









Hey guys, today is the first working day of 2019, I hope everybody is doing great. In this special day, I want to share the review about the past year to our customers and friends.
2018 is the first year of JuiceFS commercialization. The size of managed data has increased tenfold. The product has released 10 versions and supports 16 public clouds and 100 regions worldwide.
During the year, we have served a number of cool technology companies to help them cope with the rapid growth of business. During this period, some businesses doubled, and some got a new round of financing, and we were happy for them sincerely.
Enrich use scenarios, be data lake of enterprises
The concept of the data lake is that the enterprise hopes to have a unified storage space, which can store all the data together. Since the types of data are diverse, and the usage is also various, this goal is very challenging to implement.
During the development of JuiceFS, and feedback of customer usages, we saw several challenges that companies face in storage:
- There are already many open source storage products, but first, it is very difficult to use in production. It required dedicate maintainers, have to debug by yourself and even need extended development.
- The use of multiple sets of storage products in different scenarios is not only difficult to maintain but also hard to unify the data format. In the real case, the service requires a lot of scheduling.
- Very expensive, cost lots of money. Most of the existing storage solutions are still left in the data center era. When moving them directly to the cloud, the TCO sometimes increased, and the operations also cannot take advantage of the cloud.
What can JuiceFS offer?
- Fully serviced, we get all the works done and rest the customer assured.
- Fully compatible with the POSIX interface, which is the largest and most versatile interface standard in the Unix/Linux world.
- Taken the advantages of public cloud, provides fully flexible capacity and billing, TCO is very low, and no worries about capacity expansion.
JuiceFS is fully compatible with the POSIX interface, so it is compatible with many common storage scenarios. Here are a few of the customers' picks:
- Cluster log collection, archiving, and use sharing instead of scheduling, simple configurations whether in VM, Docker or Kubernetes. A single JuiceFS volume can be mounted to thousands of nodes at the same time, and the logs generated by each node can be moved at regular intervals or copied to the JuiceFS directory in real time. No need to collect, monitor, maintain and monitor any redundant components for the logs.
- Data backup for applications like MySQL, MongoDB, Ethereum Wallet Parity, etc. These applications mostly store the core data, and thus all need a perfect backup strategy. Hot backup, cold backup, and offsite backup are all indispensable, and most of them need a large storage space to cope. JuiceFS meets all of these requirements, with automatic compression, automatic encryption, and automatic offsite backup.
- Fully compatible with various products in the Hadoop ecosystem in big data analysis scenario. Build HDFS on the public cloud is expensive and complicated, and there is a lot of performance loss after switching to object storage. JuiceFS combines performance and cost and is an excellent choice for public clouds.
- Data sharing, such as training data and models are share among multi-machine and clusters in machine learning. Data sharing can considerably improve work efficiency in this scenario. At the same time, JuiceFS is optimized for a large number of small files, which is very suitable for computing requirements in the fields of image recognition and autopilot.
- Customers which deployed in the data center can use JuiceFS to back up their data to the cloud to achieve off-site disaster recovery. On the cloud, only require object storage. Therefore the overall TCO is extremely low. More offsite backup benefits security. Besides, fully automatic transmission and storage encryption further enhanced data privacy.
Fast caching, optimize data security and monitoring
During the year, JuiceFS has dozens of new features and improvements. The following are highlights:
- Support 2-Factor verification to provide better account protection.
- Support for data storage encryption, you can use your own RSA key or hosted by JuiceFS to save sensitive, private data. (Click to view design and usage documentation)
- Provides a complete metadata cache and data cache, and supports configuration items such as page size and compression. In some scenarios, small file read and write and random read and write performance can be considerably improved. (Click to view cache usage documentation)
- The client is no longer automatically updated, you need upgrade manually, it is easier to do version control. (Click to view how to upgrade client)
- Complete monitoring API provides API output for Prometheus and OpenFalcon with custom Grafana view templates.
- Several enhancements to improve productivity and user experience, including quick delete juicefs rmr, quick search juicefs grep, http access, quick space statistics, etc.
- Provide detailed local client logs with visual performance analysis tools.
- Support more public cloud platform, covering 16 different service providers and 100 regions in China and the United States.
Last year, we also released an open source tool JuiceSync, which can copy data in different service providers, different service regions, and any two object storage, which is convenient for users to move and backup object storages.
Improved performance, increased small file and random read and write performance
Performance is our high priority goal. When JuiceFS is first released online, we mainly optimize the sequential read and write scenarios for large files. In testing performed in AWS, large files were read sequentially at 271MB/s and sequentially at 612MB/s (beats the maximum bandwidth in the test environment).
The feedback that the customer first proposed is: too fast, can occupy the full bandwidth, we need speed limit function. Then, there is a speed limit function.
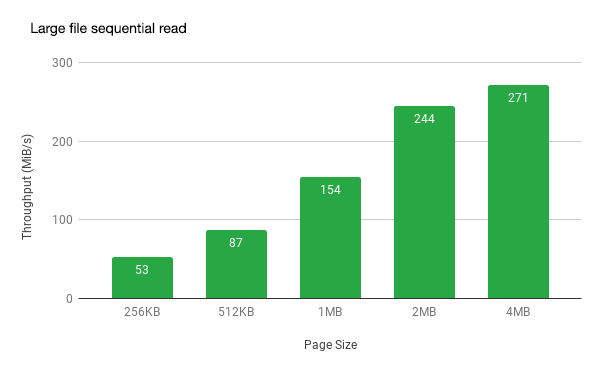
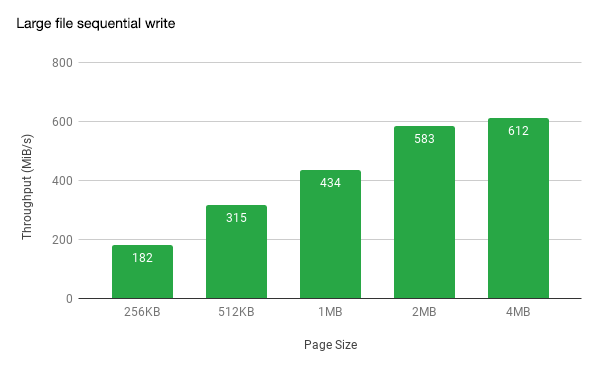
We have completed many optimizations for random reads and writes and small files as well. For specific performance indicators, please refer to Single Node Benchmark Report. Several crazy users are running MySQL slave nodes on JuiceFS, and the replication mode is chasing the master node smoothly.
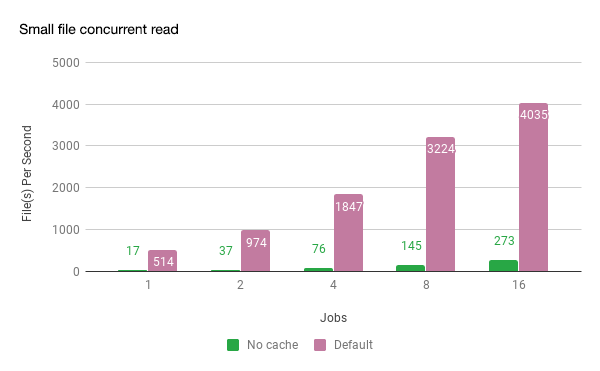
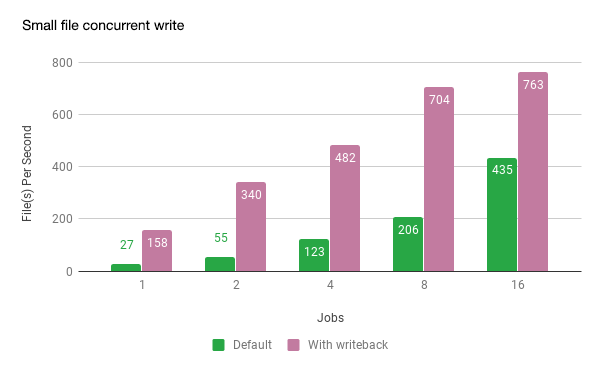
Recently, we are beginning a new series of performance optimization for machine learning scenarios. The goal is to store one billion small files and support multi-GPU parallel training scenario. We started testing with some customers, expecting official launch after the 2019 Lunar New Year.
Reduce the minimum billing size, beneficial for small file storage
To support the cost of services, JuiceFS has set a minimum billing size of 256KB for each file like Microsoft Azure Data Lake, which makes the small files size significantly larger than the actual size, which confusing users. After the practice and observation of the past year, and the optimization of the cost, to reduce the user's troubles, and make it easier for users to use JuiceFS in different scenarios, we decided to reduce the minimum space usage of files and directories to 4KB, which is the same as most stand-alone file systems.
We hope that whether you plan to store large files or small files, sequential access or random access, for computing or backup, JuiceFS is always the best choice.
This change has taken effect beginning January 1, 2019. You can find that the space occupied by JuiceFS is less than before, and the cost is decreased accordingly. It is a New Year gift for everyone.
2019
2018 is a year of accumulation, we are listening for your feedbacks seriously. 2019, we will continue thinking big and starting small, support your business growth.


