















GlusterFS is an open-source software-defined distributed storage solution. It can support data storage of PiB levels within a single cluster.
JuiceFS is an open-source, high-performance distributed file system designed for the cloud. It delivers massive, elastic, and high-performance storage at low cost.
This article compares the key attributes of JuiceFS and GlusterFS in a table and then explores them in detail, offering insights to aid your team in the technology selection process. You can easily see their main differences in the table below and delve into specific topics you're interested in within this article.
A quick summary of GlusterFS vs. JuiceFS
The table below provides a quick overview of the differences between GlusterFS and JuiceFS:
| Aspect | GlusterFS | JuiceFS |
|---|---|---|
| Metadata | Purely distributed | Independent database |
| Data storage | Self-managed | Relies on object storage |
| Large file handling | Doesn't split files | Splits large files |
| Redundancy protection | Replication, erasure coding | Relies on object storage |
| Data compression | Partial support | Supported |
| Data encryption | Partial support | Supported |
| POSIX compatibility | Full | Full |
| NFS protocol | Not directly supported | Not directly supported |
| CIFS protocol | Not directly supported | Not directly supported |
| S3 protocol | Supported (but not updated) | Supported |
| HDFS compatibility | Supported (but not updated) | Supported |
| CSI Driver | Supported | Supported |
| POSIX ACLs | Supported | Not supported |
| Cross-cluster replication | Supported | Relies on external service |
| Directory quotas | Supported | Supported |
| Snapshots | Supported | Not supported (but supports cloning) |
| Trash | Supported | Supported |
| Primary maintainer | Red Hat, Inc | Juicedata, Inc |
| Development language | C | Go |
| Open source license | GPLV2 and LGPLV3+ | Apache License 2.0 |
System architecture comparison
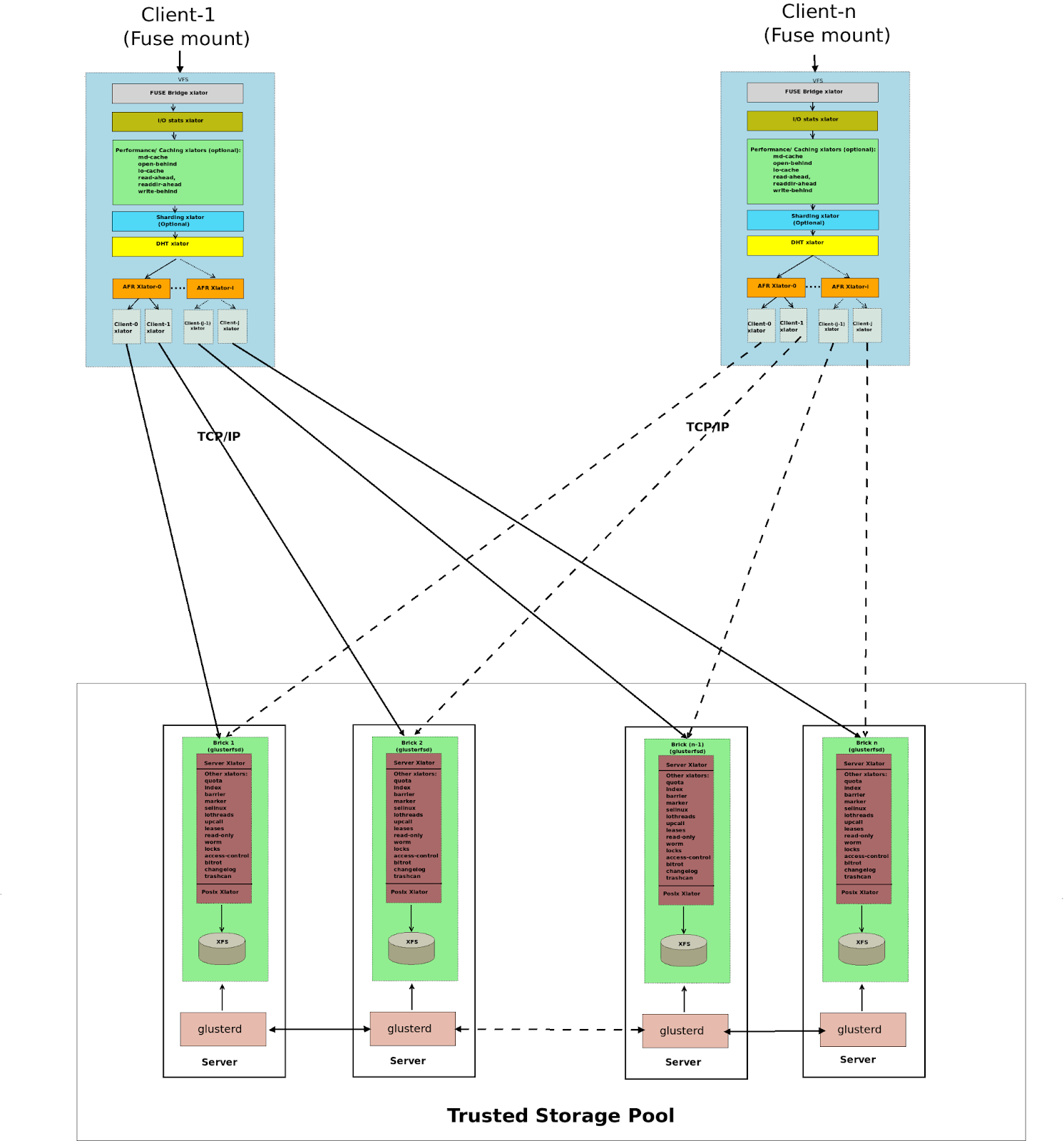
GlusterFS’ architecture
GlusterFS employs a fully distributed architecture without centralized nodes. A GlusterFS cluster consists of the server and the client. The server side manages and stores data, often referred to as the Trusted Storage Pool. This pool comprises a set of server nodes, each running two types of processes:
- glusterd: One per node, which manages and distributes configuration.
- glusterfsd: One per brick (storage unit), which handles data requests and interfaces with the underlying file system.
All files on each brick can be considered a subset of GlusterFS. File content accessed directly through the brick or via GlusterFS clients is typically consistent. If GlusterFS experiences an exception, users can partially recover original data by integrating content from multiple bricks. Additionally, for fault tolerance during deployment, data is often redundantly protected. In GlusterFS, multiple bricks form a redundancy group, protecting data through replication or erasure coding. When a node experiences a failure, recovery can only be performed within the redundancy group, which may result in longer recovery times. When scaling a GlusterFS cluster, the scaling is typically performed on a redundancy group basis.
The client side, which mounts GlusterFS, presents a unified namespace to applications. The architecture diagram is as follows (source: GlusterFS Architecture):
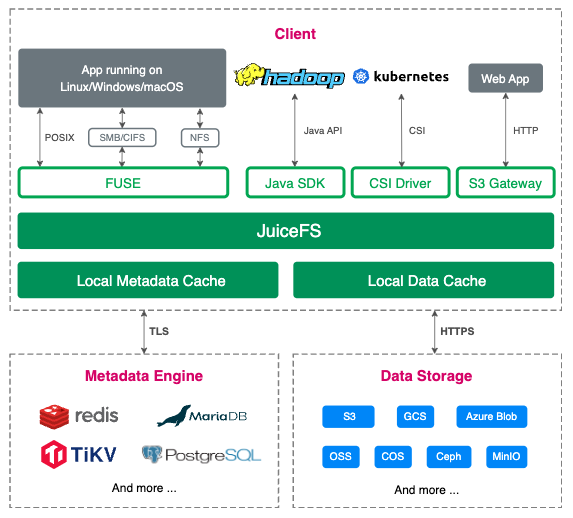
JuiceFS’ architecture
JuiceFS adopts an architecture that separates its data and metadata storage. File data is split and stored in object storage systems like Amazon S3, while metadata is stored in a user-selected database like Redis or MySQL. By sharing the same database and object storage, JuiceFS achieves a strongly consistent distributed file system with features like full POSIX compatibility and high performance. For details about JuiceFS architecture, see its document.
Metadata management comparison
GlusterFS:
Metadata in GlusterFS is purely distributed, lacking a centralized metadata service. Clients use file name hashing to determine the associated brick. When requests require access across multiple bricks, for example, mv and ls, the client is responsible for coordination. While this design is simple, it can lead to performance bottlenecks as the system scales. For instance, listing a large directory might require accessing multiple bricks, and any latency in one brick can slow down the entire request. Additionally, ensuring metadata consistency when performing cross-brick modifications in the event of failures can be challenging, and severe failures may lead to split-brain scenarios, requiring manual data recovery to achieve a consistent version.
JuiceFS: JuiceFS metadata is stored in an independent database, which is called the metadata engine. Clients transform file metadata operations into transactions within this database, leveraging its transactional capabilities to ensure operation atomicity. This design simplifies JuiceFS implementation but places higher demands on the metadata engine. JuiceFS currently supports three categories of transactional databases. For details, see the metadata engine document.
Data management comparison
GlusterFS stores data by integrating multiple server nodes' bricks (typically built on local file systems like XFS). Therefore, it provides certain data management features, including distribution management, redundancy protection, fault switching, and silent error detection.
JuiceFS, on the other hand, does not use physical disks directly but manages data through integration with various object storage systems. Most of its features rely on the capabilities of its object storage.
Large file splitting
In distributed systems, splitting large files into smaller chunks and storing them on different nodes is a common optimization technique. This often leads to higher concurrency and bandwidth when applications access such files. - GlusterFS does not split large files (although it used to support Striped Volumes for large files, this feature is no longer supported). - JuiceFS splits files into 64 MiB chunks by default, and each chunk is further divided into 4 MiB blocks based on the write pattern. For details, see How JuiceFS stores files.
Redundancy protection
GlusterFS supports both replication (Replicated Volume) and erasure coding (Dispersed Volume). JuiceFS relies on the redundancy capabilities of the underlying object storage it uses.
Data compression
GlusterFS:
- Supports only transport-layer compression. Files are compressed by clients, transmitted to the server, and decompressed by the bricks.
- Does not implement storage-layer compression but depends on the underlying file system used by the bricks, such as ZFS.
JuiceFS supports both transport-layer and storage-layer compression. Data compression and decompression are performed on the client side.
Data encryption
GlusterFS: - Supports only transport-layer encryption, relying on SSL/TLS. - Previously supported storage-layer encryption, but it is no longer supported.
JuiceFS supports both transport-layer and storage-layer encryption. Data encryption and decryption are performed on the client side.
Access protocols
POSIX compatibility
Both GlusterFS and JuiceFS offer POSIX compatibility.
NFS protocol
GlusterFS previously had embedded support for NFSv3 but now it is no longer recommended. Instead, it is suggested to export the mount point using an NFS server. JuiceFS does not provide direct support for NFS and requires mounting followed by export via another NFS server.
CIFS protocol
GlusterFS embeds support for Windows, Linux Samba clients, and macOS CLI access (excluding macOS Finder). However, it is recommended to use Samba for exporting mount points. JuiceFS does not offer direct support for CIFS and requires mounting followed by export via Samba.
S3 protocol
GlusterFS supports S3 through the gluster-swift project, but the project hasn't seen recent updates since November 2017. JuiceFS supports S3 through integration with the MinIO S3 gateway.
HDFS compatibility
GlusterFS offers HDFS compatibility through the glusterfs-hadoop project, but the project hasn't seen recent updates since May 2015. JuiceFS provides full compatibility with the HDFS API.
CSI Driver
GlusterFS previously supported CSI Driver but the latest version was released in November 2018, and the repository is marked as DEPRECATED. JuiceFS supports CSI Driver. For details, see the document.
Extended features
POSIX ACLs
In Linux, file access permissions are typically controlled by three entities: the file owner, the group owner, and others. However, when more complex requirements arise, such as the need to assign specific permissions to a particular user within the others category, this standard mechanism does not work. POSIX Access Control Lists (ACLs) offer enhanced permission management capabilities, allowing you to assign permissions to any user or user group as needed.
GlusterFS supports ACLs, including access ACLs and default ACLs. JuiceFS does not support POSIX ACLs.
Cross-cluster replication
Cross-cluster replication indicates replicating data between two independent clusters, often used for geographically distributed disaster recovery. GlusterFS supports one-way asynchronous incremental replication but requires both sides to use the same version of Gluster cluster. JuiceFS depends on the capabilities of the metadata engine and the object storage, allowing one-way replication.
Directory quotas
Both GlusterFS and JuiceFS support directory quotas, including capacity and/or file count limits.
Snapshots
GlusterFS supports volume-level snapshots and requires all bricks to be deployed on LVM thinly provisioned volumes. JuiceFS does not support snapshots but offers directory-level cloning.
Trash
GlusterFS supports the trash functionality, which is disabled by default. JuiceFS supports the trash functionality, which is enabled by default.