















Note: This post was published on DZone.
JuiceFS introduced the directory quota feature in version 1.1. The released commands support setting quotas for directories, fetching directory quota information, and listing all directory quotas. For details, see the Command Reference document.
In designing this feature, our team went through numerous discussions and trade-offs regarding its accuracy, effectiveness, and performance implications.
In this article, we’ll elaborate on different choices made during the design of this feature, their pros and cons, and share the final implementation. This aims to provide insights for users interested in directory quotas or with similar development needs.
Requirement analysis
Designing directory quotas must first consider three factors:
- Dimensions of statistics: Commonly, usage and limits are calculated based on directories, but other dimensions include user-based and user-group-based statistics.
- Resources for statistics: Generally, these include total file capacity and total file count.
- The limiting mechanism: The simplest way is to halt further writing when usage reaches a predefined value, known as the hard limit. There is also a common limiting mechanism called the soft limit, which triggers only an alert when the usage reaches this value but does not immediately restrict writing. The restriction occurs either when it hits the hard limit or after a grace period.
Furthermore, requirements for the effectiveness and accuracy of quota statistics must be considered. In distributed systems, multiple clients often access simultaneously. Ensuring that their views of quotas remain consistent at the same point in time can significantly impact performance.
It's also important to consider whether complex configurations, such as nested quotas and setting quotas for non-empty directories, should be supported.
Development principles
Our main consideration was to keep things as simple and manageable as possible. We aimed to avoid extensive code refactoring, minimize intrusions into critical read and write paths, and ensure that implementing new functionalities wouldn't greatly affect the stability and performance of the existing system. Based on this, we compiled the following to-be-developed functionalities, as indicated in the table:
| Function description | Supported | Evaluation |
|---|---|---|
| Directory-based limit | Yes | Basic functionality |
| Storage capacity limit | Yes | Basic functionality |
| Hard limit | Yes | Basic functionality |
| Total file count limit | Yes | Very simple |
| Nested quota setting | Yes | For user-friendliness |
| Quotas for non-empty directories | Yes | For user-friendliness |
| Moving directories across quotas | Yes | For user-friendliness |
| User/User-group-based restriction | No | Out of scope |
| Soft limit | No | Non-core |
| Grace period | No | Non-core |
| Real-time quota usage statistics | No | Non-essential |
| Precise quota usage statistics | No | Non-essential |
It's worth noting the three items in bold in the table. Initially, we did not plan to support these because their complexity posed a challenge to the overall implementation of the quota feature, and they were not part of our defined core functionalities. However, after extensive discussions with various users, we realized that omitting these features would significantly reduce the practicality of the quota feature. Many users indeed required these functionalities to meet their specific needs. Therefore, in the end, we decided to incorporate these functionalities in JuiceFS 1.1.
Basic functionalities
The user interface
When we designed the quota feature, our first consideration was how users would set and manage quotas. This typically involves two methods:
- Using specific command-line tools. For example, GlusterFS uses the following command to set a hard limit for a specific directory:
$ gluster volume quota <VOLNAME> limit-usage <DIR> <HARD_LIMIT>
- Using the existing Linux tool but with specific fields. For example, CephFS manages quotas as a special extended attribute:
$ setfattr -n ceph.quota.max_bytes -v 100000000 /some/dir # 100 MB
JuiceFS opted for the first approach, with the command form as follows:
$ juicefs quota set <METAURL> --path <PATH> --capacity <LIMIT> --inodes <LIMIT>
We made this choice for three reasons:
- JuiceFS already had a CLI tool in place. Adding quota management functionality only required adding a new sub-command. This was convenient.
- Quotas are usually configured by administrators and should not be changed by regular users. Custom commands can require METAURL to ensure permission.
- The second approach requires mounting the file system locally in advance. Quota settings often need to integrate with management platforms. Including the directory path as a parameter in the command avoids this step. This is more convenient.
The metadata structure
JuiceFS supports three major categories of metadata engines:
- Redis
- SQL types, such as MySQL, PostgreSQL, and SQLite
- TiKV types, such as TiKV, FoundationDB, and BadgerDB
Each category has different implementations based on the data structures they support, but the managed information is generally consistent. In the previous section, we decided to use the juicefs quota command to manage quotas. So we also decided to use separate fields to store information for the metadata engine. Taking the example of the SQL type:
// SQL table
type dirQuota struct {
Inode Ino `xorm:"pk"`
MaxSpace int64 `xorm:"notnull"`
MaxInodes int64 `xorm:"notnull"`
UsedSpace int64 `xorm:"notnull"`
UsedInodes int64 `xorm:"notnull"`
}
The code above shows that JuiceFS creates a new table for directory quotas, with the directory index number (Inode) as the primary key, storing threshold values for capacity and file count in quotas and their respective utilization.
Quota updates/checks
The maintenance of quota information mainly involves two tasks: updates and checks. Quota updates typically involve creating and deleting files or directories, which affect the file count. Additionally, writing to files impacts quota usage capacity. The most straightforward way to do this is to commit changes to the database right after each request is completed. This ensures real-time and accurate statistics but can easily lead to significant metadata transaction conflicts.
The reason behind this is that in JuiceFS' architecture, there is no separate metadata service process. Instead, multiple clients concurrently submit changes to metadata engines in the form of optimistic transactions. If they attempt to change the same field, like the usage of quotas, in a short timeframe, it results in severe conflicts.
JuiceFS' approach is to synchronize the maintenance of quota-related caches in each client's memory and asynchronously submit local updates to the database every three seconds. This sacrifices a certain degree of real-time capability but significantly reduces the number of requests and transaction conflicts. Additionally, clients load the latest information from metadata engines during each heartbeat cycle (default 12 seconds), including quota thresholds and usage, to understand the global file system situation.
Quota checks are similar to updates, but they are simpler. Before performing an operation, the client can directly perform synchronous checks in memory if necessary, only proceeding with the process if the check passes.
Design of complex functionalities
This section discusses the design approach to nested quotas and recursive statistics.
Nested quotas
In conversations with users, we often encountered this requirement: a department sets a large quota, but within that department, there might be groups or individuals, each needing their own quotas.
This necessitates adding nested structures to quotas. Without considering nesting, each directory has only two states: no quotas or limited by a single quota. However, introducing nested structures complicates the situation. For example, when updating a file, we need to identify all affected quotas and check or modify them. So, given a directory, how can we quickly find all affected quotas?
Option 1: Cache the quota tree and directory-to-nearest-quota mapping
Taking the figure below as an example:
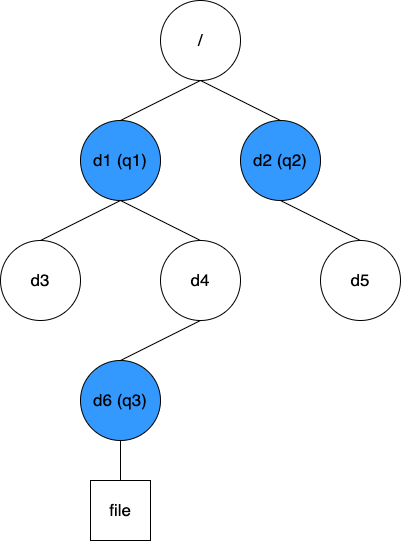
This solution involves maintaining a nested structure of quotas and mapping information for each directory to its nearest quota. The data structure for the given example is as follows:
// quotaTree map[quotaID]quotaID
{q1: 0, q2:0, q3: q1}
// dirQuotas map[Inode]quotaID
{d1: q1, d3: q1, d4: q1, d6: q3, d2: q2, d5: q2}
With this information, when updating or searching for quotas, you can quickly find the nearest quota ID based on the directory Inode you are operating on. Then, you can traverse the quotaTree to find all affected quotas. This approach allows for efficient lookups and has an advantage from a static perspective. However, certain dynamic changes can be challenging to handle. Consider the scenario below:
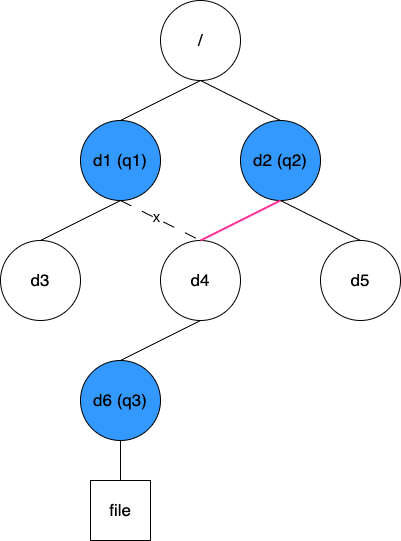
Now, if you need to move directory d4 from its original location, d1, to d2, the parent quota for q3 changes from q1 to q2. But since q3 is configured on d6, detecting this change is difficult. We could traverse all the directories underneath while moving d4 to check if they have quotas. However, it's evident that this would be a substantial undertaking. Thus, this solution is not advisable.
Option 2: Cache directory-to-parent-directory mapping
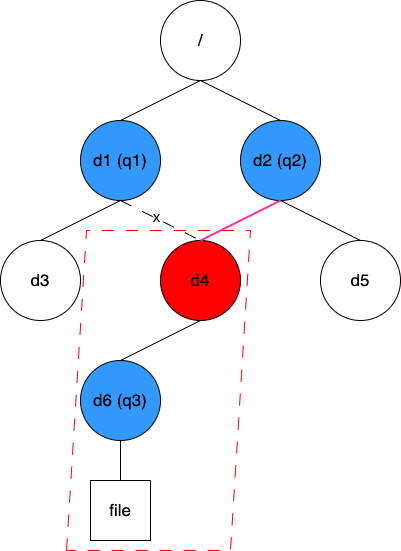
The figure shows a scenario with dynamic changes:
The second solution is caching mapping relationships for all directories to their parent directories. For the initial data structure represented in the figure above, it looks like this:
// dirParent map[Inode]Inode
{d1: 1, d3: d1, d4: d1, d6: d4, d2: 1, d5: d2}
With the same modification, all that's needed in this case is to change the value of d4 from d1 to d2. In this approach, when looking for affected quotas in a specific directory, you need to traverse up the directory tree using dirParent until you reach the root directory. During this process, you check whether each directory passed through has quotas set. Clearly, this solution has slightly lower lookup efficiency compared to the previous one. However, all this information is cached in client memory, so the overall efficiency remains acceptable. Therefore, we adopted this solution.
It's worth mentioning that the directory-to-parent-directory mapping is cached in client memory without specific expiration policies. This is primarily due to two considerations:
- In most cases, the number of directories in a file system is not large. It requires only a small amount of memory to cache them all.
- Changes made to directories by other clients do not need to be immediately detected in this client. When this client accesses related directories again, the cache is updated via kernel's lookup or reading directory (
Readdir) requests.
Recursive statistics
During requirement analysis, in addition to nested quotas, two related issues emerged: setting quotas for non-empty directories and dealing with quota changes after directory movements. These problems essentially share a common challenge: how to quickly obtain statistical information for an entire directory tree.
Option 1: Default recursion statistics for each directory
This solution is somewhat similar to the nested quotas functionality, but now it needs to add recursive statistics information to every directory. This approach provides the convenience of one-time queries for the entire tree's size. However, the cost of maintenance is high. When modifying any file, it requires updating the recursive statistics for each directory. This can lead to frequent changes, especially closer to the root directories.
JuiceFS uses an optimistic concurrency mechanism for its metadata. This means that conflicts are resolved through retries. Under high-pressure conditions, this can result in severe transaction conflicts, potentially crashing the metadata engine as the cluster scales.
Option 2: No regular interventions; only perform temporary scans when needed
This is a simple and straightforward approach. However, when dealing with directories containing a large number of files, temporary scans can be time-consuming. It also places a significant load on the metadata engine. Therefore, this solution is not suitable for direct use.
Option 3: Maintain usage statistics for immediate subdirectories only; perform a full scan when needed
The figure below illustrates this solution:
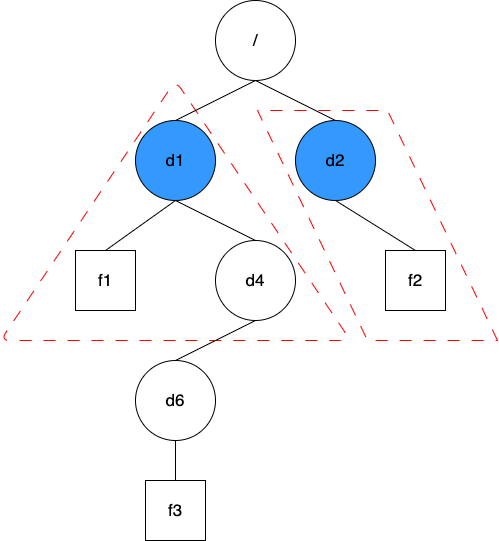
This solution combines the advantages of the previous two solutions while trying to avoid their drawbacks.
There are a couple of observations about file systems: - Most metadata requests inherently contain information about the direct parent directory. This eliminates the need for additional operations and avoids any extra transaction conflicts. - Typically, in a file system, the number of directories is 2 to 3 orders of magnitude less than the number of regular files.
Given these observations, JuiceFS implemented the directory statistics feature, which maintains usage statistics for only the immediate subdirectories. When recursive statistics are needed for the quota feature, there's no need to traverse all files; it suffices to calculate the usage of all subdirectories. This is the solution JuiceFS ultimately adopted.
Additionally, with the introduction of directory statistics, JuiceFS found some additional benefits. For example, the previously existing juicefs info -r command, used to replace du for calculating the total usage of a specific directory, has significantly improved in speed. Another new command, juicefs summary, provides a quick analysis of specific directory usage. This makes it easier to find the highest-utilized subdirectories through specific sorting.
Quota repair
As explained earlier, JuiceFS sacrifices a degree of accuracy for stability and reduced performance impact when implementing directory quotas. When a client process crashes or a directory is frequently moved, there might be slight discrepancies in quota information over time. JuiceFS offers a juicefs check functionality for rescanning the entire directory tree's statistics and comparing it with the stored quota values. If discrepancies are found, the system reports the issues and provides optional repair options.
If you have any questions or would like to learn more, feel free to join discussions about JuiceFS on GitHub and the JuiceFS community on Slack.