














Google Colaboratory(Colab)是一个由 Google 提供的云端 Jupyter 编程笔记本,直接通过浏览器即可进行 Python 编程。Colab 充分利用谷歌的闲置云计算资源,为公众提供免费的的在线编程服务,以及免费的 GPU 资源,虽然在使用方面有一定的规则限制,但对于一般的研究和学习来说绰绰有余。
访问 Colab,可以新建笔记本,也可以从 Google Drive、Github 载入笔记本,或直接从本地上传。
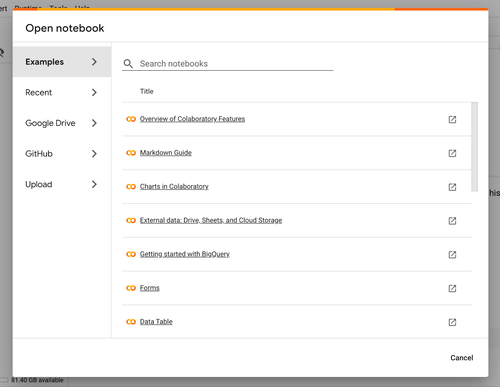
Colab 免费提供的 Python 编程环境十分慷慨,如下图,足有 12 GB 的内存和 100 GB 的硬盘。
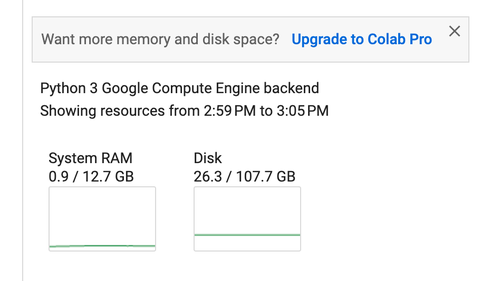
如果需要使用硬件加速,可以切换运行时类型,笔者的账户可以免费使用 T4 GPU 和 TPU。
不过需要注意,Colab 运行时是临时的,平台会监测运行时的活动状态,长时间的闲置和长时间的高强度使用,都会导致运行时被收回释放,所有数据都会被清空。
Colab 上的数据持久化
为了让 Colab 可以持久化地保存文件,人们通常会选择使用 Google Drive。如下图,使用时在界面左侧的文件管理中点击按钮即可将 Google Drive 挂载到运行时,把需要长期保留或重复使用的数据保存在里面,再次使用可以从 Google Drive 中加载,这就避免了运行被释放时丢失数据。
除了 Google Drive 以外,你还可以使用 JuiceFS 作为 Colab 笔记本的持久化存储,从而更为灵活地保存和共享更大规模的数据。
JuiceFS 与 Google Drive
这里先提供一个表格供读者参考,后文会展开介绍 JuiceFS 的技术架构以及如何创建一个适用于 Google Colab 的文件系统。
简言之,Google Drive 有平台优势,更容易集成到 Colab,也有多种容量规格以供扩容,但在使用上会有一些限制,比如单位时间的总上传量,总文件数量等。而 JuiceFS 是自建服务,没有此类限制,而且在费用方面可以通过灵活地组织资源来降低是用成本。
| JuiceFS | Google Drive | |
|---|---|---|
| 价格 | 弹性费用(取决于元数据引擎和对象存储的费用) | 按固定容量订阅 |
| 集成到 Colab | 简单 | 简单 |
| 是否需要维护 | 需要 | 不需要 |
| 扩容能力 | 无容量上限 | 15GB ~ 30TB |
| 上传限制 | 无限制 | 24 小时内可向云端硬盘上传和复制 750 GB 数据 |
| 跨平台共享 | 灵活 | 一般 |
使用 JuiceFS
JuiceFS 是面向云的高性能分布式文件系统,它在 Apache-2.0 协议下开源,具有完备的 POSIX 兼容性,并支持 FUSE POSIX、HDFS、S3、Kubernetes CSI Driver、WebDAV 等多种访问方式。
在 Colab 中可以直接采用 FUSE POSIX 方式,以守护进程形式挂载到运行时中使用。
技术架构
一个典型的 JuiceFS 文件系统由一个负责存储数据的对象存储和一个负责存储元数据的元数据引擎组成。
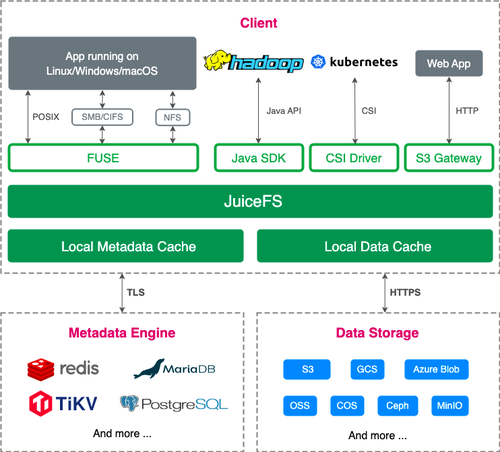
在对象存储方面,JuiceFS 支持几乎所有公有云对象存储、私有部署的对象存储、NFS、SFTP 以及本地磁盘等。在元数据引擎方面,支持 Redis、Postgres、MySQL、TiKV、SQLite 等多种数据库。
因为采用了数据与元数据分离存储的架构,JuiceFS 文件系统的读和写操作会先在元数据引擎上进行查询和处理,只有涉及到实际数据时才会访问对象存储,这样就能极高效地处理海量的数据,相比于直接与对象存储交互,JuiceFS 会有更好的性能表现。
简言之,元数据引擎至关重要,想要提升 JuiceFS 文件系统的性能,一个黄金法则是“尽量靠近业务端部署元数据引擎”。以 Colab 为例,它的服务器大多位于美国,所以找一个美国的云服务器来部署 Redis 并搭配一个可靠的对象存储是构建 JuiceFS 文件系统相对理想的搭配。
适用于 Colab 的组合
元数据引擎
为了在 Colab 上尽量发挥 JuiceFS 的潜能,笔者选择了一个位于美国硅谷的云服务器,将它用于部署 Redis 作为 JuiceFS 的元数据引擎,配置如下:
- 位置:美国硅谷
- CPU:2 核
- RAM:4GB
- SSD: 60GB
- 系统:Ubuntu Server 22.04
- IP:18.18.18.18
- 域名:redis.xxx.com
注:上述 IP 和域名均为演示目的编写,如有需要请替换成你的真实信息。
按照 JuiceFS 官方提供的数据,采用 Redis 这类键值数据库作为元数据引擎时,存储占用大概为 300 字节/文件,那么 1GB 内存大概可以存储 350 万个文件的元数据,读者可以根据预期的文件总量来决定给服务器配置多少内存。
在本文中,笔者使用 Docker 部署 Redis,并通过 Let's Encrypt 签发了一个免费的 SSL 证书对服务端进行加密:
# 拉取 redis 镜像
sudo docker pull bitnami/redis:7.2
# 删除已存在的同名 redis 容器(如果存在的话)
sudo docker rm -f redis
# 创建新的 redis 容器
sudo docker run -d --name redis \
-p 6379:6379 \
-v redis_aof_data:/bitnami/redis/data \
-v ./ssl:/ssl \
-e REDIS_PASSWORD=abcdefg \
-e REDIS_TLS_ENABLED=yes \
-e REDIS_TLS_PORT_NUMBER=6379 \
-e REDIS_TLS_AUTH_CLIENTS=no \
-e REDIS_TLS_CERT_FILE=/ssl/redis.xxx.com.crt \
-e REDIS_TLS_KEY_FILE=/ssl/redis.xxx.com.key \
-e REDIS_TLS_CA_FILE=/ssl/ca.crt \
--restart unless-stopped \
bitnami/redis:7.2
该 Redis 实例启用了以下功能:
- AOF(追加写到本地文件):它会将每个写操作都记录到本地磁盘,从而提高数据的安全性。
- 服务端 SSL:Redis 服务器会使用 SSL/TLS 协议与客户端进行通信。将 SSL 证书放在 ssl 目录中即可,注意修改环境变量中的证书文件名称。
Redis 部署完毕后,还需要检查防火墙,确保服务器开放了 6379 端口的入站请求。这样,Redis 元数据引擎就准备完毕了。
对象存储
对象存储方面,笔者选择使用 Cloudflare R2,因为它上下行流量均免费,只需为存储和 API 请求付费,很适合 Colab 这种需要在外部访问 JuiceFS 的场景。特别是存储量较大的情况,每次都要将模型数据载入到 Colab 运行时,下行收费会产生不小的开支。
以下是演示目的编写的对象存储信息,请在实际配置时替换成自己的真实信息:
- Bucket Name:myjfs
- Endpoint URL:https://xxx.r2.cloudflarestorage.com/myjfs
- Access Key:abcdefg
- Secret Key:gfedcba
创建文件系统
元数据引擎和对象存储都准备好了,接下来使用 JuiceFS 客户端来创建文件系统。
这个步骤可以在任何一台支持安装 JuiceFS 客户端的电脑上执行,可以是你本地正在使用的电脑或是部署了 Redis 实例的那台云服务。
因为 JuiceFS 是基于云的,只要 JuiceFS 客户端能够访问到元数据引擎和对象存储就可以创建和使用。
首先,安装 JuiceFS 客户端:
# macOS 或 Linux 系统
curl -sSL https://d.juicefs.com/install | sh -
# Windows 系统(建议使用 Scoop)
scoop install juicefs
其他系统及安装方法请参考 JuiceFS 官方安装文档
然后,使用已准备的元数据引擎和对象存储来创建文件系统:
# 创建文件系统
juicefs format --storage s3 \
--bucket https://xxx.r2.cloudflarestorage.com/myjfs \
--access-key abcdefg \
--secret-key gfedcba \
rediss://:[email protected]/1 \
myjfs
JuiceFS 文件系统只需要创建一次,然后就可以在任何安装了 JuiceFS 客户端的设备上挂载和使用,它是基于云的共享文件系统。可以多设备、跨地区、跨网络同时读写访问。
现在你可以在任何安装了 JuiceFS 客户端的设备上挂载使用这个文件系统,以下是几种常用的访问方式:
# 以 FUSE POSIX 方式挂载
juicefs mount rediss://:[email protected]/1 mnt
# 以 S3 Gateway 形式挂载
export MINIO_ROOT_USER=admin
export MINIO_ROOT_PASSWORD=12345678
juicefs gateway rediss://:[email protected]/1 localhost:9000
# 以 WebDAV 形式挂载
juicefs webdav rediss://:[email protected]/1 localhost:8000
可以看到,挂载 JuiceFS 文件系统时只需指定元数据引擎 URL,不再需要对象存储相关的信息。这是因为在创建文件系统的时候,对象存储相关的信息已经被写入了元数据引擎。
在 Colab 中挂载 JuiceFS
如下图,Colab 运行时的底层是一个 Ubuntu 系统,所以,只需要在 Colab 上安装 JuiceFS 客户端,执行挂载命令即可使用。
可以将安装命令和挂载命令放在一个代码块中,也可以像下图这样,将它们分成两个独立的代码块。

请注意,挂载 JuiceFS 时不要忘记 -d 选项,它的作用是让 JuiceFS 以守护进程的方式挂载到后台。因为 Colab 每次只允许一个代码块运行,如果不将 JuiceFS 挂载到后台,他就会一直让代码块处于运行状态,导致其他代码块无法运行。
如下图,左侧文件管理器中可以看到已挂载的 JuiceFS 文件系统。
使用举例
例一:用 JuiceFS 保存 Fooocus 模型
Fooocus 是开源的 AI 图片生成器,底层仍然使用 Stable Diffusion 模型,但将复杂的参数进行了调优和封装,让用户可以获得像 Midjourney 一样简单直观的作图体验。
你可以直接使用 Fooocus 官方提供的 Colab Notebook,在其基础上添加安装和挂载 JuiceFS 文件系统的代码块。
也可以参考以下代码更灵活地创建和管理 Fooocus 相关的代码:
# 安装 JuiceFS 客户端
!curl -sSL https://d.juicefs.com/install | sh -
# 挂载 JuiceFS 文件系统
!juicefs mount rediss://:[email protected]/1 myjfs -d
# 在 JuiceFS 中创建 Fooocus 模型目录结构
!mkdir -p myjfs/models/{checkpoints,loras,embeddings,vae_approx,upscale_models,inpaint,controlnet,clip_vision}
# 克隆 Fooocus 仓库
!git clone https://github.com/lllyasviel/Fooocus.git
在 Fooocus 项目根目录创建一个自定义的 config.txt 文件,让 Fooocus 以 JuiceFS 中的目录作为默认的模型存储目录:
{
"path_checkpoints": "/content/myjfs/models/checkpoints",
"path_loras": "/content/myjfs/models/loras",
"path_embeddings": "/content/myjfs/models/embeddings",
"path_vae_approx": "/content/myjfs/models/vae_approx",
"path_upscale_models": "/content/myjfs/models/upscale_models",
"path_inpaint": "/content/myjfs/models/inpaint",
"path_controlnet": "/content/myjfs/models/controlnet",
"path_clip_vision": "/content/myjfs/models/clip_vision"
}
启动 Fooocus
!pip install pygit2==1.12.2
%cd /content/Fooocus
!python entry_with_update.py --share
初次使用需要从公共仓库下载模型,这会需要一些时间,你可以在本地同时挂载 JuiceFS 文件系统,观察模型保存的情况。
再次使用时,只需挂载 JuiceFS 文件系统并确保 Fooocus 可以从中读取模型。程序会动态地从 JuiceFS 拉取所需的模型,尽管这仍然需要一些时间,但相比每次都从公共仓库完全重新下载要更加方便。特别是模型经过微调或产生了自定义数据情况,使用 JuiceFS 保存相应数据的优势就会更加明显。
例二:用 JuiceFS 保存 Chroma 向量数据库
在 Colab 上构建 RAG(检索增强生成)应用也是比较常见的,这往往涉及到要把各种资料生成的 embedding 数据保存到向量数据库。
Llamaindex 默认采用 OpenAI 的 text-embedding 模型对输入的数据进行向量化,如果不想每次都重新生成 embedding 数据,就需要将这些数据保存到向量数据库。比如使用开源的 Chroma 向量数据库,因为它默认将数据保存在本地磁盘,在 Colab 中需要注意数据库的保存位置,以防运行时收回造成数据丢失。
这里笔者提供一组 Colab 笔记本代码,让你可以将 Llamaindex 生成的 embedding 保存到 Chroma 数据库,而这个 Chroma 数据库将完全保存到 JuiceFS。
# 安装 JuiceFS 客户端
!curl -sSL https://d.juicefs.com/install | sh -
# 挂载 JuiceFS 文件系统
!juicefs mount rediss://:[email protected]/1 myjfs -d
# 安装 Llamaindex 和 chroma 相关的包
!pip install llama-index chromadb kaleido python-multipart pypdf cohere
# 从 Colab 环境变量读取 OpenAI API 密钥
from google.colab import userdata
import openai
openai.api_key = userdata.get('OPENAI_API_KEY')
把需要转换成 embedding 的文件放在 myjfs/data/ 目录中,执行以下代码生成 embedding 并保存到 Chroma。
得益于 JuiceFS 基于云的共享访问特性,可以同时在本地挂载 JuiceFS 并将所需的资料放入相应的目录。
import chromadb
from llama_index import VectorStoreIndex, SimpleDirectoryReader
from llama_index.vector_stores import ChromaVectorStore
from llama_index.storage.storage_context import StorageContext
# load some documents
documents = SimpleDirectoryReader("./myjfs/data").load_data()
# initialize client, setting path to save data
db = chromadb.PersistentClient(path="./myjfs/chroma_db")
# create collection
chroma_collection = db.get_or_create_collection("great_ceo")
# assign chroma as the vector_store to the context
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# create your index
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context,
embed_model_name="text-embedding-3-small",
)
使用时,直接让 Chroma 从 JuiceFS 读取数据。
import chromadb
from llama_index import VectorStoreIndex, SimpleDirectoryReader
from llama_index.vector_stores import ChromaVectorStore
from llama_index.storage.storage_context import StorageContext
# initialize client, setting path to save data
db = chromadb.PersistentClient(path="./myjfs/chroma_db")
# create collection
chroma_collection = db.get_or_create_collection("great_ceo")
# assign chroma as the vector_store to the context
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# 从向量数据库加载索引
index = VectorStoreIndex.from_vector_store(
vector_store, storage_context=storage_context
)
测试一下用自己 Index 作为知识库与 GPT 进行对话:
# create a query engine and query
query_engine = index.as_query_engine()
response = query_engine.query("这本书讲了什么?")
print(response)
这样一来,每次进入新的 Colab 运行时,只要挂载 JuiceFS 就可以直接使用这些已创建的向量数据。其实,不止是在 Colab,任何需要访问这些向量数据的地方都可以通过挂载 JuiceFS 来使用。
总结
本文介绍了如何在 Google Colab 中使用 JuiceFS 来持久化保存数据,通过实例介绍了如何为 JuiceFS 准备元数据引擎和对象存储来尽量发挥它的性能,以及在 Colab 中的安装和挂载方法。最后通过 Fooocus 和 Chroma 两个例子,演示了在实际应用中如何利用 JuiceFS 来更好地保存并重复利用数据。
希望这篇文章的内容能够对你起到一定的帮助,如果你有任何疑问,欢迎在评论区留言讨论。如果你对 JuiceFS 有兴趣,可以查看官方文档了解更多用法和性能调优方面的内容。
希望这篇内容能够对你有一些帮助,如果有其他疑问欢迎加入 JuiceFS 社区与大家共同交流。
