















SQL databases excel in transaction processing and consistency, making them ideal for JuiceFS metadata storage. However, their complexity has limited broader adoption.
JuiceFS v1.3-beta1 introduces key optimizations:
- Simplified transactions (20%+ faster)
- Advanced concurrency control (10x improvement)
- Enhanced connection pooling
- Optimized caching
These upgrades enable stable billion-file management while maintaining efficiency. In this article, we’ll deep dive into these optimizations, explaining the design principles and technical details behind them. In addition, we’ll offer comparative benchmark data to demonstrate the substantial improvements in performance and stability of JuiceFS in SQL metadata mode.
JuiceFS metadata engine overview
Metadata management directly impacts file system performance and stability. JuiceFS supports multiple transaction-capable engines:
| Engine type | Use case | Scale |
|---|---|---|
| File-based (such as SQLite) | Single-node mounts, read-heavy workloads | Millions of files |
| In-memory KV (such as Redis) | Multi-node mounts | ≤100 million files |
| SQL databases (such as MySQL and PostgreSQL) | Multi-node mounts, strong consistency | ≤1 billion files |
| Distributed KV (such as TiKV) | Multi-node mounts | Tens of billions of files |
Among various types of databases, SQL databases offer superior transaction processing capabilities and consistency guarantees, making them widely adopted in enterprise mission-critical applications and an ideal choice for JuiceFS metadata storage. However, due to their complex configuration and tuning requirements, users need a certain level of expertise. This limits their popularity in the community.
JuiceFS v1.3-beta1 introduces comprehensive optimizations for SQL databases, covering transaction handling, concurrency control, connection management, and cache optimization. These enhancements significantly improve SQL metadata processing efficiency, system stability, and concurrent processing capabilities. This ensures that JuiceFS Community Edition delivers more stable and efficient performance even when handling billions of files.
Simplified transaction requests: 20%+ performance boost
Optimized transaction processing mechanism (#5377)
To enhance the processing efficiency of SQL metadata under high concurrency, we first conducted a detailed analysis of the transaction execution flow. JuiceFS employs object-relational mapping (ORM) to interact with databases, supporting multiple SQL metadata types.
When executing read-write transactions, JuiceFS must ensure that repeated executions of the same SQL query within a single transaction yield consistent results—this requires the database’s transaction isolation level to be Repeatable Read. To achieve this, JuiceFS uses a transaction template to uniformly execute all SQL statements. A typical transaction template involves the following steps (each step represents a command interaction, that is, one network round-trip):
- Acquire a database connection from the connection pool or create a new one.
- Set the transaction isolation level (typically via
set transaction_isolation). - Begin the transaction (
beginorstart transaction). - Execute the first SQL query, retrieve results, and process them.
- Execute the second SQL query, retrieve results, and process them.
- Commit (
commit) or roll back (rollback) the transaction. - Return the database connection to the pool.
Upon closer inspection, we observed that many transactions contain only a single SQL query. In such cases, there is no need to set the transaction isolation level, begin the transaction, or commit/roll back the transaction.
To address this, we introduced a dedicated processing template for single-SQL query, which:
- Minimizes command interactions with the SQL metadata.
- Reduces network round-trips, improving file system access performance.
- Lightens the load on SQL metadata.
MySQL transaction mechanism optimization (#5432)
After completing the previous optimization, we observed that different databases implement transaction settings differently. For example, to ensure that the same SQL query within a transaction returns consistent results (Repeatable Read isolation level), PostgreSQL allows specifying the isolation level in the transaction start command (START TRANSACTION ISOLATION LEVEL REPEATABLE READ), without the need for additional interactions.
However, MySQL does not support this syntax—it requires a separate command (SET TRANSACTION_ISOLATION …) to set the isolation level. Further analysis revealed that the isolation level does not need to be set before every transaction. Instead, it only needs to be configured once after establishing the connection, avoiding redundant isolation-level settings for each transaction. This optimization applies exclusively to MySQL metadata, further improving transaction processing efficiency.
Performance validation
To verify the effect, we used MySQL metadata as an example and measured the Questions global metric (which counts the number of client network interactions) via show global status. The test procedure was as follows:
- Record the initial Questions value in the first query.
- Create 10,000 files and then delete them.
- Check the new Questions value and calculate the increment.
The test script (for reference only):
#!/bin/bash
/usr/local/mysql/bin/mysql -u jfs -pjfs \
-e "show global status like 'question%'"
for f in {1..10000};
do
touch testfile_${f}
done
rm -fr testfile_*
/usr/local/mysql/bin/mysql -u jfs -pjfs \
-e "show global status like 'question%'"
Results
Comparing the Questions increment between JuiceFS 1.23 and 1.3 under the same workload and application logic:
- The Questions metric dropped by over 50%.
- The execution time was reduced by about 30%.
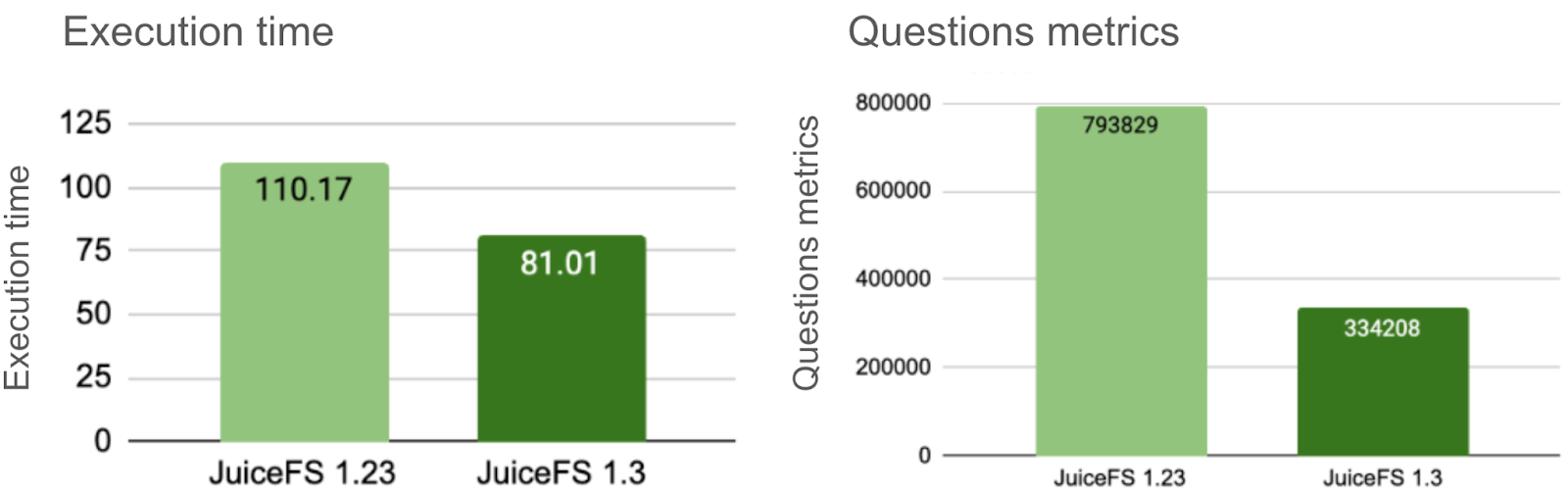
Since MySQL and the client were deployed on the same machine (local connection), the network optimization impact was limited. In real-world distributed deployments (where MySQL and clients run on separate hosts), the performance improvement in execution time would be even more pronounced.
Lock optimization: 10x improvement in single-directory concurrent performance
Concurrent processing mechanism optimization (#5460)
In a file system, when creating or deleting a file, it is necessary to update critical directory metadata (such as the NLINK value) while ensuring transactional consistency for both file and directory operations. Prior to version 1.3, JuiceFS enforced client directory-level locking for concurrency control—meaning only one session could create or delete files in the same directory at any given time. This approach limited concurrent performance, especially for large directories.
However, SQL-based metadata backends like MySQL and PostgreSQL provide robust native consistency guarantees, enabling significant improvements in large-directory concurrency performance through their built-in concurrency mechanisms.
Taking the directory's NLINK attribute as an example:
- When updating in key-value stores, due to insufficient backend guarantees, the mount point must lock the directory, retrieve the current NLINK value, increment or decrement it, and then write it back.
- When using MySQL or PostgreSQL as the backend, an atomic operation like
UPDATE ... SET NLINK = NLINK + 1 WHERE …can be used to maintain the NLINK attribute. This eliminates the need for preemptive directory locking, thereby significantly enhancing concurrent processing capabilities for large directories.
With this optimization, JuiceFS 1.3 achieves over 10x improvement in single-directory concurrency compared to previous versions. This optimization is only effective for MySQL and PostgreSQL, while other non-SQL metadata types still require the existing client directory locking mechanism.
To validate the directory concurrency improvements, we conducted stress tests using JuiceFS' built-in mdtest tool. The test was configured with shallow directory depth, high concurrency, and a large number of files in single directories. Note that this test places high resource demands on MySQL. The test command is as follows:
./juicefs mdtest META_URL testdir1 --depth=1 --dirs=2 --files=5000 --threads 50 --write 8192
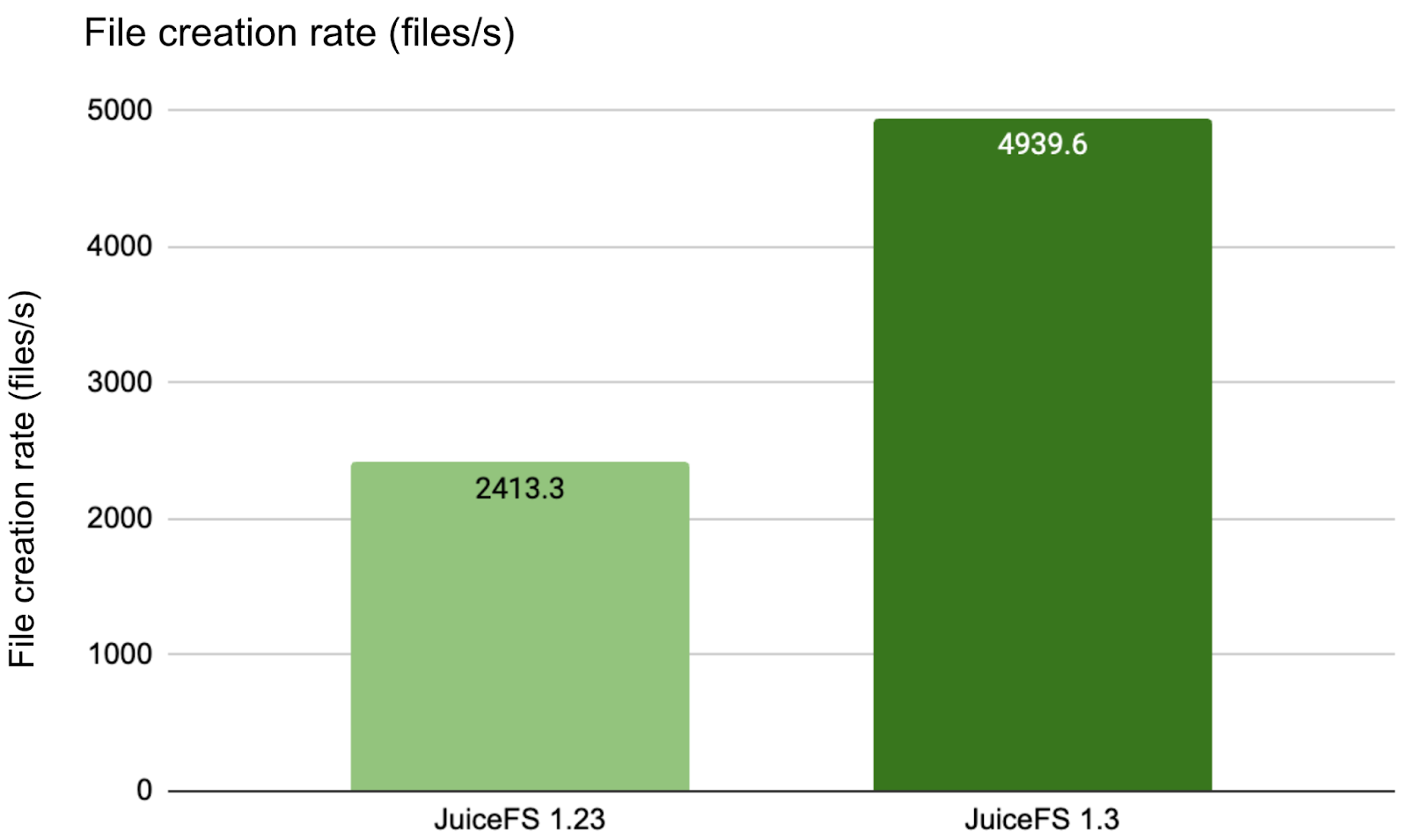
Test results comparing versions showed:
Version 1.3 demonstrated more than double the performance of version 1.23. Since this was a local test with 50 concurrent threads across three directories, the single-directory concurrency pressure wasn't extreme. Therefore, the improvement wasn't pronounced. More significant gains become apparent in networked environments with higher concurrency targeting fewer directories.
The test commands (for reference only):
2025/04/17 12:32:43.413780 juicefs[3018716] <INFO>: Create session 8 OK with version: 1.2.3+2025-01-22.4f2aba8f [base.go:398]
2025/04/17 12:32:43.414357 juicefs[3018716] <INFO>: Prometheus metrics listening on 127.0.0.1:42177 [mount.go:135]
2025/04/17 12:32:43.414725 juicefs[3018716] <INFO>: Create 750000 files in 3 dirs [mdtest.go:112]
2025/04/17 12:32:43.420143 juicefs[3018716] <INFO>: Created 3 dirs in 5.390986ms (556 dirs/s) [mdtest.go:127]
create file: 750000/750000 [==============================================================] 2413.3/s used: 5m10.781048193s
2025/04/17 12:37:54.195757 juicefs[3018716] <INFO>: Created 750000 files in 5m10.775612048s (2413 files/s) [mdtest.go:142]
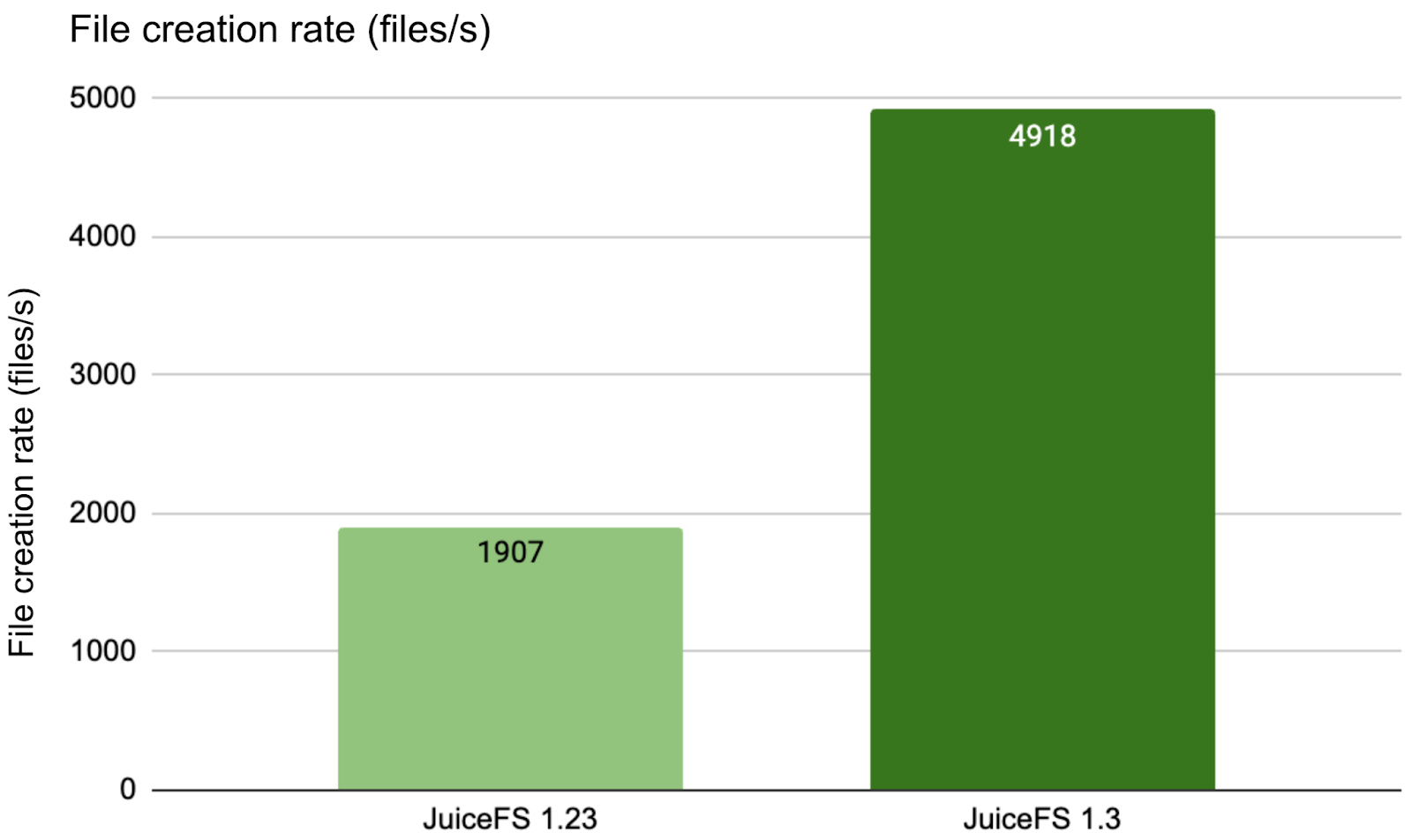
For a more focused test, we increased concurrency to 100 threads targeting a single directory:
./juicefs mdtest META_URL testdir1 --depth=0 --dirs=1 --files=1000 --threads 100 --write 8192
The results showed that the performance improvement of 1.3 over 1.23 became more evident with this configuration.
The test commands (for reference only):
2025/04/17 12:52:30.230723 juicefs[3024813] <INFO>: Create session 10 OK with version: 1.2.3+2025-01-22.4f2aba8f [base.go:398]
2025/04/17 12:52:30.232158 juicefs[3024813] <INFO>: Prometheus metrics listening on 127.0.0.1:39967 [mount.go:135]
2025/04/17 12:52:30.232479 juicefs[3024813] <INFO>: Create 100000 files in 1 dirs [mdtest.go:112]
2025/04/17 12:52:30.236389 juicefs[3024813] <INFO>: Created 1 dirs in 3.889061ms (257 dirs/s) [mdtest.go:127]
create file: 100000/100000 [==============================================================] 1907.2/s used: 52.432274105s
2025/04/17 12:53:22.664745 juicefs[3024813] <INFO>: Created 100000 files in 52.428355132s (1907 files/s) [mdtest.go:142]
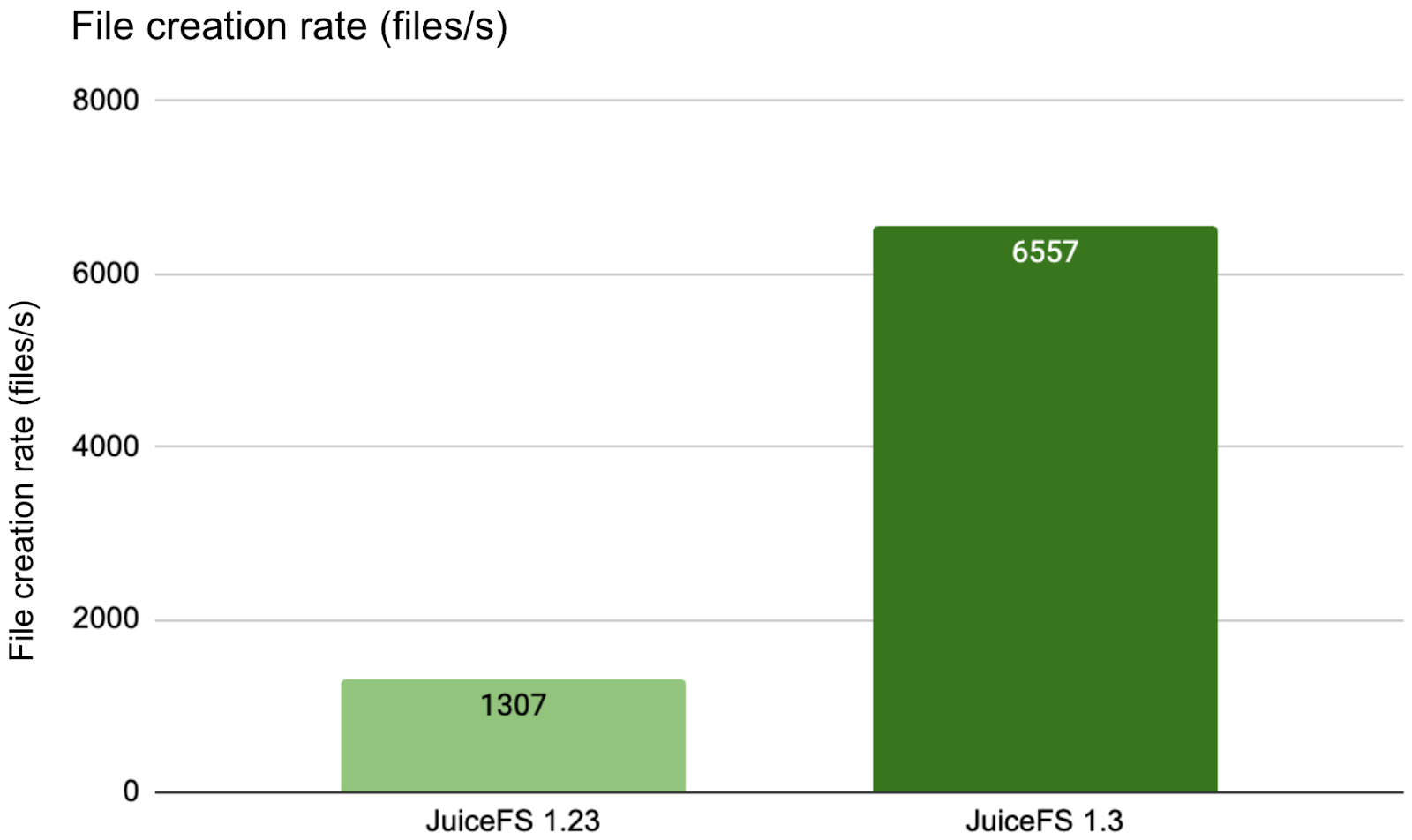
Next, we tested the metadata performance in cross-network scenarios. The results showed that in cross-network scenarios, JuiceFS 1.3 achieved about 5 times the single-directory high-concurrency throughput of version 1.23. At this point, the 8v CPU of the metadata server was fully utilized. With higher resource specifications, performance could potentially improve up to 10 times. We welcome community users to conduct more stress tests in their own environments and provide feedback.
The test commands (for reference only):
2025/04/17 13:17:29.118054 juicefs[3389620] <INFO>: Create session 18 OK with version: 1.2.3+2025-01-22.4f2aba8f [base.go:398]
2025/04/17 13:17:29.118833 juicefs[3389620] <INFO>: Prometheus metrics listening on 127.0.0.1:35563 [mount.go:135]
2025/04/17 13:17:29.119229 juicefs[3389620] <INFO>: Create 100000 files in 1 dirs [mdtest.go:112]
2025/04/17 13:17:29.125833 juicefs[3389620] <INFO>: Created 1 dirs in 6.580838ms (151 dirs/s) [mdtest.go:127]
create file: 100000/100000 [==============================================================] 1307.2/s used: 1m16.499985683s
2025/04/17 13:18:45.619253 juicefs[3389620] <INFO>: Created 100000 files in 1m16.493418414s (1307 files/s) [mdtest.go:142]
Quota-related deadlock optimization (#5706)
This issue was reported by community users. When quota limits were enabled, the system asynchronously calculated space usage level by level up the directory tree. The original logic didn't properly account for update ordering across multiple directories. JuiceFS 1.3 has optimized and refined this logic, with confirmation from the reporting user.
Connection handling optimization: Flexible configuration for improved stability
Database connection control (#5512)
Metadata operations require transaction support, and each transaction typically involves multiple SQL requests. Therefore, database connections can't be returned to the pool until all SQL operations complete. High client file operation concurrency can create excessive database connections. The resulting flood of connections and concurrent requests may overwhelm metadata service stability. Considering a file system might have hundreds or thousands of client mount points, total database connections could exceed sustainable limits. Therefore, it's necessary to limit connections per client and properly configure the database backend based on client count.
To address this, JuiceFS 1.3 introduces four new SQL meta URL options to control database connection behavior:
max-open-conns: Maximum database connections allowedmax-idle-conns: Maximum idle connections (excess connections will be closed)max-idle-time: Maximum idle connection wait time (inactive connections will be closed)max-life-time: Connection lifetime limit (prevents resource leaks from long-used connections)
Go's database/sql package provides APIs to configure these parameters without code changes. For MySQL metadata, we add these parameters to the meta URL to control maximum connections (“10” in this example):
mysql://jfs:jfs@(localhost:3306)/juicefs?max_open_conns=10
The meta URL follows standard database connection URL format. Additional parameters can be found in each database's Go driver documentation. Different databases, including Redis and TiKV, have specific options available through their respective drivers, all configurable using this same method.
Optimized dump connection consumption (#5930)
The dump feature facilitates metadata migration between different engines and file systems. To accelerate migration, a higher concurrency thread count can be configured. Previously, each thread exclusively held one or more database connections, often exceeding connection limits. JuiceFS 1.3 optimizes this by enabling high concurrency with fewer connections.
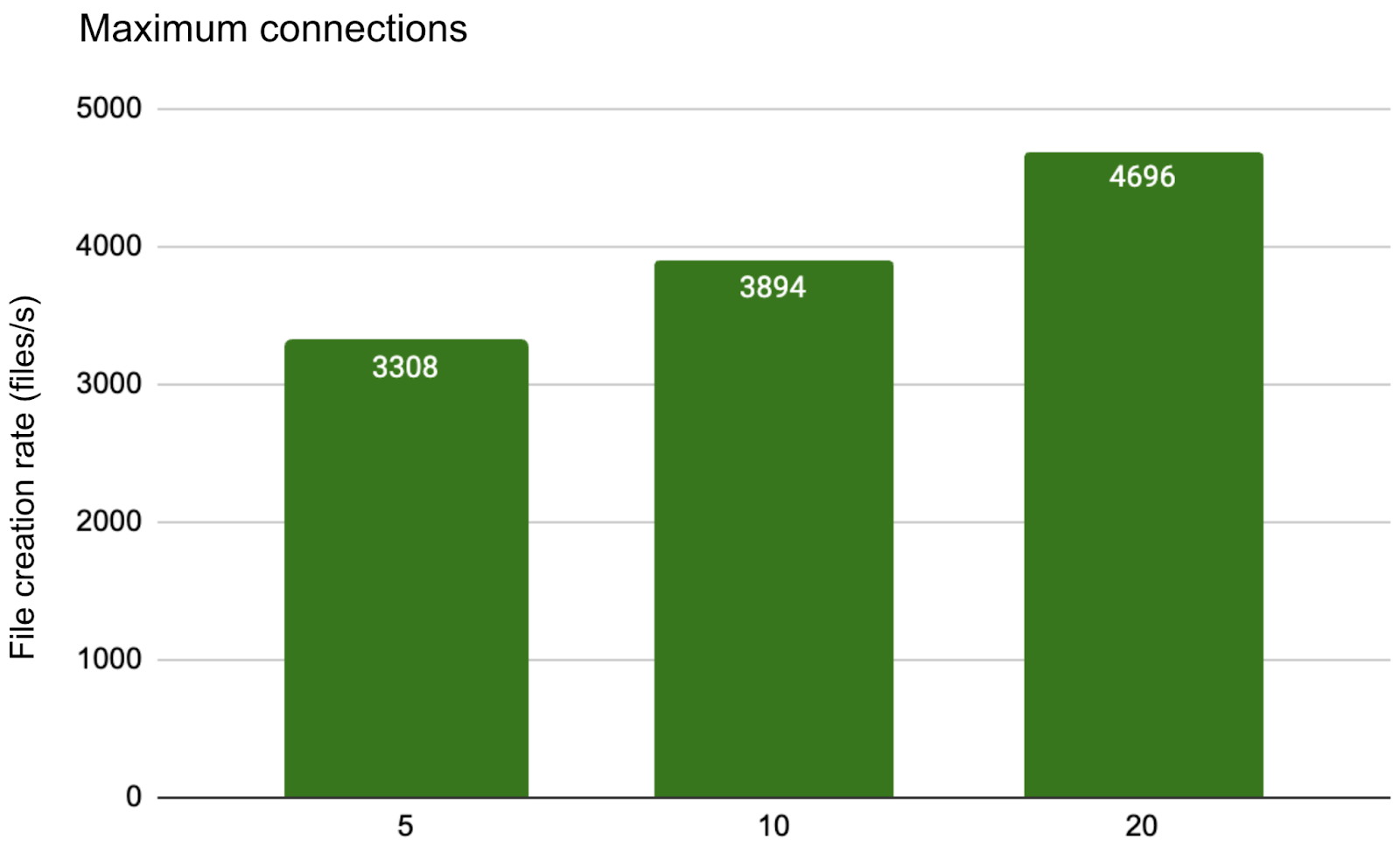
We validated the connection control improvements using the mdtest benchmark. By adding max_open_conns to META_URL, we observed:
As the maximum connections increased from 5 to 20, system throughput scaled steadily, with file creation performance improving accordingly. This demonstrates that proper connection configuration helps eliminate backend bottlenecks and enhances overall concurrency.
The test commands (for reference only):
2025/04/17 13:02:15.390685 juicefs[3029216] <INFO>: Create session 13 OK with version: 1.3.0-dev+2025-04-17.ae910a53 [[email protected]:519]
2025/04/17 13:02:15.391145 juicefs[3029216] <INFO>: Prometheus metrics listening on 127.0.0.1:43421 [[email protected]:134]
2025/04/17 13:02:15.391533 juicefs[3029216] <INFO>: Create 100000 files in 1 dirs [[email protected]:112]
2025/04/17 13:02:15.395394 juicefs[3029216] <INFO>: Created 1 dirs in 3.836901ms (260 dirs/s) [[email protected]:127]
create file: 100000/100000 [==============================================================] 3308.1/s used: 30.228489252s
2025/04/17 13:02:45.620045 juicefs[3029216] <INFO>: Created 100000 files in 30.224650745s (3308 files/s) [[email protected]:142]
Cache optimization: Fewer metadata queries, higher performance (#5540)
JuiceFS employs client metadata caching to reduce backend requests, particularly for file attributes (--attr-cache). In large-scale deployments, cache misses or invalidations could overwhelm the metadata backend with sudden query spikes.
In v1.3, we refined the lookup (lookup) and update operation (SetAttr) workflows:
- These operations now actively refresh the local
--attr-cachewith the latest metadata. - Subsequent
getattr requests benefit from cache hits, improving file system responsiveness. - Database query volume drops significantly, reducing backend pressure.
This optimization applies to all metadata types, not just SQL databases.
JuiceFS 1.3 also includes additional enhancements like error retry mechanisms. We encourage users to test SQL-backed metadata and experience these performance gains firsthand.
Download and try it now. Your feedback and suggestions are welcome!