














NAVER 是一家多元化的互联网公司,拥有韩国最大的搜索引擎并在人工智能、自动驾驶等高科技领域积极投入。
在搭建 AI 平台时,NAVER 评估了公有云平台的存储产品、Alluxio 以及高性能专用存储产品等多种选项后,最终决定采用 JuiceFS。通过使用JuiceFS,NAVER 成功地将内部存储资源升级为高性能、适应 AI 工作负载的存储解决方案。
AiSuite 是 NAVER 开发者所使用的人工智能平台,它支持 NAVER 的各种服务的开发和运维。
AiSuite 提供基于 Kubernetes 的容器环境,用于高效管理成本高昂的 GPU 资源。它支持 Kubeflow,不仅便于 AI 模型的开发,还能整合模型训练和部署服务的完整 AI 工作流程。此外,AiSuite 还支持使用集成了公司内部数据平台 Kubeflow 工作流组件。
在建设 AI 平台时,最大的挑战就是提供适合 AI 工作负载的存储。随着大型语言模型(LLM)的普及,为了生成优质的 AI 模型,所需数据的规模越来越大,且分布式学习需要多个节点能够同时访问数据。此外,还应能够轻松应用像 Llama 2、MPT 等迅速出现的各种大型语言模型开源项目。 适用于 AI 平台的存储需求如下:
-
必须能够处理大规模数据;
-
为了进行重复的训练,高性能是必须的;
-
必须能作为 Kubernetes 持久卷(persistent volume)使用,即支持 Kubernetes CSI Driver;
-
为了确保能够直接使用各种开源软件和库而无需进行任何修改,存储系统应具备 POSIX 兼容性;
-
对于分布式学习和大规模服务,必须支持多个进程同时访问(参考 ReadWriteMany, ReadOnlyMany);
-
必须确保数据的一致性;
-
运维工作应当尽可能小。
寻找能够满足所有这些要求的存储解决方案并非易事。云平台如 AWS EFS 和 Google Filestore 等服务与这些要求相似。但是,这些服务与 AWS S3 或 Google Cloud Storage 等对象存储服务相比,它们的成本要高得多(标准费率下 EFS和 AWS S3 有10倍的差异)。此外,由于 AiSuite 是在 NAVER 内部部署的,因此无法使用 AWS、GCP 等外部云存储服务。我们也可以引入一些专用的存储解决方案,如 DDN EXAScaler,但这会带来高昂的成本。本文将介绍为解决这些问题所进行的探讨以及引入新存储解决方案的经验。
01 存储方案选型
我们曾考虑引入像 GlusterFS、CephFS 这样的开源解决方案,但由此会带来比较大的运维负担。
| 类型 | POSIX | RWO | ROX | RWX | 扩展性 | 缓存 | 接口 | 考虑事项 |
|---|---|---|---|---|---|---|---|---|
| HDFS | ✕ | - | - | - | ◯ | ✕ | CLI, REST | No support for K8s CSI Driver |
| nubes | △ | - | - | - | ◯ | ✕ | CLI, REST, S3, POSIX | No support for K8s CSI Driver |
| Ceph RBD | ◯ | ◯ | ✕ | ✕ | △ | ✕ | POSIX | No support for multiple clients |
| NFS | ◯ | ◯ | ◯ | ◯ | ✕ | ✕ | POSIX | Has scaling and HA issues |
| Local Path | ◯ | ◯ | ✕ | ✕ | ✕ | ✕ | POSIX | No support for data durability, tricky scheduling |
| Alluxio | △ | ◯ | ◯ | ◯ | ◯ | ◯ | POSIX | Not fully support POSIX, data inconsistency |
我们希望能够使用 NAVER 内部现有资源可支持的存储解决方案。 NAVER 内部现有的存储方案情况如下:
-
NAVER 的 C3 HDFS(Hadoop 分布式文件系统)可以处理大规模数据。但是,由于 HDFS 不支持 Kubernetes CSI Driver,因此无法将其用作 Kubernetes 的持久卷;
-
NAVER 的对象存储 nubes 也可以处理大规模数据,并支持 CLI、REST、S3、POSIX 等多种接口。但是,由于对象存储的特性,它并不完全支持 POSIX API。此外,由于不支持 Kubernetes -- CSI Driver,因此也不能将其用作 Kubernetes 的持久卷;
-
Ceph RBD 不支持 ReadWriteMany, ReadOnlyMany,因此无法在多个 Pod 中同时访问;
-
NFS 可以简单设置,但存在扩展性和高可用性(HA)的问题;
-
Local Path 将数据存储在 Kubernetes 节点的磁盘上。尽管访问速度快,但不支持多用户同时访问。此外,由于存储的数据位于各个节点上,因此需要进行特定的调度或在应用程序级别实现相关功能。
初步方案:引入 Alluxio
为了在 AiSuite 中快速且轻松地使用在 Hadoop 集群中处理并存储在 HDFS 上的数据,我们引入了 Alluxio。但 Alluxio 在我们的场景中存在以下问题:
不完全的 POSIX 兼容性
虽然可以将 Alluxio 用作 Kubernetes 持久卷,但它不支持某些 POSIX API,例如符号链接、截断、fallocate、追加、xattr 等。例如,在挂载 Alluxio 的路径 /data 后,追加操作将失败,如下所示:
$ cd /data/
$ echo "appended" >> myfile.txt
bash: echo: write error: File exists
许多 AI 开源软件和库默认实现为假设数据位于本地文件系统上。如果不支持某些 POSIX API,可能无法正常工作。因此,在使用 Alluxio 的情况下,有时需要将数据复制到 ephemeral storage 后再使用。这样做会导致 AI 开发变得不便和低效。
数据不一致
Alluxio 更类似于现有存储系统上的一个缓存层,并非一个独立的存储解决方案。当底层存储采用 HDFS 时,直接对 HDFS 进行更改而没有经过 Alluxio,可能会引起 Alluxio 与HDFS 数据的不同步。
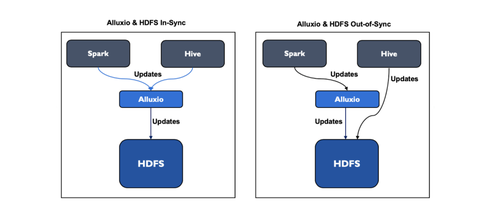
在 Alluxio 中,可以设置与原始存储数据同步的时间间隔。更多详细信息,请参考 UFS Metadata Sync。但是,如果同步过于频繁,会对原始存储产生过多的元数据请求。AiSuite 运行了一个以 HDFS 作为原始存储的 Alluxio 实例,以便与基于 Hadoop 的数据平台进行交互。但是,频繁同步导致管理 HDFS 元数据的 NameNode 负载增加。
运维压力
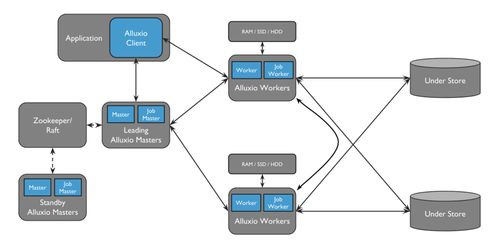
Alluxio 需要运行一个由 master 和 worker 服务器组成的单独集群,这也带来了一定的运维压力。不仅如此,由于 AiSuite 的所有用户都共享这个系统,一旦出现问题,可能会影响到所有用户。
为什么选择使用 JuiceFS
JuiceFS 是一种分布式文件系统,采用“数据”与“元数据”分离存储的架构,文件数据本身会被切分保存在对象存储(例如 Amazon S3),而元数据则可以保存在 Redis、MySQL、TiKV、SQLite 等多种数据库中,这使得企业能够利用现有存储和数据库。
接下来,我会详细介绍 JuiceFS,并解释为什么选择应用 JuiceFS。
配置
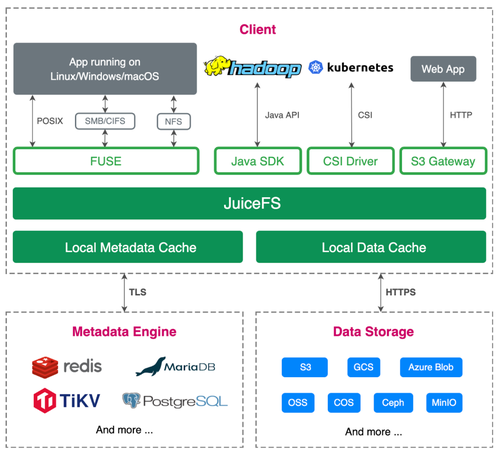
元数据引擎(Metadata Engine):负责管理文件的元数据(文件名、大小等)。可以使用多种数据库,如 Redis、TiKV、MySQL/MariaDB、PostgreSQL 等(文档:如何设置元数据)。
数据存储(Data Storage):实际存储数据的地方。可以使用多种存储,包括 S3、OpenStack Swift、Ceph、MinIO、HDFS 等(文档:如何设置对象存储);客户端(Client):与元数据引擎、数据存储进行交互,执行文件 I/O 操作。支持多种接口,适用于不同的环境;JuiceFS 的元数据和数据存储能够使用现有存储和数据库,并且可适配 Kubernetes 环境。例如,只要准备好了 S3 对象存储和 Redis,就可以通过 JuiceFS 创建一个高性能且功能丰富的存储解决方案。这也是 JuiceFS 吸引我们的原因。使用 NAVER 内部支持的存储和数据库,可以方便地搭建存储系统。
特性
JuiceFS 支持并发访问,同时支持 POSIX 和 Kubernetes 环境。满足前面提到的用于 AI 平台的存储要求,具体特性如下:
- POSIX 兼容:可像本地文件系统一样使用;
- HDFS 兼容:支持 HDFS API,可用于 Spark、Hive等数据处理框架;
- S3 兼容:通过启用 S3 网关,可以使用 S3 兼容接口进行访问;
- 云原生:支持 CSI Driver,可用于 Kubernetes 持久卷;
- 分布式:可在多个服务器上同时共享;
- 强一致性:提交的更改立即在所有服务器上生效;
- 出色性能:详细信息请参阅性能基准测试;
- 数据安全:支持数据加密;
- 文件锁定:支持 BSD 锁(flock)和 POSIX 锁(fcntl);
- 数据压缩:支持 LZ4, Zstandard,可节省存储空间。
存储原理
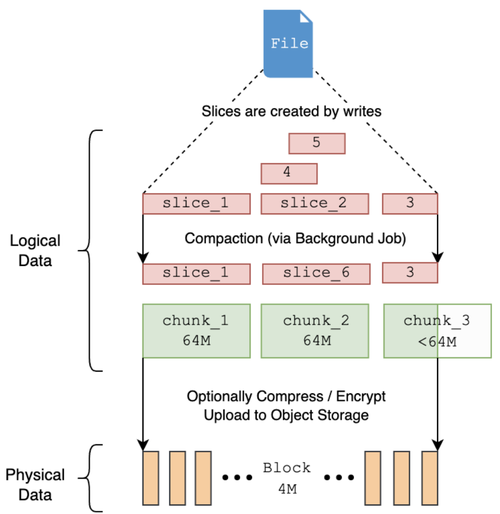
JuiceFS 引入了以下概念来处理文件,目的是为了弥补分布式存储在物理上的分散性和对象存储中对象难以修改的缺点。
-
Chunk:每个文件被划分为 64MB 大小的 Chunk 进行管理。大文件可以根据偏移量并行读取或写入,这对于处理大规模数据非常有效;
-
Slice:每个 Chunk 由一个或多个 Slice 组成。每次写入时都会创建一个新的 Slice,它们可以与同一个 Chunk 的其他 Slice 重叠。在读取 Chunk 时,会优先读取最新的 Slice。为了避免过多的 Slice 导致读取性能下降,会定期将它们合并为一个。这使得 JuiceFS 能够灵活地修改文件,解决了对象存储在数据修改方面的限制;
-
Block:在实际存储中,Slice 被划分为基础大小为 4MB(最大可达 16MB)的 Block 进行存储。Chunk 和 Slice 主要是逻辑概念,而实际存储中可见的数据单位是 Block。通过分割为较小的 Block 并进行并行处理,JuiceFS 弥补了分布式对象存储远程且较慢的特点;
元数据引擎管理着诸如文件名、文件大小等元数据。此外,它还包含了文件与实际存储数据之间的映射信息。
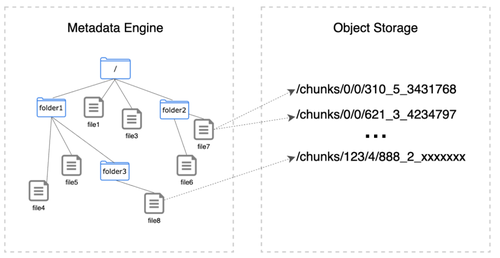
缓存
JuiceFS 为了提高性能,采用了多个层级的缓存。在读取请求时,首先尝试从内核页缓存、客户端进程缓存和本地磁盘缓存中读取数据。若这些缓存未命中,则会从远端存储中读取所需数据。从远端存储中获取的数据随后会被异步地存储在各级缓存中,以便未来能更快速地访问同样的数据。
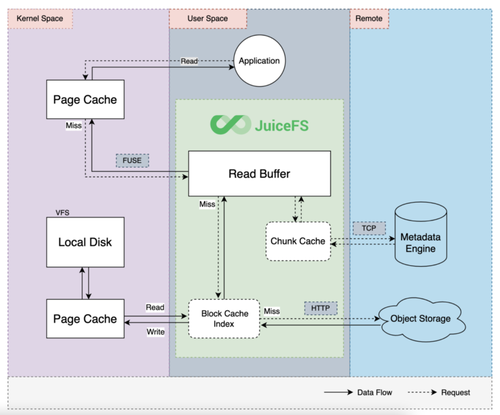
02 Alluxio vs JuiceFS
早期引入的 Alluxio 并没有满足我们所需的存储要求。那么 JuiceFS 呢?以下是对 Alluxio 和 JuiceFS 进行比较的表格。
| 功能 | Alluxio | JuiceFS |
|---|---|---|
| Storage format | Object | Block |
| Cache granularity | 64 MiB | 4 MiB |
| Multi-tier cache | ✓ | ✓ |
| Hadoop-compatible | ✓ | ✓ |
| S3-compatible | ✓ | ✓ |
| Kubernetes CSI Driver | ✓ | ✓ |
| Hadoop data locality | ✓ | ✓ |
| Fully POSIX-compatible | ✕ | ✓ |
| Atomic metadata operation | ✕ | ✓ |
| Consistency | ✕ | ✓ |
| Data compression | ✕ | ✓ |
| Data encryption | ✕ | ✓ |
| Zero-effort operation | ✕ | ✓ |
| Language | Java | Go |
| Open source license | Apache License 2.0 | Apache License 2.0 |
| Open source date | 2014 | 2021.1 |
JuiceFS 和 Alluxio 都支持多种接口,并可以通过缓存来提高性能。与 Alluxio 相比,JuiceFS 具有以下优点:
完全兼容 POSIX
Alluxio 在某些 POSIX API 上提供有限支持。而 JuiceFS 能够完全支持 POSIX 标准,因此可以像本地文件系统一样使用。这意味着,无需修改存储在 JuiceFS 中的训练数据和代码,就可以使用各种 AI 开源工具和库。下面是 POSIX 兼容性测试 pjdfstest 的结果。与AWS EFS 和 Google Filestore 相比,JuiceFS 在支持 POSIX 方面表现更佳。
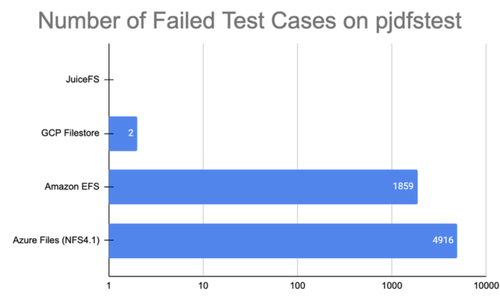
强一致性
Alluxio 更接近于对原始存储进行缓存,而 JuiceFS 是一个独立的存储系统。在 JuiceFS 中,元数据由元数据引擎管理,不依赖于外部系统。数据存储仅用于存放 Block 数据。因此,不会像 Alluxio 那样出现与原始存储不同步的问题。
减轻运维负担
Alluxio 需要运行和维护 master 和 worker 服务器,这增加了一定的运维负担。此外,因为Alluxio被所有用户共享,一旦发生故障,可能会对所有用户造成影响。JuiceFS 可以直接利用现有熟悉的存储和数据库作为元数据引擎和数据存储,仅需 JuiceFS 客户端即可运行,无需部署独立服务器。此外,每个用户都可以独立配置自己的元数据引擎和数据存储,从而避免相互干扰。
03 如何使用 JuiceFS 构建存储方案
使用 JuiceFS,需要准备一个用作元数据引擎的数据库和对象存储。如前所述,JuiceFS 支持多种数据库和对象存储。为了减轻运维负担,我们使用了 NAVER 现有的平台。
如下图所示,AiSuite 通过以下内部平台使用 JuiceFS。
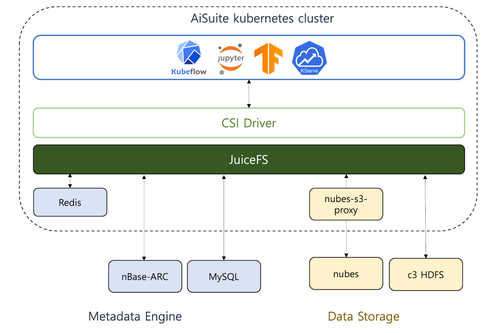
元数据引擎
在 NAVER,可以使用 nBase-ARC Redis 服务或通过 MySQL 支持来设置元数据引擎。如果是进行开发和测试,也可以通过 Helm chart 直接安装并使用 Redis、PostgreSQL 等。JuiceFS 默认每小时将元数据自动备份到数据存储中,且备份周期是可配置的。因此,即使元数据引擎的数据丢失,也可以进行恢复,但由于元数据备份周期的设定,仍有可能会有部分数据丢失。有关详细信息,请参考元数据备份和恢复。
数据存储
可以使用 NAVER 内部的 HDFS 或 nubes Object Storage 存储大规模数据。利用这些资源,可以进行大容量且稳定的数据存储。
nubes
nubes 是 NAVER 的对象存储。JuiceFS 本身不直接支持 nubes,但可以通过使用具有 MinIO 接口的 nubes-s3-proxy 来访问。
HDFS
HDFS 是 JuiceFS 默认支持的存储系统。但是,为了在大规模、多租户的 HDFS 中应用 Kerberos,需要进行以下改进:
支持 Kerberos keytab 文件
NAVER 内部的 HDFS 应用了 Kerberos。因此,当 JuiceFS 使用 HDFS 时,需要进行 Kerberos 认证。原先的 JuiceFS 是通过设置 KRB5CCNAME 环境变量为 credential cache 进行 HDFS 认证。但这个方式会在一定时间后过期失效。为解决这一问题,进行了改进,可以通过设置 KRB5KEYTAB、KRB5PRINCIPAL 环境变量使用 keytab 文件。(参见 JuiceFS issue #3283)
支持 base64 编码的 keytab 文件
AiSuite 是一个多租户 Kubernetes 集群,共享给多个用户,目标是允许每个用户使用自己选择的元数据引擎和数据存储来运行 JuiceFS。用户需要自己编写 Kubernetes Secret,设置访问元数据引擎和数据存储的路径和认证信息。但是,KRB5KEYTAB 仅是一个文件路径,并不能让用户传递实际的 keytab 文件。为解决这个问题,进行了改进,允许通过设置 KRB5KEYTAB_BASE64 环境变量使用 base64 编码的 keytab 文件字符串。(参见 JuiceFS issue #3817)
支持用户指定的 HDFS 路径
NAVER 内部的 HDFS 由多个用户共享,每个用户仅在分配给他们的 HDFS 路径上拥有权限。但是,原来的 JuiceFS 无法指定用于数据存储的 HDFS 路径,因此总是必须将数据存储在 root 目录下,这导致用户遇到了没有权限访问的路径问题。为解决这个问题,进行了改进,允许用户设置自己的 HDFS 路径。(参见 JuiceFS issue #3526)
支持 HDFS 路径 hdfs://nameservice
NAVER 内部的 HDFS 为了大规模运营,采用了 HDFS Federation,由多个 NameNode 和 Namespace 组成。原本的 JuiceFS 需要直接指定 NameNode 路径,如 nn1.example.com:8020,这对用户来说确认和设置很不方便。为了解决这个问题,进行了改进,现在可以像 hdfs://nameservice 这样设置 Namespace。(参见 JuiceFS issue #3576)
CSI Driver
AiSuite 是一个多租户 Kubernetes 集群,每个用户通过 Kubernetes namespace 进行区分。如果用户间共享 JuiceFS,可能会相互影响,降低稳定性并增加运维难度。因此,我们的目标是使每个用户都能单独准备自己的元数据引擎和数据存储,并独立使用 JuiceFS。此外,为了减轻运维负担并提高用户便利性,支持 Dynamic Volume Provisioning,使用户无需管理员介入,就能直接定义和使用 PVC(PersistentVolumeClaim)。为此,需要进行以下改进:
支持模板 Secret
用户需要创建 Secret,以设置各自准备的元数据引擎和数据存储的访问路径和认证信息。然后,需要在 StorageClass 中设置以引用这些 Secret。这些设置的 Secret 会被用于 Dynamic Volume Provisioning。但是,原有的 JuiceFS CSI Driver 只能在 StorageClass 中设置一个固定的 Secret。为解决这一问题,进行了改进,允许通过 ${pvc.name}, ${pvc.namespace}, ${pvc.annotations}等方式,从用户创建的 PVC 中引用 Secret。(参见 JuiceFS CSI Driver issue #698)
支持 Secret Finalizer
用户的 Secret 不仅在创建 PVC 时使用,还在删除 PVC 时用于删除 JuiceFS 数据。如果在删除 PVC 之前关联的 Secret 被移除,JuiceFS 数据将不会被清理,而会持续留存。为了防止这个问题,在 PVC 被删除之前,设置 Finalizer 以防止关联的 Secret 被移除。在 StorageClass 的 parameters 中设置 secretFinalizer: "true" 可以启用此功能。(参见 JuiceFS CSI Driver issue #707)
支持根据 PVC 元数据设置 mountOptions
AiSuite 中存在多种 AI 工作负载,如 AI 学习、服务和数据处理等。为了实现最优性能,根据工作类型可能需要单独配置 JuiceFS。例如,在使用只读数据进行 AI 训练的情况下,可以通过添加 --open-cache 设置来提高读取性能。有关详细信息,请参考客户端内存中的元数据缓存。原先的 JuiceFS 只能应用 StorageClass 中固定的配置。现在进行了改进,允许根据用户创建的 PVC 进行设置,例如使用 ${.PVC.namespace}, ${.PVC.name}, ${.PVC.labels.foo}, ${.PVC.annotations.bar} 这样的方法。(参见 JuiceFS CSI Driver issue)
04 JuiceFS 应用方案
为了在 Kubernetes 中支持 JuiceFS,管理员需要部署 JuiceFS CSI Driver,而用户则需要定义自己的 Secret 和 PVC。在多租户 Kubernetes 环境 AiSuite 中,将详细说明如何部署和提供 JuiceFS,包括具体的示例。
部署方法
安装 JuiceFS CSI Driver 后,可以按照标准 Kubernetes 卷的使用方式进行操作,支持通过 Helm 或 kubectl 进行安装。有关详细信息,请参考 JuiceFS CSI Driver 安装指南。进行部署需要 Kubernetes 管理员权限。为了让每个用户使用自己的元数据引擎和数据存储,StorageClass 设置如下。
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: juicefs
provisioner: csi.juicefs.com
parameters:
#配置系统以便用户可以引用自己创建的 Secret
#用户需要在 PVC 'csi.juicefs.com/secret-name'注释中设置Secret的名称
csi.storage.k8s.io/provisioner-secret-name: ${pvc.annotations['csi.juicefs.com/secret-name']}
csi.storage.k8s.io/provisioner-secret-namespace: ${pvc.namespace}
csi.storage.k8s.io/node-publish-secret-name: ${pvc.annotations['csi.juicefs.com/secret-name']}
csi.storage.k8s.io/node-publish-secret-namespace: ${pvc.namespace}
csi.storage.k8s.io/controller-expand-secret-name: ${pvc.annotations['csi.juicefs.com/secret-name']}
csi.storage.k8s.io/controller-expand-secret-namespace: ${pvc.namespace}
juicefs/clean-cache: "true"
#激活 secretFinalizer,以防止用户定义的 Secret 被随意删除
secretFinalizer: "true"
#通过指定 pathPattern来设置路径,可以挂载所需的路径
#用户可以在 PVC 'csi.juicefs.com/subdir'注释中设置所需的路径
pathPattern: "${.PVC.annotations.csi.juicefs.com/subdir}"
allowVolumeExpansion: true
reclaimPolicy: Delete
mountOptions:
#允许用户根据需要设置各自的选项
#用户可以在PVC的'csi.juicefs.com/additional-mount-options'注释中设置所需的JuiceFS选项。
- ${.PVC.annotations.csi.juicefs.com/additional-mount-options}
使用方法
用户需要为自己准备的元数据引擎和数据存储创建 Secret,包括路径和认证信息等。
apiVersion: v1
kind: Secret
metadata:
name: myjfs
type: Opaque
stringData:
#JuiceFS文件系统名称。
name: myjfs
#MINIO_ROOT_USER
access-key: user
#MINIO_ROOT_PASSWORD
secret-key: password
#元数据引擎 Redis 路径
metaurl: redis://:@redis.user1.svc.cluster.local:6379/0
#minio
storage: minio
#bucket1
bucket: http://nubes-s3-proxy.user1.svc.cluster.local:10000/bucket1
#https://juicefs.com/docs/community/command_reference/#format
format-options: trash-days=0,block-size=16384
定义 PVC。此外,需要设置以下注释(annotation):
-
csi.juicefs.com/secret-name:指定引用的 Secret 名称; -
csi.juicefs.com/subdir:如果是新的卷,则指定 PVC 名称。如果需要挂载已存在的 JuiceFS 路径,则可以指定所需的路径; -
csi.juicefs.com/additional-mount-options:可以添加适合工作负载的 JuiceFS 挂载选项。有关详细信息,请参考挂载指南。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: myjfs
annotations:
csi.juicefs.com/secret-name: myjfs # 之前创建的Secret名称
csi.juicefs.com/subdir: myjfs # 在JuiceFS文件系统中的路径
csi.juicefs.com/additional-mount-options: "writeback,upload-delay=1m" # 如果需要,可以添加JuiceFS的配置
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 100Gi
storageClassName: juicefs
创建 Secret 和 PVC 后,可以像使用普通卷一样使用它们。下面是一个将之前创建的 myjfs PVC 挂载到 /data 上的 Pod 示例。
apiVersion: v1
kind: Pod
metadata:
name: example
spec:
containers:
- name: app
...
volumeMounts:
- mountPath: /data
name: juicefs-pv
volumes:
- name: juicefs-pv
persistentVolumeClaim:
claimName: myjfs
05 性能测试
JuiceFS 性能基准测试如下所示,与 EFS, S3FS 相比,其性能更高。
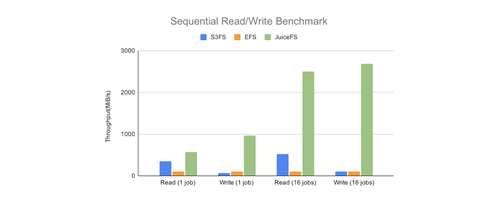
我们需要验证当使用 nubes 对象存储和 HDFS 作为数据存储时的性能表现。由于 JuiceFS 的性能可能会根据所使用的数据存储类型而有所差异,我们还需关注由于使用 UserSpace 中的 Fuse 而可能出现的性能降低。特别是需要检验因 JuiceFS Fuse 引起的性能下降情况。测试的主要目的是确定,相比直接使用数据存储,JuiceFS 是否会导致性能下降。如果性能差异不显著,那么我们可以在保持性能的同时支持 POSIX 兼容性、并发访问等多项功能。
顺序读写
参考 Fio Standalone Performance Test,按照以下方式进行了测试:
-
元数据引擎使用 Redis;
-
在单个节点上使用 fio 进行测试时,调整
--numjobs选项; -
单节点的最大网络带宽为 1200MB/s,即此测试的可能最高值;
-
由于 Object Storage 基本上不支持 POSIX,因此没有使用 fio,而是采用了针对 nubes Object Storage 性能优化的其他方法,仅测量 read(1 job), write(1 job) 项目;
-
JuiceFS 设置中,块大小设置为 16MB,其他选项使用默认值;
-
没有使用 JuiceFS 缓存,仅进行了读写新数据的测试;
-
对于 Alluxio,由于在执行 fio 时出现“fio: posix_fallocate fails: Not supported”等错误而导致失败,因此在测试中被排除了。
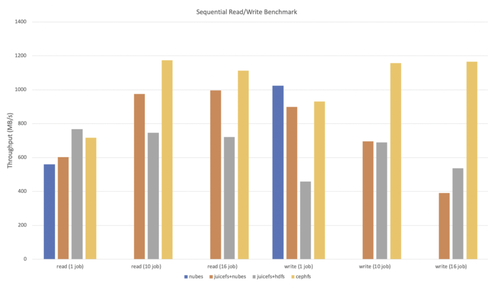
测试结果如下:
-
在读取方面,与单独的 nubes 相比,JuiceFS+nubes 和 JuiceFS+hdfs 的性能更好,并且随着并发数量的增加而提升。这可能是因为通过 Chunk 进行的并发读取更为有利;
-
在写入方面,与单独的 nubes 相比,JuiceFS+nubes 和 JuiceFS+hdfs 的性能相似或略低。并发数量增加时,性能会降低。这可能是由于多个 Slice 带来的负担所致。
文件创建
此次测试比较了创建 1 万个小文件所需的时间。测量使用 nubes 作为数据存储时处理元数据的性能,并与 JuiceFS 进行比较。
-
元数据引擎使用 Redis;
-
测量了在 10 个进程中使用 cp 命令复制 100 字节文件 1 万个时的每秒文件创建数;
-
由于 Object Storage 基本上不支持 POSIX,因此没有使用 cp,而是采用了针对 nubes Object Storage 性能优化的其他方法来测量 nubes 项;
-
也测量了设置了 JuiceFS 的 writeback 选项的情况。此选项首先在本地进行数据更新,然后异步保存到数据存储。更多详细信息,请参考 client-write-cache。
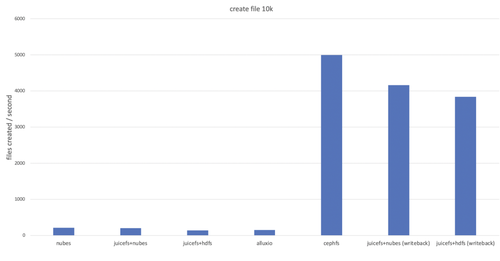
测试结果如下:
-
nubes 和 juicefs+nubes 之间没有显著差异。这意味着使用 nubes 作为数据存储的 JuiceFS 不会导致性能下降;
-
与 HDFS 配合使用时, JuiceFS+hdfs 和 alluxio 似乎与 HDFS 的元数据处理性能,即 NameNode 的性能趋于一致;
-
使用 writeback 选项可实现数十倍的性能提升。然而,启用 writeback 选项可能导致数据丢失,因此适用于临时数据的场景。
测试结论
JuiceFS 的性能基本上取决于存储数据设备的性能。它能够支持 POSIX 兼容性且无性能损失、还能支持并发访问等功能。
在某些工作负载和使用情况下,JuiceFS 的性能有时甚至可能优于数据存储设备的原始性能。尽管本文未进行测试,但读取缓存数据时,因为是从本地磁盘读取,因此有可能提高性能。写入临时数据时,应用 writeback 选项也可以提升性能。
JuiceFS 支持多种可根据工作负载进行调整的缓存选项。更多详细信息,请参考 cache。
06 小结
企业内部存储 + JuiceFS
在 AiSuite 中,我们利用公司内部支持的 HDFS 和 nubes 对象存储来构建 JuiceFS。这样既能为 AI 工作负载提供适合的存储,又能减轻运维负担。对于前文中评估的企业内部存储,可以总结如下:
| 类型 | POSIX | RWO | ROX | RWX | 扩展性 | 缓存 | 接口 | 考虑事项 |
| HDFS | X | - | - | - | O | X | CLI, REST | Kubernetes CSI Driver 不支持 |
| nubes | △ | - | - | - | O | X | CLI, REST, S3, POSIX | Kubernetes CSI Driver 不支持 |
| Ceph RBD | O | O | X | X | △ | X | POSIX | 不支持并发访问 |
| NFS | O | O | O | O | X | X | POSIX | 扩展性, HA 问题 |
| Local Path | O | O | X | X | X | X | POSIX | 不支持数据持久性,调度复杂 |
| Alluxio | △ | O | O | O | O | O | POSIX | 无法保障数据一致性 |
| JuiceFS+nubes | O | O | O | O | O | O | POSIX | nubes 高负载 |
| JuiceFS+hdfs | O | O | O | O | O | O | POSIX | HDFS 文件数限制, 配额(块大小16 MB) |
在 AiSuite 中,相比于 HDFS,更推荐使用 nubes Object Storage 用作数据存储。这是因为在 HDFS 中,如果文件数量众多,会对管理 HDFS 元数据的 NameNode 造成负担。而 JuiceFS 会将文件分割成小的 Block 来存储,从而在 HDFS 中产生大量文件。即使是最大可设置的 Block 大小 16MB,为了存储 1TB 数据,也需要创建超过 62,500 个文件。虽然考虑过将最大 Block 大小提升至 64MB,但 Block 变大可能会导致效率低下。更多详细信息,请参考 Increase the maximum of blockSize to 64MB。
优势
在 AI 平台 AiSuite 中,我们评估了 JuiceFS 作为 AI 工作负载的存储解决方案的可行性。JuiceFS 具有以下多种优势:
-
可以使用大容量、可共享(ReadWriteMany, ReadOnlyMany)卷;
-
高性能(缓存),可以替代 hostPath、local-path。可以轻松实现有状态应用的云原生转换;
-
在 AI 分布式学习中,可以作为共享的工作区、checkpoint、日志存储;
-
能够处理 AI 学习过程中所需的大量小文件(HDFS/Alluxio 的替代品);
-
可利用企业内部的 HDFS、nubes Object Storage 存储,降低运维负担;
-
通过用户各自的数据存储和元数据引擎运行,互不影响;
-
支持多种数据存储和元数据引擎,适用于大多数 k8s 环境;
-
可以替代高成本的共享存储,如 AWS EFS、Google filestore、DDN exascaler。
通过使用 JuiceFS,能够将企业内部传统的存储转换为具有高性能和多功能的、适合 AI 工作负载的存储。JuiceFS 支持多种存储和多种数据库。这篇文章主要介绍了在 NAVER 内部的 on-premise 环境中的应用案例,但它也可以应用于 AWS、Google Cloud 等公共云环境。希望这篇文章能对面临类似问题的用户提供帮助。
原文链接:https://d2.naver.com/helloworld/4555524
