














容器存储接口(Container Storage Interface)简称 CSI,CSI 建立了行业标准接口的规范,借助 CSI 容器编排系统可以将任意存储系统暴露给自己的容器工作负载。JuiceFS CSI Driver 通过实现 CSI 接口使得 Kubernetes 上的应用可以通过 PVC(PersistentVolumeClaim)使用 JuiceFS。本文将详细介绍 CSI 的工作原理以及 JuiceFS CSI Driver 的架构设计。
CSI 的基本组件
CSI 的 cloud providers 有两种类型,一种为 in-tree 类型,一种为 out-of-tree 类型。前者是指运行在 Kubernetes 核心组件内部的存储插件;后者是指独立在 Kubernetes 组件之外运行的存储插件。本文主要介绍 out-of-tree 类型的插件。
out-of-tree 类型的插件主要是通过 gRPC 接口跟 Kubernetes 组件交互,并且 Kubernetes 提供了大量的 SideCar 组件来配合 CSI 插件实现丰富的功能。对于 out-of-tree 类型的插件来说,所用到的组件分为 SideCar 组件和第三方需要实现的插件。
SideCar 组件
external-attacher
监听 VolumeAttachment 对象,并调用 CSI driver Controller 服务的 ControllerPublishVolume 和 ControllerUnpublishVolume 接口,用来将 volume 附着到 node 上,或从 node 上删除。
如果存储系统需要 attach/detach 这一步,就需要使用到这个组件,因为 Kubernetes 内部的 Attach/Detach Controller 不会直接调用 CSI driver 的接口。
external-provisioner
监听 PVC 对象,并调用 CSI driver Controller 服务的 CreateVolume 和 DeleteVolume 接口,用来提供一个新的 volume。前提是 PVC 中指定的 StorageClass 的 provisioner 字段和 CSI driver Identity 服务的 GetPluginInfo 接口的返回值一样。一旦新的 volume 提供出来,Kubernetes 就会创建对应的 PV。
而如果 PVC 绑定的 PV 的回收策略是 delete,那么 external-provisioner 组件监听到 PVC 的删除后,会调用 CSI driver Controller 服务的 DeleteVolume 接口。一旦 volume 删除成功,该组件也会删除相应的 PV。
该组件还支持从快照创建数据源。如果在 PVC 中指定了 Snapshot CRD 的数据源,那么该组件会通过 SnapshotContent 对象获取有关快照的信息,并将此内容在调用 CreateVolume 接口的时候传给 CSI driver,CSI driver 需要根据数据源快照来创建 volume。
external-resizer
监听 PVC 对象,如果用户请求在 PVC 对象上请求更多存储,该组件会调用 CSI driver Controller 服务的 NodeExpandVolume 接口,用来对 volume 进行扩容。
external-snapshotter
该组件需要与 Snapshot Controller 配合使用。Snapshot Controller 会根据集群中创建的 Snapshot 对象创建对应的 VolumeSnapshotContent,而 external-snapshotter 负责监听 VolumeSnapshotContent 对象。当监听到 VolumeSnapshotContent 时,将其对应参数通过 CreateSnapshotRequest 传给 CSI driver Controller 服务,调用其 CreateSnapshot 接口。该组件还负责调用 DeleteSnapshot、ListSnapshots 接口。
livenessprobe
负责监测 CSI driver 的健康情况,并通过 Liveness Probe 机制汇报给 Kubernetes,当监测到 CSI driver 有异常时负责重启 pod。
node-driver-registrar
通过直接调用 CSI driver Node 服务的 NodeGetInfo 接口,将 CSI driver 的信息通过 kubelet 的插件注册机制在对应节点的 kubelet 上进行注册。
external-health-monitor-controller
通过调用 CSI driver Controller 服务的 ListVolumes 或者 ControllerGetVolume 接口,来检查 CSI volume 的健康情况,并上报在 PVC 的 event 中。
external-health-monitor-agent
通过调用 CSI driver Node 服务的 NodeGetVolumeStats 接口,来检查 CSI volume 的健康情况,并上报在 pod 的 event 中。
第三方插件
第三方存储提供方(即 SP,Storage Provider)需要实现 Controller 和 Node 两个插件,其中 Controller 负责 Volume 的管理,以 StatefulSet 形式部署;Node 负责将 Volume mount 到 pod 中,以 DaemonSet 形式部署在每个 node 中。
CSI 插件与 kubelet 以及 Kubernetes 外部组件是通过 Unix Domain Socket gRPC 来进行交互调用的。CSI 定义了三套 RPC 接口,SP 需要实现这三组接口,以便与 Kubernetes 外部组件进行通信。三组接口分别是:CSI Identity、CSI Controller 和 CSI Node,下面详细看看这些接口定义。
CSI Identity
用于提供 CSI driver 的身份信息,Controller 和 Node 都需要实现。接口如下:
service Identity {
rpc GetPluginInfo(GetPluginInfoRequest)
returns (GetPluginInfoResponse) {}
rpc GetPluginCapabilities(GetPluginCapabilitiesRequest)
returns (GetPluginCapabilitiesResponse) {}
rpc Probe (ProbeRequest)
returns (ProbeResponse) {}
}GetPluginInfo 是必须要实现的,node-driver-registrar 组件会调用这个接口将 CSI driver 注册到 kubelet;GetPluginCapabilities 是用来表明该 CSI driver 主要提供了哪些功能。
CSI Controller
用于实现创建/删除 volume、attach/detach volume、volume 快照、volume 扩缩容等功能,Controller 插件需要实现这组接口。接口如下:
service Controller {
rpc CreateVolume (CreateVolumeRequest)
returns (CreateVolumeResponse) {}
rpc DeleteVolume (DeleteVolumeRequest)
returns (DeleteVolumeResponse) {}
rpc ControllerPublishVolume (ControllerPublishVolumeRequest)
returns (ControllerPublishVolumeResponse) {}
rpc ControllerUnpublishVolume (ControllerUnpublishVolumeRequest)
returns (ControllerUnpublishVolumeResponse) {}
rpc ValidateVolumeCapabilities (ValidateVolumeCapabilitiesRequest)
returns (ValidateVolumeCapabilitiesResponse) {}
rpc ListVolumes (ListVolumesRequest)
returns (ListVolumesResponse) {}
rpc GetCapacity (GetCapacityRequest)
returns (GetCapacityResponse) {}
rpc ControllerGetCapabilities (ControllerGetCapabilitiesRequest)
returns (ControllerGetCapabilitiesResponse) {}
rpc CreateSnapshot (CreateSnapshotRequest)
returns (CreateSnapshotResponse) {}
rpc DeleteSnapshot (DeleteSnapshotRequest)
returns (DeleteSnapshotResponse) {}
rpc ListSnapshots (ListSnapshotsRequest)
returns (ListSnapshotsResponse) {}
rpc ControllerExpandVolume (ControllerExpandVolumeRequest)
returns (ControllerExpandVolumeResponse) {}
rpc ControllerGetVolume (ControllerGetVolumeRequest)
returns (ControllerGetVolumeResponse) {
option (alpha_method) = true;
}
}在上面介绍 Kubernetes 外部组件的时候已经提到,不同的接口分别提供给不同的组件调用,用于配合实现不同的功能。比如 CreateVolume/DeleteVolume 配合 external-provisioner 实现创建/删除 volume 的功能;ControllerPublishVolume/ControllerUnpublishVolume 配合 external-attacher 实现 volume 的 attach/detach 功能等。
CSI Node
用于实现 mount/umount volume、检查 volume 状态等功能,Node 插件需要实现这组接口。接口如下:
service Node {
rpc NodeStageVolume (NodeStageVolumeRequest)
returns (NodeStageVolumeResponse) {}
rpc NodeUnstageVolume (NodeUnstageVolumeRequest)
returns (NodeUnstageVolumeResponse) {}
rpc NodePublishVolume (NodePublishVolumeRequest)
returns (NodePublishVolumeResponse) {}
rpc NodeUnpublishVolume (NodeUnpublishVolumeRequest)
returns (NodeUnpublishVolumeResponse) {}
rpc NodeGetVolumeStats (NodeGetVolumeStatsRequest)
returns (NodeGetVolumeStatsResponse) {}
rpc NodeExpandVolume(NodeExpandVolumeRequest)
returns (NodeExpandVolumeResponse) {}
rpc NodeGetCapabilities (NodeGetCapabilitiesRequest)
returns (NodeGetCapabilitiesResponse) {}
rpc NodeGetInfo (NodeGetInfoRequest)
returns (NodeGetInfoResponse) {}
}NodeStageVolume 用来实现多个 pod 共享一个 volume 的功能,支持先将 volume 挂载到一个临时目录,然后通过 NodePublishVolume 将其挂载到 pod 中;NodeUnstageVolume 为其反操作。
工作流程
下面来看看 pod 挂载 volume 的整个工作流程。整个流程流程分别三个阶段:Provision/Delete、Attach/Detach、Mount/Unmount,不过不是每个存储方案都会经历这三个阶段,比如 NFS 就没有 Attach/Detach 阶段。
整个过程不仅仅涉及到上面介绍的组件的工作,还涉及 ControllerManager 的 AttachDetachController 组件和 PVController 组件以及 kubelet。下面分别详细分析一下 Provision、Attach、Mount 三个阶段。
Provision
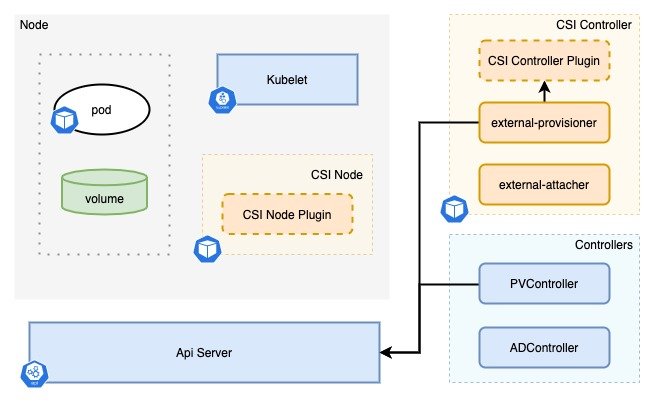
先来看 Provision 阶段,整个过程如上图所示。其中 extenal-provisioner 和 PVController 均 watch PVC 资源。
- 当 PVController watch 到集群中有 PVC 创建时,会判断当前是否有 in-tree plugin 与之相符,如果没有则判断其存储类型为 out-of-tree 类型,于是给 PVC 打上注解
volume.beta.kubernetes.io/storage-provisioner={csi driver name}; - 当 extenal-provisioner watch 到 PVC 的注解 csi driver 与自己的 csi driver 一致时,调用 CSI Controller 的
CreateVolume接口; - 当 CSI Controller 的
CreateVolume接口返回成功时,extenal-provisioner 会在集群中创建对应的 PV; - PVController watch 到集群中有 PV 创建时,将 PV 与 PVC 进行绑定。
Attach
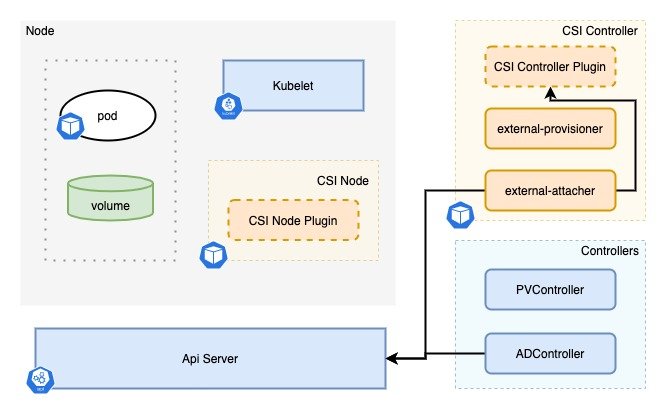
Attach 阶段是指将 volume 附着到节点上,整个过程如上图所示。
- ADController 监听到 pod 被调度到某节点,并且使用的是 CSI 类型的 PV,会调用内部的 in-tree CSI 插件的接口,该接口会在集群中创建一个 VolumeAttachment 资源;
- external-attacher 组件 watch 到有 VolumeAttachment 资源创建出来时,会调用 CSI Controller 的
ControllerPublishVolume接口; - 当 CSI Controller 的
ControllerPublishVolume接口调用成功后,external-attacher 将对应的 VolumeAttachment 对象的 Attached 状态设为 true; - ADController watch 到 VolumeAttachment 对象的 Attached 状态为 true 时,更新 ADController 内部的状态 ActualStateOfWorld。
Mount
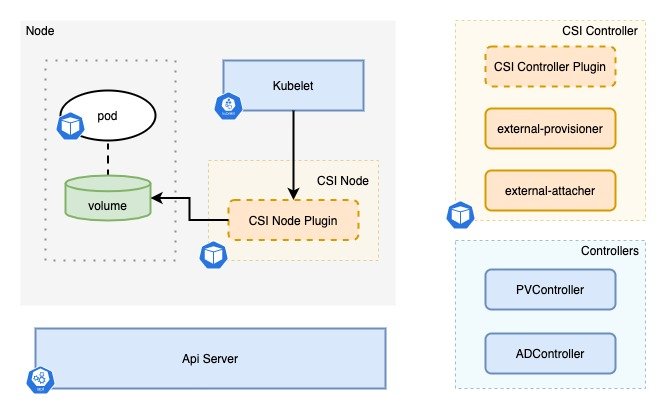
最后一步将 volume 挂载到 pod 里的过程涉及到 kubelet。整个流程简单地说是,对应节点上的 kubelet 在创建 pod 的过程中,会调用 CSI Node 插件,执行 mount 操作。下面再针对 kubelet 内部的组件细分进行分析。
首先 kubelet 创建 pod 的主函数 syncPod 中,kubelet 会调用其子组件 volumeManager 的 WaitForAttachAndMount 方法,等待 volume mount 完成:
func (kl *Kubelet) syncPod(o syncPodOptions) error {
...
// Volume manager will not mount volumes for terminated pods
if !kl.podIsTerminated(pod) {
// Wait for volumes to attach/mount
if err := kl.volumeManager.WaitForAttachAndMount(pod); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedMountVolume, "Unable to attach or mount volumes: %v", err)
klog.Errorf("Unable to attach or mount volumes for pod %q: %v; skipping pod", format.Pod(pod), err)
return err
}
}
...
}volumeManager 中包含两个组件:desiredStateOfWorldPopulator 和 reconciler。这两个组件相互配合就完成了 volume 在 pod 中的 mount 和 umount 过程。整个过程如下:
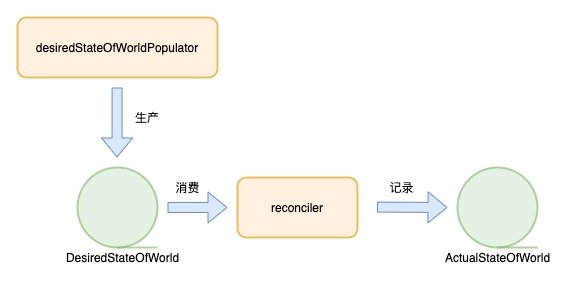
desiredStateOfWorldPopulator 和 reconciler 的协同模式是生产者和消费者的模式。volumeManager 中维护了两个队列(严格来讲是 interface,但这里充当了队列的作用),即 DesiredStateOfWorld 和 ActualStateOfWorld,前者维护的是当前节点中 volume 的期望状态;后者维护的是当前节点中 volume 的实际状态。
而 desiredStateOfWorldPopulator 在自己的循环中只做了两个事情,一个是从 kubelet 的 podManager 中获取当前节点新建的 Pod,将其需要挂载的 volume 信息记录到 DesiredStateOfWorld 中;另一件事是从 podManager 中获取当前节点中被删除的 pod,检查其 volume 是否在 ActualStateOfWorld 的记录中,如果没有,将其在 DesiredStateOfWorld 中也删除,从而保证 DesiredStateOfWorld 记录的是节点中所有 volume 的期望状态。相关代码如下(为了精简逻辑,删除了部分代码):
// Iterate through all pods and add to desired state of world if they don't
// exist but should
func (dswp *desiredStateOfWorldPopulator) findAndAddNewPods() {
// Map unique pod name to outer volume name to MountedVolume.
mountedVolumesForPod := make(map[volumetypes.UniquePodName]map[string]cache.MountedVolume)
...
processedVolumesForFSResize := sets.NewString()
for _, pod := range dswp.podManager.GetPods() {
dswp.processPodVolumes(pod, mountedVolumesForPod, processedVolumesForFSResize)
}
}
// processPodVolumes processes the volumes in the given pod and adds them to the
// desired state of the world.
func (dswp *desiredStateOfWorldPopulator) processPodVolumes(
pod *v1.Pod,
mountedVolumesForPod map[volumetypes.UniquePodName]map[string]cache.MountedVolume,
processedVolumesForFSResize sets.String) {
uniquePodName := util.GetUniquePodName(pod)
...
for _, podVolume := range pod.Spec.Volumes {
pvc, volumeSpec, volumeGidValue, err :=
dswp.createVolumeSpec(podVolume, pod, mounts, devices)
// Add volume to desired state of world
_, err = dswp.desiredStateOfWorld.AddPodToVolume(
uniquePodName, pod, volumeSpec, podVolume.Name, volumeGidValue)
dswp.actualStateOfWorld.MarkRemountRequired(uniquePodName)
}
}而 reconciler 就是消费者,它主要做了三件事:
unmountVolumes():在 ActualStateOfWorld 中遍历 volume,判断其是否在 DesiredStateOfWorld 中,如果不在,则调用 CSI Node 的接口执行 unmount,并在 ActualStateOfWorld 中记录;mountAttachVolumes():从 DesiredStateOfWorld 中获取需要被 mount 的 volume,调用 CSI Node 的接口执行 mount 或扩容,并在 ActualStateOfWorld 中做记录;unmountDetachDevices(): 在 ActualStateOfWorld 中遍历 volume,若其已经 attach,但没有使用的 pod,并在 DesiredStateOfWorld 也没有记录,则将其 unmount/detach 掉。
我们以 mountAttachVolumes() 为例,看看其如何调用 CSI Node 的接口。
func (rc *reconciler) mountAttachVolumes() {
// Ensure volumes that should be attached/mounted are attached/mounted.
for _, volumeToMount := range rc.desiredStateOfWorld.GetVolumesToMount() {
volMounted, devicePath, err := rc.actualStateOfWorld.PodExistsInVolume(volumeToMount.PodName, volumeToMount.VolumeName)
volumeToMount.DevicePath = devicePath
if cache.IsVolumeNotAttachedError(err) {
...
} else if !volMounted || cache.IsRemountRequiredError(err) {
// Volume is not mounted, or is already mounted, but requires remounting
err := rc.operationExecutor.MountVolume(
rc.waitForAttachTimeout,
volumeToMount.VolumeToMount,
rc.actualStateOfWorld,
isRemount)
...
} else if cache.IsFSResizeRequiredError(err) {
err := rc.operationExecutor.ExpandInUseVolume(
volumeToMount.VolumeToMount,
rc.actualStateOfWorld)
...
}
}
}执行 mount 的操作全在 rc.operationExecutor 中完成,再看 operationExecutor 的代码:
func (oe *operationExecutor) MountVolume(
waitForAttachTimeout time.Duration,
volumeToMount VolumeToMount,
actualStateOfWorld ActualStateOfWorldMounterUpdater,
isRemount bool) error {
...
var generatedOperations volumetypes.GeneratedOperations
generatedOperations = oe.operationGenerator.GenerateMountVolumeFunc(
waitForAttachTimeout, volumeToMount, actualStateOfWorld, isRemount)
// Avoid executing mount/map from multiple pods referencing the
// same volume in parallel
podName := nestedpendingoperations.EmptyUniquePodName
return oe.pendingOperations.Run(
volumeToMount.VolumeName, podName, "" /* nodeName */, generatedOperations)
}该函数先构造执行函数,再执行,那么再看构造函数:
func (og *operationGenerator) GenerateMountVolumeFunc(
waitForAttachTimeout time.Duration,
volumeToMount VolumeToMount,
actualStateOfWorld ActualStateOfWorldMounterUpdater,
isRemount bool) volumetypes.GeneratedOperations {
volumePlugin, err :=
og.volumePluginMgr.FindPluginBySpec(volumeToMount.VolumeSpec)
mountVolumeFunc := func() volumetypes.OperationContext {
// Get mounter plugin
volumePlugin, err := og.volumePluginMgr.FindPluginBySpec(volumeToMount.VolumeSpec)
volumeMounter, newMounterErr := volumePlugin.NewMounter(
volumeToMount.VolumeSpec,
volumeToMount.Pod,
volume.VolumeOptions{})
...
// Execute mount
mountErr := volumeMounter.SetUp(volume.MounterArgs{
FsUser: util.FsUserFrom(volumeToMount.Pod),
FsGroup: fsGroup,
DesiredSize: volumeToMount.DesiredSizeLimit,
FSGroupChangePolicy: fsGroupChangePolicy,
})
// Update actual state of world
markOpts := MarkVolumeOpts{
PodName: volumeToMount.PodName,
PodUID: volumeToMount.Pod.UID,
VolumeName: volumeToMount.VolumeName,
Mounter: volumeMounter,
OuterVolumeSpecName: volumeToMount.OuterVolumeSpecName,
VolumeGidVolume: volumeToMount.VolumeGidValue,
VolumeSpec: volumeToMount.VolumeSpec,
VolumeMountState: VolumeMounted,
}
markVolMountedErr := actualStateOfWorld.MarkVolumeAsMounted(markOpts)
...
return volumetypes.NewOperationContext(nil, nil, migrated)
}
return volumetypes.GeneratedOperations{
OperationName: "volume_mount",
OperationFunc: mountVolumeFunc,
EventRecorderFunc: eventRecorderFunc,
CompleteFunc: util.OperationCompleteHook(util.GetFullQualifiedPluginNameForVolume(volumePluginName, volumeToMount.VolumeSpec), "volume_mount"),
}
}这里先去注册到 kubelet 的 CSI 的 plugin 列表中找到对应的插件,然后再执行 volumeMounter.SetUp,最后更新 ActualStateOfWorld 的记录。这里负责执行 external CSI 插件的是 csiMountMgr,代码如下:
func (c *csiMountMgr) SetUp(mounterArgs volume.MounterArgs) error {
return c.SetUpAt(c.GetPath(), mounterArgs)
}
func (c *csiMountMgr) SetUpAt(dir string, mounterArgs volume.MounterArgs) error {
csi, err := c.csiClientGetter.Get()
...
err = csi.NodePublishVolume(
ctx,
volumeHandle,
readOnly,
deviceMountPath,
dir,
accessMode,
publishContext,
volAttribs,
nodePublishSecrets,
fsType,
mountOptions,
)
...
return nil
}可以看到,在 kubelet 中调用 CSI Node NodePublishVolume/NodeUnPublishVolume 接口的是 volumeManager 的 csiMountMgr。至此,整个 Pod 的 volume 流程就已经梳理清楚了。
JuiceFS CSI Driver 工作原理
接下来再来看看 JuiceFS CSI Driver 的工作原理。架构图如下:
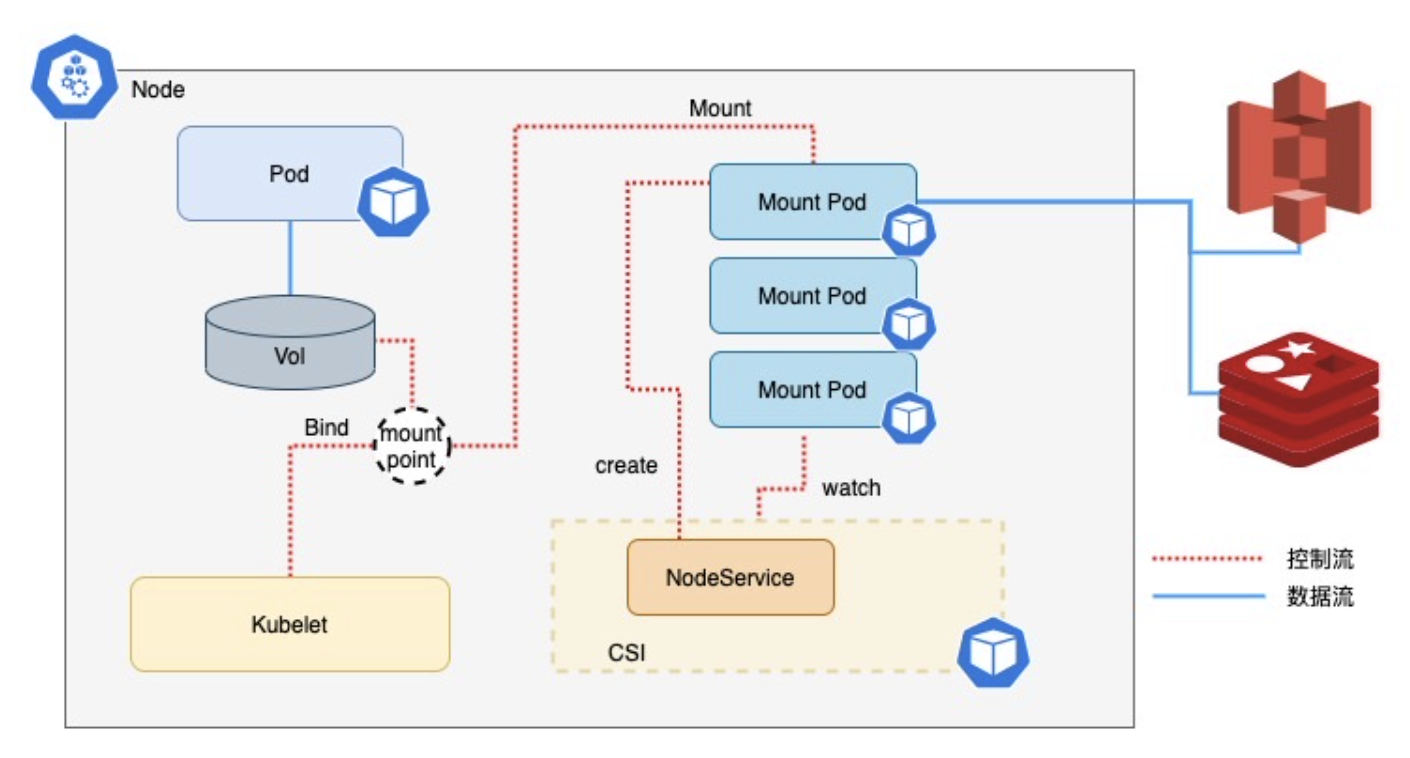
JuiceFS 在 CSI Node 接口 NodePublishVolume 中创建 pod,用来执行 juicefs mount xxx,从而保证 juicefs 客户端运行在 pod 里。如果有多个的业务 pod 共用一份存储,mount pod 会在 annotation 进行引用计数,确保不会重复创建。具体的代码如下(为了方便阅读,省去了日志等无关代码):
func (p *PodMount) JMount(jfsSetting *jfsConfig.JfsSetting) error {
if err := p.createOrAddRef(jfsSetting); err != nil {
return err
}
return p.waitUtilPodReady(GenerateNameByVolumeId(jfsSetting.VolumeId))
}
func (p *PodMount) createOrAddRef(jfsSetting *jfsConfig.JfsSetting) error {
...
for i := 0; i < 120; i++ {
// wait for old pod deleted
oldPod, err := p.K8sClient.GetPod(podName, jfsConfig.Namespace)
if err == nil && oldPod.DeletionTimestamp != nil {
time.Sleep(time.Millisecond * 500)
continue
} else if err != nil {
if K8serrors.IsNotFound(err) {
newPod := r.NewMountPod(podName)
if newPod.Annotations == nil {
newPod.Annotations = make(map[string]string)
}
newPod.Annotations[key] = jfsSetting.TargetPath
po, err := p.K8sClient.CreatePod(newPod)
...
return err
}
return err
}
...
return p.AddRefOfMount(jfsSetting.TargetPath, podName)
}
return status.Errorf(codes.Internal, "Mount %v failed: mount pod %s has been deleting for 1 min", jfsSetting.VolumeId, podName)
}
func (p *PodMount) waitUtilPodReady(podName string) error {
// Wait until the mount pod is ready
for i := 0; i < 60; i++ {
pod, err := p.K8sClient.GetPod(podName, jfsConfig.Namespace)
...
if util.IsPodReady(pod) {
return nil
}
time.Sleep(time.Millisecond * 500)
}
...
return status.Errorf(codes.Internal, "waitUtilPodReady: mount pod %s isn't ready in 30 seconds: %v", podName, log)
}每当有业务 pod 退出时,CSI Node 会在接口 NodeUnpublishVolume 删除 mount pod annotation 中对应的计数,当最后一个记录被删除时,mount pod 才会被删除。具体代码如下(为了方便阅读,省去了日志等无关代码):
func (p *PodMount) JUmount(volumeId, target string) error {
...
err = retry.RetryOnConflict(retry.DefaultBackoff, func() error {
po, err := p.K8sClient.GetPod(pod.Name, pod.Namespace)
if err != nil {
return err
}
annotation := po.Annotations
...
delete(annotation, key)
po.Annotations = annotation
return p.K8sClient.UpdatePod(po)
})
...
deleteMountPod := func(podName, namespace string) error {
return retry.RetryOnConflict(retry.DefaultBackoff, func() error {
po, err := p.K8sClient.GetPod(podName, namespace)
...
shouldDelay, err = util.ShouldDelay(po, p.K8sClient)
if err != nil {
return err
}
if !shouldDelay {
// do not set delay delete, delete it now
if err := p.K8sClient.DeletePod(po); err != nil {
return err
}
}
return nil
})
}
newPod, err := p.K8sClient.GetPod(pod.Name, pod.Namespace)
...
if HasRef(newPod) {
return nil
}
return deleteMountPod(pod.Name, pod.Namespace)
}CSI Driver 与 juicefs 客户端解耦,做升级不会影响到业务容器;将客户端独立在 pod 中运行也就使其在 Kubernetes 的管控内,可观测性更强;同时 pod 的好处我们也能享受到,比如隔离性更强,可以单独设置客户端的资源配额等。
总结
本文从 CSI 的组件、CSI 接口、volume 如何挂载到 pod 上,三个方面入手,分析了 CSI 整个体系工作的过程,并介绍了 JuiceFS CSI Driver 的工作原理。CSI 是整个容器生态的标准存储接口,CO 通过 gRPC 方式和 CSI 插件通信,而为了做到普适,Kubernetes 设计了很多外部组件来配合 CSI 插件来实现不同的功能,从而保证了 Kubernetes 内部逻辑的纯粹以及 CSI 插件的简单易用。
