















Clobotics is a computer vision technology company with offices around the world. We apply computer vision and machine learning technologies to the wind power and retail industries. In the wind power sector, we use drones to inspect wind turbine blades, significantly reducing reliance on manual labor. In the retail industry, we analyze images of packaged products. In 2018, we were named to the CNBC Upstart 100 List. Initially, we used cloud SDKs for storage, and some systems employed internal wrappers. This resulted in a lack of a unified storage layer and challenges related to multi-cloud architectures, massive small files, and compatibility issues. When we transformed our storage layer, we compared HDFS, Ceph, SeaweedFS, GlusterFS, and JuiceFS. Finally, we chose JuiceFS.
JuiceFS integrates with most major public cloud platforms and efficiently handles massive small files. Its full POSIX compatibility simplifies our data workflow, cutting engineering effort and costs. Currently, JuiceFS supports our wind power and retail operations, including application access, data annotation, and model training, with further expansion to new scenarios.
In this article, we’ll dive into our storage transformation journey, covering storage requirements, the selection process, how we applied JuiceFS, and our future plans.
Our application architecture and storage requirements
We have two main application modules: wind power and retail. The figure below shows our technical architecture.
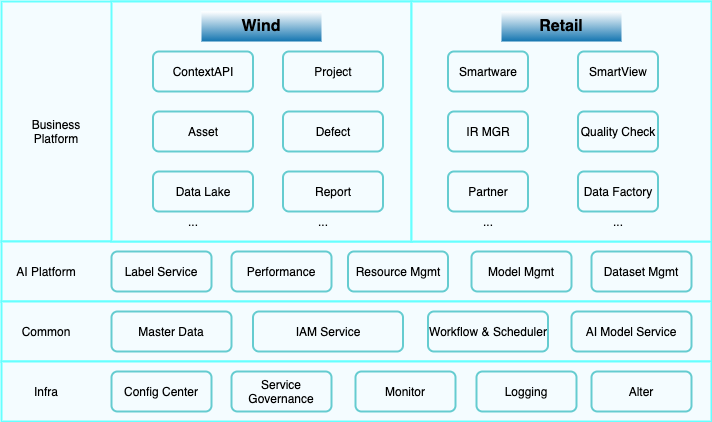
At the infrastructure layer, we use standardized service components, including the configuration center (such as Apollo), service governance center (such as Nacos), monitoring, logging, and alerting systems. These systems rely on widely recognized open-source components, such as Elasticsearch and Grafana for log and monitoring data visualization, and Prometheus for monitoring metric collection.
Above this, the common service layer focuses on centralized management of various asset data, covering multiple domains such as wind turbines in the wind power industry, stores and supermarkets in the retail industry, and our own assets like drones and retail cold storage units. In addition, the Identity and Access Management (IAM) system manages user permissions to ensure system security.
To address real-time, near-real-time, and batch processing needs during data handling, we designed and implemented a unified workflow and scheduling center. This center integrates open-source components like Apache Airflow for batch processing. We developed customized services to enhance scheduling capabilities for specific needs not fully covered by Airflow. We also abstracted AI model services to enable shared and reusable AI capabilities.
Data characteristics in computer vision scenarios
Our core data types include various collected images, which differ significantly in specifications and pixel clarity. We add about 50 million raw images each month, covering both wind power and retail fields, with the following data characteristics:
- Massive small files: In the wind power scenario, raw image files can be up to tens of megabytes in size. Even after compression, their size remains substantial. During annotation, these images need to be examined individually. To enhance network transmission efficiency and annotation workflow, we used the tile image technique, which split large images into smaller tiles similar to map tiles. However, this method resulted in a significant increase in file numbers. Especially at the lowest tile levels, the files were small but numerous. In retail scenarios, we process about 2 to 3 million tile commands per month, with peaks exceeding 500.
- Over 20 types of model training: This includes both general and domain-specific models with different iteration cycles (weekly, monthly, quarterly) to meet different scenario needs. High metadata performance requirements: Metadata files such as CSV and JS are crucial for AI model training. Model files, as key components of online services, require frequent updates and iterations. This poses higher performance demands on storage.
- Management of new data: With the continuous addition of new sites, regular updates or refreshes of these data are required. This generates extra I/O operations. Reports generated need to be temporarily stored in specific locations for user downloads or sharing.
- Version management: This is critical, particularly for raw data and image datasets. In retail scenarios, rapid customer demand changes require detailed version control of datasets. In the wind power scenario, fine-grained management of data subsets and versions is also necessary for different blade shapes.
Storage layer challenges in multi-cloud architectures
We use a multi-cloud storage solution, including Azure Blob Storage, Alibaba Cloud OSS, Google Cloud Storage (GCS), Amazon S3, and MinIO in standalone or small cluster modes. This is driven by the need to adapt to various customer environments.
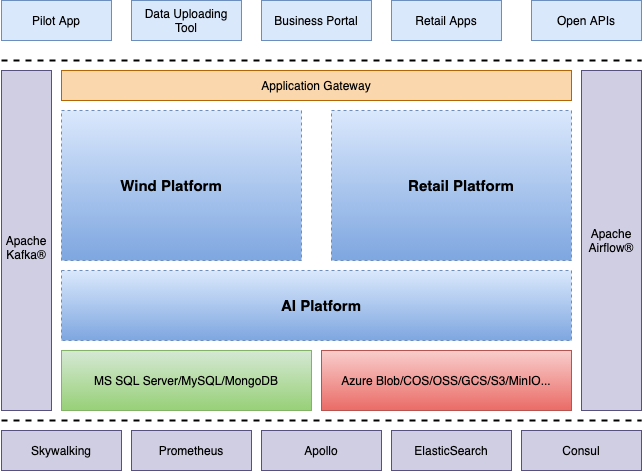
Due to different cloud service providers chosen by customers, we continuously performed adaptation work to support data access needs across various technology stacks (for example, .NET, Go, Python, C++, Java). This increased architectural complexity and operational challenges. In addition, due to functional and scenario differences between wind power and retail application platforms, we faced some degree of redundant development work. This put pressure on the startup's R&D resources.
Furthermore, in a cross-cloud architecture, data annotation and model training operations required pulling data from multiple cloud storage services. This not only added complexity to data migration but also incurred potential costs due to frequent data reads. Therefore, optimizing cross-cloud data storage and access strategies while ensuring data consistency and security became a pressing issue.
File storage selection: POSIX, cloud-native, low maintenance
Given the data characteristics of our scenarios and the challenges of multi-cloud architecture, we reevaluated how to construct a more lightweight and flexible storage layer architecture. This architecture needs to handle different application scenarios' data storage requirements and enable rapid integration of new cloud storage services with minimal or no cost.
In the initial selection process, we carefully compared mainstream and open-source storage solutions, including HDFS, Ceph, SeaweedFS, GlusterFS, and JuiceFS. The table below shows the comparing results:
| Product | POSIX-compatible | CSI Driver | Scalability | Operation cost | Documentation |
|---|---|---|---|---|---|
| HDFS | No | No | Good | High | Good |
| Ceph | Yes | Yes | Medium | High | Good |
| SeaweedFS | Basic | Yes | Medium | High | Medium |
| GlusterFS | Yes | Not mature | Medium | Medium | Medium |
| JuiceFS | Yes | Yes | Good | Low | Good |
After thorough research, we first ruled out HDFS, despite its widespread use in many companies. HDFS is designed for high-throughput big data scenarios rather than managing numerous files that need regular deletion. The NameNode in HDFS can experience significant pressure with a large number of files, and file deletion operations are costly. In addition, HDFS' lack of POSIX compatibility did not meet our requirements.
Given that most companies deploy and manage services on Kubernetes, the CSI Driver became a necessary consideration. Our data volume was only 700 TB and grew at a slow rate, so scalability was not our primary concern. However, controlling operational costs was critical. As a startup, we wanted to minimize human resources on infrastructure to focus on mission-critical areas.
When evaluating Ceph, we found it easy to install and deploy, but it has these disadvantages:
- Ceph has high operational costs, especially in capacity planning and expansion.
- Although Ceph’s documentation is extensive, it’s somewhat disorganized. This adds to the learning curve.
SeaweedFS is a good open-source project, but it has these shortcomings:
- High operational costs
- Incomplete documentation
GlusterFS has lightweight maintenance and scalability features. While building a self-managed storage layer with GlusterFS does incur some increase in operational costs, these costs are still within an acceptable range.
Ultimately, we chose JuiceFS. Its full POSIX compatibility and support for cloud-native environments caught our attention. JuiceFS has these advantages:
- Its low operational cost relies on its lightweight metadata engine such as MySQL or Redis, which was already part of our existing technology stack. This reduces operational complexity.
- JuiceFS’ clear and easy-to-understand documentation facilitates quick onboarding for newcomers.
JuiceFS application and our benefits
After we selected JuiceFS as our storage layer solution, our storage architecture has been progressively built and optimized. I’ll focus on key aspects of our practical application.
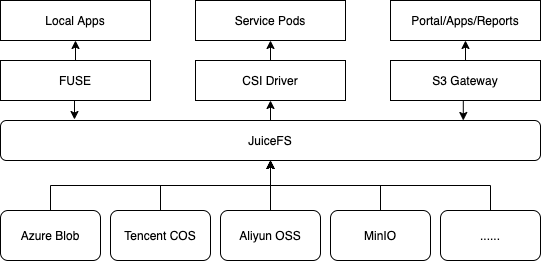
In the model training phase, the FUSE module plays a crucial role. Model training requires handling large amounts of data typically stored in the cloud. We use high-performance bare metals with sufficient GPU resources to meet computing and scheduling needs for model training. All training tasks are centralized on a single high-performance server. Thus, we use the FUSE mount method to synchronize data from various cloud storage sources to local directories, forming locally accessible storage. The largest single training dataset we handle reaches up to millions of entries, providing high data stability, primarily for rapid recognition model training in retail scenarios.
In resource management and access control, the CSI Driver application is mainly reflected in the use of mount Pods. This approach simplifies deployment and Pod organization. Through precise control by internal schedulers, it effectively avoids conflicts and concurrent read/write issues between different Pods. Although there were initial deadlock issues, we optimized dataset management and access scheduling strategies to achieve efficient concurrent control.
JuiceFS S3 Gateway turned out to be an unexpected gain after we selected JuiceFS. Originally, we planned to build an independent file service for internal file sharing but faced complex permissions and timeliness issues. The S3 Gateway not only provided role-based access control to meet basic needs but also implemented fine-grained management of shared link validity through security tokens. This effectively prevents malicious data scraping risks.
We’ve gained the following benefits from using JuiceFS:
- A unified storage layer: JuiceFS achieved our primary goal of providing a unified storage layer. This layer not only simplified data storage management but also improved overall data access efficiency.
- Flexibility in cloud storage integration: As our application grows, we can more easily integrate new cloud storage services or types without requiring large-scale adjustments to our existing architecture. This enhanced the system's scalability and adaptability.
- Simplified access management: JuiceFS’ built-in access-control list (ACL) mechanism meets our access control needs in most scenarios. Although this functionality may require additional expansion for particularly large or complex application environments, it’s sufficient for our everyday requirements.
- Cross-cloud storage version management: JuiceFS allows us to effectively manage data versions across different cloud storage services. This ensures data consistency and traceability, providing solid support for application decisions.
- Performance monitoring and optimization: With JuiceFS, we can collect and analyze performance metrics of the storage layer. This enables us to more accurately assess and optimize system performance. This capability is difficult to achieve with raw cloud storage due to the typically opaque management of raw data.
- Transparent metadata management: JuiceFS makes it easier to access and manage file metadata, such as creation and modification times. This is crucial for advanced operations like data repair and tiered storage.
- POSIX compatibility: JuiceFS’ POSIX compatibility means developers can use standard file APIs regardless of the programming language or technology stack. This eliminates the need for additional learning and enhances development efficiency and system compatibility.
- Simplified maintenance: Maintenance of JuiceFS is easy, primarily focusing on the health of metadata services like Redis or MySQL. This feature reduced maintenance complexity and minimized the risk of downtime due to improper system maintenance.
- Cost savings: A surprising benefit of JuiceFS is the significant reduction in duplicate data uploads and storage. This improvement not only lowers storage costs but also saves operational expenses by reducing unnecessary data copies. In addition, cleaning up duplicate data further boosts storage efficiency.
Our strategies for data storage and management optimization:
-
An independent instance architecture for data isolation and merging: We prioritize an independent instance architecture using different metadata engines to precisely manage various data storage needs. This approach reduces complexity and management challenges compared to building a unified large storage cluster. By allocating data to separate instances based on characteristics and usage, we facilitate quick access to specific data areas, like experimental data, and lower data recovery costs. Adding redundant nodes and retry mechanisms in model training helps quickly recover from issues, minimizing impact on training cycles.
-
Dataset version management and isolation:
- We use multi-layer directory structures and specific naming conventions to manage data versions to address frequent updates in retail scenarios.
- Using a unified prefix management system, we ensure quick location of specific dataset versions during model training or data retrieval.
- We use a hierarchical directory structure with subnode arrangements to enable efficient management and rapid combination of different dataset versions. This enhanced our data processing flexibility and efficiency.
Our future plans
We have these plans in the future:
- Optimize data warm-up process: Currently, we mount JuiceFS locally and copy data to the local directories used for model training. This method was considered inefficient in initial implementation. Given JuiceFS offers advanced features like caching and prefetching, we plan to explore and utilize these capabilities for smart data caching. This will improve dataset management and access speed.
- Optimize cross-regional data access: In certain scenarios, we need to access data located in Europe. But data protection policies restrict its transfer outside the region. While temporary access is allowed, we currently use an internally deployed CDN solution to manage this need to control costs and avoid potentially expensive native CDN services. In the future, we aim to use JuiceFS’ cache mechanism to facilitate short-term data sharing and efficient access, further optimizing cross-regional data handling.
- Deploy multiple JuiceFS instances: We’ll focus on detailed tuning and optimization. By adjusting configuration parameters, optimizing resource allocation, and monitoring performance, we aim to enhance overall system efficiency and stability. This will ensure JuiceFS can continue to effectively support our application needs.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and community on Slack.