














在 AI 训练、数据集管理等大规模文件访问场景中,随着文件数量和访问并发增加,元数据层往往更早成为性能瓶颈。无论是删除百万级小文件、克隆大规模数据集,还是高并发目录遍历,元数据引擎的响应能力都会直接影响上层业务效率。
JuiceFS 社区版 1.4 在元数据引擎层面引入了三项优化:批量删除(Batch Unlink)、批量克隆(Batch Clone)和 Redis 客户端缓存(Client-Side Caching),分别面向大规模删除、元数据克隆和热点元数据读取场景,减少事务提交、网络交互和重复查询开销。在 100,000 个文件的 flat 目录测试中,批量删除最高提升 93 倍,批量克隆最高提升 24 倍。本文将从问题背景、设计思路和性能收益三个方面介绍这些优化。
01 删除:从逐个回收到批量事务
在 JuiceFS 的元数据与数据分离架构下,删除文件不仅移除目录项,还需要更新 inode 引用计数、回收空间和 inode、处理回收站、调整配额等多项元数据操作,这些操作通常必须在同一个事务中完成。
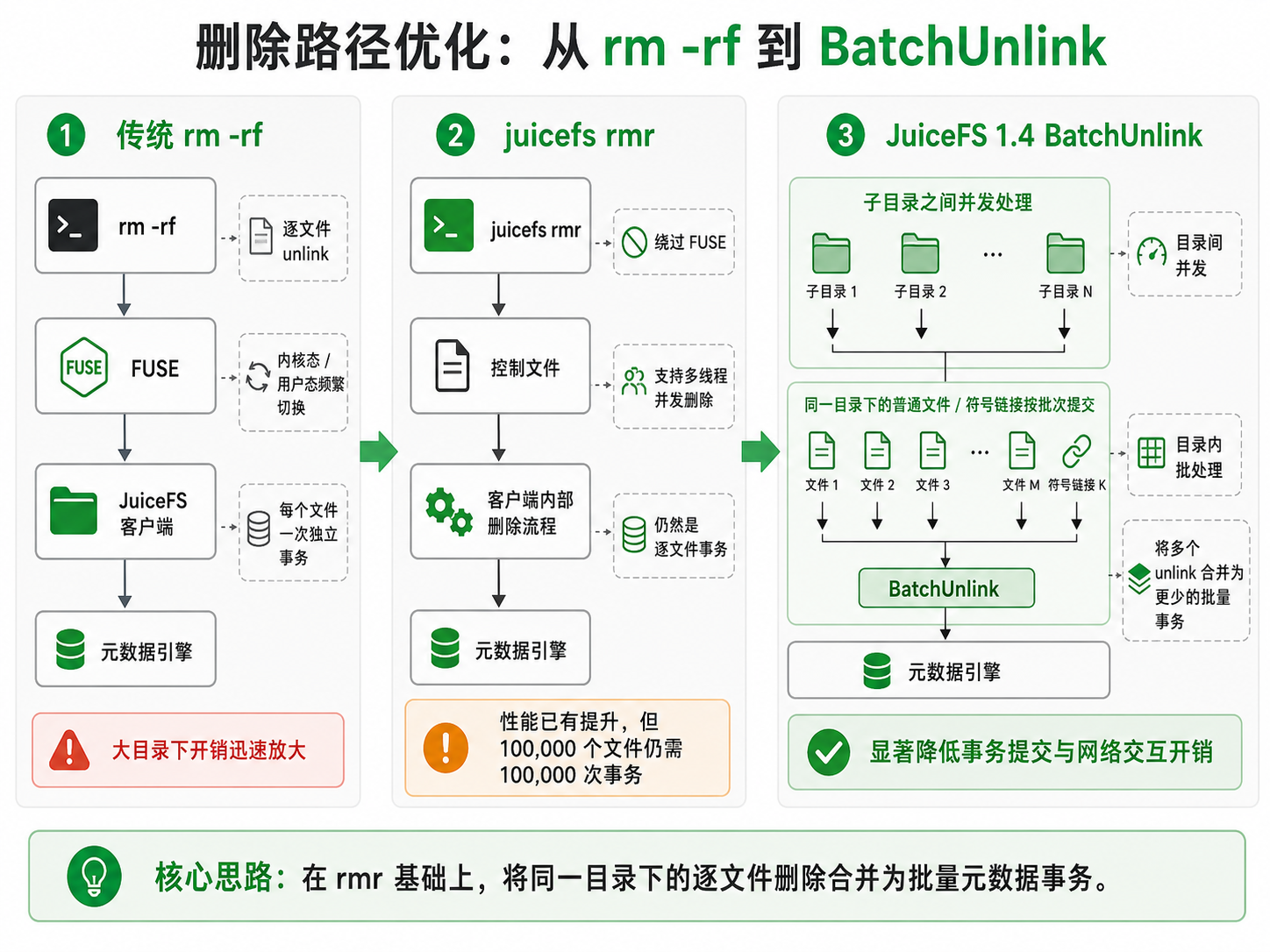
当目录中包含数十万甚至数百万个文件时,早期 rm -rf 的逐文件删除方式会迅速暴露性能瓶颈:每个 unlink 请求都需要经过 FUSE 协议在内核态与用户态之间交互,并触发一次独立的元数据事务提交。文件数量越多,系统调用、上下文切换、网络往返和事务提交开销累积越明显。
JuiceFS 此前已引入 juicefs rmr 命令来缓解这一问题。rmr 绕过 FUSE 协议层,通过控制文件直接将删除请求投递到客户端内部,同时支持多线程并发删除(默认 50 线程),相比 rm -rf 有显著提升。但 rmr 的每次删除仍然是独立的事务——十万个文件就需要十万次事务。本次的批量删除优化,正是要在 rmr 的基础上,将同一目录下的多次独立事务合并为一次批量事务,进一步消除网络开销。
核心优化思路
解决这个问题的关键在于将"多次小事务"合并为"少量大事务"。JuiceFS 在元数据引擎层面新增了 BatchUnlink 接口,它允许客户端将同一目录下的多个非目录文件在一次调用中批量删除。
在递归清空目录时,JuiceFS 会同时从两个层面减少删除开销:一方面,不同子目录之间可以并发处理,充分利用多线程删除能力;另一方面,在同一目录内部,会将普通文件和符号链接等非目录条目按批次提交给 BatchUnlink 处理。这样,原本需要逐个发起的 unlink 操作,就可以在元数据层面合并为更少的批量事务。
需要注意的是,BatchUnlink 并不直接批量删除目录。目录删除遵循递归顺序:先清空子目录中的内容,再删除子目录本身。因此, BatchUnlink 的作用范围限定在同一目录下的普通文件和符号链接上。这个限制既保证了递归删除语义的正确性,也避免了批量操作影响目录树结构的一致性。
各引擎的实现策略
在 BatchUnlink 的实现中,JuiceFS 针对不同元数据后端采用了相应的批量化策略,以减少事务提交次数和网络往返。
在 SQL 后端(MySQL、PostgreSQL 等),原来的逐条删除意味着每次都要执行独立的 INSERT、DELETE、UPDATE 语句序列。引入 BatchUnlink 后,系统会先通过一次批量查询获取所有待删除条目的 edge 记录,再通过一次带行锁的批量查询获取所有涉及的 inode 属性。随后,在同一个事务内批量执行 edge 删除、inode 状态更新(nlink 递减或标记为待清理)、delfile 条目插入等操作。原来 N 个文件的删除需要 N 次独立事务,现在只需要一次。
在 Redis 后端,优化策略则利用了 Redis 的 Pipeline 和事务机制。原来的逐条删除每次都需要独立的命令交互,而 BatchUnlink 将多个文件的 HDEL(删除 dentry)、ZADD(加入待清理队列)、SET(更新 inode 属性)、INCRBY(更新统计计数)等命令全部放入一个 Pipeline 中,在单次 MULTI/EXEC 事务中原子执行。为了控制单次事务中的命令总量,避免阻塞 Redis 单线程过久,批次大小固定为 250 个条目。
在 TiKV 后端,BatchUnlink 同样将多次删除操作合并到单次事务中,利用 TiKV 的批量写入能力减少网络往返和事务开销。对于分布式 KV 后端而言,这类批量化操作可以更充分地发挥后端的并发写入能力。
以下是在 100,000 个文件 flat 目录下,使用 juicefs rmr --threads 16 的测试结果,可以看到批量删除在不同元数据后端上均带来了明显提升,其中 TiKV 和 Redis 的收益更为显著。
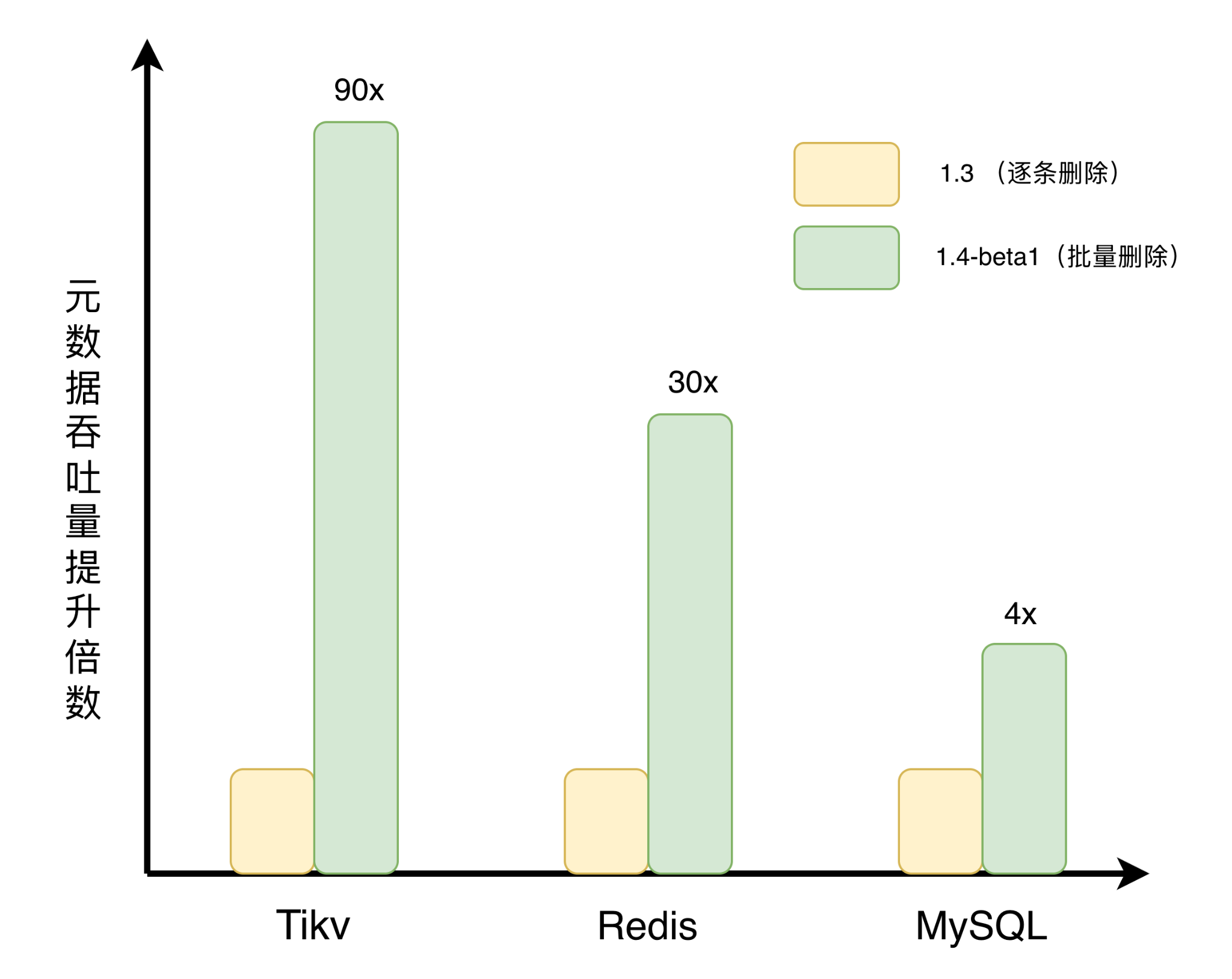
02 克隆:从逐条复制到批量引用
JuiceFS clone 常用于快速生成文件或目录副本,例如训练数据集版本管理、实验数据快照和大规模目录复制等场景。其高效之处在于创建副本时不会立即拷贝底层数据块,而是在元数据层创建新的文件记录,并复用源文件已有的数据块引用;后续只有副本发生写入时,系统才会为被修改的部分分配新的数据块。因此,clone 可以减少完整复制带来的时间和存储开销。
对于克隆大目录,与删除类似,逐文件处理会导致大量短事务和网络交互,由此产生大量元数据操作。批量克隆的核心是将同一目录下多个文件的克隆操作合并为一次批量事务。递归克隆目录时,系统会流式分批读取目录条目,将每批中的所有非目录条目收集后一次性批量克隆。
实现上的一个关键优化是"inode 预分配":在进入事务之前,系统先通过 nextInode 为所有待克隆条目预先分配好目标 inode。这避免了在事务内部频繁申请 inode 导致锁竞争。进入事务后,系统批量查询所有源文件属性(带行锁),构建好所有目标 node、edge、chunk、symlink、xattr 的插入数据,然后一次性批量插入。
批量克隆在不同元数据后端中的实现仍然会利用各自的批量写入能力,这一节不再展开写入细节。不同后端的性能提升幅度不仅取决于事务模型和网络交互成本,也与批量写入 node、edge、chunk 引用等元数据记录的效率有关。
具体测试结果如下表所示,在包含十万个文件的 flat 目录上,我们使用 juicefs clone 对比了优化前后的克隆性能,MySQL 后端提升最为显著,约 24 倍;Redis 后端约 5 倍,TiKV 后端约 2 倍。
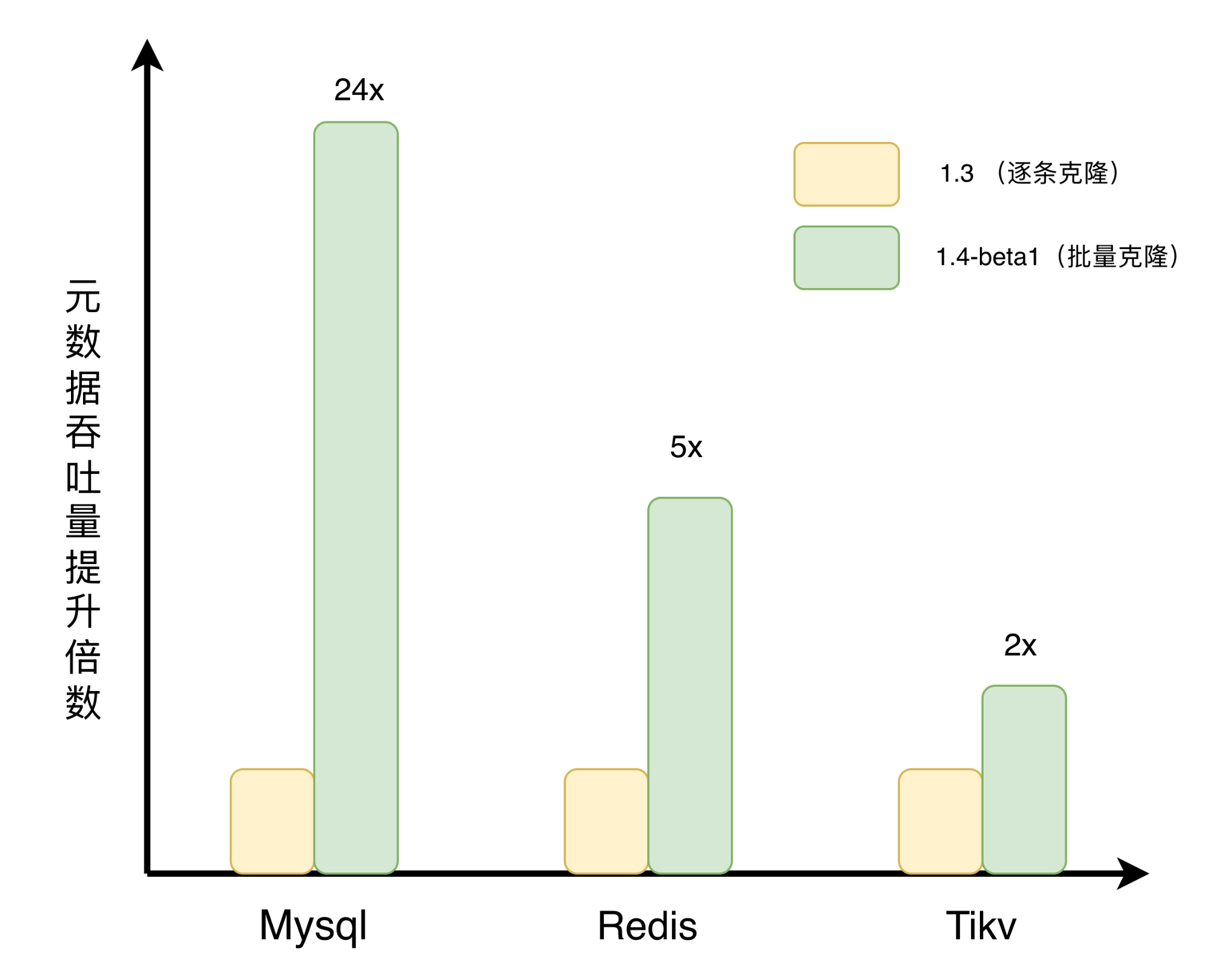
03 Redis 客户端缓存:将热点元数据缓存在本地
在高并发元数据访问场景,如 AI 训练数据集加载、大规模容器启动等,客户端与 Redis 元数据引擎之间的网络往返是主要的性能瓶颈。
以内核 VFS 的路径解析为例:当进程执行 open("/mnt/jfs/dataset/images/cat.jpg") 时,VFS 层需要逐级解析每个路径分量——先 lookup dataset,再 lookup images,最后 lookup cat.jpg。
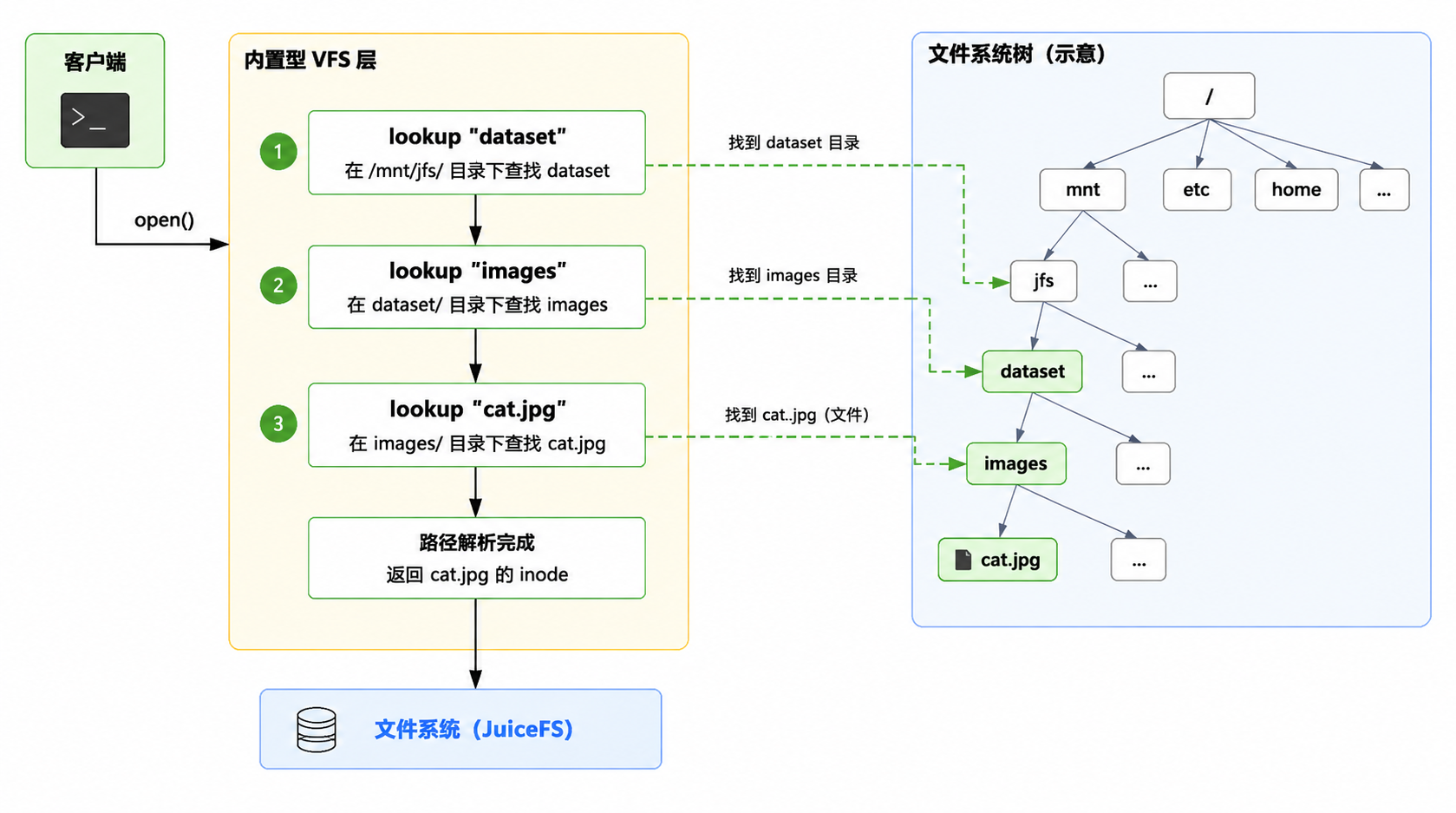
如果 images 目录下包含数十万个文件,而训练任务需要随机访问其中的文件,那么每次 lookup 都需要向 Redis 发起一次 GET 请求。在高并发场景下,这会造成大量的网络往返和 Redis CPU 消耗。即使 Redis 本身单次查询只需几十微秒,但加上网络延迟后,每次 lookup 可能就需要几百微秒甚至毫秒级。当数千个训练进程同时进行文件访问时,这个开销会被急剧放大。
实现原理:基于 Redis 6.0 客户端缓存机制
Redis 6.0 引入了客户端缓存(Client-Side Caching)功能,允许客户端在本地缓存热点键值,并由 Redis 服务器在键被修改时主动推送失效通知。JuiceFS 基于这一能力,将两类核心元数据缓存在客户端内存中:
第一类是 inode 属性缓存。以 inode 号为键,缓存该文件的完整属性数据(类型、大小、权限、时间戳等)。这类缓存通过 Redis 客户端驱动层的钩子机制透明实现:查询时自动先检查本地缓存,命中则直接返回,完全跳过网络请求;修改时则自动清除对应缓存,业务逻辑无需感知。
第二类是 目录条目缓存(entry cache)。以"父目录 inode + 路径分隔符 + 文件名"为键,缓存目录 lookup 的结果。与 inode 属性缓存不同,这类缓存的检查逻辑内嵌于目录查找路径本身,而非通过驱动层透明拦截。当某个目录的条目失效时,通过前缀匹配清除该目录下的所有相关缓存。这样一来,路径解析或重复访问同一目录下的热点条目时可以直接命中本地缓存。
引入客户端缓存后,核心挑战在于多客户端挂载场景下的元数据一致性维护。当多个客户端共享同一个 JuiceFS 文件系统时,某一客户端对文件或目录执行创建、删除、重命名或属性更新等操作后,其他客户端本地缓存中的相关 inode 属性或目录项结果可能随之失效。如果缺少有效的缓存失效机制,后续访问就可能命中过期元数据,导致客户端观察到的目录项或文件属性与后端元数据状态不一致。
为此,JuiceFS 基于 Redis 的客户端缓存机制,引入 Tracking 与广播失效(BCAST)模式。客户端连接 Redis 后,会声明需要跟踪的元数据 key 前缀;当这些 key 被修改时,Redis 会向相关客户端发送失效通知。客户端收到通知后,会根据 key 类型清理对应的 inode 属性缓存或 entry cache,使后续访问重新从元数据引擎获取最新结果。
此外,客户端初始化时,JuiceFS 会对挂载点根目录下的元数据进行预热。由于这部分文件通常访问频率最高,实测表明该优化能够有效提升整体访问性能。
通过上述机制,热点元数据可以在客户端本地复用;一旦相关元数据发生变化,对应缓存会被及时淘汰,从而降低过期元数据被继续使用的风险。
适用场景与注意事项
Redis 客户端缓存最适合读多写少、热点元数据重复访问明显的场景,例如 AI 训练数据集加载——训练过程中数据集通常只读不写,任务会反复访问相同目录和文件,因此 inode 属性缓存和 entry cache 更容易命中,进而减少重复 lookup 和远端元数据查询。
如果客户端与 Redis 元数据引擎之间存在较高网络延迟,例如跨可用区部署,本地缓存的收益会更加明显。
使用该能力时,需要确保 Redis 版本为 6.0 及以上。默认缓存过期时间为 1 分钟,用于在网络闪断、连接异常等情况下为失效通知机制提供兜底,避免过期元数据长期保留在客户端本地缓存中。对于强一致性行更高的场景,可以根据实际需求缩短缓存过期时间,或关闭客户端缓存,以降低读取过期元数据的风险。
04 小结
这三项优化分别覆盖了元数据的写、复制和读三条路径:
- 批量删除将同一目录下的多次独立 unlink 合并为一次批量事务
- 批量克隆将同一目录下的多次独立 clone 合并为一次批量事务
- Redis 客户端缓存在客户端本地缓存热点元数据,将读操作延迟从网络级降到内存级,通过广播失效保证多客户端一致性。
其中 BatchUnlink 和 BatchClone 都是内部接口,用户无需直接调用,只需选择正确的操作方式即可命中优化(例如,删除大目录用 juicefs rmr,复制目录用 juicefs clone)。
需要注意的是,批量操作的核心是把同一目录下的普通文件合并为一次批量事务;子目录则通过并发 goroutine 递归处理。因此,越是大型的目录,优化的收益越明显。
以上优化均已在 JuiceFS 社区版 1.4 中可用,升级客户端版本即可获得性能收益。
