















About Author
At Juicedata, Youpeng Tang works as a full-stack engineer and is responsible for integrating JuiceFS with the Hadoop platform.
HDFS has become the go-to choice for big data storage and is typically deployed in data center environments.
JuiceFS, on the other hand, is a distributed file system based on object storage that allows users to quickly deploy elastic file systems that can be scaled on demand in the cloud.
For enterprises considering building a big data platform in the cloud, understanding the differences and pros and cons between these two products can provide valuable insights for migrating or switching storage solutions. In this article, we will analyze the similarities and differences between HDFS and JuiceFS from multiple aspects, including technical architecture, features, and use cases.
1 Architecture
1.1 HDFS Architecture
HDFS (Hadoop Distributed File System) is a distributed file system within the Hadoop ecosystem. Its architecture consists of NameNode and DataNode. The most basic HDFS cluster is made up of one NameNode and a group of DataNodes.
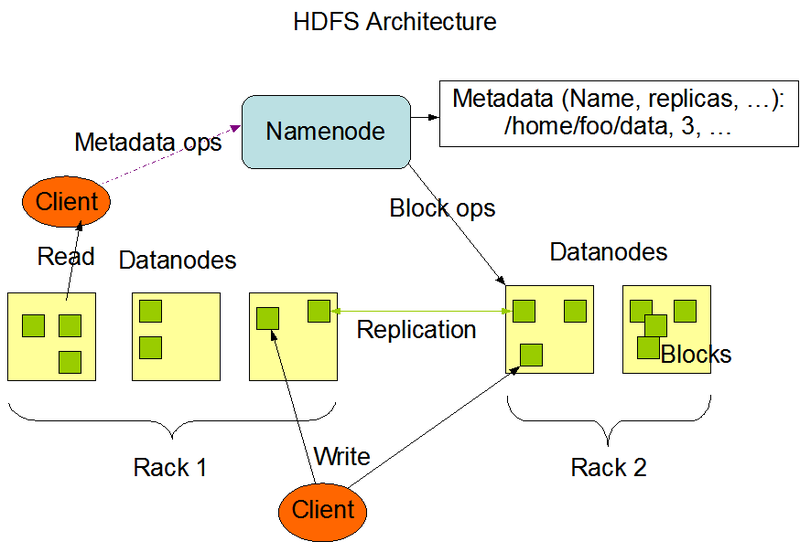
NameNode is responsible for storing file metadata and serving client requests such as create, open, rename, and delete. It manages the mapping between DataNodes and data blocks, maintaining a hierarchical structure of all files and directories, storing information such as file name, size, and the location of file blocks. In production environments, multiple NameNodes are required along with ZooKeeper and JournalNode for high availability.
DataNode is responsible for storing actual data. Files are divided into one or more blocks, each of which is stored on a different DataNode. The DataNode reports the list and status of stored blocks to the NameNode. DataNode nodes handle the actual file read/write requests and provide the client with data from the file blocks.
1.2 JuiceFS Architecture
JuiceFS community edition also splits file data into blocks, but unlike HDFS, JuiceFS stores data in the object storage (such as Amazon S3 or MinIO), while metadata is stored in a user-selected database such as Redis, TiKV, or MySQL.
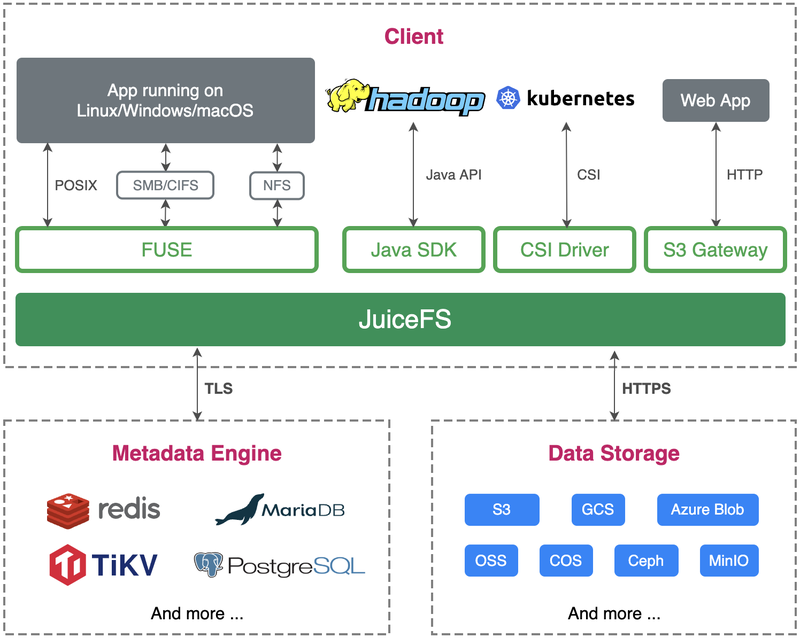
JuiceFS's metadata management is completely independent of its data storage, which means it can support large-scale data storage and fast file system operations while maintaining high availability and data consistency. JuiceFS provides Hadoop Java SDK which supports seamless switching from HDFS to JuiceFS. Additionally, JuiceFS provides multiple APIs and tools such as POSIX, S3 Gateway, and Kubernetes CSI Driver, making it easy to integrate into existing applications.
The JuiceFS Enterprise Edition shares the same technical architecture as the Community Edition but is tailored for enterprise users with higher demands for performance, reliability, and availability, providing a proprietary distributed metadata storage engine. It also includes several advanced features beyond the Community Edition, such as a web console, snapshots, cross-region data replication, and file system mirroring.
2. Basic Capabilities
2.1 Metadata
2.1.1 Metadata Storage
HDFS stores metadata in memory using FsImage and EditLog, to ensure that metadata is not lost and can be quickly recovered after a restart.
JuiceFS Community Edition employs independent third-party databases to store metadata, such as Redis, MySQL, TiKV, and others. As of the time of this writing, JuiceFS Community Edition supports a total of 10 transactional databases across three categories.
JuiceFS Enterprise Edition uses a self-developed high-performance metadata storage engine that stores metadata in memory. It ensures data integrity and fast recovery after restart through changelog and checkpoint mechanism, similar to HDFS's EditLog and FsImage.
2.1.2 Memory consumption for metadata
The metadata of each file in HDFS takes up approximately 300 bytes of memory space.
When Redis is used as the metadata engine in JuiceFS Community Edition, the metadata of each file takes up approximately 300 bytes of memory space.
For JuiceFS Enterprise Edition, the metadata of each file for hot data takes up approximately 300 bytes of memory space. JuiceFS Enterprise Edition supports memory compression, and for infrequently used cold data, memory usage can be reduced to around 80 bytes per file.
2.1.3 Scaling metadata
If metadata service cannot scale well, performance and reliability will degrade at a large scale.
HDFS addresses the capacity limitation of a single NameNode by using federation. Each NameNode in the federation has an independent namespace, and they can share the same DataNode cluster to simplify management. Applications need to access a specific NameNode or use statically configured ViewFS to create a unified namespace, but cross-NameNode operations are not supported.
JuiceFS Community Edition uses third-party databases as metadata storage, and these database systems usually come with mature scaling solutions. Typically, storage scaling can be achieved simply by increasing the database capacity or adding database instances.
JuiceFS Enterprise Edition also supports horizontal scaling of metadata clusters, where multiple metadata service nodes jointly form a single namespace to support larger-scale data and handle more access requests. No client modifications are required when scaling horizontally.
2.1.4 Metadata operations
HDFS resolves file paths based on the full path. The HDFS client sends the full path that needs to be accessed directly to the NameNode. Therefore, any request for a file at any depth only requires one RPC call.
JuiceFS Community Edition accesses files through inode-based path lookup, which involves searching for files layer by layer starting from the root directory until the final file is found. Therefore, depending on the file's depth, multiple RPC calls may be required, which can slow down the process. To speed up path resolution, some metadata engines that support fast path resolution, such as Redis, can directly resolve to the final file on the server side. If the metadata database used does not support fast path resolution, enabling metadata caching can speed up the process and reduce the load on metadata services. However, enabling metadata caching changes the consistency semantics and requires further adjustments based on the actual scenario.
JuiceFS Enterprise Edition supports server-side path resolution, requiring only one RPC call for any file at any depth.
2.1.5 Metadata cache
Metadata caching can significantly improve the performance and throughput of a file system. By storing the most frequently used file metadata in the cache, the number of RPC calls will significantly decrease, hence improving performance.
HDFS does not support client-side metadata caching.
Both JuiceFS Community and Enterprise Editions support client-side metadata caching to accelerate metadata operations such as open, list, and getattr, and reduce the workload on the metadata server.
2.2 Data management
2.2.1 Data storage
In HDFS, files are stored in 128MB blocks with three replicas on three different DataNodes for fault tolerance. The number of replicas can be adjusted by modifying the configuration. In addition, HDFS supports Erasure Coding, an efficient data encoding technique that provides fault tolerance by splitting data blocks into smaller chunks and encoding them for storage. Compared to replication, erasure coding can save storage space but will increase computational load.
On the other hand, JuiceFS splits data into 4MB blocks and stores them in object storage. For big data scenarios, it introduces a logical block of 128MB for computational task scheduling. Since JuiceFS uses object storage as the data storage layer, data reliability depends on the object storage service used, which generally provides reliability assurance through technologies such as replication and Erasure Coding.
2.2.2 Data cache
In HDFS, specified data can be cached in the off-heap memory of DataNodes on the server-side to improve the speed and efficiency of data access. For example, in Hive, small tables can be cached in the memory of DataNodes to improve join speed.
On the other hand, JuiceFS's data persistence layer resides on object storage, which usually has higher latency. To address this issue, JuiceFS provides client-side data caching, which caches data blocks from object storage on local disks to improve the speed and efficiency of data access.
JuiceFS Enterprise Edition not only provides basic client-side caching capabilities but also offers cache sharing functionality, allowing multiple clients to form a cache cluster and share local caches. In addition, JuiceFS Enterprise Edition can also set up a dedicated cache cluster to provide stable caching capabilities for unstable compute nodes (like Kubernetes).
2.2.3 Data Locality
HDFS stores the storage location information for each data block, which can be used by resource schedulers such as YARN to achieve affinity scheduling.
JuiceFS supports using local disk cache to accelerate data access. It calculates and generates preferred location information for each data block based on a pre-configured list of compute nodes, allowing resource schedulers like YARN to allocate compute tasks for the same data to the same fixed node, thereby increasing the cache hit rate.
JuiceFS Enterprise also supports sharing data cache between multiple compute nodes, called distributed cache. Even if a compute task is not scheduled to the preferred node, it can still access cached data through distributed cache.
3. Features
3.1 Data consistency
Both HDFS and JuiceFS ensure strong consistency for their metadata (CP systems), providing strong consistency guarantees for the file system data.
JuiceFS supports client-side caching of metadata. When client caching is enabled, it may impact data consistency and should be carefully configured for different scenarios.
For read-write scenarios, both HDFS and JuiceFS provide close-to-open consistency, which ensures that newly opened files can read data previously written by files that have been closed. However, when a file is kept open, it may not be able to read data written by other clients.
3.2 Data Reliability
When writing data to HDFS, applications typically rely on closing files successfully to ensure data is persistent, this is the same for JuiceFS.
To provide low-latency data writes for HBase, typically used for HBase's WAL files, HDFS provides the hflush method to sacrifice data persistence (writing to memory on multiple DataNodes) to achieve low latency.
JuiceFS's hflush method will persist data to the client's cache disk (this is JuiceFS Client write cache, also called writeback mode), relying on the performance and reliability of the cache disk. Additionally, when the upload speed to the object storage is insufficient or client exits prematurely, it may cause data loss, affecting HBase's fault recovery ability.
To ensure higher data reliability, HBase can use HDFS's hsync interface to ensure data persistence. JuiceFS also supports hsync, in which JuiceFS will persist data to the object storage.
3.3 Concurrent Read and Write
Both HDFS and JuiceFS support concurrent reading of a single file from multiple machines, which can provide relatively high read performance.
HDFS does not support concurrent writing to the same file. JuiceFS, on the other hand, supports concurrent writing, but the application needs to manage the offset of the file itself. If multiple clients simultaneously write to the same offset, these operations will overwrite each other.
Both for HDFS and JuiceFS, if multiple clients simultaneously open a file, one client modifies the file, and other clients may not be able to read the latest modification.
3.4 Security
Kerberos is used for identity authentication. Both HDFS and JuiceFS Enterprise Edition support it. However, the JuiceFS community version only supports authenticated usernames and cannot verify user identities.
Apache Ranger is used for authorization. Both HDFS and JuiceFS Enterprise Edition support it, but the JuiceFS community version does not.
Both HDFS and JuiceFS Enterprise Edition support setting additional access rules (ACL) for directories and files, but the JuiceFS community version does not.
3.5 Data Encryption
HDFS has implemented transparent end-to-end encryption. Once configured, data read and written by users from special HDFS directories are automatically encrypted and decrypted without requiring any modifications to the application code, making the process transparent to the user. For more information, see "Apache Hadoop 3.3.4 - Transparent Encryption in HDFS".
JuiceFS also supports transparent end-to-end encryption, including encryption in transit and encryption at rest. When static encryption is enabled, users need to manage their own key, and all written data will be encrypted based on this key. For more information, see "Data Encryption". All of these encryption applications are transparent and do not require modifications to the application code.
3.6 Snapshot
Snapshots in HDFS refer to read-only mirrors of a directory that allow users to easily access the state of a directory at a particular point in time. The data in a snapshot is read-only and any modifications made to the original directory will not affect the snapshot. In HDFS, snapshots are implemented by recording metadata information on the filesystem directory tree and have the following features:
- Snapshot creation is instantaneous: the cost is O(1) and does not include node lookup time.
- Additional memory is used only when modifications are made relative to the snapshot: memory usage is O(M), where M is the number of files/directories modified.
- Blocks in the datanodes are not copied: snapshot files record the list of blocks and file size. There is no data replication.
- Snapshots do not have any adverse impact on regular HDFS operations: modifications are recorded in reverse chronological order, so current data can be accessed directly. Snapshot data is calculated by subtracting the modified content from the current data.
Furthermore, using snapshot diffs allows for quick copying of incremental data.
JuiceFS Enterprise Edition implements snapshot functionality in a similar way to cloning, quickly copying metadata without copying underlying data. Snapshot creation is O(N) and memory usage is also O(N). Unlike HDFS snapshots, JuiceFS snapshots can be modified.
3.7 Storage Quota
Both HDFS and JuiceFS support file and storage space quotas. JuiceFS Community Edition needs to be upgraded to the upcoming 1.1 version.
3.8 Symbolic Links
HDFS does not support symbolic links.
JuiceFS Community Edition supports symbolic links, and the Java SDK can access symbolic links created through the POSIX interface (relative paths).
JuiceFS Enterprise Edition supports not only symbolic links with relative paths but also links to external storage systems (HDFS compatible), achieving similar effects as Hadoop's ViewFS.
3.9 Directory Usage Statistics
HDFS provides the du command to obtain real-time usage statistics for a directory, and JuiceFS also supports the du command. The enterprise edition of JuiceFS can provide real-time results similar to HDFS, while the community edition needs to traverse subdirectories on the client side to gather statistics.
3.10 Elastic Scaling
HDFS supports dynamic node adjustment for storage capacity scaling, but this may involve data migration and load balancing issues. In contrast, JuiceFS typically uses cloud object storage, whose natural elasticity enables storage space to be used on demand.
3.11 Operations and Maintenance
In terms of operations and management, there are incompatibilities between different major versions of HDFS, and it is necessary to match other ecosystem component versions, making the upgrade process complex.
In contrast, both the JuiceFS community and enterprise versions support Hadoop 2 and Hadoop 3, and upgrading is simple, only requiring the replacement of jar files. Additionally, JuiceFS provides tools for exporting and importing metadata, facilitating data migration between different clusters.
4. Applicable Scenarios
When choosing between HDFS and JuiceFS, it is important to consider the different scenarios and requirements.
HDFS is more suitable for data center environments with relatively fixed hardwares, using bare metals as storage media and not requiring elastic and storage-compute separation.
However, in public cloud environments, the available types of bare metal disk nodes are often limited, and object storage has become a better storage option. By using JuiceFS, users can achieve storage-compute separation to obtain better elasticity and at the same time support most of the applications in the Hadoop big data ecosystem, making it a more efficient choice.
In addition, when big data scenarios need to share data with other applications, such as AI, JuiceFS provides richer interface protocols, making it very convenient to share data between different applications and eliminating the need for data copying, which can also be a more convenient choice.
5. Conclusion
Feature
| Feature | HDFS | JuiceFS Community Edition | JuiceFS Enterprise Edition |
|---|---|---|---|
| Release Date | 2005 | 2021 | 2017 |
| Language | Java | Go | Go |
| Open Source | Apache V2 | Apache V2 | Closed source |
| High availability | Support(depend on ZK) | Depending on Metadata engine | support |
| Metadata scaling | Independent namespace | Depending on Metadata engine | Horizontal scaling, single namespace |
| Metadata storage | Memory | Database | Memory |
| Metadata Caching | Not support | Support | Support |
| Data storage | Disk | Object storage | Object storage |
| Data caching | Datanode memory cache | Client cache | Client cache/ distributed cache |
| Data locality | Support | Support | Support |
| Data consistency | Strong consistency | Strong consistency | Strong consistency |
| Atomicity of rename | Yes | Yes | Yes |
| Append writes | Support | Support | Support |
| File truncation ( truncate) | Support | Support | Support |
| Concurrent writing | Not support | Support | Support |
| hflush(HBase WAL) | Multiple DataNodes' memory | Write cache disk | Write cache disk |
| ApacheRanger | Support | Not support | Not support |
| Kerberos authentication | Support | Not support | Not support |
| Data encryption | Support | Support | Support |
| Snapshot | Support | Not support | Support (clone) |
| Storage quota | Support | Support | Support |
| Symbolic link | Not support | Support | Support |
| Directory statistics | Support | Not supported (requires traversal) | Support |
| Elastic scaling | Manual | Automatic | Automatic |
| Operations & Maintenance | Relatively complicated | Simple | Simple |
Access protocol
| Protocl | HDFS | JuiceFS |
|---|---|---|
| FileSystem Java API | ✅ | ✅ |
| libhdfs (C API) | ✅ | ✅ |
| WebHDFS (REST API) | ✅ | ❌ |
| POSIX (FUSE or NFS) | ❌ | ✅ |
| Kubernetes CSI | ❌ | ✅ |
| S3 | ❌ | ✅ |
Although HDFS also provides NFS Gateway and FUSE-based clients, they are rarely used due to poor compatibility with POSIX and insufficient performance.