















Disclaimer: This article is translated by DeepL, there is the original post in Chinese.
Apache Kylin 4.0 uses Spark as the build engine and Parquet as the storage, making it easier to deploy and scale on the cloud, but using object storage on the cloud may have some compatibility and performance issues compared to using HDFS on local disk. The powerful query engine of Kylin 4.0 and the efficient local cache of JuiceFS can achieve the win-win of compatibility and performance! For more details, check out this great article from Kylin and Juicedata!
About the Author
Rui Su, Partner at Juicedata, has been working in the Internet industry for over 15 years.
Xiaoxiang Yu, Senior Engineer of Kyligence, Apache Kylin Committer & PMC.
What is Apache Kylin?
Apache Kylin is an open source, distributed analytics engine designed for hyperscale data, providing SQL query interfaces and multidimensional online analytics (OLAP) capabilities on top of Hadoop/Spark. Originally developed by eBay and contributed to the Apache Software Foundation, Kylin is capable of sub-second query responses even with massive amounts of data.
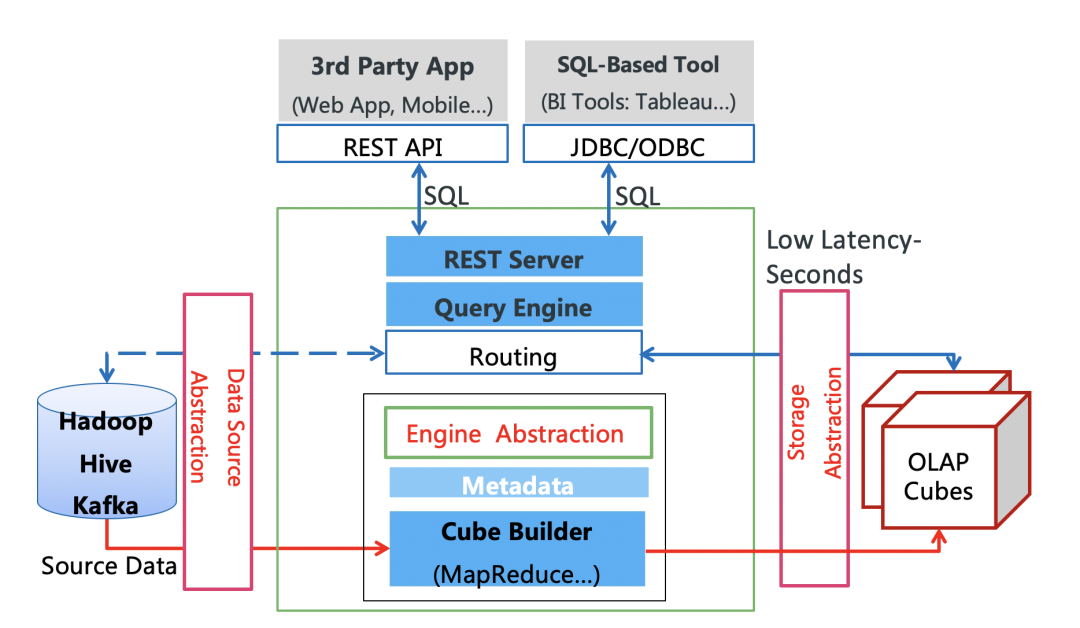
As an ultra-high performance query engine, Kylin can connect to a variety of data sources such as Hive and Kafka, and a variety of BI systems such as Tableau and Superset, and also provides JDBC/ODBC/REST APIs for integration with various applications. Since the open source, Kylin has been used by a large number of applications, such as Meituan, Xiaomi, 58 Tongcheng, KE Holdings, Huawei, Autohome, Ctrip, Tongcheng, Vivo, Yahoo Japan, OLX Group, etc. The daily access volume ranges from tens of thousands to tens of millions, and most queries can be completed within 1-3 seconds.
If your product/business side comes to you and says it needs to do flexible aggregate queries on billions or even tens of billions of records, with fast response, high concurrency, and low resource consumption; and in order to support application development, it also needs to fully support SQL syntax and seamlessly integrate with BI, then Apache Kylin is the right choice for you.
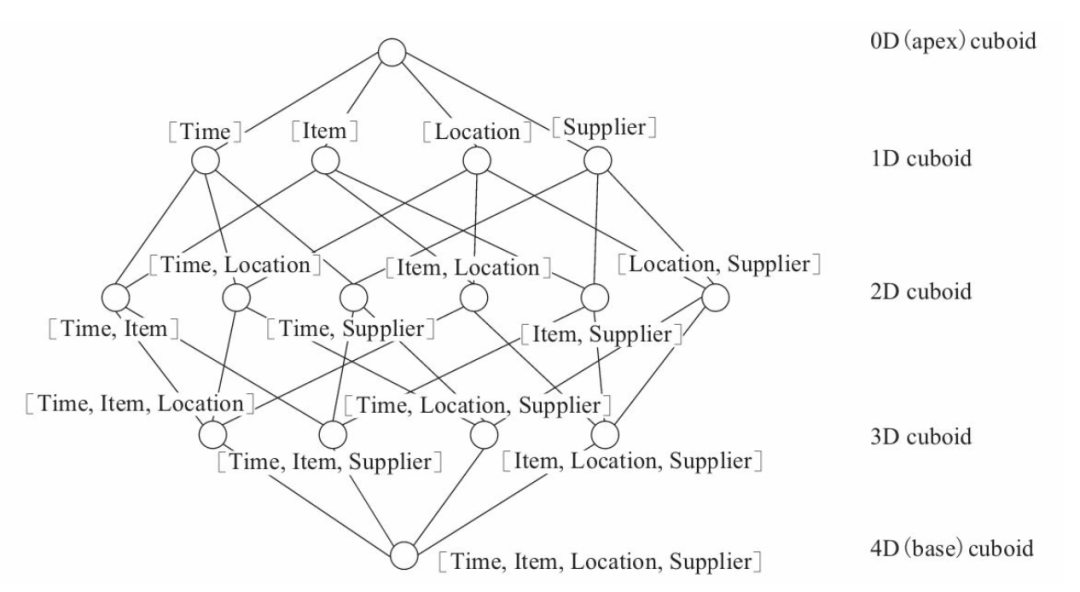
The core idea of Kylin is precomputation, which precomputes all possible query results (also known as Cube, multi-dimensional cube) based on specified dimensions and metrics to accelerate OLAP queries with fixed query patterns using space for time. Each combination of dimensions is called a Cuboid, and the set of all Cuboids is a Cube. The Cuboid that consists of all dimensions is called the Base Cuboid, and all other Cuboids can be aggregated secondarily from the Base Cuboid. At query time, Kylin automatically selects the most appropriate Cuboid that meets the criteria, which greatly reduces the amount of data and computation needed to scan the data from the Cuboid compared to computing from the user's original table.
Kylin chose HBase as the storage engine from the beginning to basically meet the query performance requirements; however, there are a series of pain points based on HBase solution, such as the complexity of HBase operation and maintenance, single point of query node problem, HBase is not pure columnar storage IO efficiency, etc. Apache Kylin v4 uses Apache Kylin v4 uses a combination of Parquet + Spark and no longer uses HBase, making the separation of compute and storage a major architectural upgrade that is more in line with the trend of cloud-native technologies.
{{ }}
}}
The challenges of Kylin on Parquet on the cloud
Compared to the previous generation of Kylin 4, users can deploy high-performance, low-TCO data analytics services on the cloud more quickly and easily. The separation of compute and storage and the reduction in architectural complexity make Kylin one of the best choices for data analytics on the cloud. However, the huge difference between the file system abstracted from object storage and traditional HDFS on the cloud brings a series of concerns, such as data locality, object storage API call frequency limitation, and difficulty in ensuring consistency of data movement operations, which brings some stability and performance challenges to Kylin build and query. We can see some successful solutions on how to mitigate and even achieve the excellent performance experience of native HDFS, and JuiceFS is one of them.
What is JuiceFS?
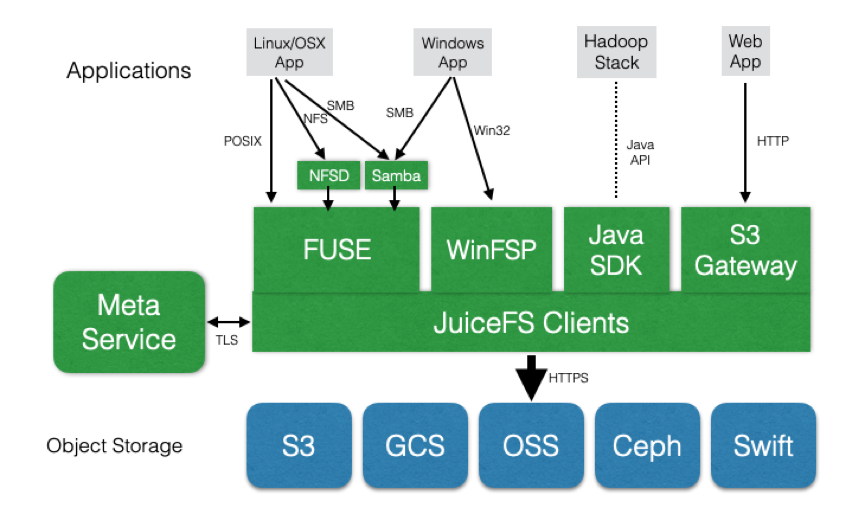
JuiceFS is a distributed file system designed for cloud-native environments, fully compatible with POSIX and HDFS for big data, machine learning training, Kubernetes shared storage, and massive data archive management scenarios. It supports all global public cloud providers and provides fully managed services, so customers can instantly have an elastic and scalable file system with up to 100PB capacity without investing any operation and maintenance efforts.
As you can see in the architecture diagram below, JuiceFS already supports various public cloud object storage products, as well as open source object storage, such as Ceph, MinIO, Swift, etc. FUSE clients are available on Linux and macOS, and native clients are available on Windows systems to mount JuiceFS file systems, making the experience identical to that of a local disk. The Java SDK is available in Hadoop environments and the experience is the same as HDFS. JuiceFS' metadata services are deployed as a fully managed service on all public clouds, so customers don't have to maintain any services themselves and the learning and usage barriers are extremely low.
Why should Kylin and JuiceFS be used together?
If a customer is using Kylin on a public cloud and wants to store their data on an object store, they run into two issues.
The first issue is compatibility, Kylin supports HDFS and Amazon S3 by default, other public clouds also provide "S3 compatible" object storage, but in actual testing we found that currently there are incompatible object storage in other public clouds except AWS and Azure, for example, we run Kylin on AliCloud based on OSS, both based on AliCloud EMR and CDH self-built cluster, it will fail in the Cube build phase.
The second problem is performance. From the user's perspective, when switching from HDFS to object storage in a big data scenario, the performance degradation can be felt. There are several reasons for the performance degradation.
- increased network overhead: HDFS to do storage with data locality characteristics, after switching to object storage data transfer all to go through the network, will increase the overhead, resulting in a decline in performance.
- degradation of metadata performance: there are a lot of file metadata operations in the Cube construction process, especially Listing and Rename, which have poor performance on object storage compared to HDFS, leading to increased time consumption of the whole job, resulting in degradation of performance.
- performance degradation due to read amplification: when Kylin data is replaced by Parquet file format, data queries often do not need to read the complete Parquet file, but only the header or footer, which requires the storage system to provide good random read capability, which is precisely the shortcomings of the object storage, so it will cause read amplification which increases the I/O of the entire query task and leads to performance degradation.
JuiceFS can completely solve the compatibility and performance problems in big data scenarios, and here's how it does it. JuiceFS can completely solve the compatibility and performance problems in big data scenarios.
First of all, compatibility, JuiceFS metadata service provides a Java SDK, which is equivalent to the HDFS Java SDK, and implements the Interface of all HDFS file interface APIs to ensure consistent behavior with HDFS. can use JuiceFS without any compatibility issues. Moreover, JuiceFS supports all public cloud services worldwide to provide a consistent experience, and users no longer have to care about the differences in object storage from different cloud vendors.
Secondly, on performance, explain how JuiceFS addresses the performance degradation caused by the above three aspects.
- The compute cluster using JuiceFS is also a storage compute separation architecture, which also loses the data locality feature of HDFS, but JuiceFS provides data caching capability on the client side, all the data read from JuiceFS will be automatically cached to the client's node (virtual machine or container can be) on the The next time this data is accessed, it will be read directly from the local storage and will not go through the network. In big data query analysis scenarios, where data is often hot, performance can be significantly improved with the support of JuiceFS caching (see test results below). You may also be concerned about cache management, expiration, and consistency issues, JuiceFS has a complete set of handling mechanisms, which is worth a separate article, and will not be expanded in this paper.
- The metadata performance, JuiceFS has its own independent metadata service, Listing, Rename operations are responded by JuiceFS metadata, performance than object storage dozens of times faster than HDFS also improved by more than 50%, see JuiceFS test cases.
- JuiceFS caching can effectively reduce the latency of random reads and reduce read amplification, which has a very obvious performance advantage in query analysis scenarios based on Parquet and ORC data formats.
In summary, JuiceFS can achieve performance comparable to HDFS, while providing perfect compatibility with the Hadoop ecosystem. More importantly, customers can use JuiceFS for a consistent experience regardless of which public cloud they use.
Performance Comparison
While the benefits of using Kylin on Parquet and JuiceFS together are explained above, here's a look at the performance test results.
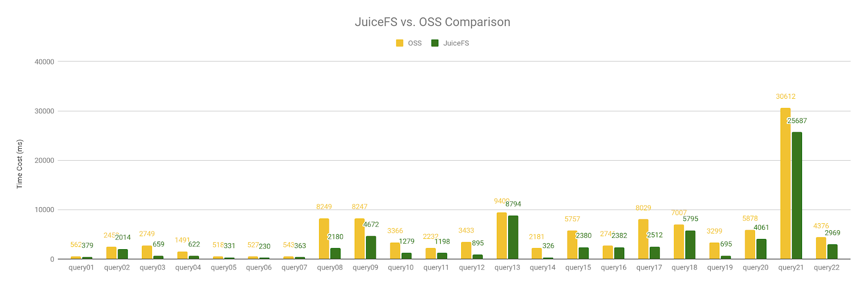
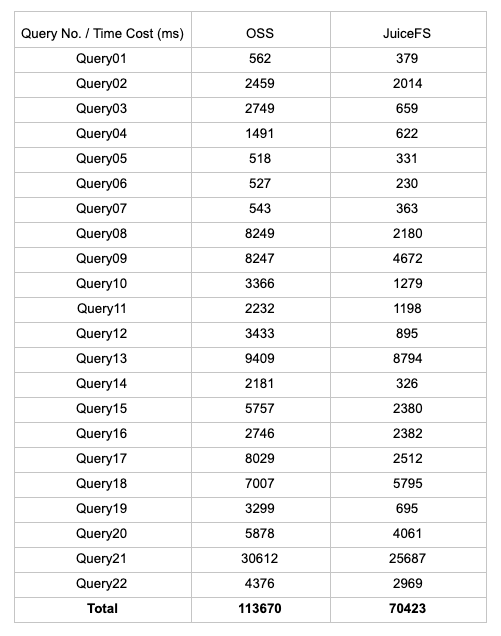
As mentioned earlier, there is a compatibility problem with OSS-based Cube building, and the Cube cannot be built correctly, but we can copy the Cube data built on JuiceFS to OSS to execute the Query, so we tested Query1 to Query22 based on the TPC-H 10GB size dataset. Query22, JuiceFS is 38% faster than OSS in terms of total execution time.
- JuiceFS uses 70,423ms
- OSS uses 113,670ms
The following table gives the detailed test environment configuration and execution time of all tested Queries.
Machine Configuration
- Kylin and master(1 node): 4Cores, 16G RAM, 200G ESSD
- Workers(3 nodes): 4Cores, 16G RAM, 2x200G ESSD
Build the cluster on AliCloud using CDH 5.16 with the following detailed configuration and software version.

All test query execution times
Summary
Kylin 4.0 introduces a separate architecture for compute and storage, making it easier to deploy and scale Kylin on the cloud, but using object storage on the cloud compared to HDFS on local disk has docking development and compatibility issues on one hand, and performance degradation on the other. With JuiceFS and Kylin, you can use cloud storage services for big data computation in EMR or self-built Hadoop clusters without special adaptations on all public clouds. In Parquet-based query analysis scenarios, it can effectively reduce latency and read amplification for random reads, achieving performance close to that of HDFS. In our test scenario, we saw a 38% performance improvement using JuiceFS compared to direct object storage.
If you plan to use Kylin on the public cloud for your data analysis needs, using JuiceFS with object storage for storage can be a win-win in terms of compatibility and performance.