














以下文章来源于微信公众号 apachekylin ,作者苏锐/俞霄翔
Apache Kylin 4.0 采用 Spark 作为构建引擎以及 Parquet 作为存储,让云上部署和伸缩变得更容易,然而使用云上的对象存储相较于使用本地磁盘的 HDFS,可能存在部分兼容性和性能问题。面对这样的问题,今天为大家带来 JuiceFS 的优化方案。Kylin 4.0 的强大查询引擎加上 JuiceFS 高效的本地缓存,就能实现兼容性和性能的双赢!想了解更多详情,快看这篇 Kylin 和 Juicedata 联合出品的实用好文吧!
作者简介
苏锐,Juicedata 合伙人,在互联网行业工作超过十五年,参与创建国内首个完全架构在公有云上的分布式文件系统 JuiceFS,客户覆盖国内数十家科技企业,并在运营商、证券、能源、航天、广电等多个领域交付存储容量近百 PB。
俞霄翔,Kyligence 高级工程师,Apache Kylin Committer & PMC。
什么是 Apache Kylin?
Apache Kylin 是一个为超大规模数据设计的、开源的、分布式的分析引擎,提供 Hadoop/Spark 之上的 SQL 查询接口及多维在线分析(OLAP)能力,最初由 eBay 开发并贡献至 Apache 软件基金会,面对海量数据,Kylin 也能实现亚秒级的查询响应。
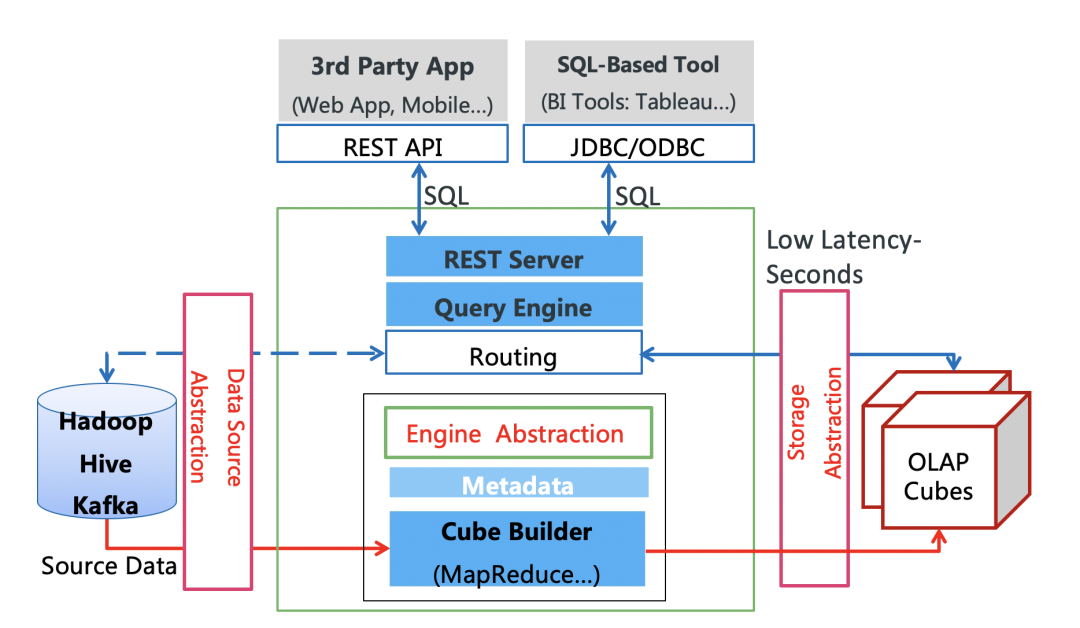
作为一个超高性能的查询引擎,Kylin 可以下接各种数据源,如 Hive、Kafka,上接各种 BI 系统,比如 Tableau、Superset,还提供 JDBC/ODBC/REST API 等供各种应用集成。自开源以来,Kylin 已经得到大量使用,例如美团、小米、58 同城、贝壳找房、华为、汽车之家、携程、同程、Vivo、雅虎日本、OLX Group 等,每日访问量从几万到上千万不等,大部分查询能够在 1-3 秒内完成。
如果你的产品/业务方找到你,说需要在几十亿甚至上百上千亿的记录上做灵活汇总查询,响应要快,并发要高,同时资源占用要少;为了支持应用开发,它还要完整支持 SQL 语法并且能够无缝集成 BI,那么 Apache Kylin 就是你的不二选择。
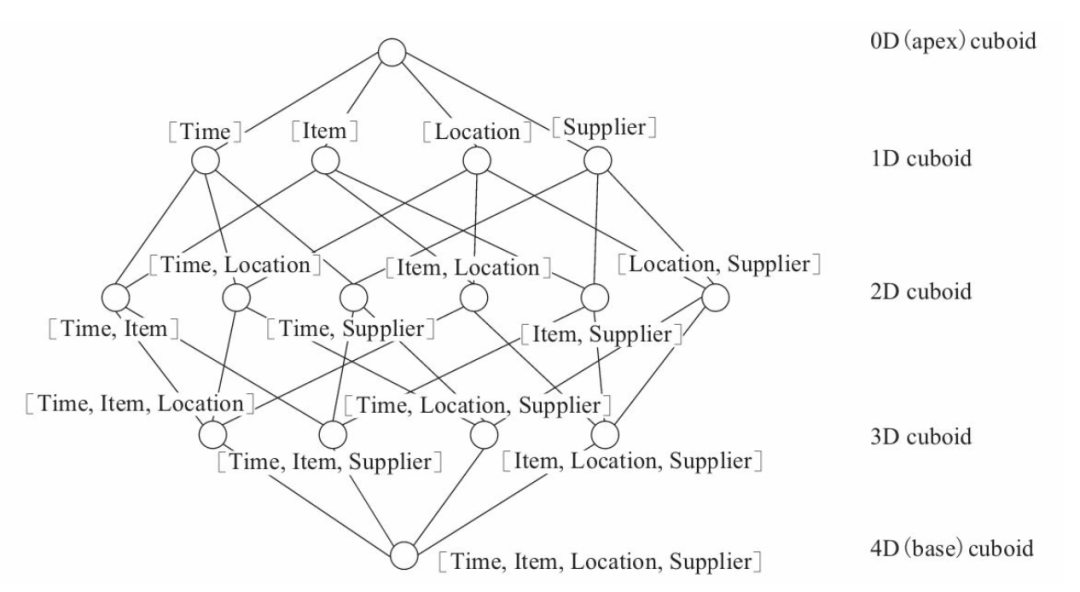
Kylin 的核心思想是预计算,将数据按照指定的维度和指标,预先计算出所有可能的查询结果(也就是 Cube,多维立方体),利用空间换时间来加速查询模式固定的 OLAP 查询。每一种维度组合称之为 Cuboid,所有 Cuboid 的集合是一个 Cube。其中由所有维度组成的 Cuboid 称为 Base Cuboid,其它的 Cuboid 都可以从 Base Cuboid 二次聚合出来。在查询时,Kylin 会自动选择满足条件的最合适的 Cuboid,相比于从用户的原始表进行计算,从 Cuboid 取数据进行计算能极大的降低扫描的数据量和计算量。
Kylin 从诞生之初选择了 HBase 作为存储引擎,基本满足查询性能的要求;然而基于 HBase 方案存在一系列痛点,例如 HBase 运维复杂、查询节点存在单点问题、HBase 并非纯列式存储 IO 效率不高等。Apache Kylin v4 采用 Parquet + Spark 的组合,不再使用 HBase,使得计算和存储相分离,是一次重大架构升级,更加适应云原生的技术趋势。
{{ }}
}}
Kylin on Parquet 在云上面临的挑战
相比以前,基于新一代的 Kylin 4,用户可以在云上更加快速简单地部署高性能、低 TCO 的的数据分析服务。计算和存储的分离,以及架构复杂性的降低,都使得 Kylin 成为云上数据分析的最佳选择之一。但是在云上基于对象存储抽象而来的文件系统和传统的 HDFS 的巨大差异,带来了一系列需要关注的问题,例如数据本地性、对象存储 API 调用频次限制、数据移动操作的一致性难以保证等,给 Kylin 构建和查询带来了一些稳定性和性能方面的挑战。关于如何缓解乃至达到原生 HDFS 的优秀性能体验,我们可以看到一些成功的解决方案,JuiceFS 就是其中之一。
什么是 JuiceFS?
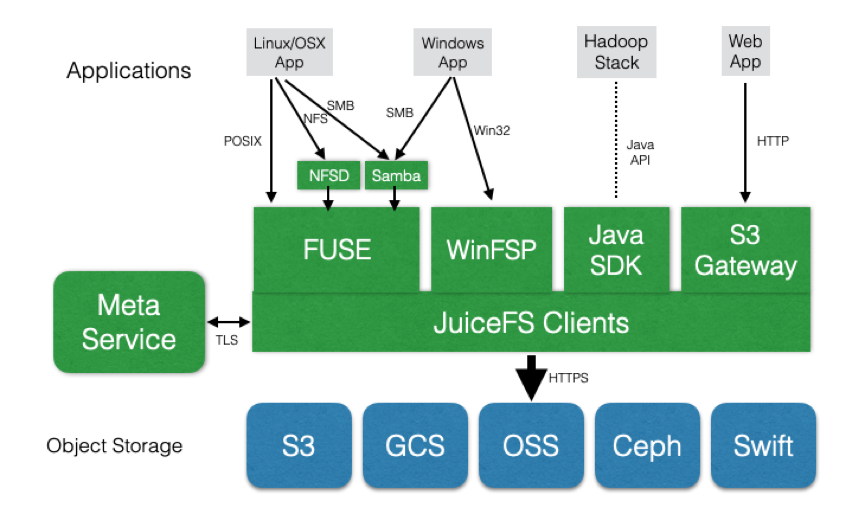
JuiceFS 是面向云原生环境设计的分布式文件系统,完全兼容 POSIX 和 HDFS,适用于大数据、机器学习训练、Kubernetes 共享存储、海量数据归档管理场景。支持全球所有公有云服务商,并提供全托管服务,客户无需投入任何运维力量,即刻拥有一个弹性伸缩,并可扩展至 100PB 容量的文件系统。
在下面的这张架构图中可以看出,JuiceFS 已经支持各种公有云的对象存储产品,同时也支持了开源对象存储,如 Ceph、MinIO、Swift 等。在 Linux 和 macOS 上提供 FUSE 客户端,在 Windows 系统上也提供原生客户端,都可以将 JuiceFS 的文件系统挂载到系统中,使用体验和本地盘一模一样。在 Hadoop 环境中提供 Java SDK,使用体验和 HDFS 一样。JuiceFS 的元数据服务在所有公有云上都部署了全托管服务,客户不用自己维护任何服务,学习和使用门槛极低。
为什么 Kylin 和 JuiceFS 要一起使用?
如果客户在公有云上使用 Kylin,并且希望将数据存储在对象存储上,会遇到两个问题:
首要问题是兼容性,Kylin 默认支持 HDFS 和 Amazon S3,其他的公有云也都提供了 “S3 兼容” 的对象存储,但是在实际的测试中我们发现,目前除了 AWS 和 Azure,其他公有云的对象存储存在不兼容的情况,比如我们在阿里云上基于 OSS 运行 Kylin,无论是基于阿里云 EMR 和 CDH 自建集群,都会在 Cube 构建阶段失败。
第二个问题是性能,从用户角度看在大数据场景下由 HDFS 换成对象存储,能感受到的是性能下降。造成性能下降的原因有几个:
- 网络开销增加:用 HDFS 做存储有 data locality 特性,换成对象存储后数据传输全部要经过网络,会增加一定的开销,导致性能下降;
- 元数据性能下降:在 Cube 构建过程中有大量文件元数据操作,尤其是 Listing 和 Rename,这两个操作在对象存储上的性能相比 HDFS 是很差的,会导致整个 job 的时间消耗增加,导致性能下降;
- 读放大带来的性能下降:当 Kylin 的数据换成 Parquet 文件格式后,数据查询时,往往不需要读出完整的 Parquet 文件,仅需要读取 header 或 footer,这需要存储系统提供良好的随机读能力,这恰恰是对象存储的短板,所以会造成读放大,增加了整个查询任务的 I/O,导致性能下降。
JuiceFS 在大数据场景中可以彻底解决兼容性和性能问题,下面说说是怎么做到的。
首先说兼容性,JuiceFS 的元数据服务提供一个 Java SDK,它的作用和 HDFS 的 Java SDK 是等价的,实现了 HDFS 所有文件接口 API 的 Interface,在行为上保证和 HDFS 一致,只要是支持 HDFS 的计算引擎都可以使用 JuiceFS,不会有任何兼容性问题。而且,JuiceFS 支持全球所有的公有云服务,提供一致的体验,用户完全不用再关心不同云厂商对象存储的差异性。
其次说性能,解释一下 JuiceFS 如何解决上面三个方面带来的性能下降:
- 使用 JuiceFS 的计算集群也是存储计算分离架构,同样失去了 HDFS 的 data locality 特性,但是 JuiceFS 在客户端上提供了数据缓存能力,所有从 JuiceFS 读出来的数据会自动缓存到客户端所在节点(虚拟机或容器都可以)的本地存储上,下次再访问这份数据,就会直接从本地存储中读取,不再经过网络。在大数据的查询分析场景中,数据通常是有热点的,在 JuiceFS 缓存的支持下,可以明显提升性能(见下文测试结果)。您可能还会关心缓存的管理、过期、一致性问题,JuiceFS 有一套完整的处理机制,值得单独一篇文章讲讲,本文不做展开。
- 元数据性能,JuiceFS 有自己独立的元数据服务,Listing、Rename 操作都由 JuiceFS 元数据响应,性能方面比对象存储快几十倍,相比 HDFS 也提升了 50% 以上,具体可以参看 JuiceFS的测试用例。
- JuiceFS 的缓存能够有效地降低随机读的延迟并减少读放大,在基于 Parquet 和 ORC 数据格式的查询分析场景有非常明显的性能优势。
综上,JuiceFS 可以获得与 HDFS 相当的性能表现,同时对 Hadoop 生态的产品提供完美的兼容性支持。更重要的一点是,无论客户使用哪家公有云,都可以使用 JuiceFS,获得一致的体验。
性能比较
上面解释了 Kylin on Parquet 和 JuiceFS 一起使用能获得的收益,下面来看一下性能测试的结果。
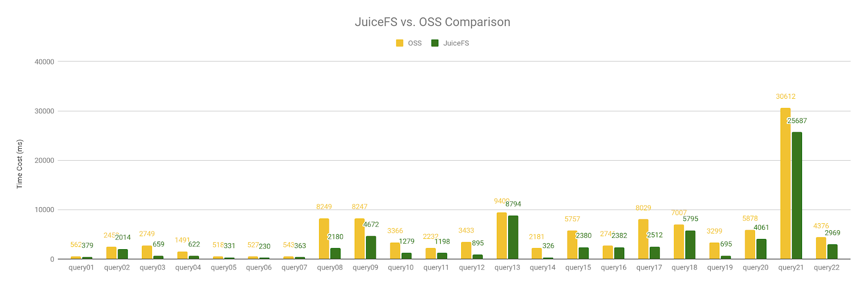
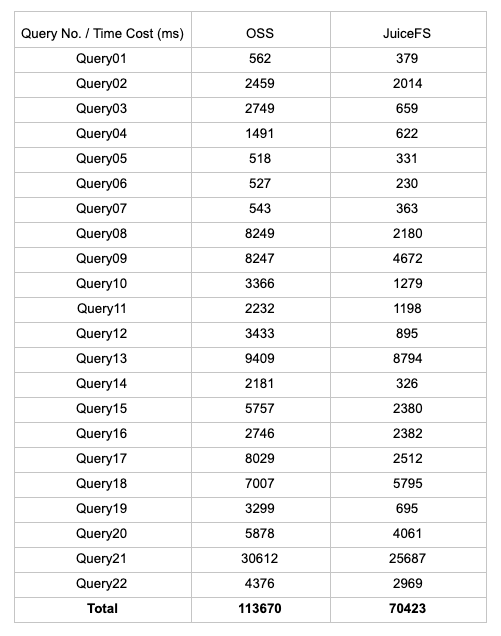
前文提到基于 OSS 做 Cube 构建出现兼容性问题,无法正确构建 Cube。但是我们把 JuiceFS 上构建好的 Cube 数据拷贝到 OSS 上执行 Query 是可以的,所以我们基于 TPC-H 10GB 大小的数据集,测试了其中的 Query1 至 Query22,在总的执行时间上 JuiceFS 比 OSS 快了 38%。
- JuiceFS 使用 70,423ms
- OSS 使用 113,670ms
下表给出详细的测试环境配置和所有测试 Query 执行时间:
机器配置

在阿里云上使用 CDH 5.16 搭建集群,详细配置和软件版本如下:

所有测试查询执行时间
总结
Kylin 4.0 引入计算和存储分离的架构,使得 Kylin 在云上的部署和伸缩变得更加容易,然而使用云上的对象存储相较于使用本地磁盘的 HDFS ,一方面存在对接开发以及兼容性问题,另一方面性能会有所下降。使用 JuiceFS 搭配 Kylin,在所有公有云上都无需特殊适配,即可在 EMR 或者自建 Hadoop 集群中使用云存储服务进行大数据计算。JuiceFS 让你的集群实现存储计算分离架构的同时,通过高效的本地缓存减少每次网络 IO 带来的开销,在基于 Parquet 格式的查询分析场景中,对于随机读可以有效降低延迟,并减少读放大,获得跟 HDFS 接近的性能。在我们的测试场景中,使用 JuiceFS 相比于直接使用对象存储性能提升了 38%。
如果你打算在公有云上使用 Kylin 来完成数据分析需求,存储使用 JuiceFS 配合对象存储,能在兼容性和性能上双赢。
