















Jerry, an American tech company, uses AI and machine learning to streamline the comparison and purchasing process for car insurance and car loans. In the US, it’s the top app in the field.
As data size grew, we faced performance and cost challenges with AWS Redshift. Switching to ClickHouse improved our query performance by 20 times and greatly cut costs. But this also introduced storage challenges like disk failures and data recovery.
To avoid extensive maintenance, we adopted JuiceFS, a distributed file system with high performance. We innovatively use its snapshot feature to implement a primary-replica architecture for ClickHouse. This architecture ensures high availability and stability of the data while significantly enhancing system performance and data recovery capabilities. Over more than a year, it has operated without downtime and replication errors, delivering expected performance.
In this post, I’ll deep dive into our application challenges, why we chose JuiceFS, how we use it in various scenarios, and our future plans. I hope this article provides valuable insights for startups and small teams in large companies.
Data architecture: From Redshift to ClickHouse
Initially, we chose Redshift for analytical queries. But as data volume grew, we encountered severe performance and cost challenges. For example, when generating funnel and A/B test reports, we faced loading times of up to tens of minutes. Even on a reasonably sized Redshift cluster, these operations were too slow. This made our data service unavailable.
Therefore, we looked for a faster, more cost-effective solution, and we chose ClickHouse despite its limitations on real-time updates and deletions. The switch to ClickHouse brought significant benefits:
- Report loading times were reduced from tens of minutes to seconds. This greatly improved our data processing efficiency.
- Overall costs were reduced to a quarter or less of the previous amount.
ClickHouse became the core of our architecture, complemented by Snowflake for handling the remaining 1% of data tasks that ClickHouse couldn't manage. This setup ensured smooth data exchange between ClickHouse and Snowflake.
ClickHouse deployment and challenges
We initially maintained a stand-alone deployment for several reasons:
- Performance: Stand-alone deployments avoid the overhead of clusters and perform well under equal computing resources.
- Maintenance costs: Stand-alone deployments have the lowest maintenance costs. This covers not only integration maintenance costs but also application data settings and application layer exposure maintenance costs.
- Hardware capabilities: Current hardware can support large-scale stand-alone ClickHouse deployments. For example, we can now get EC2 instances on AWS with 24 TB of memory and 488 vCPUs. This surpasses many deployed ClickHouse clusters in scale. These instances also offer the disk bandwidth to meet our planned capacity.
Therefore, considering memory, CPU, and storage bandwidth, stand-alone ClickHouse is an acceptable solution that will be effective for the foreseeable future.
However, the ClickHouse solution also has inherent issues:
- Hardware failures: When hardware failures occur, ClickHouse will experience long downtime. This poses a threat to application continuity and stability.
- Data migration and backup: Data migration and backup in ClickHouse remain challenging tasks, and achieving a robust solution is still difficult.
After we deployed ClickHouse, we encountered the following issues:
- Storage scaling and maintenance: Rapid data growth made maintaining reasonable disk utilization rates challenging.
- Disk failures: ClickHouse is designed to aggressively use hardware resources to deliver optimal query performance. This leads to frequent read and write operations that often push disk bandwidth to its limits. This increases the likelihood of disk hardware failures. When such failures occur, recovery can take several hours to over ten hours, depending on the data volume. We've heard similar experiences from other users. Although data analysis systems are typically considered replicas of other systems' data, the impact of these failures is still significant. Therefore, we must be well-prepared for potential hardware failures. Data backup, recovery, and migration are particularly challenging tasks that require additional effort and resources to manage effectively.
Why we chose JuiceFS
To solve our pain points, we chose JuiceFS due to the following reasons:
- JuiceFS was the only available POSIX file system that could run on object storage.
- Unlimited capacity: Since we started using it, we no longer have to worry about storage capacity.
- Significant cost advantage: Compared to other solutions, JuiceFS drastically reduces our costs.
- Powerful snapshot capability: JuiceFS ingeniously applies the Git branching model to the file system level, implementing it correctly and efficiently. When two different concepts merge so seamlessly, they often produce highly creative solutions. - This makes previously challenging problems much easier to solve.
Running ClickHouse on JuiceFS
We came up with the idea of migrating ClickHouse to a shared storage environment based on JuiceFS. The article Exploring Storage and Computing Separation for ClickHouse provided some insights for us.
To validate this approach, we conducted a series of tests. The results showed that with caching enabled, JuiceFS read performance was close to that of local disks. This is similar to the test results in this article.
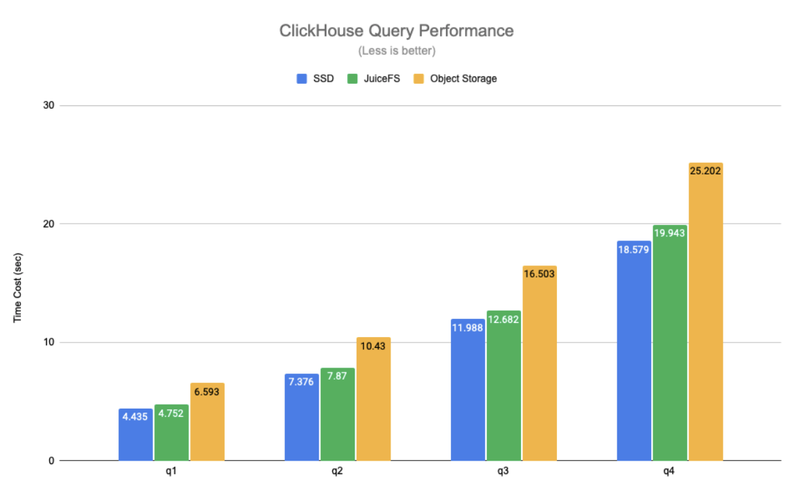
Although write performance dropped to 10% to 50% of disk write speed, this was acceptable for us:
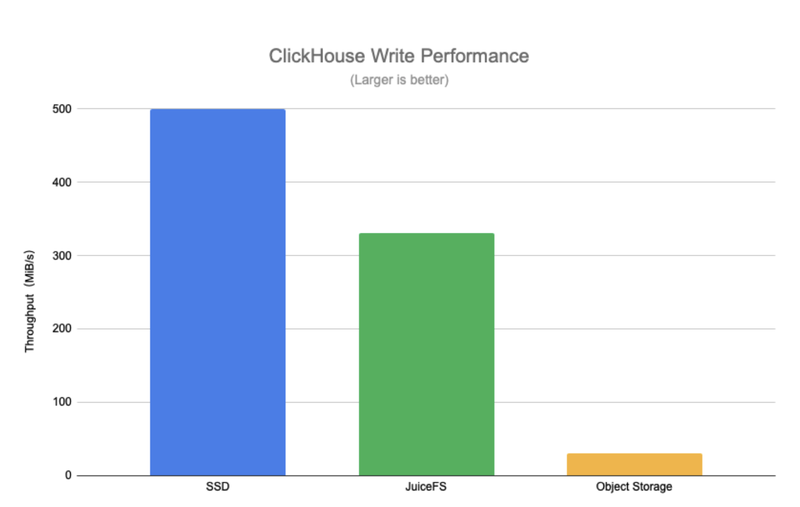
Here are the tuning adjustments we made for JuiceFS mounting:
- We enabled the writeback feature to achieve asynchronous writes and avoid potential blocking issues.
- In cache settings, we set
attrcachetoto 3,600.0 seconds,cache-sizeto 2,300,000, and enabled the metacache feature. - Considering that I/O runtime on JuiceFS might be longer than on local disks, we adjusted our strategy by introducing the block-interrupt feature.
Our optimization goal was to improve cache hit rates. Using JuiceFS Cloud Service, we successfully increased the cache hit rate to 95%. If we need further improvement, we’ll consider adding more disk resources.
The combination of ClickHouse and JuiceFS significantly reduced our operational workload. We no longer need to frequently expand disk space. Instead, we focus on monitoring cache hit rates. This greatly alleviated the urgency of disk expansion. Furthermore, when we encounter hardware failures, we don’t need to migrate data. This significantly reduced potential risks and loss.
The JuiceFS snapshot feature provided convenient data backup and recovery solutions, which was invaluable to us. With snapshots, we can restart database services at any point in the future and view the original state of the data. This approach addresses issues that were previously handled at the application level by implementing solutions at the file system level. In addition, the snapshot feature is very fast and economical, since only one copy of the data is stored. The community edition users can use the clone feature to achieve similar functionality.
Moreover, without the need for data migration, downtime was dramatically reduced. We could quickly respond to failures or allow automated systems to mount directories on another server, ensuring service continuity. It’s worth mentioning that ClickHouse startup time is only a few minutes, which further improves system recovery speed.
Furthermore, our read performance remained stable after the migration. The entire company noticed no difference. This demonstrated the performance stability of this solution.
Finally, our costs significantly decreased. By replacing expensive cloud storage products with inexpensive object storage, we reduced total storage costs by an order of magnitude and further enhanced overall efficiency.
Why we set up a primary-replica architecture
After migrating to ClickHouse, we encountered several issues that led us to consider building a primary-replica architecture:
- Resource contention caused performance degradation. In our setup, all tasks ran on the same ClickHouse instance. This led to frequent conflicts between extract, transform, and load (ETL) tasks and reporting tasks, which affected overall performance.
- Hardware failures caused downtime. Our company needed to access data at all times, so long downtime was unacceptable. Therefore, we sought a solution, which led us to the solution of a primary-replica architecture.
JuiceFS supports multiple mount points in different locations. We attempted to mount the JuiceFS file system elsewhere and run ClickHouse at the same location. However, we encountered some issues during the implementation:
- ClickHouse restricted a file to be run by only one instance through file lock mechanisms, which presented a challenge. Fortunately, this issue was easy to solve by modifying the ClickHouse source code to handle the locking.
- Even during read-only operations, ClickHouse retained some state information, such as write-time cache.
- Metadata synchronization was also a problem. When running multiple ClickHouse instances on JuiceFS, some data written by one instance might not be recognized by others. This required instance restarts to resolve the issue.
Therefore, we decided to use JuiceFS snapshots to implement a primary-replica architecture. This approach operates similarly to a traditional primary-replica setup. All data updates, including synchronization and ETL tasks, occur on the primary instance, while the replica instance focuses on providing query capabilities.
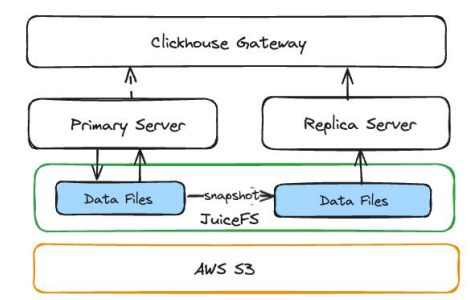
How we created a replica instance for ClickHouse
- Creating a snapshot: We used the JuiceFS snapshot command to create a snapshot directory from the ClickHouse data directory on the primary instance and deploy a ClickHouse service on this directory.
- Pausing Kafka consumer queues: Before starting the ClickHouse instance, we must stop the consumption of stateful content from other data sources. For us, this meant pausing the Kafka message queue to avoid competing for Kafka data with the primary instance.
- Run ClickHouse on the snapshot directory: After starting the ClickHouse service, we injected some metadata to provide information about the ClickHouse creation time to users.
- Delete ClickHouse data mutation: On the replica instance, we deleted all data mutations to improve system performance.
- Performing continuous replication: Snapshots only retain the state at the time of creation. To ensure the replica instance reads the latest data, we periodically recreate the replica instance and replace the original instance. This method is intuitive and efficient, with each replica instance starting from two replicas and a pointer pointing to one replica. We can recreate another replica based on time intervals or specific conditions and point the pointer to the newly created replica without downtime. Our minimum time interval is 10 minutes, but usually running once an hour can meet our requirement.
Our ClickHouse primary-replica architecture has been running stably for over a year. It has completed more than 20,000 replication operations without failure, demonstrating high reliability. Workload isolation and the stability of data replicas are key to improving performance. We successfully increased overall report availability from less than 95% to 99%, without any application-layer optimizations. In addition, this architecture supports elastic scaling, greatly enhancing flexibility. This allows us to develop and deploy new ClickHouse services as needed without complex operations.
Application scenarios of JuiceFS
Data exchange
We focus on the application of ClickHouse. Using its ability to access shared storage, we've unlocked many interesting scenarios. Notably, mounting JuiceFS on JupyterHub has been particularly impressive.
Some data scientists output data to specific directories, allowing us to directly perform joint queries on all tables in ClickHouse when creating reports. This greatly optimizes the entire workflow. Although many engineers believe that synchronizing data writes isn't difficult, skipping this step daily over time significantly reduces mental load.
Machine learning pipelines
Storing all the data required for machine learning pipelines, including training data, on JuiceFS has provided a seamless workflow. This way, we can easily place the output from training notebooks in designated locations, enabling quick access on JupyterHub and ensuring a smooth pipeline process.
Kafka+JuiceFS
We store Kafka data on JuiceFS. Although we don't frequently access Kafka directly, we value it for long-term data asset storage. Compared to using equivalent AWS products, this approach conservatively saves us about 10-20 times the cost.
Performance tests revealed some single-server performance degradation, but this solution has excellent horizontal scalability. It allows us to achieve the required throughput by adding nodes. Compared to local storage, this solution has slightly higher information latency and some instability. It’s unsuitable for real-time stream processing scenarios.
“I initially started using JuiceFS as an individual user. In my view, JuiceFS' elegant design simplifies developers' lives. When I introduced JuiceFS at work, it consistently made tasks easier.” – Tao Ma, Data Engineering Lead at Jerry
What’s next
Our plans for the future:
- We’ll develop an optimized control interface to automate instance lifecycle management, creation operations, and cache management.
- During the operation of the primary-replica architecture, we observed that the primary instance was more prone to crashes on JuiceFS compared to local disks. Although data can usually be synchronized, and the synchronized data is typically accessible by other replicas, we need to consider this issue when handling failures. Although we have a conceptual and theoretical understanding of the causes of crashes, we have not fully resolved the issue. In short, because the I/O system calls on the file system take longer than on local disks, these anomalies can propagate to other components, potentially causing the primary instance to crash.
- We also plan to optimize write performance. From the application layer, given the robust support for the Parquet open format, we can directly write most loads into JuiceFS outside ClickHouse for easier access. This allows us to use traditional methods to achieve parallel writes, thereby improving write performance.
- We noticed a new project, chDB, which allows users to embed ClickHouse functionality directly in a Python environment without requiring a ClickHouse server. Combining CHDB with JuiceFS, we can achieve a completely serverless ClickHouse. This is a direction we are currently exploring.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and their community on Slack.