














在数据迁移、跨云同步与对象存储备份等场景中,juicefs sync 常用于执行大规模数据同步任务。当数据规模达到 TB 到 PB 级、对象数量达到数百万甚至数十亿级时,单次任务执行周期通常会延长到数小时甚至数天。
在这个过程中,系统运行过程中通常会逐步暴露出以下几类问题:
- 任务在网络抖动、进程异常退出或节点重启后,难以从一致状态继续执行,往往需要重新扫描或重复处理;
- 数据备份场景可能存在明文暴露风险并可能面临合规与安全要求;
- 多个同步任务并发运行时,带宽资源竞争明显,整体传输过程缺乏有效的全局控制手段。
围绕这些场景,JuiceFS 1.4 在 sync 中提供了三项能力增强:断点续传、数据加解密,以及全局流量控制。本文将围绕这三项能力,介绍其适用场景、实现机制和使用方式。
01 断点续传
在早期版本中,用户同步过程中遇到错误或者中断,重新执行任务时,juicefs sync 需要重新扫描源端和目标端,再判断哪些对象已经完成、哪些对象仍需复制。对于上亿级对象或大量大文件场景,仅重新扫描本身就可能带来显著的时间成本和对象存储请求开销。
为了解决这一问题,我们在 JuiceFS 1.4 中为 sync 引入了 断点续传机制。启用后,sync 会将任务进度保存到目标端。当任务中断后,用户只需重新执行相同命令,sync 就会自动查找并加载与当前源端、目标端及关键参数匹配的 checkpoint,从上次未完成的位置继续执行,避免从头重新处理。
工作原理
启用 断点续传 后,sync 会在目标端保存一个 JSON 格式的状态文件,文件名格式如下:
.juicefs-sync-checkpoint.<hash>.json
其中,<hash> 由源端、目标端和关键同步参数计算得到,用于确保当前任务只加载与自身匹配的 checkpoint,避免不同同步任务之间误用状态文件。
断点续传的运行流程如下图所示:
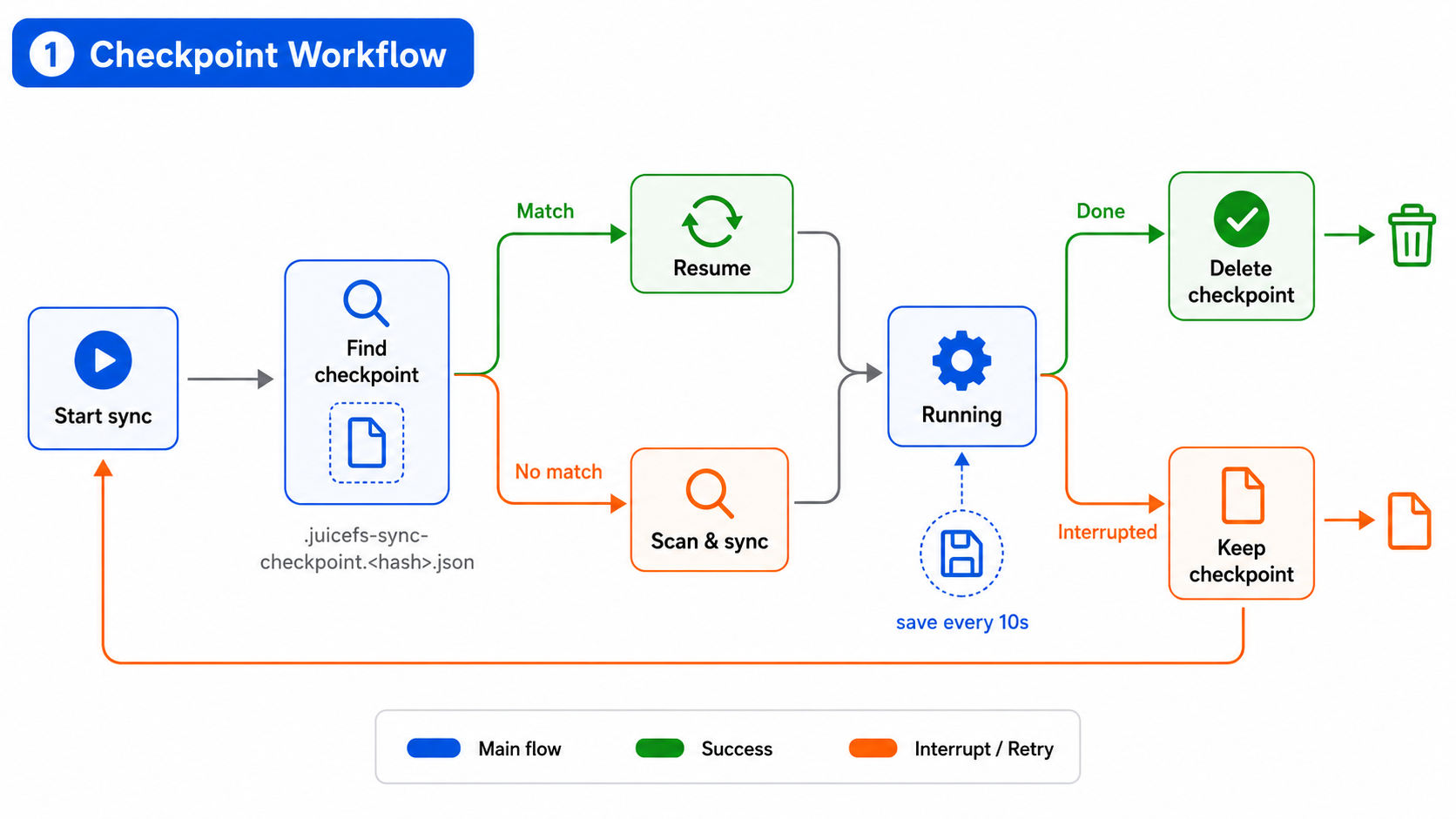
sync启动后,首先在目标端查找与当前任务匹配的 checkpoint。- 如果找到匹配项,则从上次保存的状态恢复执行;如果未找到,则按正常流程扫描并开始同步。sync 会并发遍历多个前缀,每个前缀都有独立状态,包括是否已完成遍历、上次遍历到的位置、待同步对象以及同步失败的对象。
- 从 checkpoint 恢复时,sync 会先从每个前缀中记录的待同步对象和失败对象重新加入任务队列,对于上次尚未遍历完成的前缀,则从记录的位置继续扫描并同步;已经完成遍历的前缀只会继续处理 checkpoint 中尚未完成的对象。
- 任务运行过程中,
sync会按设定间隔异步保存当前进度,默认每 10 秒保存一次。 - 任务正常完成后,checkpoint 文件会被自动删除;如果任务中断或失败,则会保留下来,供下次执行相同命令时继续恢复。
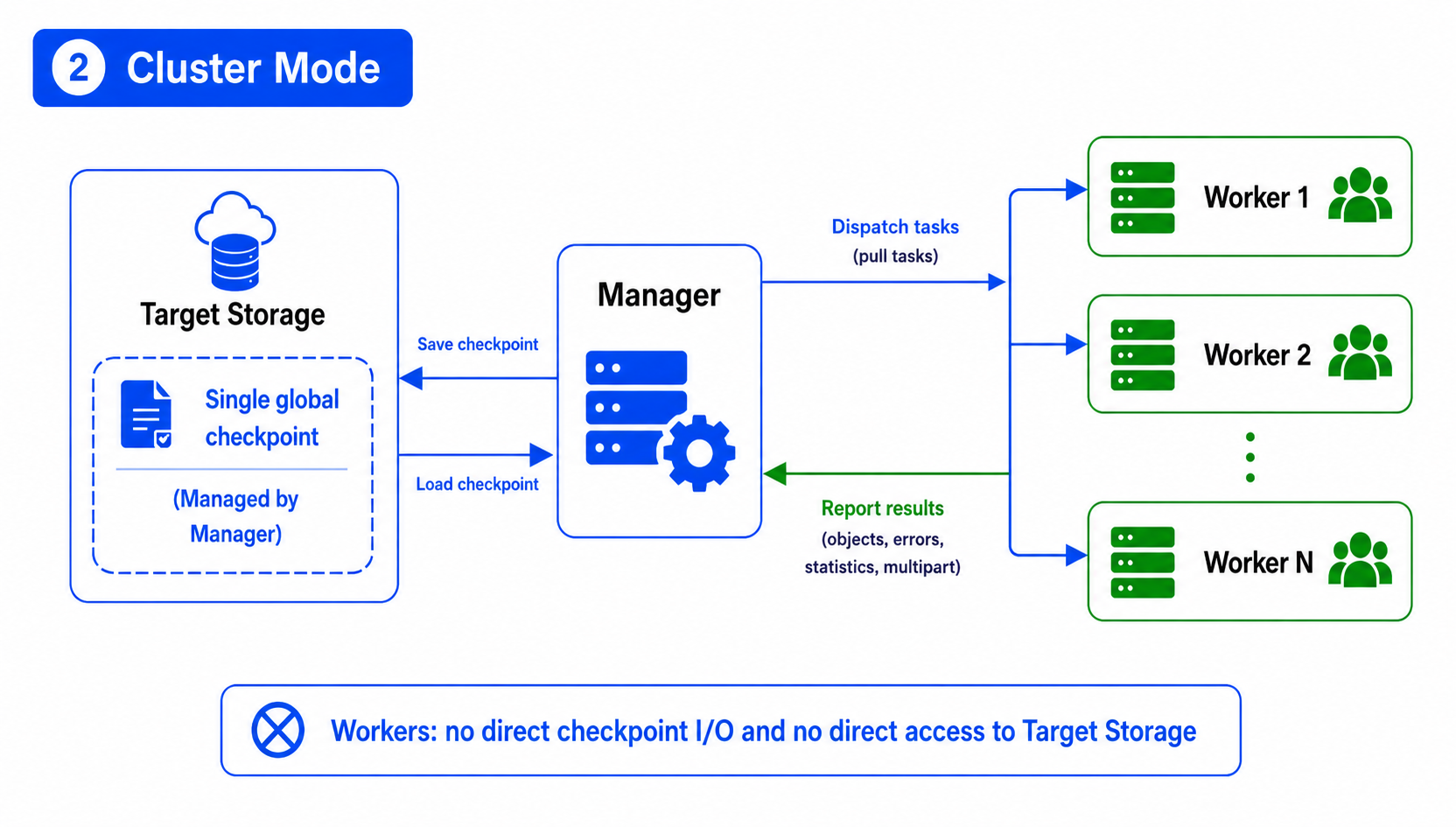
在集群模式下,checkpoint 只有一份,由 Manager 统一维护。Worker 不直接读写目标端的 checkpoint 文件,而是负责从 Manager 拉取任务、执行同步并回传结果。Manager 会将 Worker 回传的完成对象、失败对象、统计信息和 multipart 状态合并到全局 checkpoint 中。
使用方式
# 启用断点续传
juicefs sync --enable-checkpoint SRC DST
# 自定义 checkpoint 保存间隔(默认 10s)
juicefs sync --enable-checkpoint --checkpoint-interval 30s SRC DST
# 忽略已有 checkpoint,强制从头同步
juicefs sync --enable-checkpoint --checkpoint-force-reset SRC DST
02 数据加解密
在跨云备份和归档场景中,客户端加密是常见的合规要求,例如数据主权、静态数据保护、敏感数据迁移等。此前,juicefs sync 没有原生加解密能力,用户如果希望将数据加密后写在目的端,通常需要借助外部工具额外处理。
在 JuiceFS 1.4 中,我们将流式加解密能力集成到 sync 流程中,使用户可以在数据同步的同时完成加密、解密或重新加密,主要支持以下三类场景:
- 加密写入:将明文数据加密后写入目标端,适用于加密备份和归档场景。
- 解密恢复:从源端读取加密数据,解密后写入目标端,适用于数据恢复或明文迁移。
- 重新加密:使用旧密钥解密源端数据,再使用新密钥加密后写入目标端,适用于密钥轮换或加密算法迁移。
工作原理:分块流式加密
为了支持对象存储的 Range GET,并避免一次性加载大文件带来的高内存占用,sync 采用固定 1 MiB 分块的流式加密方案。每个文件会先被拆分为多个明文块,再分别加密写入目标端。
原始文件结构可以理解为:
[chunk 1: 1 MiB][chunk 2: 1 MiB] ... [chunk N: ≤1 MiB]
加密后,每个明文块会对应生成一个加密块。每个加密块由 4 字节头部和密文数据组成,其中 4 字节头部用于记录该块的实际密文长度,即 ct_len:
每个加密块: [4B ct_len][ciphertext + padding]
加密后的文件: [encrypted chunk 1][encrypted chunk 2] ... [encrypted chunk N]
加密块的大小由明文块大小和加密开销共同决定,可以理解为 plainChunkSize + overhead。其中,plainChunkSize 固定为 1 MiB,overhead 取决于所使用的加密算法和密钥类型。
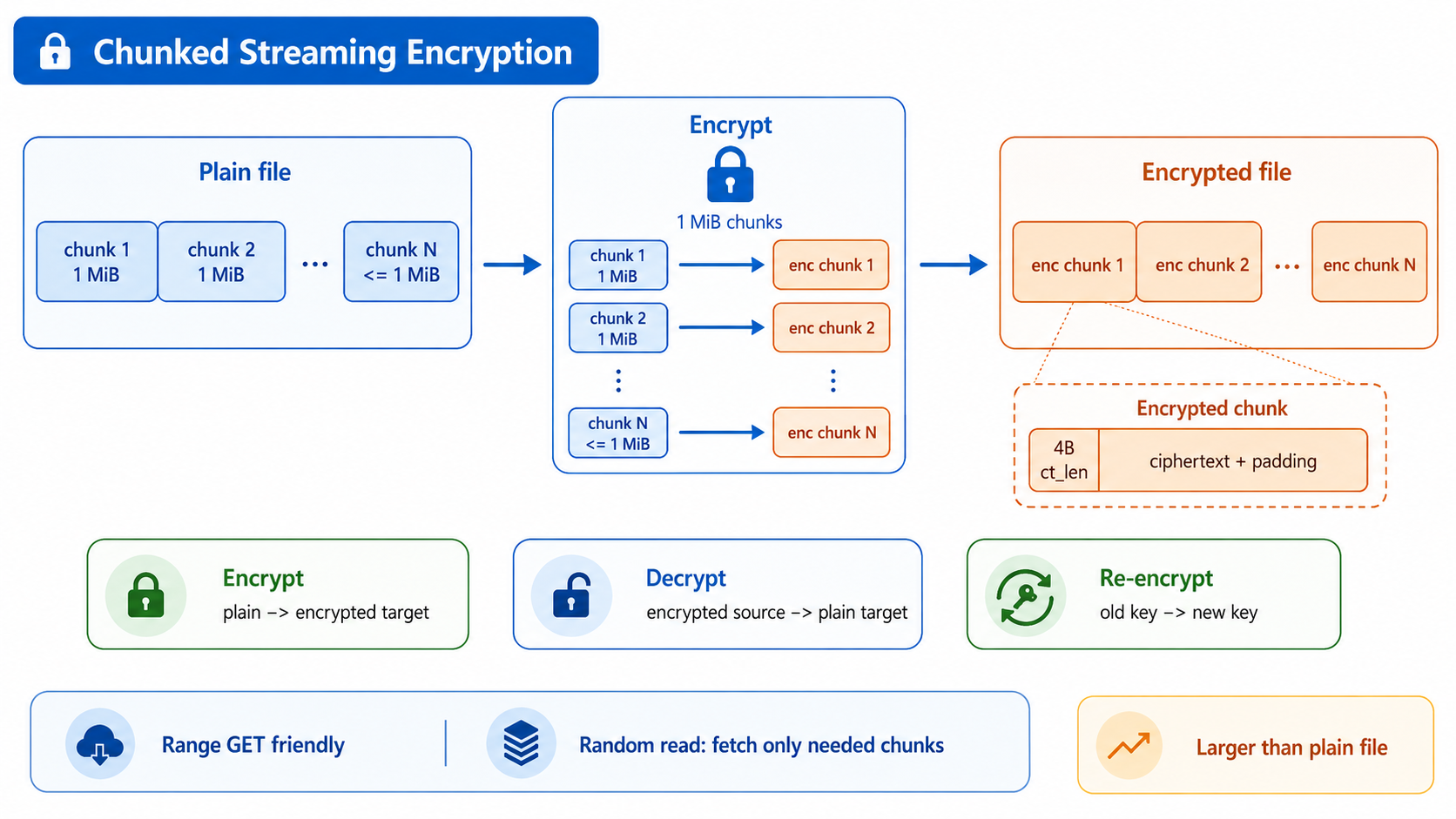
这种设计的好处是,随机读取时只需要根据偏移定位到对应的加密块,并下载相关块数据,不必读取整个文件。相应地,加密后的对象会包含额外头部、填充和加密元数据,因此目标端对象通常会比原始明文文件更大。
支持的算法
| 参数值 | 对称算法 | 密钥封装 | 适用场景 |
|---|---|---|---|
| aes256gcm-rsa(默认) | AES-256-GCM | RSA | 通用场景 |
| chacha20-rsa | ChaCha20-Poly1305 | RSA | 对 AES 硬件加速支持有限的环境 |
| sm4gcm | SM4-GCM | SM2 | 需要国密算法的场景 |
使用方式
下面以 RSA 密钥为例说明加密、解密和重新加密的使用方式。
生成密钥对:
# 生成 RSA 私钥(公钥内嵌其中,JuiceFS 自动提取)
openssl genrsa -out private.pem 2048
# 带密码保护的私钥
openssl genrsa -aes256 -out private.pem 2048
场景一:加密写入目标端
juicefs sync /local/data s3://mybucket/backup
--encrypt-rsa-key /path/to/private.pem
场景二:解密读取源端,用于数据恢复或明文迁移。
juicefs sync s3://mybucket/backup /local/data
--decrypt-rsa-key /path/to/private.pem
场景三:重新加密,用于密钥轮换或算法迁移。
# 解密旧密钥加密的数据,用新密钥重新加密写入新存储
juicefs sync s3://old-bucket/encrypted s3://new-bucket/re-encrypted
--decrypt-rsa-key /path/to/old-private.pem
--encrypt-rsa-key /path/to/new-private.pem
如果私钥设置了密码,可以通过环境变量传入。
# 加密场景使用 JFS_ENCRYPT_RSA_PASSPHRASE
export JFS_ENCRYPT_RSA_PASSPHRASE="your-passphrase"
juicefs sync /local/data s3://mybucket/backup --encrypt-rsa-key private.pem
# 解密场景使用 JFS_DECRYPT_RSA_PASSPHRASE
export JFS_DECRYPT_RSA_PASSPHRASE="your-passphrase"
juicefs sync s3://mybucket/backup /local/data --decrypt-rsa-key private.pem
注意
- 加密后的数据采用 JuiceFS 私有格式存储,需通过
juicefs sync并提供对应密钥进行解密读取。 - 请妥善备份加解密所用私钥;私钥一旦丢失,已加密数据将无法解密访问。
03 全局流量控制
在早期版本中,juicefs sync 已经支持通过 --bwlimit 对单个 sync 进程限速。但在多个 sync 进程同时运行时,例如分布式同步中的多个 Worker,或多个独立同步任务共享同一条出口链路,单进程限速并不能约束整体带宽使用量,仍然可能导致出口带宽被打满,影响其他业务流量。
我们在 JuiceFS 1.4 中新增了 --traffic-control-url 参数。用户可以将多个 sync 进程接入同一个外部流量控制服务,由该服务统一分配带宽配额,从而实现跨进程、跨任务的全局限速。
工作原理
全局流量控制采用令牌桶模型。多个 sync 进程在传输数据前,都会向同一个流量控制服务申请字节配额:
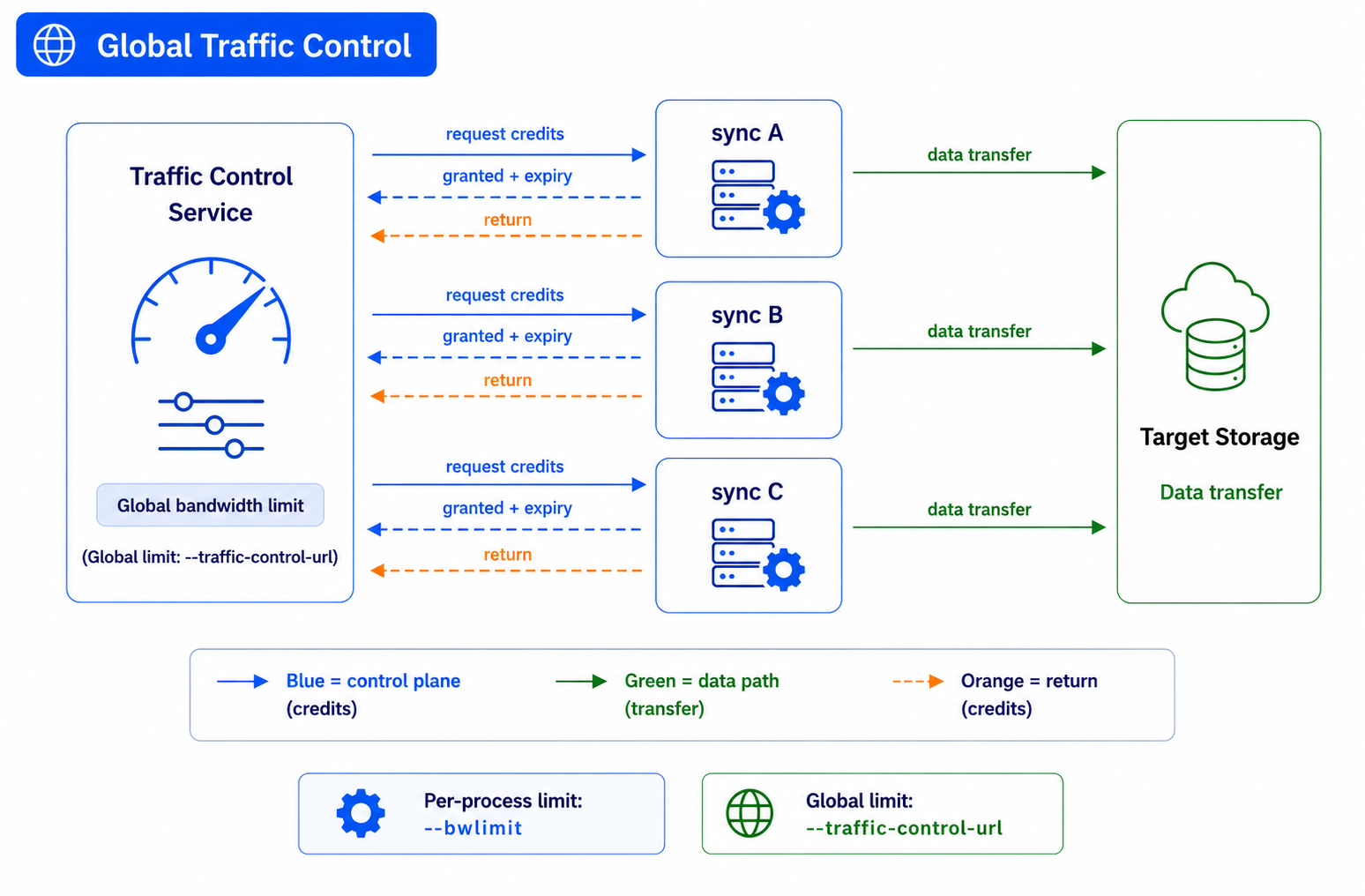
每个 sync 进程在传输数据前,会向控制服务申请一定数量的字节配额(credit)。控制服务根据当前总带宽使用情况,决定本次授予多少配额,以及配额的有效时间。配额用完后,sync 会继续申请新的配额;如果配额即将过期但尚未用完,未使用的部分会提前归还给控制服务。
控制服务通过 HTTP 接口提供配额申请和归还能力,接口需由用户自行实现或接入现有服务:
POST /traffic-control
Content-Type: application/json
请求:
{"bytes": 1048576}
bytes > 0: 申请 bytes 字节的额度
bytes < 0: 归还 |bytes| 字节的未使用额度
响应:
{"granted": 524288, "expired": 1000}
granted: 本次授予的字节数
expired: 额度有效期(毫秒)
在同步过程中,sync 会在传输数据前向流量控制服务申请配额。如果当前没有可用配额,传输会阻塞等待,直到获得新的配额。通过这种方式,多个同步任务可以共享同一个全局带宽上限,避免并发任务各自限速但总流量失控的问题。
使用方式
# 先部署流量控制服务(示例:监听 8080 端口,限制总带宽 100 Mbps)
# (服务实现由用户自行决定,juicefs 只负责调用接口)
# 多个 sync 进程接入同一个控制服务
juicefs sync SRC1 DST1 --traffic-control-url http://127.0.0.1:8080/traffic-control &
juicefs sync SRC2 DST2 --traffic-control-url http://127.0.0.1:8080/traffic-control &
--traffic-control-url 可与 --bwlimit 同时使用,两个限制独立生效:--bwlimit 用于限制单个 sync 进程的最大带宽,--traffic-control-url 用于控制多个 sync 进程的全局带宽。
# 单进程不超过 50 Mbps,同时所有进程合计不超过服务端配置的上限
juicefs sync SRC DST
--bwlimit 50
--traffic-control-url http://controller:8080/traffic-control
04 小结
JuiceFS 1.4 对 sync 的增强包括:断点续传降低了任务中断后的恢复成本,数据加解密提高了数据备份的安全性,全局流量控制则帮助多个同步任务更有序地共享带宽。对于数据迁移、跨云同步、对象存储备份和加密归档等场景,用户可以根据任务规模、网络环境和安全要求,灵活组合使用这些能力。
