















Li Auto is a leading Chinese NEV manufacturer that designs, develops, manufactures, and sells premium smart NEVs. And it debuted on the Nasdaq in 2020. The company started volume production of its first model Li One in November 2019. The model is a six-seater, large, premium plug-in electric SUV equipped with a range extension system and advanced smart vehicle solutions. It sold over 90,000 EVs in 2021, accounting for about 2.7% of China's passenger new energy vehicle market.
Li Auto's big data platform is built based on the Hadoop stack. With the maturity of cloud computing, Li Auto is gradually migrating its big data platform from Hadoop to cloud-native stack.
Problems with HDFS
First: the coupled design of HDFS storage and computing is poorly scalable and not suitable for cloud environments. Hadoop tends to encourage companies to build their own data centers, while various cloud service providers are shipping their own EMR systems,which are usually built on top of Hadoop. These EMR systems have been phasing out Hadoop over the last year or two.
Second: Object storage is not well adapted to the HDFS API, and the performance is much worse than the local disk due to network and other reasons, and the metadata operations such as ls are also very slow.
Third: In HDFS, when the NameNode is under pressure or Full GC, there will be read failures. Our solution is to add as much memory as possible, but it is difficult to completely solve the problem of HDFS in this case, because it is written in Java and there is no way to completely avoid the GC problem.
Fourth, HDFS does not have a disaster recovery strategy. At present, we use a large number of physical machines to deploy HDFS.
From HDFS to JuiceFS
Based on these problems, we researched some storage products and learned about JuiceFS, a distributed file system based on object storage, which can be well adapted to object storage.
On the issue of disaster recovery, object storage is usually deployed across regions. There will be at least three copies within one region. The cloud vendor helped us to do the backup.
In terms of performance, from the test results of JuiceFS, it is basically comparable to local disk with cache. Thus we quickly switch the current data on HDFS to JuiceFS directly. We used DistCp to start the synchronization, and it was very easy to synchronize the data with JuiceFS Hadoop SDK, and the overall migration was smooth.
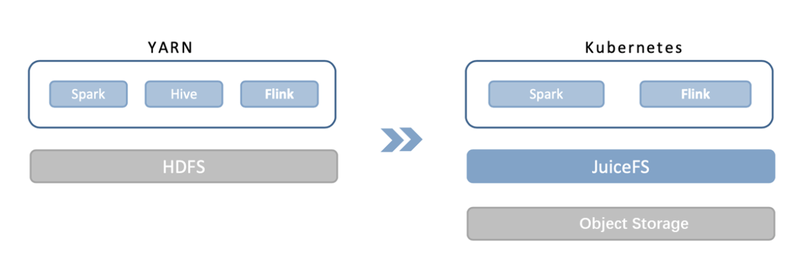
After the migration, the platform-level file sharing was achieved. All the shared files of our current scheduling system, real-time system and development platform were used to be stored on HDFS, The current solution is to use JuiceFS to connect to the object storage, and mount them all in POSIX way through the application layer service, so that each system can access the files in JuiceFS without modifying code.
JuiceFS provides several types of clients, and as you can see from the architecture diagram of the overall solution below, we use three of them in different scenarios
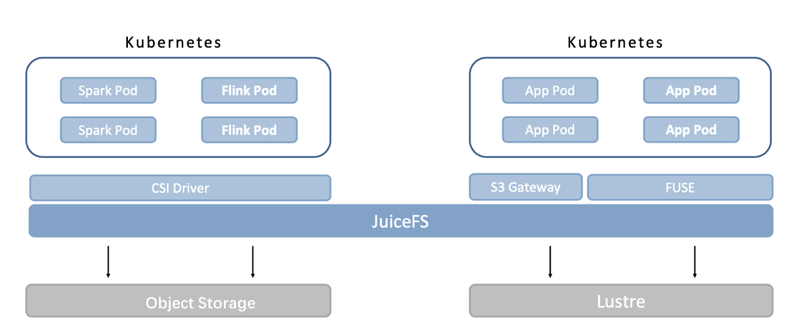
1) CSI Driver, as shown in the left half of the figure above, we have separate Spark and Flink clusters, and we mount JuiceFS directly to the whole cluster by CSI Driver, so that when users start Spark and Flink, read and write tasks are all done transparently through JuiceFS.
This scenario currently has a problem related to shuffle. Spark requires a large amount of data to be dropped during the shuffle phase , the large number of read and write requests generated during this time,which requires high performance of the underlying storage. Flink is relatively better because it is streaming and does not require a lot of disk flushes. In the future, we hope that JuiceFS can write directly to Lustre, but then we need to make some modifications in JuiceFS through integration of client. Thus the performance of read and write in the shuffle phase can be improved in a way that’s transparent to users.
2) S3 gateway, there are two scenarios in the right half of the above figure. One is a simple query of JuiceFS data, such as data preview through Hive JDBC. This scenario can be accessed through the S3 gateway to JuiceFS.
3) FUSE, the scenario of linking data platform and AI platform. For example, colleagues in AI platform need to read sample data and feature data frequently in their daily work, and these data are usually generated by Spark or Flink tasks on big data platform which have been stored in JuiceFS. In order to share data between different platforms, JuiceFS is directly mounted to the pod of AI platform through FUSE when the pod is started, so that colleagues of AI platform can directly access the data in JuiceFS for model training through Jupyter, instead of repeatedly copying data between different platforms as in traditional architecture, which improves the efficiency of cross-team collaboration.
JuiceFS uses POSIX standard users and user groups for permission control, but containers use root by default, it is not easy to control the permission. Therefore, we made a modification to JuiceFS to mount the file system with an authentication token, which contains the connection information of the metadata engine and some other permission control policies.
In some scenarios where multiple JuiceFS file systems need to be accessed at the same time, we use the JuiceFS S3 gateway and combine it with IAM policies for unified privilege management.
Innovation Scenario: JuiceFS + Lustre, Distributed Cache Acceleration
We are now using bare metal machines, and physical disks can be used to cache data. However, because computing tasks are executed on multiple nodes, the cache hit rate is not too high. The JuiceFS community edition does not support distributed caching, only local caching for a single node, where each node may read a lot of data. This situation also puts some disk pressure on the compute nodes, as the cache takes up some disk space.
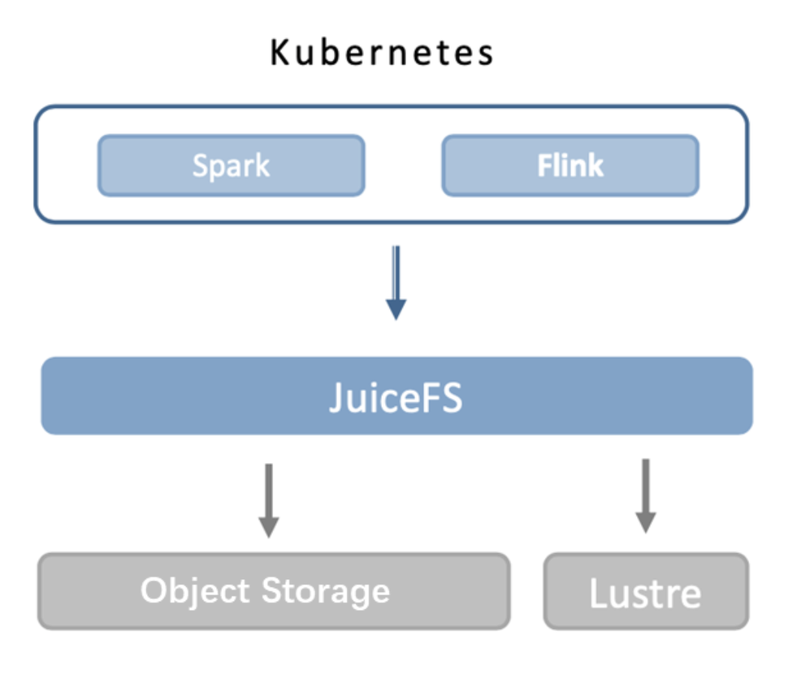
To solve this problem, we are testing a solution to use Lustre as a read cache for JuiceFS. We use Lustre's cache to help JuiceFS improve read speed and cache hit ratio. Specifically, depending on the size of the data to be cached, a Lustre file system with a capacity of about 20~30TB is mounted locally on the compute node, and then this Lustre mount point is used as the cache directory of JuiceFS. In this case, JuiceFS can asynchronously cache the data into Lustre after reading. This solution can effectively solve the problem of poor cache hit rate and significantly improve the read performance.
When we write data directly to the object storage in Spark, there are bandwidth and QPS limitations, and if the write is too slow, the upstream tasks may experience jitter. In this case you can use the write cache feature of JuiceFS to write the data to Lustre first and then asynchronously to the object storage.
However, one problem is that Lustre is not a cloud-native solution. When users start the pod, they need to write an extra command to mount it. Therefore, we also want to make some modifications to JuiceFS to automatically identify object storage and Lustre, and then automatically implement some cache mechanisms so that Lustre becomes transparent to users.
At present, the PoC of this solution has been completed and passed the basic tests, next we will do a lot of pressure testing in the production environment, and it is expected that we should be able to ship this to some online applications officially soon.