














随着人工智能技术的爆发,内容生成式人工智能(AIGC)成为了当下热门领域。除了 ChatGPT 之外,文本生成图像技术更令人惊艳。
Stable Diffusion,是一款开源的深度学习模型。与 Midjourney 提供的直接将文本转化为图像的服务不同的是它允许用户自行搭配并训练自己的图像风格,这一特性吸引了众多的开发者。
也正因此,用户需要下载和安装模型数据来进行模型训练。模型数据是指用于训练和生成图像的数据集,它们通常占用很大的空间,并且需要经常更新和同步。模型文件小则几百 MB,大则几十上百 GB。如果用户在不同的计算机上使用 Stable Diffusion ,或者是团队进行共创,就需要在每台计算机上下载和安装相同的模型数据,这样既浪费时间又浪费空间。而且,如果用户没有及时备份模型数据,就有可能因为意外损坏或丢失而造成不可挽回的损失。
那么,有没有一种方法可以实现模型数据的持久化和共享存储呢?答案是肯定的。
本文将介绍如何使用 JuiceFS 云服务创建一个文件系统,让它可以像移动硬盘一样,在任何部署了 Stable Diffusion 应用的计算机上插上即可使用,特别是对于团队使用的情况,JuiceFS 的共享存储能力可以令多个设备共享同一份预训练模型数据。
一、JuiceFS 简介
JuiceFS 是一款面向云原生设计的高性能分布式文件系统,在 Apache 2.0 开源协议下发布。提供完备的 POSIX 兼容性,可将几乎所有对象存储接入本地作为海量本地磁盘使用,亦可同时在跨平台、跨地区的不同主机上挂载读写。
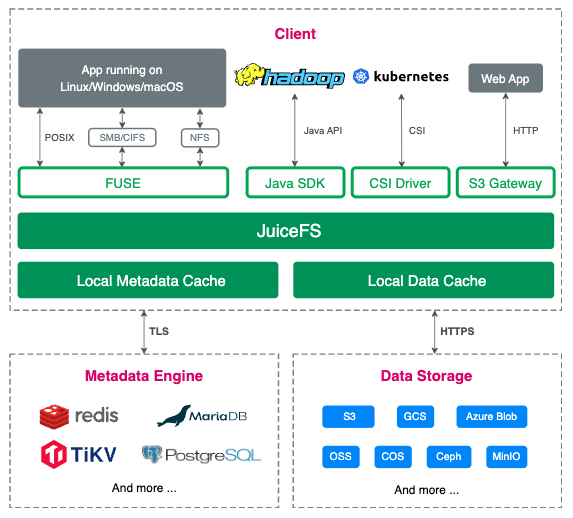
如图所示,JuiceFS 文件系统由元数据引擎和对象存储组成,元数据引擎用来存储文件名、大小、权限等元数据信息,对象存储用来存储文件的数据块。使用基于网络的对象存储和数据库创建 JuiceFS 文件系统,它就具备了跨平台、跨网络的共享访问能力。
为了解决对象存储和数据库的时延问题,JuiceFS 引入了缓存层,它会将频繁访问的数据缓存到本地,提升访问速度。缓存层可以根据用户的配置自动管理缓存空间和策略,保证数据的一致性和完整性。通过缓存层,JuiceFS 可以实现毫秒级的延迟和近乎无限的吞吐量。
JuiceFS 文件系统支持多种访问接口,包括 FUSE POSIX 挂载、S3 Gateway、CSI Driver、Hadoop HDFS API、WebDAV 等。既可以将 JuiceFS 挂载到本地像网盘一样使用,也可以通过专用接口将 JuiceFS 接入到特定平台使用。
二、使用 JuiceFS 创建共享存储
JuiceFS 有开源的社区版和付费的云服务版,它们的核心架构是一致的,区别在于社区版所需的数据库和对象存储均需要用户自行搭建,而云服务使用 JuiceFS 官方提供的数据库,同时提供了更多高级功能。使用 JuiceFS 云服务版,用户只需自备对象存储,在 JuiceFS 官网创建文件系统即可,整体会更简单方便。
因此本文会直接采用 JuiceFS 云服务。对于想尝试上手的用户不用担心它的费用,创建一个 1TB 容量的文件系统目前是免费的。
说明:JuiceFS 云服务价格方案中的容量是指用户在平台上可以创建的文件系统的最大容量。一个文件系统由平台提供的数据库和用户自备的对象存储组成,用户通过 JuiceFS 客户端访问和读写文件系统,文件数据实际上是存储在用户自己的对象存储中的。换言之,免费档支持创建一个 1TB 的文件系统,就是指这个文件系统最多可以向用户的对象存储中存入 1TB 的数据。
创建文件系统
访问 JuiceFS 官网 https://juicefs.com,注册并登录到云服务后台。
点击“创建文件系统”按钮,填写信息并创建文件系统。
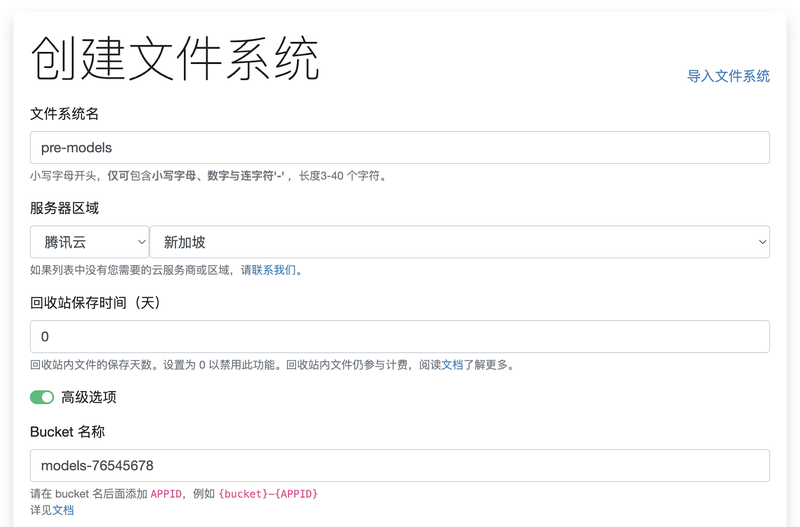
创建文件系统主要涉及以下选项:
- 文件系统名称:根据格式要求设置,名称需要平台唯一;
- 服务器区域:如果你的 Stable Diffusion 安装在云服务器上,那么就选择你所使用的云平台及所在的区域。如果你在本地电脑上安装使用 Stable Diffusion 则选择你的对象存储所在的云平台及区域。
- 回收站保存时间:这是 JuiceFS 的数据安全机制,开启回收站后,文件不会立即删除而是根据设置的时长继续保留在对象存储中,超期后才会实际删除。对于 Stable Diffusion 模型数据存储的场景,可以设置 0 关闭回收站。
- Bucket 名称:即用户自备对象存储的桶名称,你可以提前在云平台上创建存储桶,然后把桶名称填写在这里,也可以在稍后挂载 JuiceFS 文件系统时由客户端自动创建。
- 其他选项:保持默认即可
安装客户端并挂载文件系统
文件系统创建完成以后,会自动跳转到“设置”页面。现在,你可以在任何需要使用这个文件系统的计算机上执行以下命令安装客户端:
sudo curl -L https://juicefs.com/static/juicefs -o /usr/local/bin/juicefs && sudo chmod +x /usr/local/bin/juicefsJuiceFS 是基于云的文件系统,免费档支持 100 台设备同时挂载使用,也就是说,你现在就可以在任意一台电脑上挂载并使用它,存入 Stable Diffusion 模型数据,然后在其他同样需要使用这些模型数据的服务器上同时挂载这个文件系统,让你所有的设备都能共享使用同一份预训练模型。
提示:JuiceFS 云服务版目前仅支持 macOS 和 Linux 系统,如果你希望在 Windows 系统上使用,可以通过 WSL 进行使用。你也可以尝试 JuiceFS 社区版,详情参考社区版文档。
三、使用 Stable Diffusion 访问共享存储
准确来说,Stable Diffusion 并不是一个单一的软件,而是一系列开放源码的 AI 模型。要想使用这些模型来生成图像,就必须先安装或访问可以运行模型的程序或平台,比如基于网页的 Stable Diffusion web UI、桌面版的 DiffusionBee、iPad 适用的 Draw Things 等。
如果你不想为了 AI 作图预先投入大量资金在电脑硬件上,可以考虑使用云计算平台提供的 GPU 云服务器,一些抢占式实例每小时单价可能低至几元。下图是一台抢占式实例,它拥有 8 核 CPU、32GB 内存、100GB SSD 硬盘和一块 NVIDIA Tesla T4 显卡(16GB GPU),单位价格相对较低。但抢占式实例的特点是会在平台上出现更高的出价者时,服务器会被自动释放销毁,所以在使用这种云服务器时要格外注意模型数据的保存。
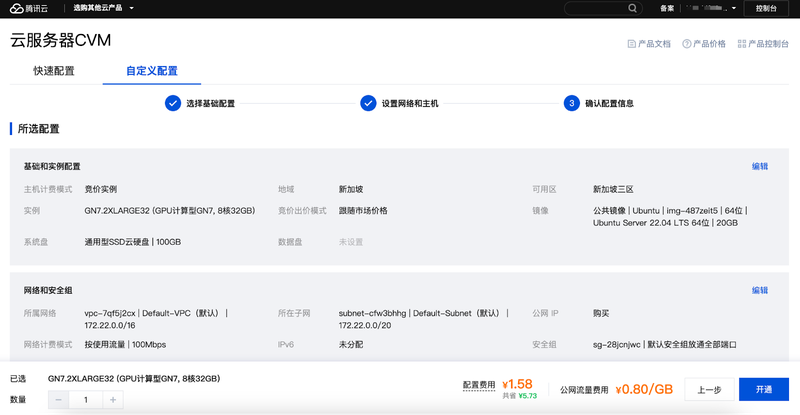
接下来就以 GPU 云服务器为例,介绍如何安装 Stable Diffusion web UI。稍后你会发现,对于这种使用 Stable Diffusion 的方式而言,JuiceFS 的共享访问特性简直是如虎添翼。
安装 Stable Diffusion web UI
这里假设在腾讯云创建了一个上述配置的 GPU 云服务器,它使用 Ubuntu 22.04 系统。首先需要安装依赖的软件包和 NVIDIA 显卡驱动:
# 安装依赖
sudo apt install build-essential libgl1 dkms
# 切换至 root 用户
su
# 下载驱动(请到 NVIDIA 官网查找最新版链接,这里只是一个示例)
wget https://cn.download.nvidia.com/tesla/460.106.00/NVIDIA-Linux-x86_64-460.106.00.run
# 安装显卡驱动
sh NVIDIA-Linux-x86_64-460.106.00.run --ui=none --disable-nouveau --no-install-libglvnd --dkms -s
# 检查驱动是否安装成功(返回显卡信息代表安装成功)
nvidia-smi显卡驱动安装完毕,建议重启系统。然后,以普通用户身份安装 Stable Diffusion web UI 程序。
# 安装项目依赖
sudo apt install wget git python3 python3-venv
# 安装 Stable Diffusion web UI
bash <(wget -qO- https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.sh)运行 Stable Diffusion web UI
Stable Diffusion web UI 安装在Python venv 虚拟环境中,因此,在启动之前需要先激活虚拟环境。
# 激活虚拟环境
source venv/bin/activate
# 启动程序
python webui.py – –listen程序启动成功以后,就可以通过浏览器访问了,假设云服务器的 IP 地址为 111.222.33.44,则访问地址为 111.222.33.44:7860。
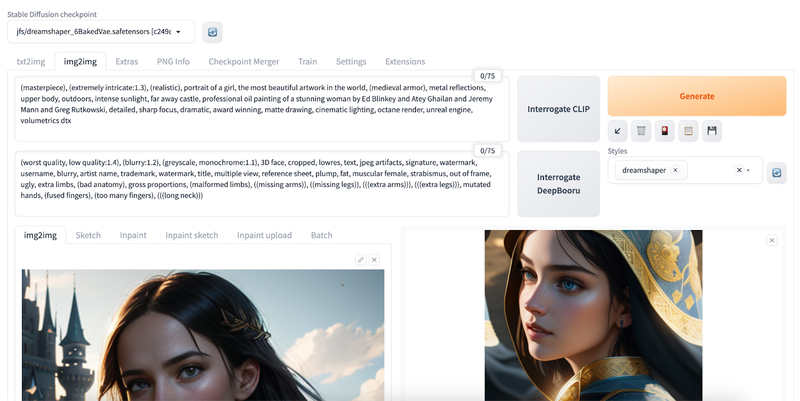
用 JuiceFS 存储模型
Stable Diffusion web UI 的模型文件位于 models 目录,根据类型把模型文件放到对应的文件夹即可,比如在 civitai 网站下载的 checkpoint 类型的模型就放到 models/Stable-diffusion 目录,而 VAE 模型则放到 models/VAE 目录。

了解了保存模型的目录结构,接下来就可以把 JuiceFS 文件系统挂载到模型目录了,回到 JuiceFS 官网控制台,打开文件系统的“设置”选项卡,如下图所示。
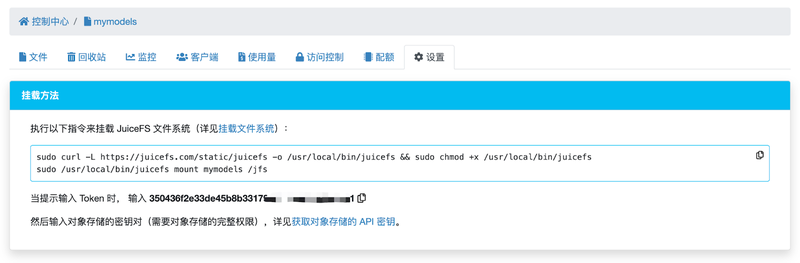
先将 JuiceFS 文件系统挂载到当前用户的 $HOME/jfs 目录,挂载过程中程序会询问文件系统的 token 以及对象存储 Access Key 和 Secret Key,根据提示输入即可。
sudo /usr/local/bin/juicefs mount mymodels $HOME/jfs提示:请将挂载命令中 mymodels 替换成你的文件系统名,最后的挂载点路径也可以替换成你想要的路径。
文件系统挂载成功以后,你现在可以把 $HOME/jfs 当作网盘来使用了,所有存入这个目录的文件都会保存到关联的对象存储中。与此同时,你可以在其他电脑上安装 JuiceFS 云服务客户端,执行相同的挂载命令,共享读写其中存储的文件。
你可以把所有预训练模型都拷贝到 $HOME/jfs 目录,不过,为了科学管理不同类型的模型,建议在 $HOME/jfs 中建立与 models 目录对应目录结构,比如创建一个 SD 目录专门存储 Stable-diffusion 适用的模型,建一个 VAE 目录存储 VAE 模型,再创建一个 Lora 目录存储 Lora 相关的模型,依此类推。
在 JuiceFS 文件系统中根据模型类别创建目录对之后的使用会很有帮助,这便于使用 JuiceFS 的子目录挂载功能将特定的目录挂载到 models 下对应的子目录中,从而避免修改项目配置调整读取模型的位置。可以使用 JuiceFS 的子目录挂载功能,也可以使用软连接将子目录映射到 Stable Diffusion 模型目录中。
比如,可以将 SD 目录挂载到 $HOME/stable-diffusion-webui/models/Stable-diffusion/jfs,将 VAE 目录挂载到 $HOME/stable-diffusion-webui/models/VAE/jfs 等。
注意:这里假设 Stable Diffusion web UI 部署在 $HOME 目录,请根据实际信息替换子目录、挂载点路径和文件系统名称。
# 挂载子目录 SD 到 models/Stable-diffusion/jfs
sudo juicefs mount mymodels --subdir SD $HOME/stable-diffusion-webui/models/Stable-diffusion/jfs
# 挂载子目录 VAE 到 models/VAE/jfs
sudo juicefs mount mymodels --subdir VAE $HOME/stable-diffusion-webui/models/VAE/jfs同样地,也可以使用软连接来将 JuiceFS 的目录映射到模型目录:
# 假设文件系统挂载在 $HOME/jfs
ln -s $HOME/jfs/SD $HOME/stable-diffusion-webui/models/Stable-diffusion/jfs挂载成功以后,在应用界面的左上角点击刷新按钮即可看到所有可用的模型,如下图所示。
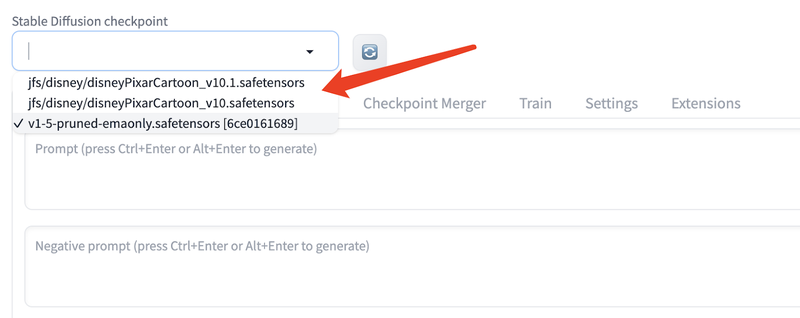
不要忘记,JuiceFS 是共享文件系统,使用同样的挂载方式,你可以把模型数据挂载到其他云服务器或本地电脑上。
四、训练自己的 Stable Diffusion 模型
除了使用预训练模型开箱即用的“文生图”、“图生图”功能以外,Stable Diffusion 的另一大优势就是可以通过任意基础模型训练自己的模型。
Stable Diffusion 做模型训练的常用方式主要有以下几种:
- • 全模型微调:用新数据集进一步训练基础模型,可以保持基础模型能力,同时提升模型的质量和效果。但需要更多的时间和资源,也可能导致模型过拟合或欠拟合。
- • Lora 微调:为基础模型注入低秩矩阵,让模型能够适应新的数据和任务,可以简单的理解为给基础模型“打补丁”。优点是节省时间和计算资源,不会破坏基础模型的能力。但这种方式也需要更多数据和训练技巧,基础模型的能力可能会成为它的局限。
- • DreamBooth 微调:使用少量特定主题图片对基础模型进行微调,产生一个可以独立使用的新模型。优点在于只需要准备少量的训练图片,但可能导致新模型失去基础模型的特点或能力。
- • 文本反转:效果与 DreamBooth 原理类似,但实现方法不同。同样是让模型学会新的主题或风格,最终产生需要与基础模型一起使用的文件。缺点是在使用时需要通过特定的关键词来激活新训练的概念。
这里以 DreamBooth 为例介绍如何在 Stable Diffusion web UI 中进行微调训练。
DreamBooth 的原理

如上图所示,DreamBooth 的原理是用 3~5 张特定主题(比如一只小狗不同角度)照片对 Stable Diffusion 的基础模型进行训练,从而让模型掌握这个特定的对象(比如,一只名为“Lafa”的狗)的特征。然后用“a Lafa dog in a bucket”(一只在桶里的 Lafa 狗)作为提示词,模型就会生成这只小狗在桶里的照片。也就是说,只要提示词中使用“a Lafa dog”,他就会直接使用这只小狗的特征来作图,而不是随机生成一只其他的狗。
在 Stable Diffusion web UI 中使用 DreamBooth
Stable Diffusion web UI 默认没有安装 DreamBooth 扩展,需要在 extensions 中搜索并安装。
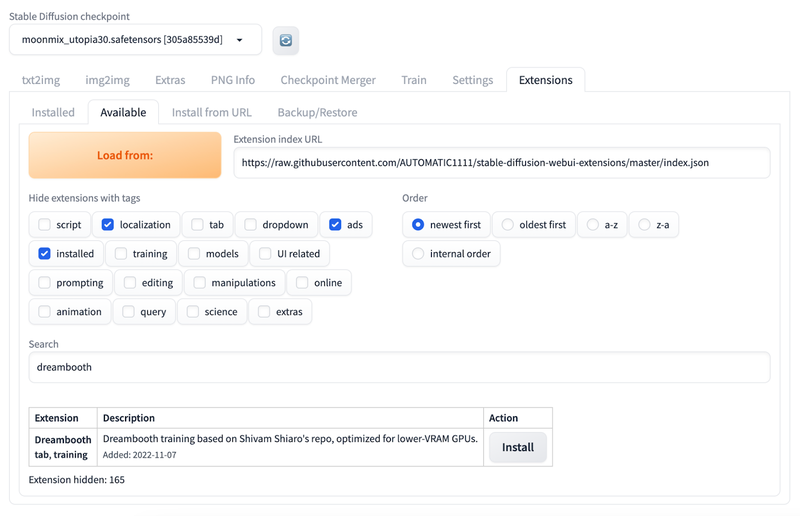
安装完成后,切换到 Installed 选项卡,点击 Apply and restart UI 按钮。如果仍然没有显示 DreamBooth 的选项卡,则需要重启 Stable Diffusion web UI。
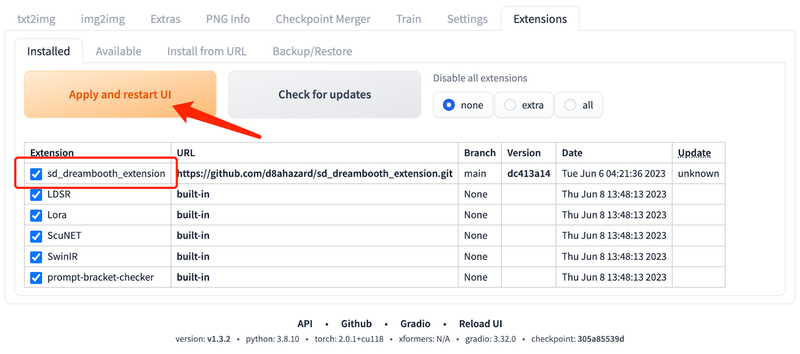
初次用 DreamBooth 微调,需要先创建一个新模型,如下图所示,输入新模型的名称,并选择基础模型。创建新模型需要一定的时间,具体取决于硬件配置。
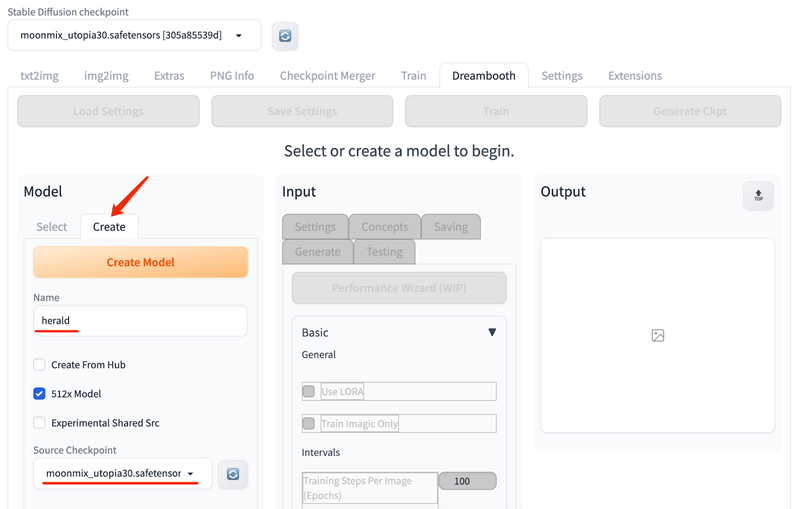
现在重新选中刚刚新创建的模型,我们要对它进行微调训练。将准备好的照片放到 Stable Diffusion web UI 能够读取到的位置。
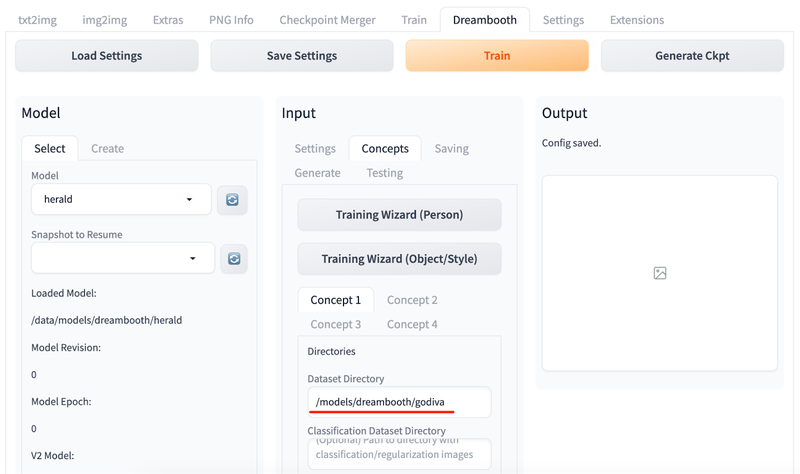
然后在 Input 部分的 Concepts 选项卡中添加所准备照片的实例提示词、类别提示词以及反向提示词,另外还应该根据硬件配置调整训练的轮次、算法等设置。
值得注意的是,在准备用于训练模型的图片时应该选择一个人或物体不同角度的照片,尽量保证主体特征清晰没有遮挡,数量在 3~5 张即可,图片尺寸要保持与训练参数设置的规格一致,默认为 512x512 像素。
设置就绪,点击 Train 开始训练,具体的训练时长取决于所采用的硬件和训练周期等参数的设置。
默认情况下,训练时模型数据会自动写入新创建的模型,你可以随时切换到“文生图”检查模型的效果,在训练完毕后,可以点击 Generate Ckpt 按钮将模型保存成 .ckpt 模型文件。
如下图所示,我用 5 张巧克力盒子作为输入,训练了一个名为 godi_box 的物体,只要在 Prompt 中使用这个关键词,他就会在场景中生成这个盒子。
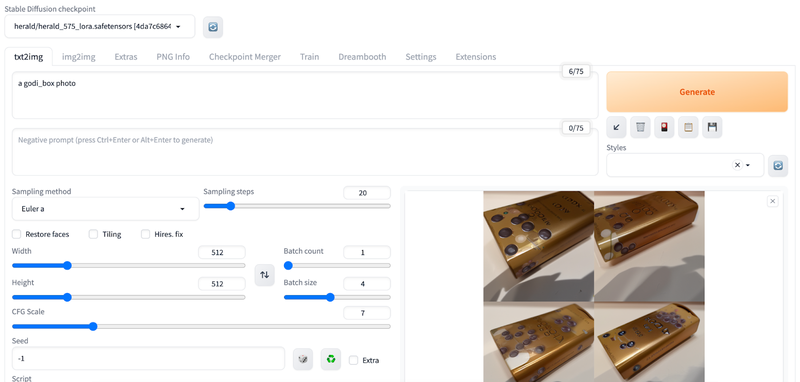
同样地,使用 DreamBooth 训练的模型位于 models/dreambooth 目录,你可以用前面介绍的方法在 JuiceFS 文件系统中提前创建 DreamBooth 目录并挂载到 Stable Diffusion 中。
# 挂载子目录 dreambooth 到 models/dreambooth
sudo juicefs mount mymodels --subdir dreambooth $HOME/stable-diffusion-webui/models/dreambooth五、总结和提示
本文介绍了如何使用 JuiceFS 云服务创建一个共享存储,实现 Stable Diffusion 预训练模型数据的共享使用。JuiceFS 是一款面向云原生设计的高性能分布式文件系统,它可以将几乎所有对象存储接入本地作为海量本地磁盘使用,亦可同时在跨平台、跨地区的不同主机上挂载读写。JuiceFS 为 Stable Diffusion 提供了一种高效、可靠、易用的共享存储方案,解决了模型数据存储的难题。
在使用 JuiceFS 和 Stable Diffusion 的过程中,有一些注意事项和提示,我们在这里简要列举如下:
- 对象存储的存储和流量费用:使用 JuiceFS 时,用户需要自行承担对象存储的存储和流量费用,特别是跨网络使用的下行流量费用,以及读写请求费用。建议用户尽可能使用与云服务器相同平台、相同区域的对象存储,从而充分利用平台的内网线路节约开销。对于使用本地电脑的用户,对象存储建议选择与自己物理距离近的地区,同时可以选用云平台的存储包、流量包、请求包等资源来降低使用成本。
- JuiceFS 的缓存空间和策略:JuiceFS 会将频繁访问的数据缓存到本地,提升访问速度。用户可以根据自己的需求和硬盘空间来配置缓存空间和策略,如设置缓存大小、缓存有效期、缓存清理策略等。具体的配置方法可以参考 JuiceFS 的文档。
希望本文能够帮助您更好地使用 Stable Diffusion 来创作自己的数字艺术作品。如果您有任何问题或建议,欢迎联系我们。感谢您的阅读和支持。
