














在 4月17日 DataFunSummit 大数据存储架构峰会上邀请了互联网一线巨头、云原生大数据存储、数据库,国内外知名数据开源产品一线专家、学者,就大数据存储架构的关键技术、挑战和当前应用展开了交流讨论。
作为今年开源的热门云原生文件系统项目 JuiceFS,合伙人苏锐做了题为 「JuiceFS,云原生时代的分布式文件系统」的演讲,为与会嘉宾分享了在云原生环境下文件存储的挑战和需求,在这样背景下产生的 JuiceFS 的目标和架构设计,以及在大数据、AI 等业务领域中的价值与收益。
以下为演讲实录:
大家好,我是 JuiceFS 合伙人苏锐。很高兴今天能在这里和各位交流,介绍我们今年初刚刚开源的产品 JuiceFS,我们在今年 1 月份将项目开源,目前在 GitHub 上已经有 3100 多星,上过 Hack News 首页,也上过 GitHub Trending 榜单,作为一个非常底层技术的项目,受到这样的关注也出乎我们的意料,同时也说明它确实击中了云原生环境中文件存储的需求。
我今天分享的题目是「JuiceFS,云原生时代的分布式文件系统」。演讲内容分为四个部分,首先要说说为什么云原生环境中需要文件系统,也叫做文件存储,这个部分讲了 JuiceFS 诞生的背景。然后介绍 JuiceFS 的目标与架构设计,以及云原生环境中我们正面对哪些业务挑战。最后,再展望一下未来,讲一讲 JuiceFS 已经在做,和计划要做的事情。
云原生环境为什么需要文件系统
第一部分内容讲讲云原生环境为什么需要文件系统,包括两方面,首先是文件存储的架构变迁,然后讲讲云原生文件存储的需求是什么?

在这张幻灯中,我列出了过去 40 年文件存储的产品形态和架构设计的变化,自上世纪 80 年代一直到 2000 年左右,也就是从局域网的普及到互联网的普及,文件存储都是由专业厂商提供软硬件一体的产品,这类产品都依赖专有硬件,扩展性有限。所以到 21 世纪初,随着宽带网络的普及,Web2.0 时代的到来,UGC 数据(User Generated Content)爆发,整个互联网的数据呈指数增长,大家第一次开始面对 “大数据” 这个概念,当时 Google 的一篇论文「Google File System」提供了大数据存储的一种思路,然后有了一个开源实现 HDFS,也是今天大数据领域最流行的分布式文件系统。同时也出现了 Ceph、MooseFS 等不同思路的分布式文件系统,这些项目的重要意义在于它们第一次基于普通、标准的 x86 硬件,使用纯软件的方式将成百上千台机器管理起来,成为一套存储系统。
直到 2006 年,Amazon 发布了第一个云服务 S3(Simple Storage Service),正如它的名字,S3 具备两个非常重要的特点:简单 & 服务。首先,S3 简化了 File System 的能力,仅提供非常简单的数据结构(Key-Value)和访问接口,同时 S3 也是第一次把数据存储作为一种 “服务” 提供给用户,大家不用再操心扩容、监控、数据维护等工作。在此之前,大家从来没有想象过这样的体验。S3 发布的时间同时也是移动互联网出现的时间,这样便捷的服务正好满足了移动互联网时代数据规模进一步爆发带来的存储需求。
S3 提供的 Key-Value 类型现在都叫做 对象存储,它简化了文件系统中数据与数据之间的组织结构,这种简单的组织方式可以很好满足 UGC 数据的需求,用户上传数据,服务进行存储,然后交给 CDN 网络分发。但是放到大数据分析,机器学习训练,还有很多行业对数据处理的需求中,对象存储并不适合。因为对象存储为了满足高可用、高扩展性、价格便宜的需要,简化了数据结构,原来文件系统的一些访问接口也就无法原生实现,虽然有模拟行为的接口,但是会带来性能大幅下降、数据一致性下降等问题。随着数据规模的增加,管理员想对一个对象存储 Bucket 中的数据做管理、维护等工作的难度都是巨大的。
上面提到的这些对象存储面临的问题,正是文件系统擅长的,所以我们从 2017 年开始探索云原生文件系统的方向,有了 JuiceFS 这个项目。起初我们学习 S3 的方法,在全球所有公有云上提供 JuiceFS 文件存储服务,在经过业务验证、场景打磨,收获几十个互联网行业客户之后,让我们对 JuiceFS 有了非常坚定的信心。同时,JuiceFS 作为一种新的产品形态和体验,为了让更多开发者可以了解和探索,建设一个开源社区一定是可以让更多开发者受益的方式。
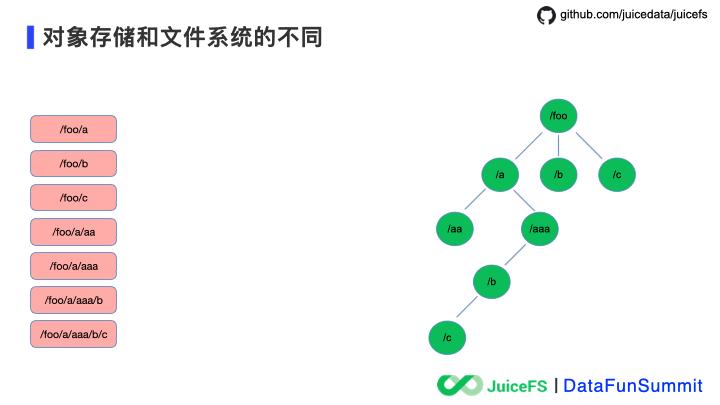
在这里我举个例子来说明对象存储与文件系统的不同,一个文件系统的目录结构中应该是右边树形结构的样子,而对象存储中是左边扁平的结构,每个对象的 key 用 “/” 模拟了路径结构,但对象与对象之间没有关联。在这两种数据结构下咱们看看 “rename” 操作的不同实现方式。
在 mv /foo /bar 这个改名操作中,昨天对象存储需要在元数据索引中找到搜索出所有 key 包含 /foo 对象,然后拷贝为一份新的对象,将 key 里的 /foo 改为 /bar,这样就会有大量的对象发生 I/O 复制,拷贝完成后删除旧的对象,在拷贝和删除完成之后再更新对象存储的元数据索引。整个操作没有事务保证,完成时间依赖于改名操作涉及的对象数量,缺少事务保证也是造成数据不是强一致性的原因。
再看右边文件系统中的改名操作,只需要找到路径名对应的 inodes 更新即可,保证了操作原子性。
云原生文件存储的需求是什么?
介绍完文件存储的发展,也详细举例了对象存储和文件系统的差异之后,咱们来看看云原生文件存储的需求是什么?

一方面云原生架构提供了很多设计理念,一方面我们也更关注用户在自己的业务场景中遇到的痛点和对应的需求,比如希望存储系统服务化,可以弹性伸缩,在海量数据面前对人、对程序同样友好,如何支持 Hadoop 生态、OLAP 产品等实现存储计算分离。同时简单、可靠、高性能、低成本当然也是一个文件存储服务必须具备的。
JuiceFS 的设计目标和架构

在考虑 JuiceFS 设计目标的时候,我们再重新分析一下对象存储的优劣势。正如上图左边列出的,优势在 JuiceFS 中应该都继承,然后结合业务场景的需求,针对性的解决对象存储的劣势。这里我们提出了几个重点能力:
- 数据强一致性,这是文件系统必须的;
- 高性能元数据,解决对象存储在计算、分析场景中的痛点;
- 多访问协议互通,包括 POSIX、HDFS、S3,其实 POSIX 是最久经考验,生态丰富的文件访问接口,但是考虑到已有的 Hadoop 生态和基于 S3 API 开发的程序,JuiceFS 需要提供一个平滑对接的体验才好,不要让开发者改代码;
- 小文件管理能力,无论在大数据场景还是 AI 训练场景,十亿、百亿甚至千亿文件的管理需求被越来越多的提起。在实际的生产环境中,也已经有客户使用 JuiceFS 管理数十亿的文件了。
- Kubernetes 友好,这是云原生时代最重要的用户体验,JuiceFS 必须支持,而且必须支持的很好。
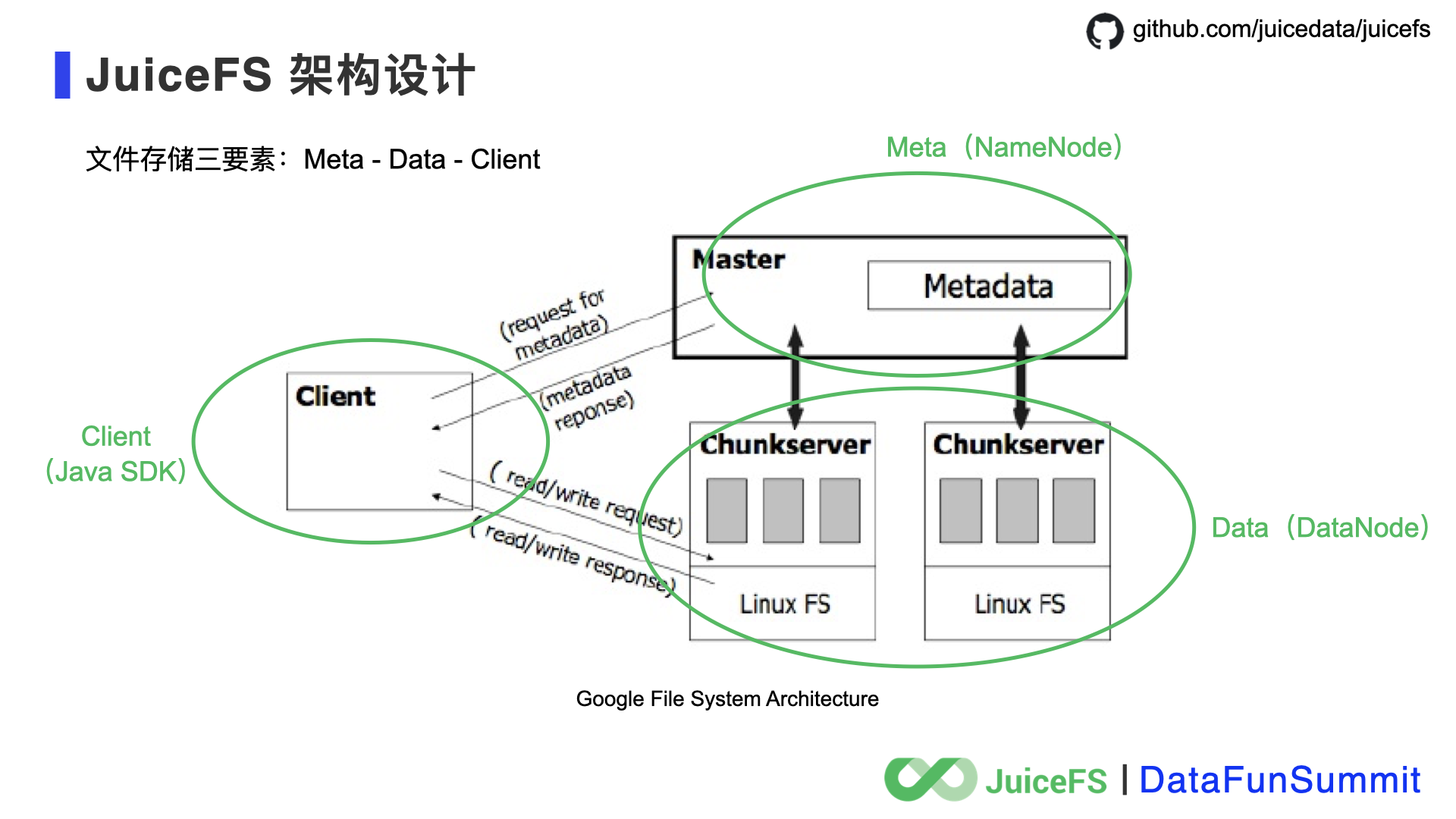
基于这些设计目标再来看看架构设计的思路。在分布式文件系统中有核心三要素:元数据、数据、客户端。在 Google File System(GFS)的论文中给出了一个简单经典的设计。大家看下图,系统从顶层架构角度看分为三大块,用 GFS 和 HDFS 做个比较,GFS Master 对应 HDFS NameNode,GFS ChunkServer 对应 HDFS DataNode,然后都有一个 Client 负责程序和存储系统交互。
下面是 JuiceFS 的架构设计,可以看出来系统也分为三个部分,这里 JuiceFS 做个两个很重要的创新。
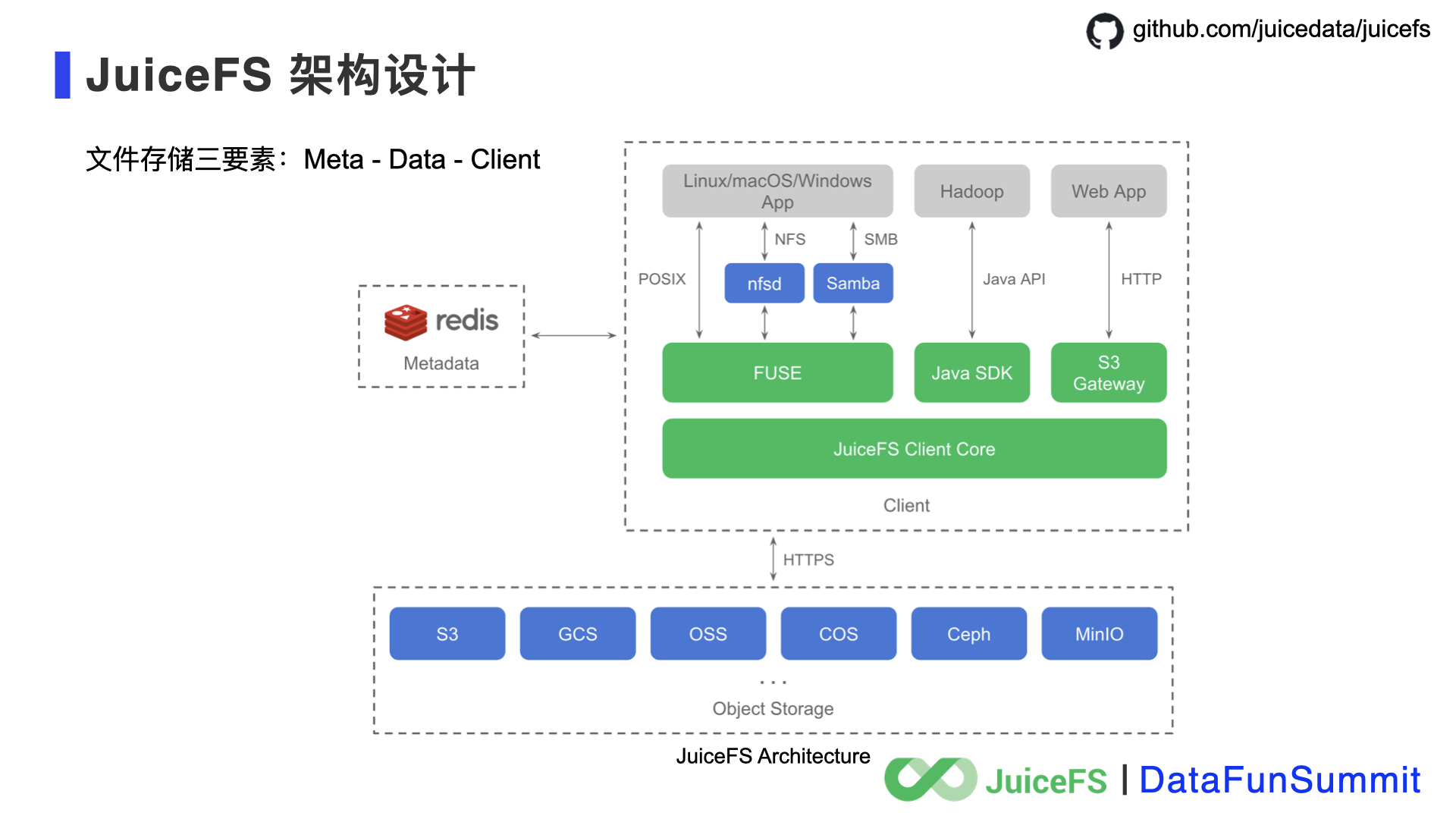
首先,架构图下面的对象存储对应 ChunkServer 和 DataNode 的角色,是 JuiceFS 的存储层。JuiceFS 没有再重新设计一个数据存储层,而是借助了已经被广泛使用的对象存储技术,这样选择是因为对于数据存储层(ChunkServer)的需求核心是扩展性、持久性安全、低成本,这几点刚好是对象存储的优势,无论在公有云还是私有云都能找到成熟、可靠的对象存储产品。所以 JuiceFS 选择站在对象存储的肩膀上来构建文件系统,而不是重复造轮子。
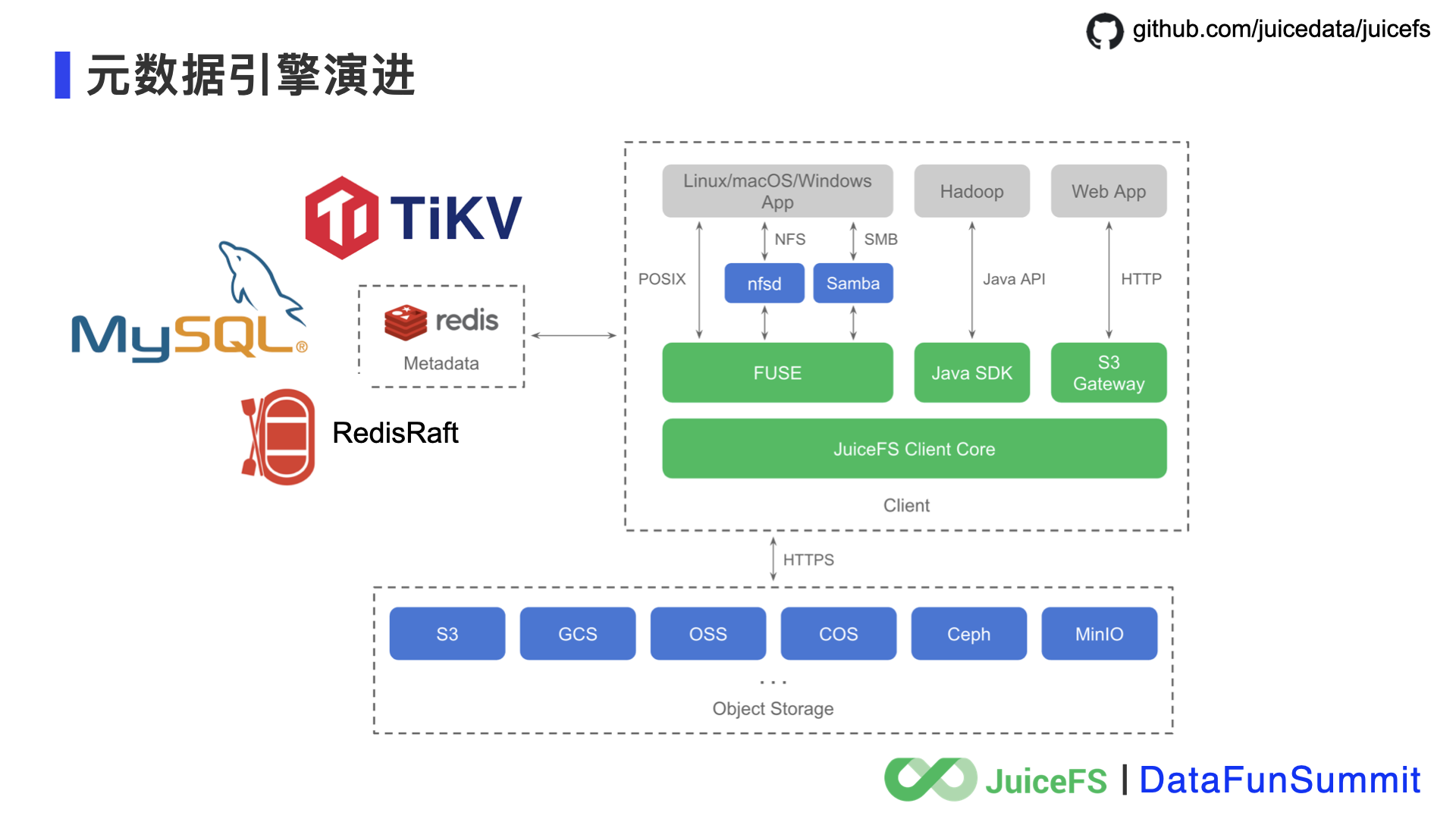
第二个创新是元数据管理,JuiceFS 在元数据管理上做了分析和抽象之后,明确了管理元数据的引擎所需要的能力,包括数据结构、事务能力、效率、扩展性和成本等。在这些方面找到一个简单、可靠、都满足的引擎并不容易,结合业务需求看往往也是可以取舍的,所以 JuiceFS 计划做支持多引擎的元数据管理服务。目前社区版选用了 Redis,因为它有合适的数据类型支持、事务能力、高效等优势,而且最重要的是它已经被广大开发者熟悉和信任,把它作为 JuiceFS 的元数据存储引擎,学习门槛就很低了。当然 Redis 也有自身的局限,JuiceFS 已经在社区中计划推出第二、第三款元数据引擎。
第三点讲客户端,在架构图的右上方。这里面包含了很多核心工作来实现文件系统各方面的能力。比如 GFS 和 HDFS 都是只能追加数据,不能修改数据,对象存储也存在同样的不足。JuiceFS 的目标则是做一个提供全功能的文件系统,要支持随机读写,很多的工作都是在客户端里实现的。今天的分享不展开讲,有兴趣的朋友请关注我们后续的分享,也可以在 GitHub 关注项目直接看代码 ;)

云原生环境中的业务挑战
下面讲讲我们和客户交流中遇到的几个普遍存在于云原生环境中的业务挑战。
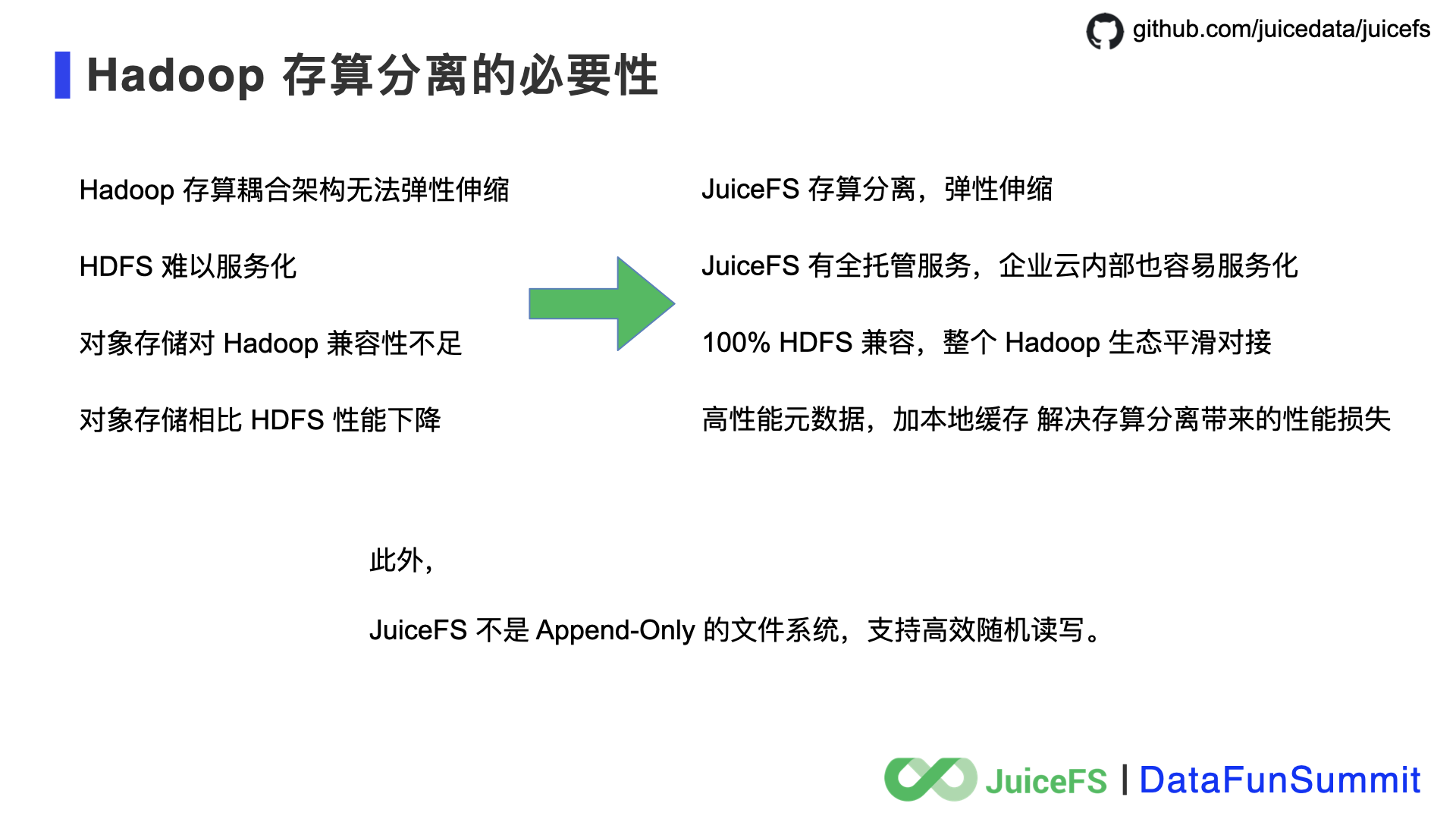
首先说 Hadoop 生态,在公有云上,标准的 Hadoop 架构已经不再适用,存储计算分离架构是必然趋势,有利于弹性伸缩,提升资源利用率,同时将资源调度迁移至 Kubernetes 也有利用和其它资源的统一管理。
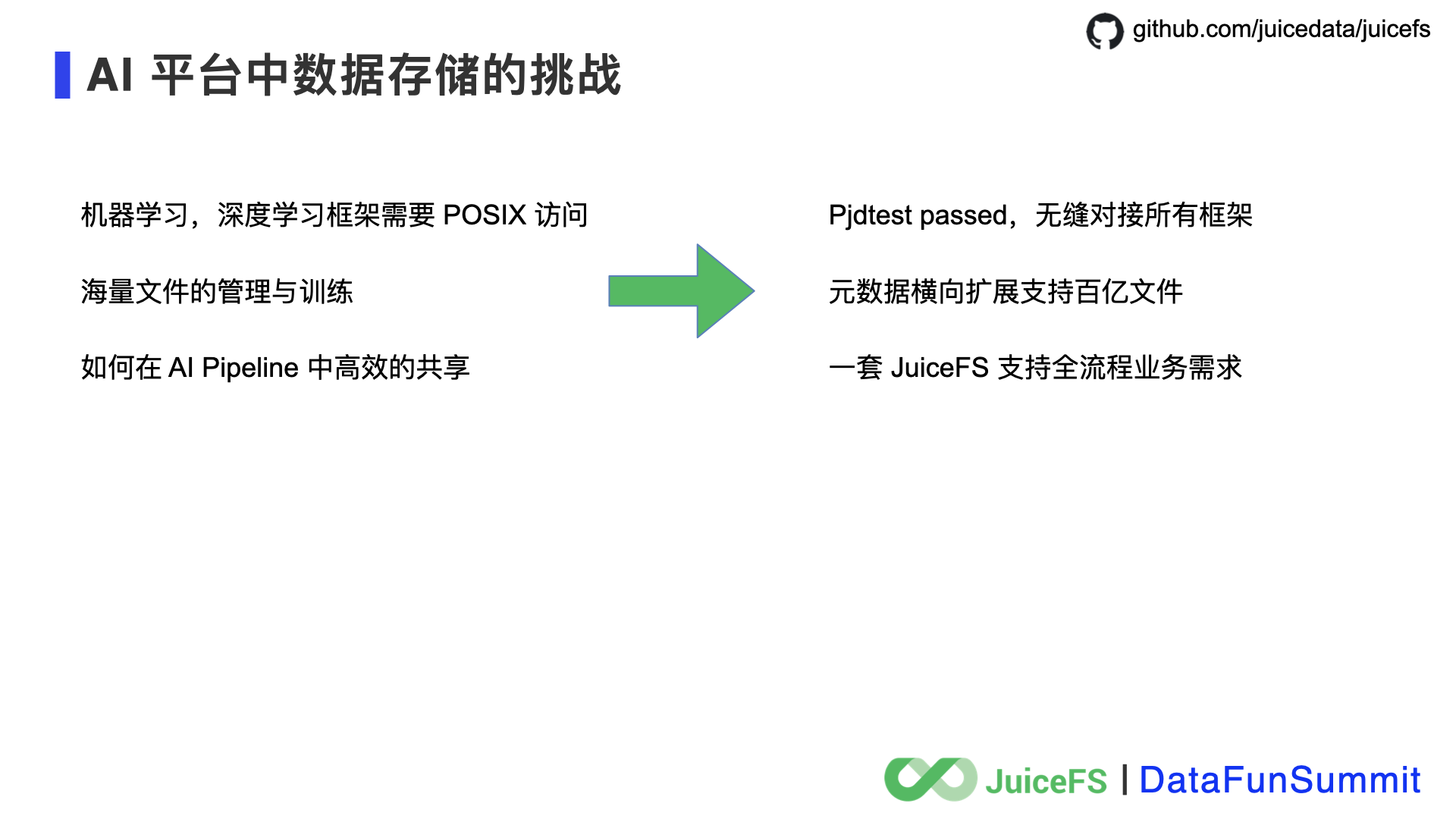
在 AI 业务中,POSIX 文件系统对深度学习框架的兼容性最好,对开发过程的支持也最简单易用,对 数据集、Checkpoint、日志、模型等数据的管理也最方便。如果有一套高性能的 POSIX 分布式文件系统,又能很好的管理起百亿规模的文件,无疑是 AI 业务中的一个利器。

再看看 Kubernetes 和存储的关系。现在 Kubernetes 已经成为了越来越多业务的资源管理和部署管理的基础,也是云原生环境中的基础。当 Spark 资源调度和管理迁移到 Kubernetes,当 Presto 查询引擎的管理迁移到 Kubernetes,当 AI 平台整体迁移到 Kubernetes,当大量的有状态应用要迁移到 Kubernetes,都要和数据打交道,都需要一个可靠的存储服务,文件存储一定是最普遍适用的方案。在 Kubernetes 中也有 PersistentVolume 和 CSI 驱动的定义来让存储以合适的方式在 Kubernetes 中使用。
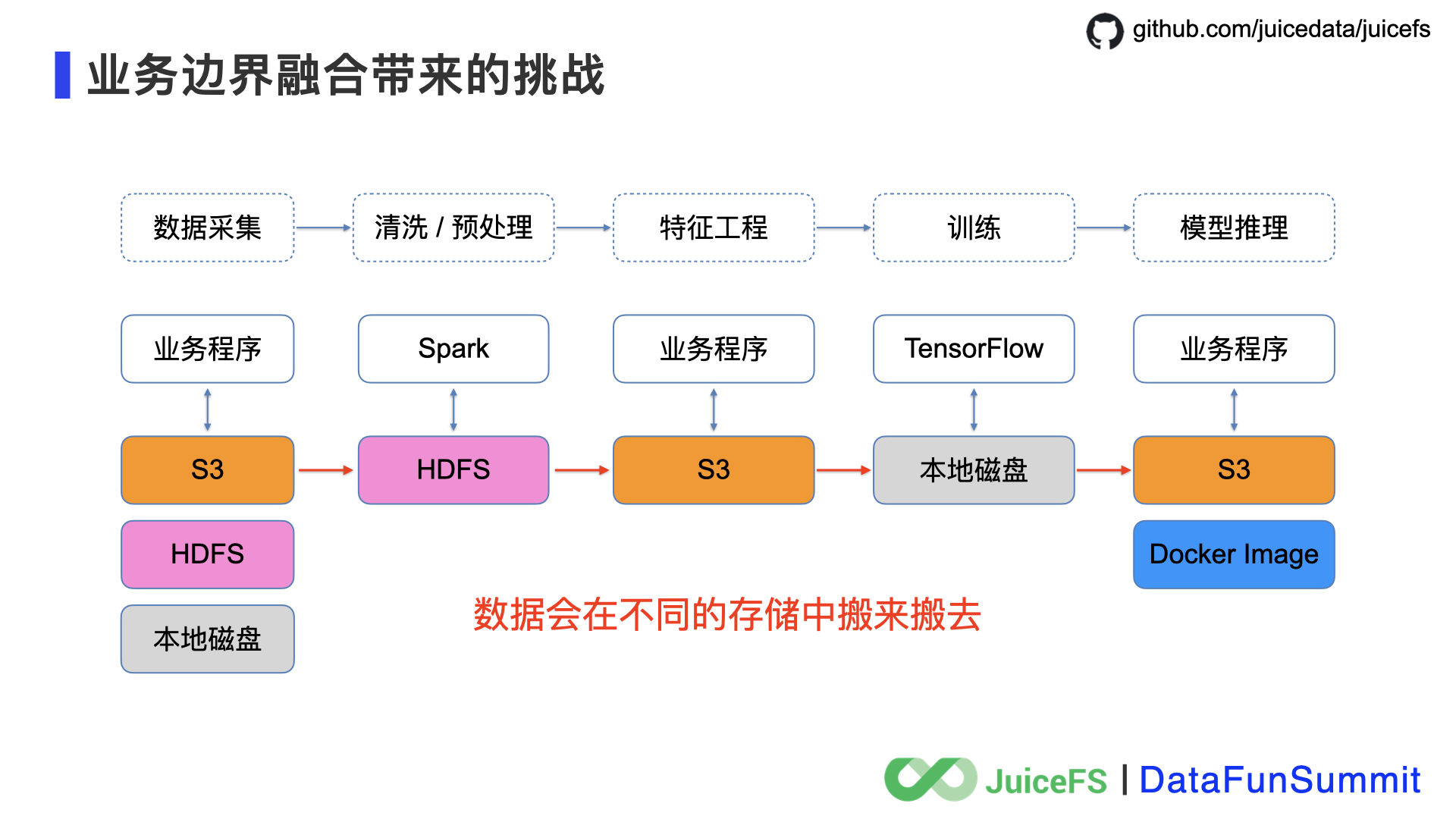
这里我举一个业务边界融合的例子 - AI 平台。AI 平台分为多个环节,每个环节都在和数据打交道,实际上就是一个 Data Pipeline,在过去的 AI 平台中,每个业务环节都按照自己的数据处理需求选择存储系统,从下图可以看出,在整个 Pipeline 中会涉及到多套存储系统,这样一来数据就要在不同业务环境上搬来搬去,同时还要运维多套系统,复杂度很高,工程效率低下。
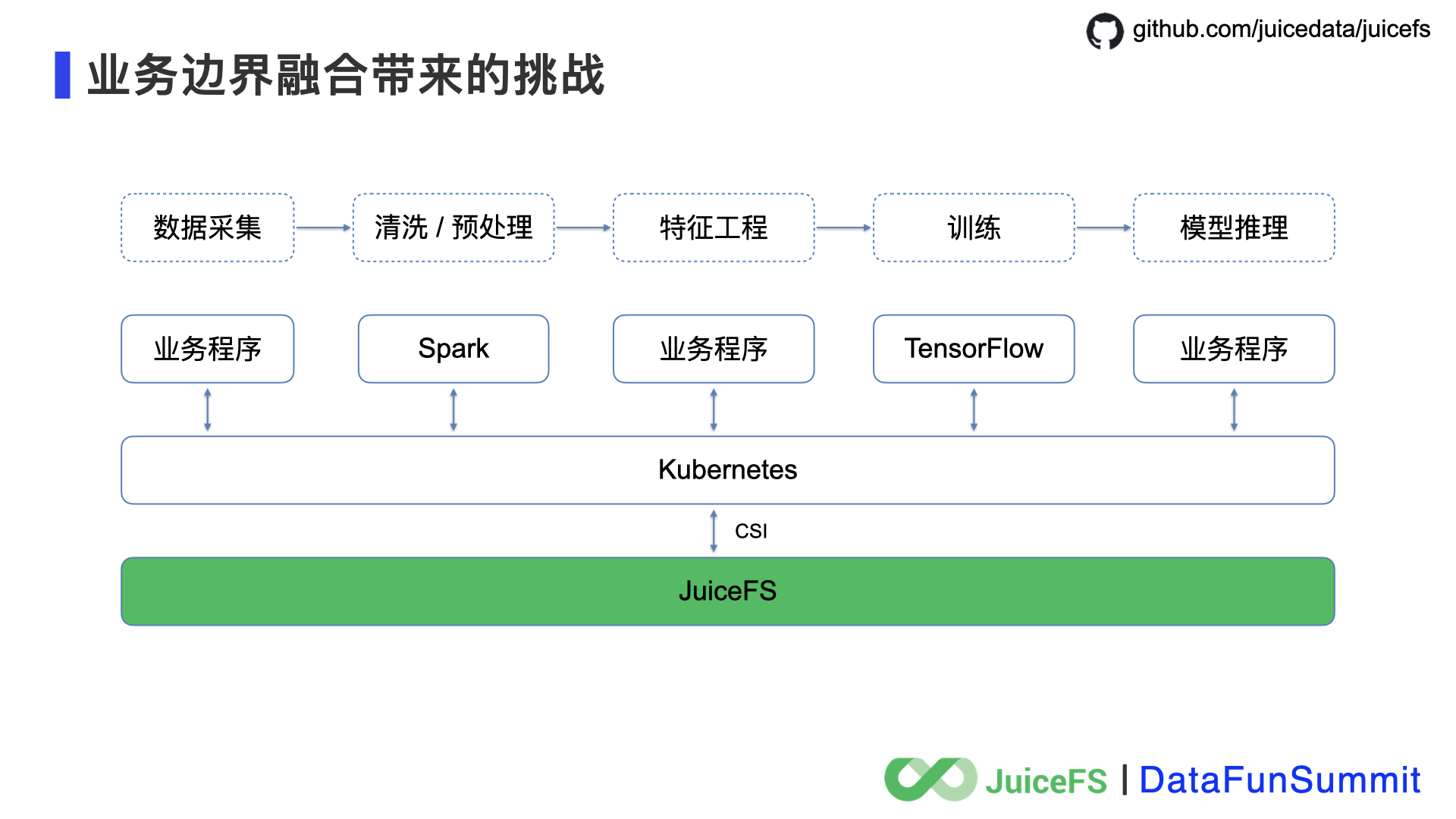
如果能将不同的存储系统统一起来是什么样子呢?JuiceFS 作为共享文件存储服务支持整个 Pipeline 中所有业务环节的需要,运维一套系统,数据不用搬家,学习和使用门槛低,效率提升。
展望
最后,我和大家一起展望一下 JuiceFS 的未来。
首先作为一个分布式文件系统,在 IT 架构中处在很底层的位置,很多开发者都不需要和存储打交道,更多的精力是放在数据库、计算引擎、业务服务上面。JuiceFS 的工作则是和上游的各种引擎、组件做好适配,提供最佳的用户体验、稳定可靠的 SLA、优越的性能,帮开发者解决存储层的后顾之忧。下面这张图列出了部分和 JuiceFS 对接过的引擎。

第二点我想讲一个可观测性,这是云原生设计理念中很重要的一环,也是容易被大家忽视的一环。大家比较熟悉的应该是在微服务中的可观测性,有时也叫 APM 服务,可以全链路的检测微服务系统的状态。但是在以前的存储服务监控中,往往只能看到存储服务的一些简单指标,比如吞吐是多少,IOPS 是多少,API 调用有多少等等,这样只能了解存储服务是快是慢,但是不知道为什么慢?慢在哪里?
JuiceFS 可以通过自身的日志和分析工具很清晰的展示出上层应用对存储的所有访问细节,每个接口访问的关系,消耗的时间,通过下面图形化的方式,一看就很容易发现到底是存储系统慢了,还是上层应用的调用存储 API 的方式错了,造成了阻塞。

最后,再讲一下 JuiceFS 元数据引擎演进的计划。在讲架构的时候已经提到, JuiceFS 的元数据管理已经做了很好的抽象,可以基于不同的存储引擎来实现。目前社区用户已经贡献了一些思路,比如:RedisRaft,MySQL,TiKV 等等,这些引擎在效率、可扩展性、吞吐能力、易维护性、成本等方面有着不同的特点,期待大家参与到 JuiceFS 的社区里,一起来探索!
我今天的分享就到这里,谢谢大家!欢迎各位到 GitHub 上关注 JuiceFS。
