














今天,我们很激动地宣布,将经过 4 年持续迭代和累计几千万小时线上考验的 JuiceFS 开源了!
JuiceFS 是什么
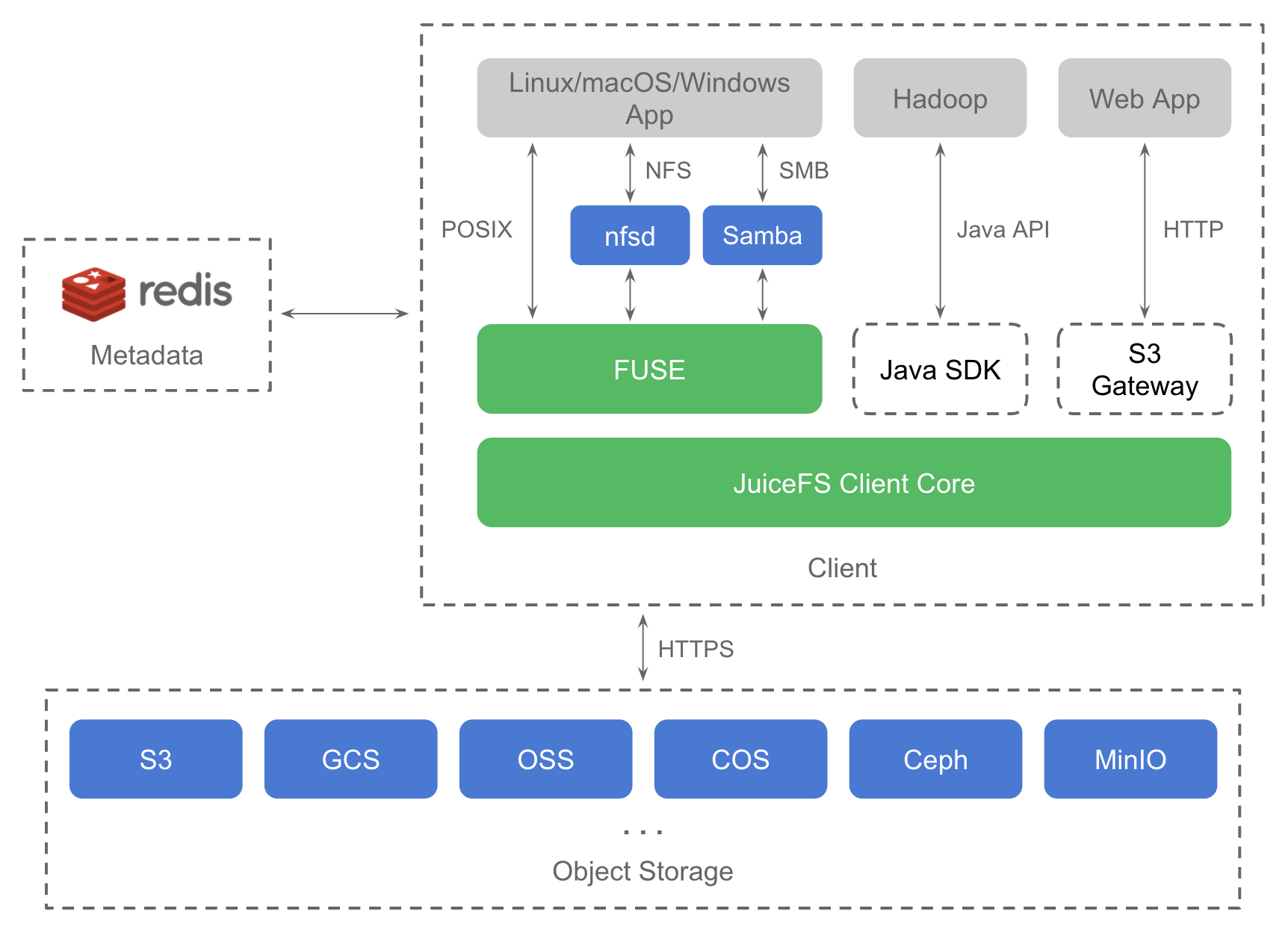
JuiceFS 是为海量数据设计的分布式文件系统,使用对象存储来做数据持久化,避免重复造轮子,还能大大降低工程复杂度,让我们专注解决元数据和访问协议部分的难题。
JuiceFS 的创新架构更符合云原生的发展趋势,我们一开始就以 SaaS 的形式将它提供给公有云的客户,让客户分钟级就可以获得 PB 级企业文件存储服务。同时,我们也和行业领先的对象存储厂商一起服务私有云客户。
为什么开源
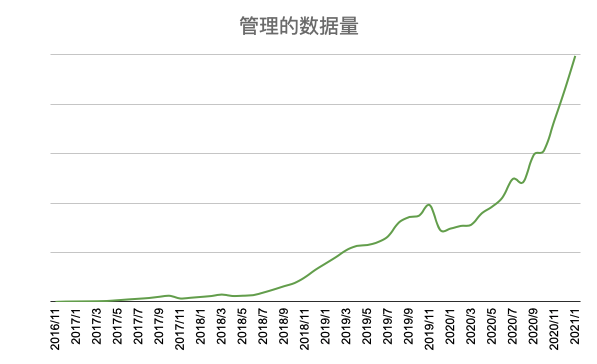
在创业之初,我们认为 SaaS 可以为用户提供最佳的体验,同时让我们更快地迭代产品,决定优先把 SaaS 做好。经过 4 年的持续迭代和积累,JuiceFS 已经在几十家科技企业的大数据、AI、容器平台、归档、备份等场景中形成最佳实践, SaaS 使用量也持续快速增长,并且在过去的 2020 年首次实现了盈亏平衡。我们相信找到了可持续发展的模式,有信心保障 JuiceFS 的长期运营。
我们也发现闭源的基础软件会限制使用者对它的深度理解,不利于它服务更多的人,依靠 SaaS 产品的收入支撑和开源社区的力量,我们可以让 JuiceFS 帮助更多的人。
架构再升级
借助对象存储的帮助,JuiceFS 已经大大降低了分布式文件系统的复杂度,元数据管理是它最核心的问题。JuiceFS 的 SaaS 使用的元数据引擎,是专为文件系统打造的数据库,我们已经积累了丰富的运维经验,仍然如履薄冰。如果开源的话,让社区用户自己运维仍然会是一个大的挑战和负担,一旦运维失误导致数据丢失,后果非常严重。
带着这个问题,我们将元数据服务改造为支持多引擎的插件式架构,可以利用已有的开源数据库实现元数据存储。这样可以更灵活地适应不同场景,根据场景的规模、性能和成本需求,选用不同的元数据实现。这是 JuiceFS 的架构再升级,为未来的发展翻开新的篇章。
我们选用 Redis 作为第一个开源存储引擎,是因为它:
- 是全内存的,可以满足元数据的低延时和高 IOPS 要求;
- 支持乐观事务,能够满足文件系统元数据操作的原子性要求;
- 有丰富的数据结构,易于实现文件系统的诸多 API;
- 有着非常广泛的社区和成熟的生态,运维 Redis 不会是一个问题;
- 在各个云上都有托管的服务,在云上使用会更简单;
未来,我们还会增加 SQL 数据库、TiKV 等支持事务的 KV 数据库支持。
未来发展
最近几年,数据库领域发生了一件有趣的事情:当 NoSQL 数据库在满足了数据的快速增长后,它在一致性、访问便捷性和管理能力方面的不足逐渐显露,把这些复杂性转嫁到了业务系统和运维上,开始被人诟病。同时, SQL 数据库也有了长足的进展,已经能够满足现在的数据规模需求,经过全面的对比分析后,大家又在回归 SQL 数据库,曾经的 NoSQL 运动也逐渐显出颓势。
估计类似的事情也会发生在非结构数据领域。对象存储在媒体文件等场景取得了巨大的成功,但当人们以为它就是未来的存储形态,开始推广到更大范围时,它牺牲掉的树形目录结构、可修改性、元数据性能、一致性等等,变成了一只只拦路虎,影响它在其他场景的使用效果。
我们坚信文件系统是最好的管理非结构化数据的方式,对象存储只适用于某些简单场景。分布式文件系统一直是基础软件中难啃的骨头,JuiceFS 通过对文件系统中元数据和数据的独立抽象,大大减低了系统复杂度,使得文件系统能够借助这些年来对象存储和分布式数据库的进展,管理超大规模的数据。同时,复杂度的降低可以让更多的开发者参与进来,未来更多的应用也会建立在文件系统接口之上。
我们将通过开源社区的相互协作,一方面为各个应用提供更好的存储支持,也会在底层存储引擎和对象存储上加深协作,一起推动文件存储的快速发展,打造未来数据生态的坚实底座。
我们 GitHub 见:https://github.com/juicedata/juicefs !
