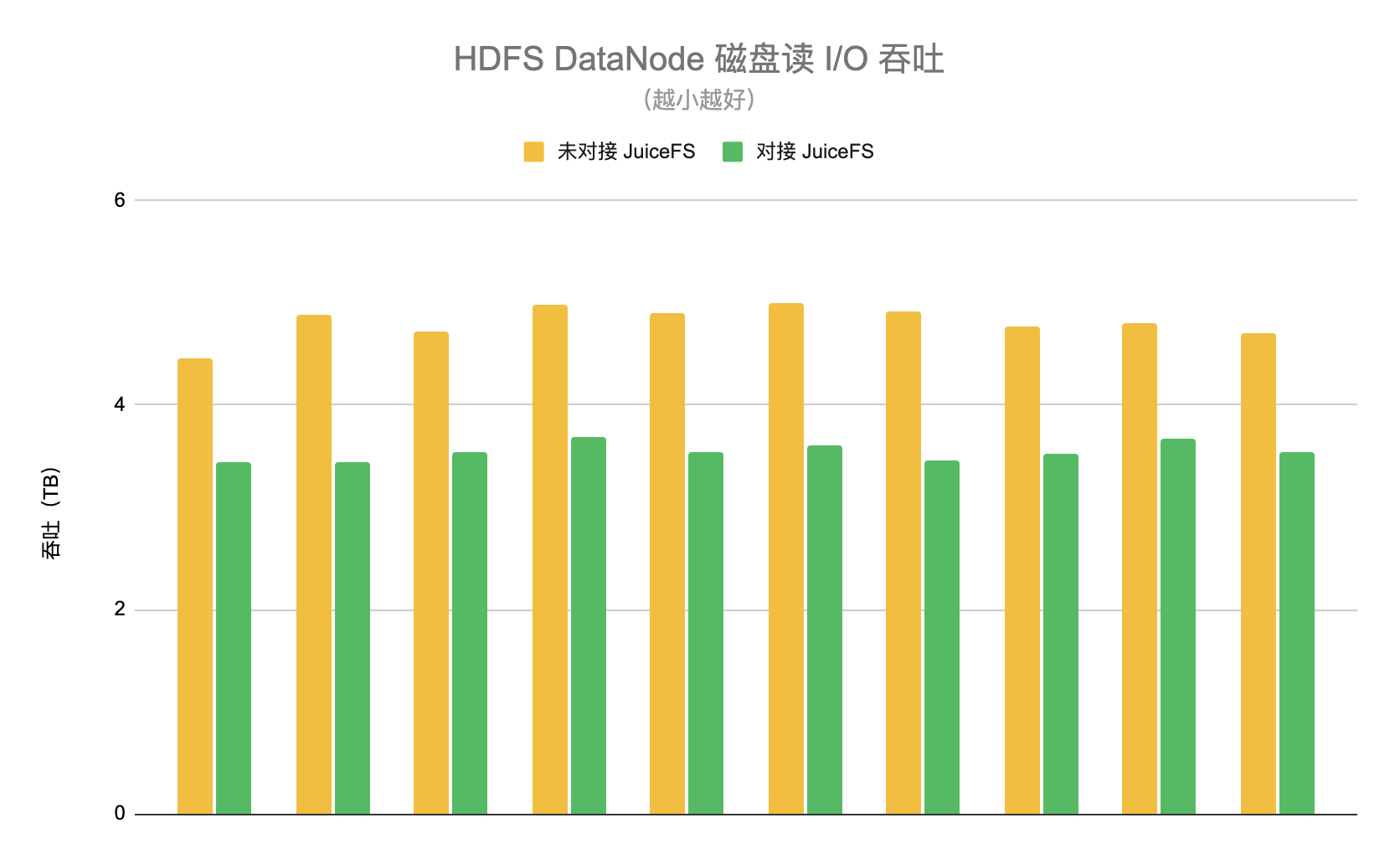
我们设计了两个阶段分别开启和关闭 JuiceFS 的功能。在开启阶段随机选取 10 台 HDFS DataNode,统计这一阶段每台 DataNode 平均每天的磁盘读 I/O 吞吐,平均值约为 3.5TB。在关闭阶段同样选择这 10 个节点,统计下来的平均值约为 4.8TB。因此使用 JuiceFS 以后可以降低 HDFS 集群约 26% 的负载,如下图所示。
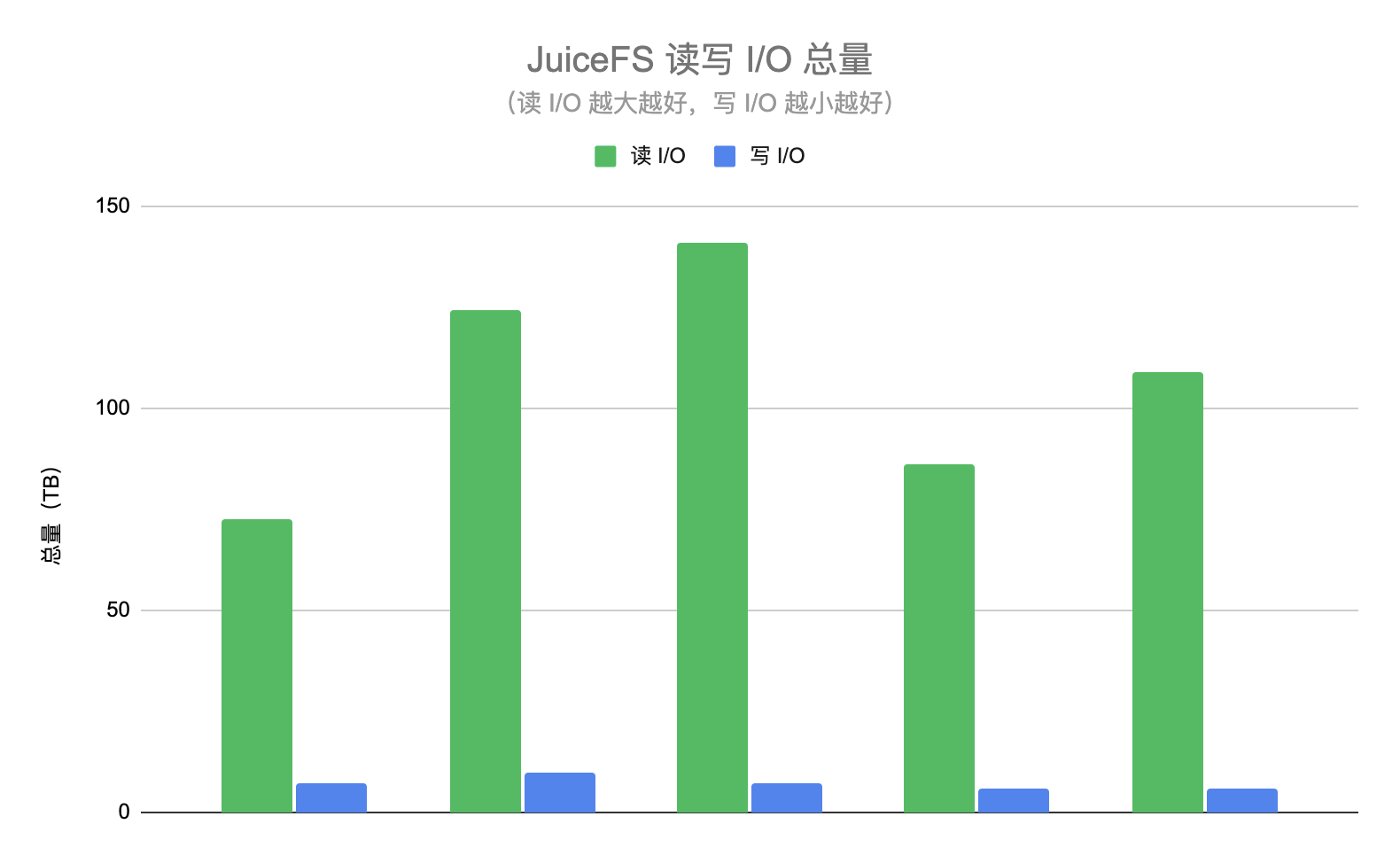
从另一个维度也能反映 HDFS 集群负载降低的效果,在这两个阶段我们都统计了读取及写入 JuiceFS 的 I/O 总量。JuiceFS 的读 I/O 表示为 HDFS 集群降低的 I/O 量,如果没有使用 JuiceFS 那么这些请求将会直接查询 HDFS。JuiceFS 的写 I/O 表示从 HDFS 拷贝的数据量,这些请求会增大 HDFS 的压力。读 I/O 总量应该越大越好,而写 I/O 总量越小越好。下图展示了某几天的读写 I/O 总量,可以看到读 I/O 基本是写 I/O 的 10 倍以上,也就是说 JuiceFS 数据的命中率在 90% 以上,即超过 90% 的 ad-hoc 查询都不需要请求 HDFS。
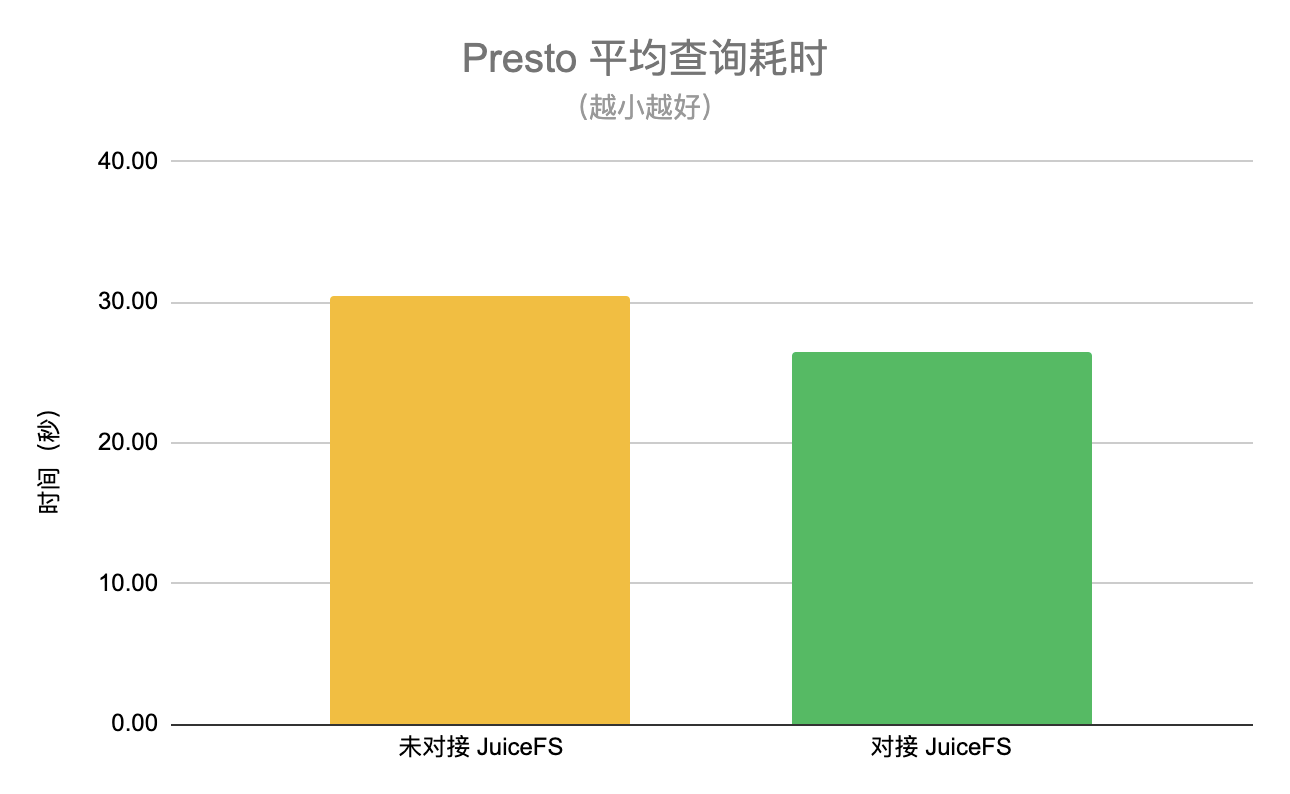
平均查询耗时
在某一阶段将各 50% 流量的查询请求分配给未对接和已对接 JuiceFS 的两个集群,并分别统计平均查询耗时。从下图可以看到,使用 JuiceFS 以后平均查询耗时降低约 13%。
测试总结
JuiceFS 的方案在不改动业务配置的前提下,以对业务透明的方式大幅降低了 HDFS 集群的负载,超过 90% 的 Presto 查询不再需要请求 HDFS,同时还降低了 13% 的 Presto 平均查询耗时,超出最初设定的测试目标预期。之前长期存在的大数据组件不稳定的问题也得到解决。
值得注意的是,整个测试流程也很顺畅,JuiceFS 仅用数天就完成了测试环境的基础功能和性能验证,很快进入到生产环境灰度测试阶段。在生产环境中 JuiceFS 的运行也非常平稳,承受住了全量请求的压力,过程中遇到的一些问题都能很快得到修复。
未来展望
展望未来还有更多值得尝试和优化的地方:
- 进一步提升 JuiceFS 缓存数据的命中率,降低 HDFS 集群负载。
- 增大 Presto worker 本地缓存盘的空间,提升本地缓存的命中率,优化长尾问题。
- Spark 集群接入 JuiceFS,覆盖更多 ad-hoc 查询场景。
- 将 HDFS 平滑迁移至 JuiceFS,完全实现存储和计算分离,降低运维成本,提升资源利用率。
