









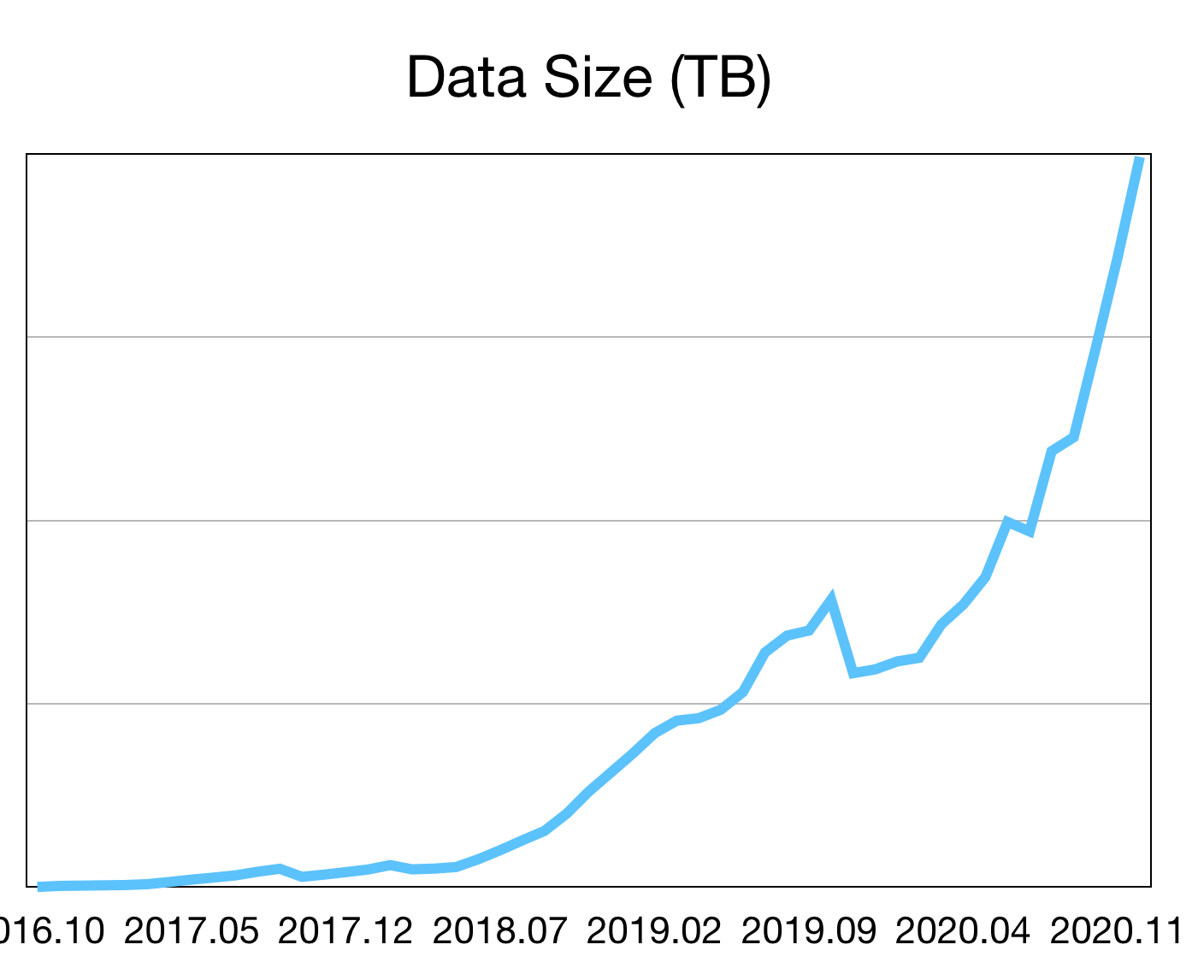
Today, we’re excited to announce the launch of the JuiceFS open source! JuiceFS has been developed over four years and tested a cumulative ten million hours in production environment.
What’s JuiceFS?
JuiceFS is a distributed file system for massive data which uses object storage for data persistence, avoiding reinventing the wheel and greatly reducing engineering complexity. Allow us to focus on solving the problems of metadata and access protocol.
The innovative architecture of JuiceFS is more in line with cloud native trends. We started it as a SaaS service to our public cloud customers, allowing them to access petabyte-level enterprise file storage services in minutes. We also work with industry leading object storage vendors to serve private cloud customers.
Why open source?
At the beginning of the business, we thought that SaaS would provide the best experience for our users, while allowing us to iterate the product faster and decide to prioritize SaaS. After four years of continuous iteration and accumulation, JuiceFS has formed best practices in the big data, AI, container platform, archiving, backup and other scenarios of dozens of technology companies. SaaS usage has also continued to grow rapidly, and break even for the first time in the past 2020. We believe we have found a sustainable development model and are confident in the long-term operation of JuiceFS.
We also found that closed source software can limit the depth of understanding it can offer, which is not conducive to serving more people. Relying on SaaS revenues and the strength of the open source community, we can get JuiceFS to help more people.
Architecture Upgrades
With the help of object storage, JuiceFS has greatly reduced the complexity of distributed file system, and metadata management is its core issue. The metadata engine used by SaaS is a database built specifically for file systems, and we have accumulated a wealth of operational experience and are still walking on thin ice. If it is open source, it would still be a big challenge and burden for the community users to operate by themselves. The consequences would be very serious if the data were lost due to maintenance errors.
With this problem in mind, we transform the metadata service into a plug-in architecture that supports multiple engines, which can use the existing open source database to implement metadata storage. In this way, it can adapt to different scenarios more flexibly, and choose different metadata implementations according to the size, performance and cost requirements of the scenario. This is an upgrade of the JuiceFS’s architecture, opening a new chapter for future development.
We chose Redis as the first open source metadata engine because:
- It is full memory, which can meet the low latency and high IOPS requirements of metadata operations;
- Support optimistic transactions, can meet the atomicity requirements of file system metadata operations;
- Rich data structure, easy to implement many APIs of the file system;
- With a very broad community and mature ecology, the operation and maintenance of Redis will not be a problem;
- There are managed services on each public cloud, it will be easier to use on the cloud.
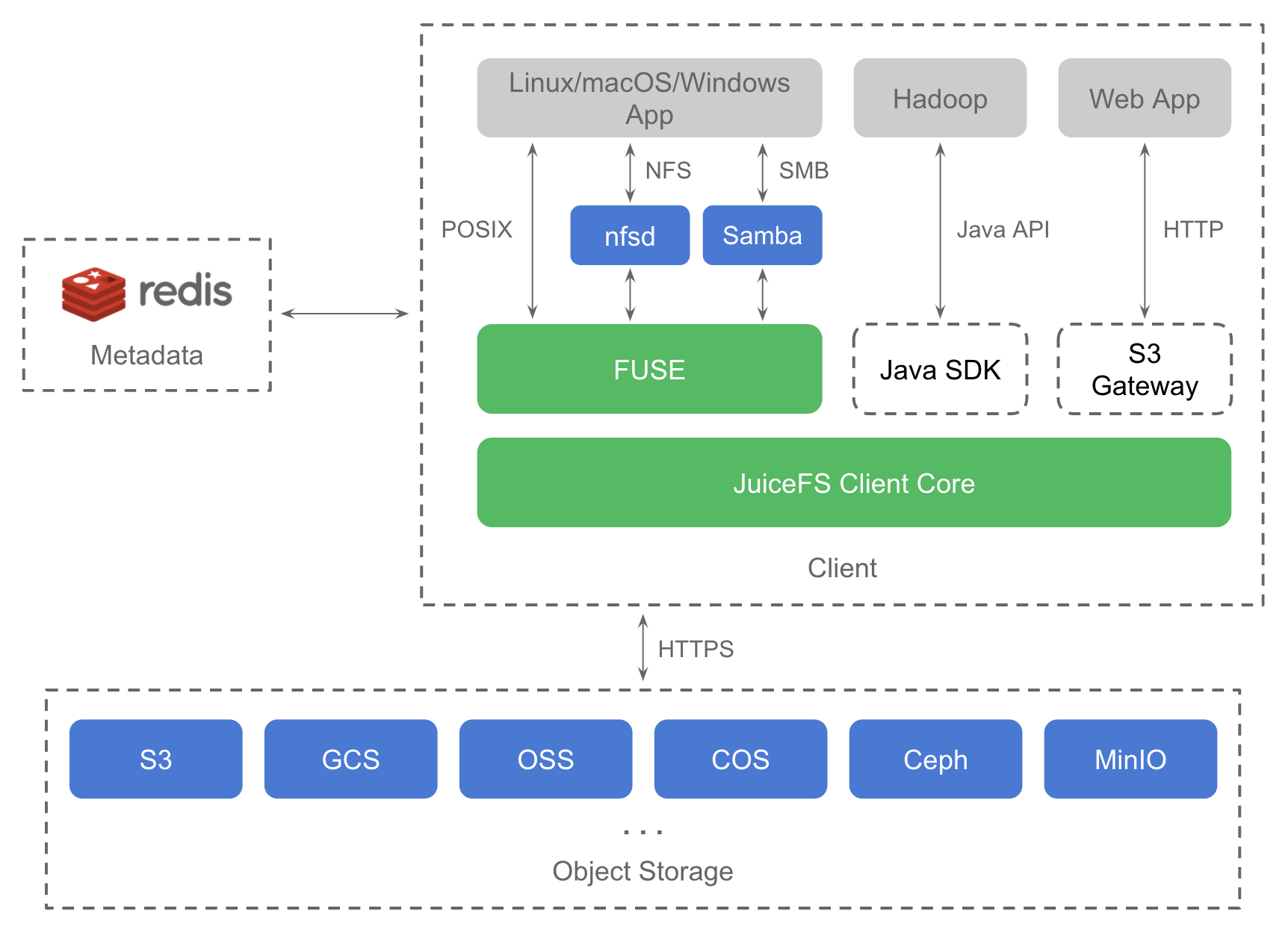
In the future, we will also add support for SQL database and KV database that support transactions such as TiKV.
Future Development
One of the interesting things that has happened in the database domain in recent years is that as the NoSQL database satisfies the rapid growth of data, its shortcomings in consistency, accessibility, and management capabilities have gradually emerged, and these complexities have been transferred to business systems. The operation and maintenance began to be criticized. At the same time, SQL database has also made great progress, has been able to meet the current data scale needs. After a comprehensive comparison and analysis, we are returning to SQL database. The previous NoSQL movement is also gradually showing decline.
It is estimated that similar things will happen in the field of unstructured data. Object storage in media files and other scenarios has achieved great success, but when people thought it is the future storage form and begin to expand it to wider range, it sacrifices tree directory structure, modifiability, metadata performance, consistency, and so on to become a roadblock, affecting its use in other scenarios.
We firmly believe that the file system is the best way to manage unstructured data, and that object storage is only appropriate for some simple scenarios. Distributed file system has always been a difficult bone in foundation software. JuiceFS has greatly reduced system complexity by making independent abstractions of metadata and data in the file system, enabling the file system to take advantage of the progress of object storage and distributed databases over the years, to manage massive scale data. At the same time, the reduction in complexity will allow more developers to participate, and more applications will also be built on the file system interface in the future.
Through the collaboration of the open source community, we will not only provide better storage support for various applications, but also deepen collaboration on the underlying storage engine and object storage to promote the rapid development of file storage, building a solid foundation for the future data ecology.
See you at GitHub: https://github.com/juicedata/juicefs


