















Ariste AI is a company specializing in AI-driven trading, with businesses covering proprietary trading, asset management, high-frequency market making, and other fields. In quantitative trading research, data read speed and storage efficiency often determine the speed of research iteration.
In the process of building quantitative research infrastructure, facing market and factor data with a total scale exceeding 500 TB, we went through four stages—from local disks to eventually choosing the JuiceFS file system on top of MinIO object storage. Through caching mechanisms and a layered architecture, we achieved fast access to high-frequency data and centralized management. This practice validates the feasibility of the integrated solution of cache acceleration + elastic object storage + POSIX compatibility in quantitative scenarios. We hope our experience can provide some reference for you.
Storage challenges in quantitative investment: balancing scale, speed, and collaboration
The quantitative investment process sequentially includes the data layer, factor and signal layer, strategy and position layer, and execution and trading layer. They form a closed loop from data acquisition to trade execution.
Throughout this process, the storage system faced multiple challenges:
- Data scale and growth rate: Quantitative research requires processing a large total volume of data, covering historical market data, news data, and self-calculated factor data. Currently, the total volume of this data is close to 500 TB. Furthermore, our company adds hundreds of gigabytes of new market data daily. Using traditional disks for storage would clearly be unable to meet such massive data storage demands.
- High-frequency access and low-latency requirements: High-frequency data access relies on low-latency data reads. The data read rate directly determines research efficiency. Faster data reads allow the research process to advance rapidly; conversely, slower reads lead to inefficient research.
- Multi-team parallelism and data management: During quantitative research, multiple teams often conduct different experiments simultaneously. To ensure the independence and data security of each team's research work, secure isolation is necessary to avoid data confusion and leakage.
To address the data storage needs of the entire quantitative process and build a future-proof storage system, we wanted to achieve high performance, easy scalability, and management capability:
- High performance: Single-node read/write bandwidth should exceed 500 MB/s, and access latency should be below the local disk perception threshold.
- Easy scalability: The solution should support on-demand horizontal scaling of storage and computing resources, enabling smooth elastic scaling without application modification.
- Management capability: The solution should provide one-stop management capabilities for fine-grained permission control, operation auditing, and data lifecycle policies.
Evolution of the storage architecture
Stage 1: Local disk
In the initial phase of the project, we adopted the QuantraByte research framework. It had a built-in exchange-traded fund (ETF) module allowing data to be stored directly on local disks. This resulted in fast data read speeds. Researchers could directly run the data they needed, and the iteration process was quick.
However, this stage had some issues:
- Resource waste from repeated downloads: Multiple researchers downloading the same data led to redundant efforts.
- Insufficient storage capacity: Research servers had limited storage capacity, only about 15 TB. This could not meet growing data storage needs.
- Collaboration difficulties: The process was not convenient when needing to reuse others' research results.
Stage 2: MinIO centralized management
To solve the problems of the first stage, we introduced MinIO for centralized management. All stored data was centralized on MinIO, with a split-out module handling all data ingestion. Specific factor data was also stored in MinIO. This enabled unified downloads of public data. Permission isolation facilitated multi-team data sharing and improved storage space utilization.
However, new bottlenecks emerged in this stage:
- High latency for high-frequency random reads: High-latency I/O operations during high-frequency data access impacted data read speeds.
- Slow reads/writes due to lack of cache: Since the MinIO community edition lacked caching, reading and writing high-frequency public data was slow.
Stage 3: Introducing JuiceFS for cache acceleration
To address the above bottlenecks, after thorough research, we finally introduced JuiceFS’ cache acceleration solution. This solution involved mounting via client-side local RAID5 storage. With an efficient caching mechanism, it improved read/write performance by about three times. This significantly enhanced the access experience for high-frequency shared data.

As application data volume surpassed 300 TB, the scaling limitations of local storage became apparent. Since data was stored locally, scaling required reconfiguring storage devices. Scaling under a RAID5 architecture was slow and risky, making it difficult to meet the needs of continuous application growth.
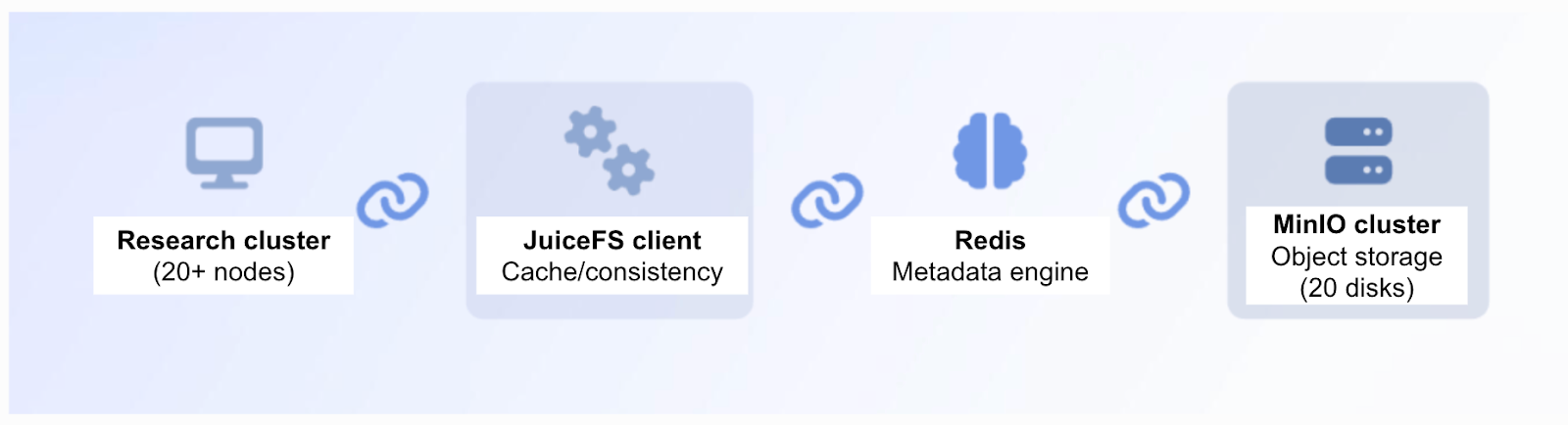
Stage 4: JuiceFS + MinIO cluster
To solve the scaling challenge, we ultimately adopted the JuiceFS + MinIO cluster architecture. This solution offers the following advantages:
- Sustained high performance: JuiceFS provides good caching capability, fully meeting the performance demands of high-frequency data access scenarios.
- Easy cluster scaling: Based on the clustered solution, we quickly achieved horizontal scaling. Simply by adding disks of the same type, we can flexibly increase storage capacity. This greatly enhances system scalability.
Through this four-stage evolution, we validated the feasibility of the integrated solution combining cache acceleration, elastic object storage, and POSIX compatibility in quantitative scenarios. This solution can provide the industry with a replicable, implementable best practice template, achieving an excellent balance between performance, cost, and management.
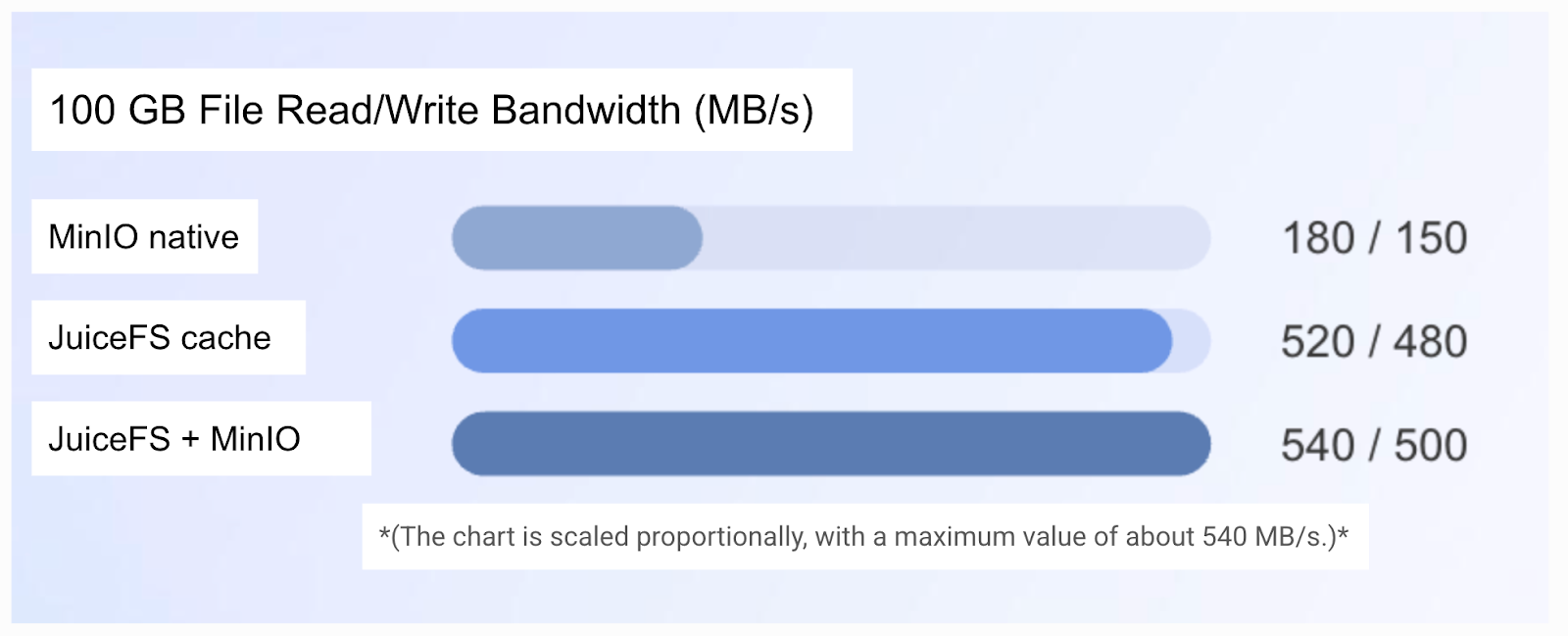
Performance and cost benefits
By adopting the combined storage architecture of JuiceFS and MinIO, our system bandwidth and resource utilization efficiency greatly improved. Now they fully meet the storage performance requirements of the research application. After introducing the JuiceFS cache layer, backtesting task execution efficiency increased dramatically. The time required for backtesting 100 million entries of tick data was reduced from hours to tens of minutes.
We implemented a tiered storage strategy for managing the data lifecycle:
- Hot data (0-90 days): This tier handles data that is accessed frequently. To ensure maximum performance, it’s automatically cached on local SSDs.
- Warm data (90-365 days): Data with medium access frequency resides here. It’s stored on MinIO's standard object storage drives, striking an optimal balance between cost and performance.
- Cold data (>365 days): This tier is for rarely accessed, archival data. It’s automatically migrated to a low-frequency access storage layer, which is compatible with the S3 Glacier strategy.
Based on this tiered storage strategy, we achieved a smooth transition from higher to lower storage unit costs. Our overall storage costs were reduced by over 40%.
Operational practices
Multi-tenant management
Regarding data isolation and permission management, we’ve established a comprehensive management system:
Logical isolation is achieved through namespaces, using path planning like /factor/A and /factor/B to ensure clear data boundaries for each application. For permission control, we implemented fine-grained management across three dimensions: user, team, and project. They seamlessly integrate with the POSIX ACL permission system.
We’ve also established a complete audit log system. It enables real-time tracking of access behaviors and historical change backtracking. This fully meets compliance requirements.
Observability and automated operations
We built a complete monitoring system around four critical metrics: cache hit rate, I/O throughput, I/O latency, and write retry rate. The system automatically triggers alerts when metrics are abnormal.
We implemented closed-loop operations management based on Grafana to continuously monitor node health and storage capacity. Before each scaling operation, we did simulated stress tests to verify system capacity and ensure no application impact. The overall operations system achieves high-standard goals of automation, predictability, and rollback capability.
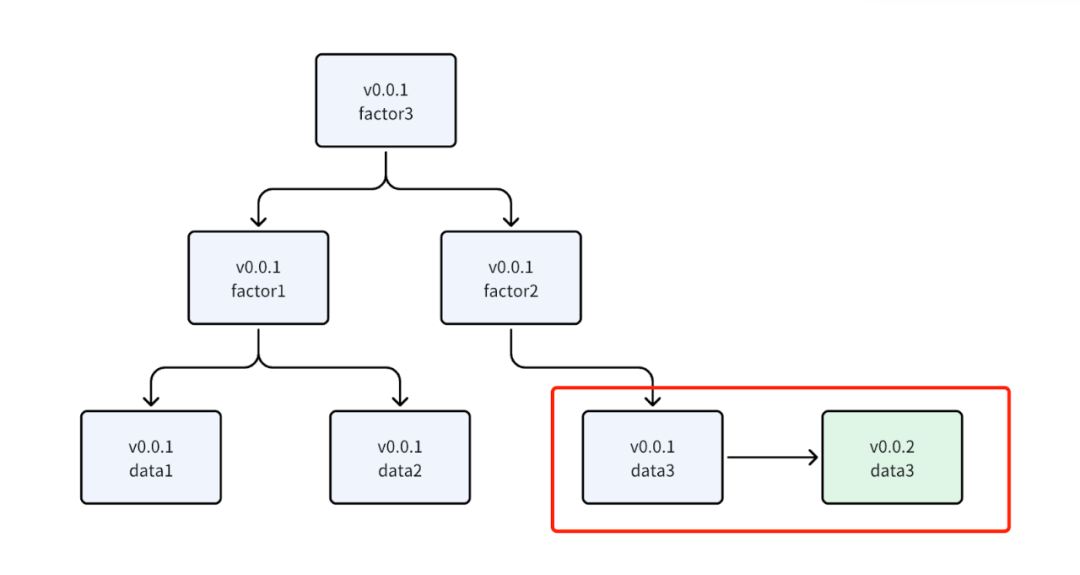
Data update design in the backtesting system
In our backtesting system design, we adopted an architecture based on directed acyclic graphs (DAGs) to improve computational efficiency and maintainability. This framework centers on computational nodes and dependency relationships, abstracting data processing, feature calculation, signal generation, and other steps into nodes, all managed uniformly through a dependency graph. The system has a built-in version control mechanism. When data versions are updated, the dependency graph automatically identifies affected nodes, precisely locating parts that need recalculation, thereby enabling efficient incremental updates and result traceability.
Plans for the future
In future planning, we’ll continue to optimize the storage architecture in the following three aspects:
- Metadata high availability upgrade: We plan to migrate metadata storage from Redis to TiKV or PostgreSQL to build a cross-data-center high-availability architecture. This can significantly improve our system disaster recovery and rapid recovery capabilities.
- Hybrid cloud tiered storage: By integrating with public cloud S3 and Glacier storage services, we aim to build an intelligent hot/cold tiering system to achieve unlimited storage elasticity while optimizing costs.
- Unified management for the research data lake: We’ll build a unified research data lake platform, integrating core services such as schema registration, automatic data cleansing, and unified catalog management. We hope to comprehensively improve the discoverability and management efficiency of data assets.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and community on Slack.