















JuiceFS Community Edition 1.3 is released today. It marks the fourth major version since its open-source debut in 2021. Over the past four years, JuiceFS has garnered over 11.8k stars on GitHub, managed 800+ PiB of data, and been rigorously validated in enterprise production environments. With core features now highly stable, v1.3 focuses on performance and stability optimizations for large-scale, high-concurrency scenarios. This release is a long-term support (LTS) version, with ongoing maintenance for v1.3 and v1.2, while v1.1 reaches end-of-life.
In JuiceFS 1.3, we’ve introduced Python SDK support, 100 million file backup acceleration, SQL metadata engine optimizations (50% faster TiKV transactions), and Windows client enhancements. This article will walk you through these major updates and explain how they can benefit your data-intensive workloads.
Key feature highlights
Python SDK: Seamless AI integration
Python dominates AI and data science workflows. To enhance usability in these scenarios, JuiceFS Community Edition 1.3 introduces a Python SDK, streamlining access while improving compatibility in constrained environments.
In AI and data science applications, Python has become the most mainstream programming language. In order to facilitate users to use JuiceFS more efficiently in these scenarios, the JuiceFS Python SDK was launched in the community version v1.3. It not only simplifies the access to JuiceFS, but also improves the ease of use in restricted environments. For example, in the Serverless scenario, users usually cannot mount the file system themselves. With the Python SDK, data in JuiceFS can be directly read and written without mounting, which greatly improves flexibility.
For example, in serverless architectures where traditional file system mounting is restricted, the SDK enables direct read/write operations without mounting. This significantly improves flexibility.
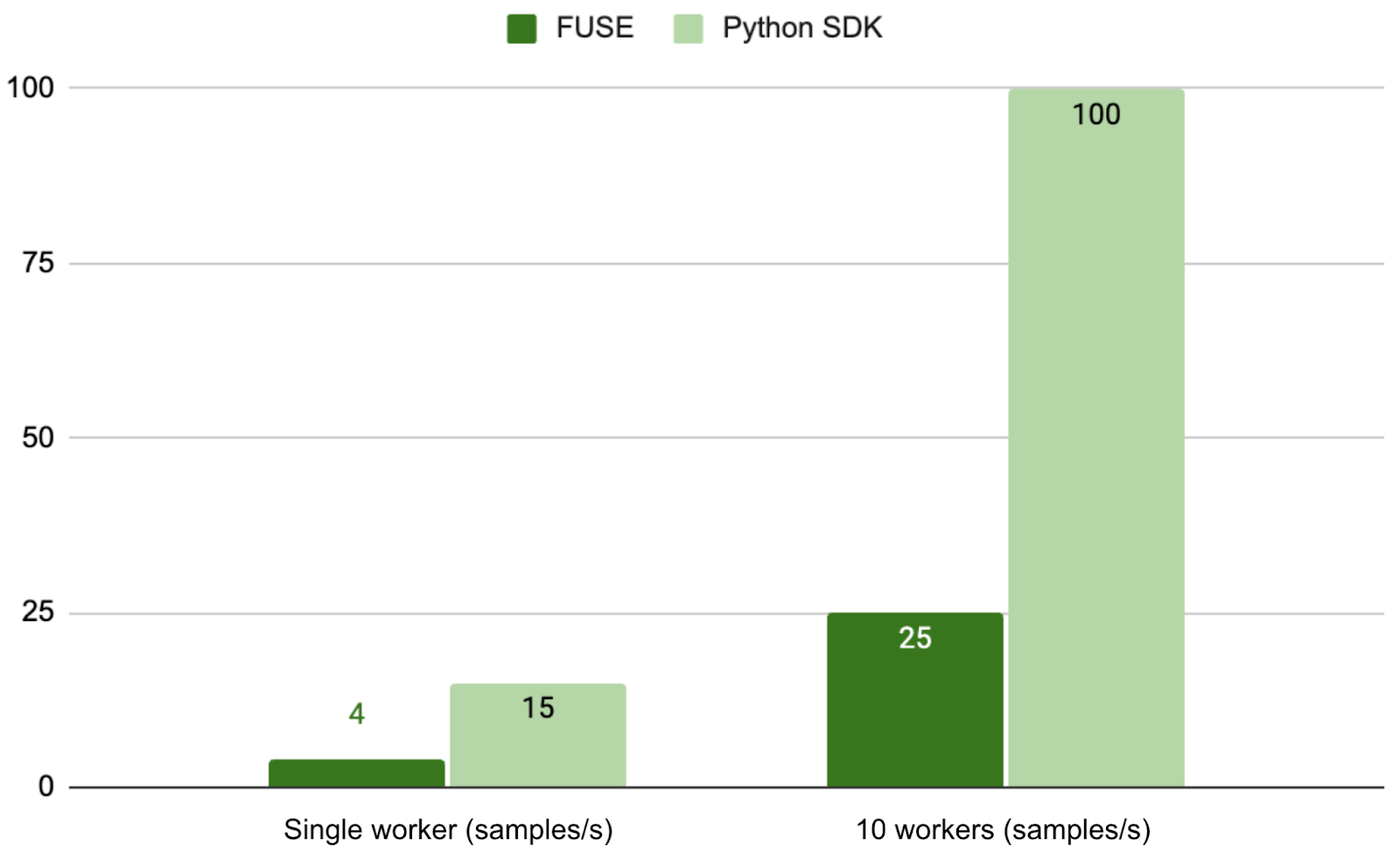
In specific high-performance scenarios, the Python SDK delivers superior performance and user experience compared to using FUSE. We’ve developed an FFRecord dataloader based on the Python SDK. In dataset testing for simulated training tasks, a read operation of 1,000 samples showed that the Python SDK improves loading performance by approximately 3.75x in single-worker scenarios and 4x in multi-worker scenarios compared to the default FUSE mount method. For details, see Introducing JuiceFS Python SDK: 3x Faster than FUSE for Data Loading.
Backup performance optimization: Minute-level completion for 100 million files
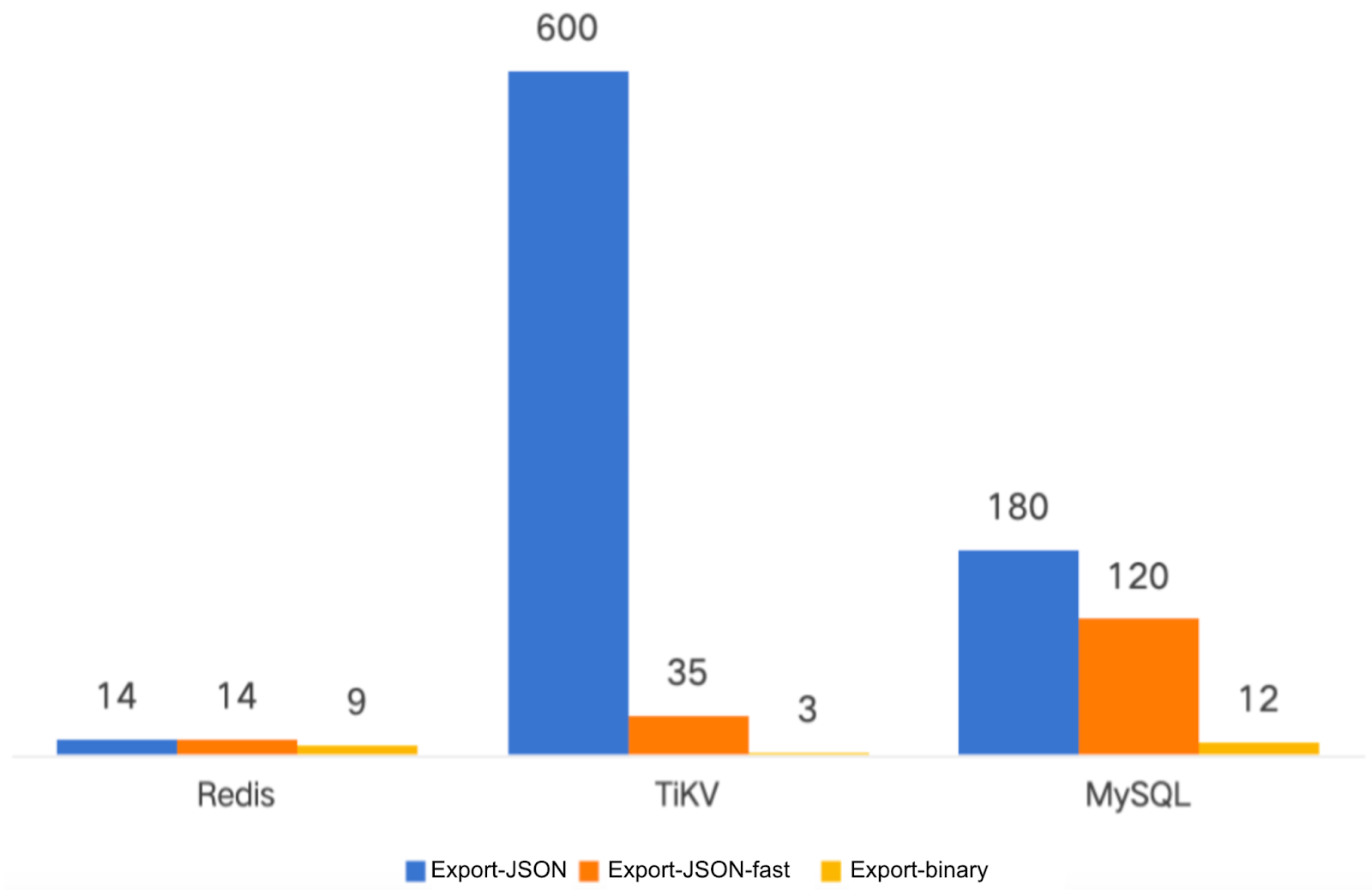
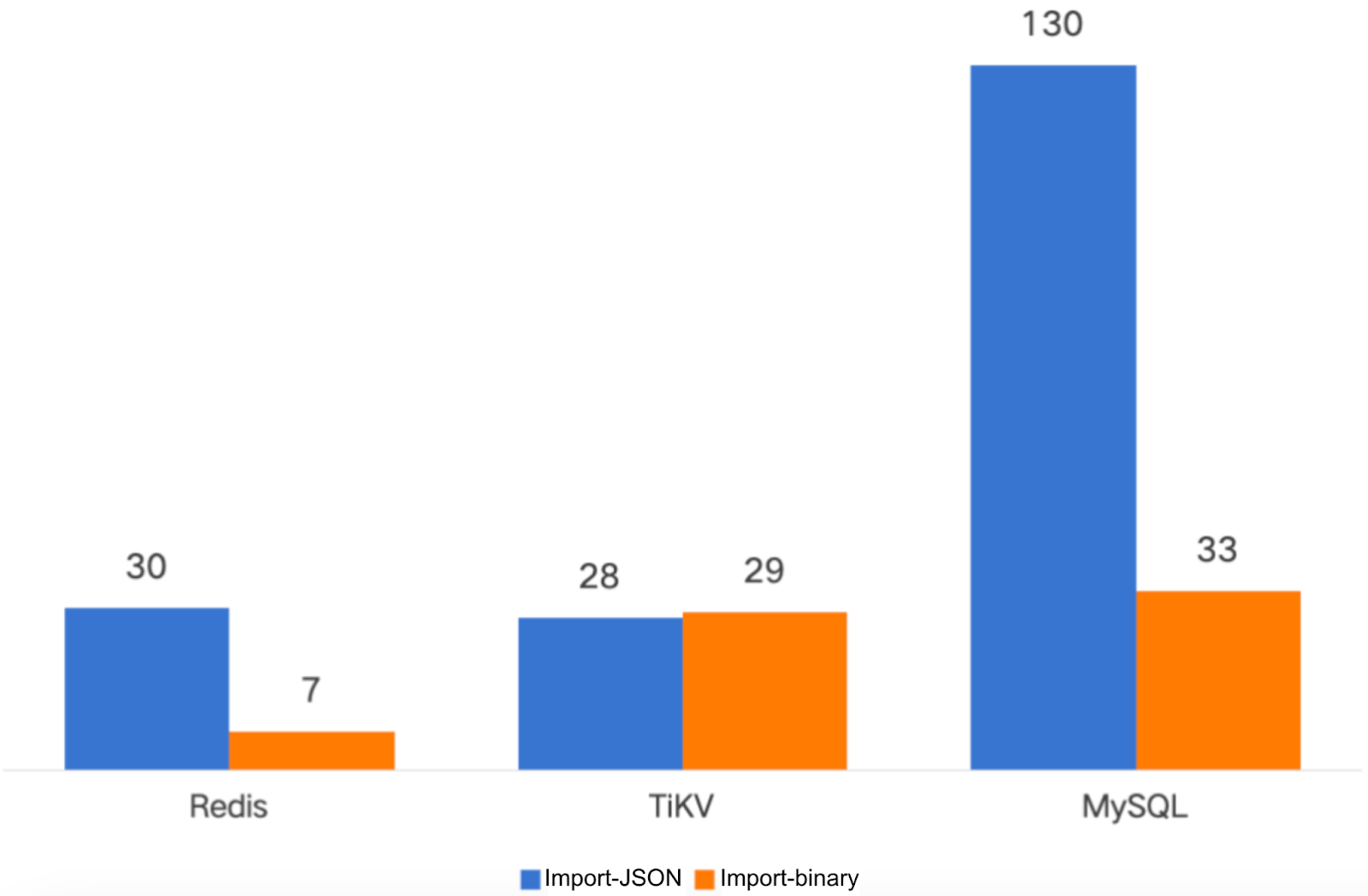
To better support backup and migration at scales of hundreds of millions of files, JuiceFS 1.3 introduces a new binary backup mechanism. Compared with the traditional JSON backup method, the new mechanism significantly improves import and export performance, while greatly reducing memory usage. It’s especially suitable for large-scale file system scenarios.
In the test of 100 million files, the binary backup solution compressed the import time to 1/10 to 1/2 of the original, and the export time was also shortened to about 1/4, bringing significant performance improvement. For details, see How JuiceFS 1.3 Backs Up 100 Million Files in Just Minutes.
Significant optimization of Windows client availability
This version update includes major optimizations and improvements to Windows clients, such as:
- Fixed Windows API compatibility issues and user identity management problems.
- Enhanced tool support, including improvements to subcommands like
debug,stat, andinfo. - The update also enables JuiceFS to be mounted directly as a system service, eliminating the need for third-party tools.
The optimization of Windows clients will be an ongoing effort. In the next release, we’ll continue dedicating more resources to further refine the Windows platform, primarily focusing on:
- Improved compatibility
- Performance optimizations
- Enhanced Active Directory domain-related features
Apache Ranger support for finer-grained permission management
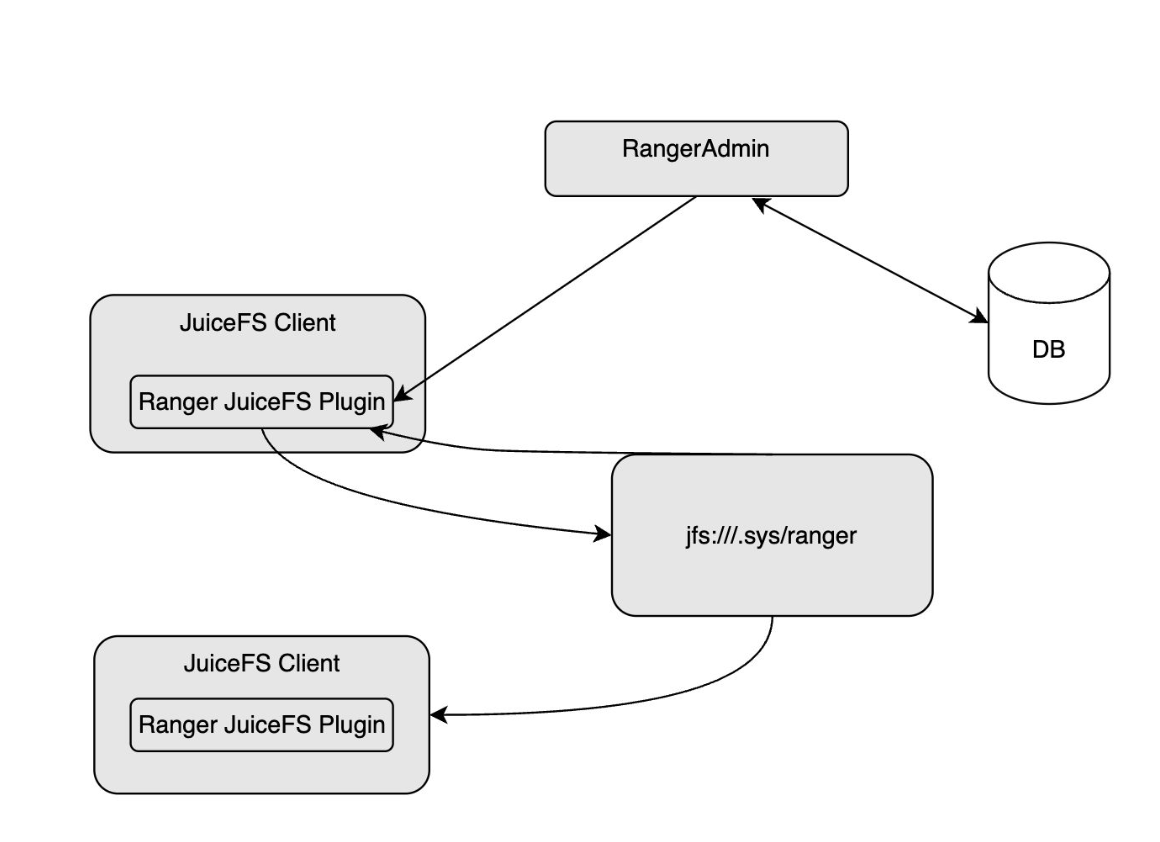
Apache Ranger is a centralized security management framework for the Hadoop ecosystem, providing fine-grained access control for components such as HDFS, Hive, and HBase.
In JuiceFS Community Edition 1.3, we introduced integration with Apache Ranger, offering users a more flexible and fine-grained permission control solution for big data scenarios. This feature was contributed by Ming Li from the Data Platform Team at DMALL. For details, see JuiceFS 1.3 Beta 2 Integrates Apache Ranger for Fine-Grained Access Control.
Metadata engine optimization: SQL capability upgrade, TiKV simple transactions 50% faster
Metadata management directly impacts the performance and stability of a file system. JuiceFS supports various transaction-capable engines, including in-memory KV stores, SQL databases, and distributed KV systems. Among these, SQL databases excel in transaction handling and consistency guarantees, making them an ideal choice for JuiceFS metadata storage in enterprise-critical systems.
However, the complexity of SQL database configuration and tuning has limited its widespread adoption in the community. In JuiceFS 1.3, we optimized SQL database support, enhancing transaction processing, concurrency control, connection management, and cache optimization. These improvements ensure greater stability and efficiency, even when handling billions of files. For details, see JuiceFS 1.3 Beta: Enhanced Support for SQL Databases, a New Option for Billion-Scale Metadata Management.
The figure below shows that in cross-network environments, v1.3 delivered 5x higher throughput for single-directory high-concurrency operations compared to v1.23.
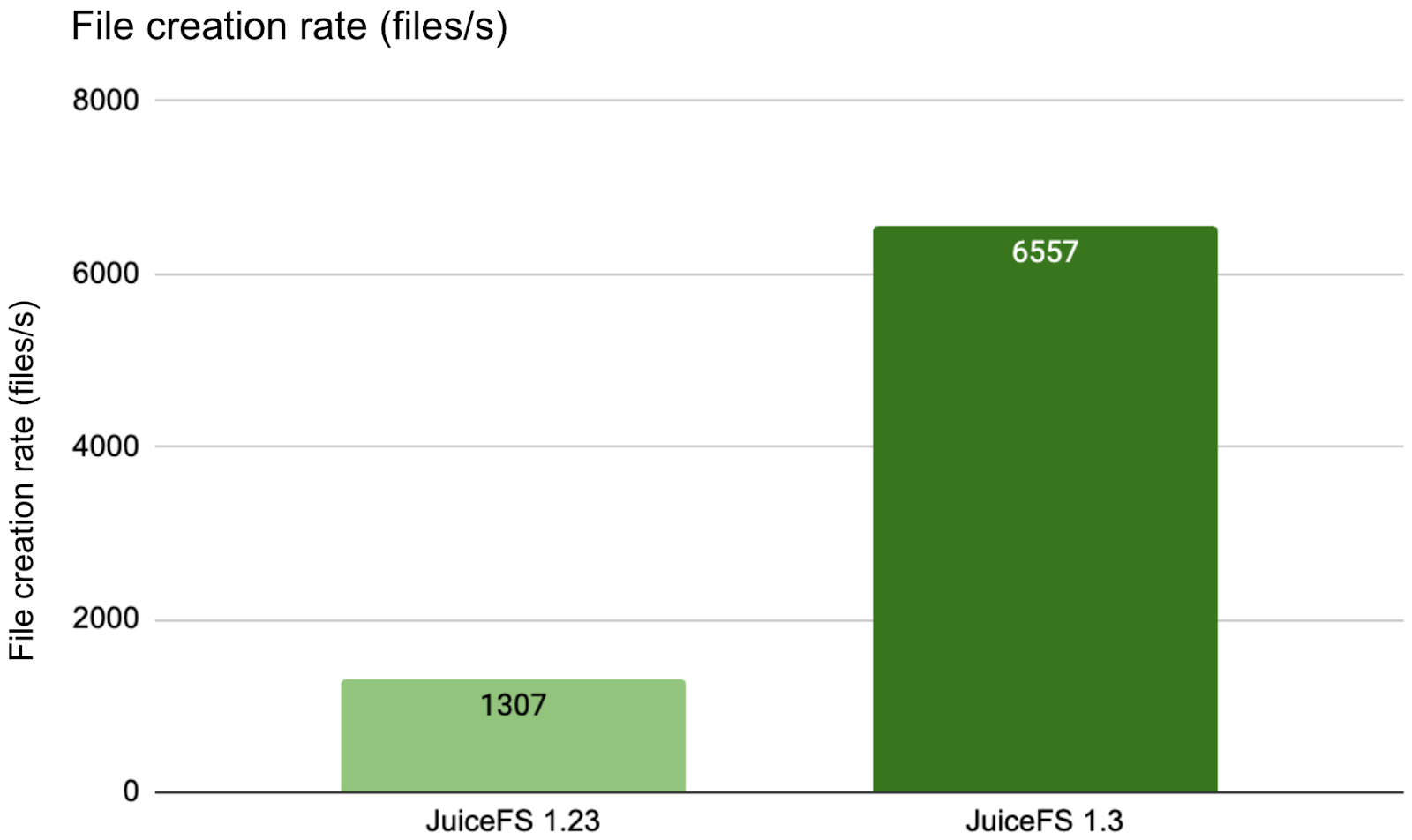
As a CNCF-graduated project, TiKV remains the most popular metadata engine among large-scale users (handling 1 billion+ files). Recently, by using TiKV's point get mode, we significantly reduced client requests to the Placement Driver (PD). This effectively lowers request overhead and latency.
In JuiceFS 1.3, we applied this optimization to simple transaction paths. Benchmark results show an average 50% performance improvement for `stat` and read operations, substantially enhancing JuiceFS' responsiveness and efficiency in hyper-large-scale TiKV deployments. This optimization was contributed by Changxin Miao from Jieyue Xingchen.
Key module optimization
Improved sync efficiency for large directories:
- Improving sync efficiency in large directory scenarios: Added the
--files-fromparameter to support reading the path list to be synchronized directly from the file, skipping the traditional list operation. It’s suitable for scenarios where the list is severely enlarged or the target file has no unified prefix. - Enhancing fault tolerance control: Introduced
--max-failureto allow users to set the maximum tolerable number of failed files. If the number exceeds the limit, the sync task will be interrupted. This is convenient for fast failure handling. - Improving sync efficiency: Optimized
--check-newmode. By streaming source checksum during transmission, it avoids repeated reading, effectively reducing read amplification. - Cluster mode stability and experience improvement
- `StrictHostKeyChecking` is disabled by default: Avoids blocking the automation script during the first connection interactive confirmation.
- Force key login: Prevents the worker from accidentally entering the password input process when there is no key configuration. This ensures that the cluster task runs fully automatically.
Gateway module enhanced S3 compatibility, interface flexibility, and concurrent upload performance:
- Feature enhancements: Added the
--object-metaparameter, supports object-level metadata (such as caching policies and content types) transmission, and improves S3 protocol compatibility. - Usability improvements: Added the
--head-dirand--hide-dir-objectparameters to provide flexible control over directory-related behaviors, accommodating different application interpretations of S3 and file system directory semantics. - Performance optimization: Introduced multi-level temporary directory structure to mitigate directory-level transaction conflicts during high-concurrency uploads, effectively reducing lock conflicts in the metadata engine and boosting upload throughput in concurrent scenarios.
In addition, JuiceFS 1.3 has optimized the performance of multiple modules:
- FUSE layer improvements
- Added support for kernel readdir cache and symlink cache.
- Optimized by filtering non-essential xattr requests to boost access efficiency.
- Metadata engine upgrades
- Enhanced streaming directory reads to reduce memory overhead from oversized requests.
- Improved concurrency handling and system stability.
- Simplified implementations of
statfsandmknodoperations for significant performance gains. - Added customizable prefetch parameters to adapt to more usage scenarios.
- Data processing layer refinements
- Accelerated list operations to mitigate read amplification in object storage.
- Improved resilience of the caching system.
Open source for five years: Powering critical AI scenarios with accelerating community growth
Over the past two years, the AI field has experienced explosive growth. As early as 2019, JuiceFS began serving AI scenarios like deep learning, with some AI users now managing single volumes exceeding hundreds of billions of files. Today, JuiceFS supports diverse AI domains, including:
- Generative AI
- AI infrastructure
- Autonomous driving
- Quantitative finance
- Biopharmaceuticals
In the past year, the community has contributed numerous real-world case studies across industries, offering valuable references for new users exploring AI applications.
New case studies:
- NFS to JuiceFS: Building a Scalable Storage Platform for LLM Training & Inference by Wei Sun from a leading research institution in China
- BioMap Cut AI Model Storage Costs by 90% Using JuiceFS by Zedong Zheng at BioMap
- JuiceFS at Trip.com: Managing 10 PB of Data for Stable and Cost-Effective LLM Storage by Songlin Wu at Trip.com
- Tongcheng Travel Chose JuiceFS over CephFS to Manage Hundreds of Millions of Files by Chuanhai Wei at Tongcheng Travel
- How Clobotics Overcame Multi-Cloud and Massive File Storage Challenges by Jonnas at Clobotics
- MemVerge Chose JuiceFS: Small File Writes 5x Faster than s3fs by Jon Jiang at MemVerge
- iSEE Lab Stores 500M+ Files on JuiceFS Replacing NFS by Guohao Xu at Sun Yat-sen University
- Hai Robotics Achieved High Availability & Easy Operations in a Hybrid Cloud Architecture with JuiceFS by Sendong Wu at Hai Robotics
- TAL: Building a Low-Operation Model Repository Based on JuiceFS in a Multi-Cloud Environment by Longhua He at Tomorrow Advancing Life (TAL)
Since open-sourcing in 2021, JuiceFS has garnered 11.8k+ GitHub stars, ranking among the fastest-growing open-source distributed storage projects globally. This remarkable growth stems from our vibrant community's collective support.
v1.3 development metrics:
- 366 new issues
- 696 pull requests merged
- 60 contributors participated
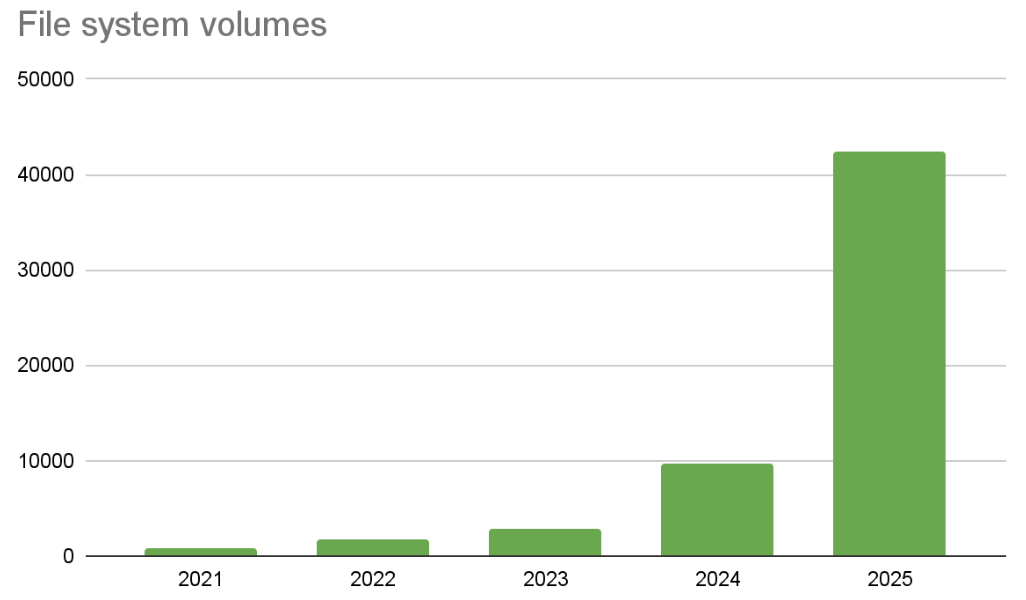
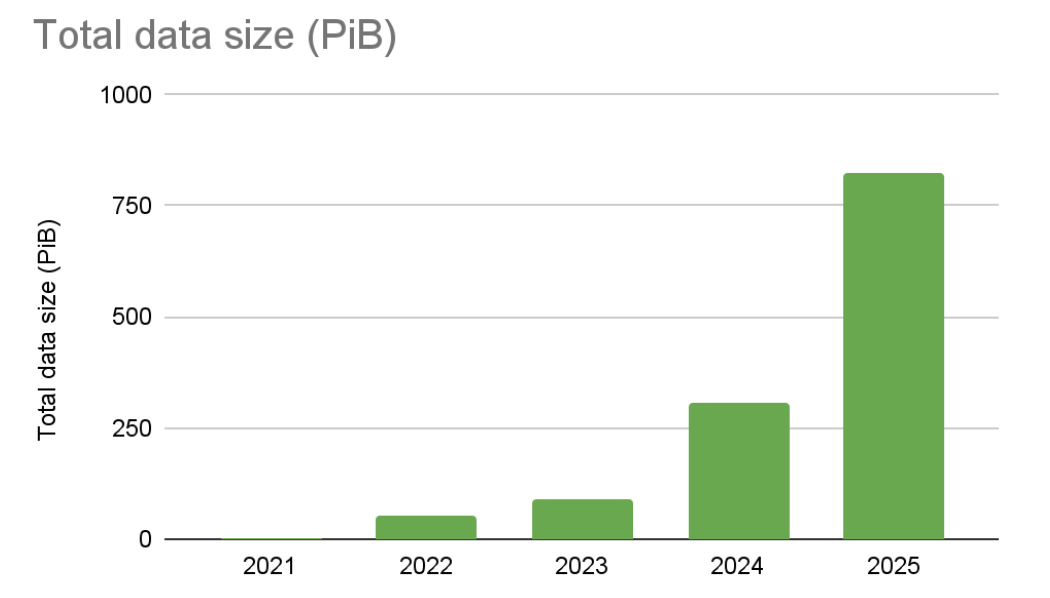
- Anonymous usage reports show:
- 40,000+ file systems
- 800+ PiB of data
- Accelerated adoption since 2023
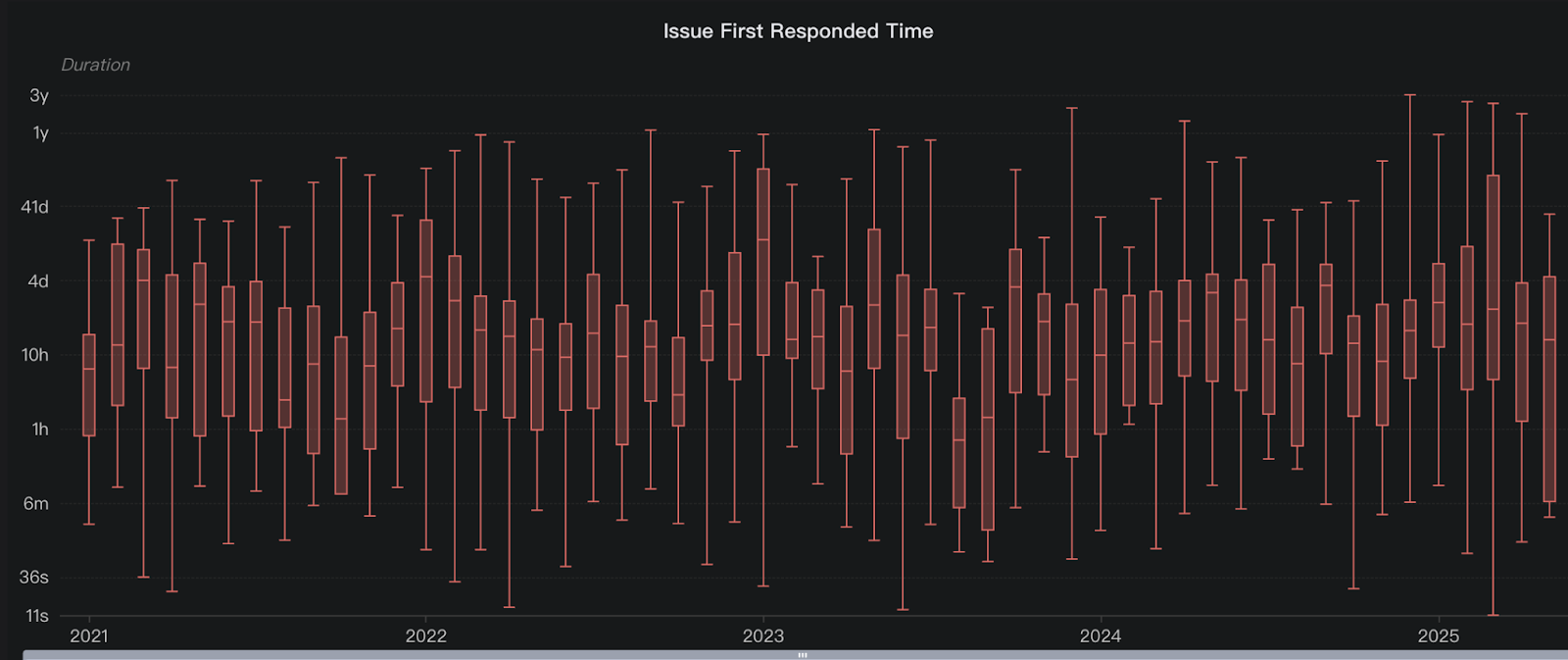
The figure below shows our median GitHub issue response time has remained consistently prompt since 2021.
Beyond GitHub:
- 30% year-on-year growth in Slack channel membership
- New Ask AI feature in documentation for instant support
Try it out
We deeply appreciate every community member who reports issues, shares use cases, contributes code, improves documentation, and helps troubleshoot.
Your participation fuels JuiceFS' evolution as a robust foundation for AI infrastructure. Join us in building the future of storage.
Download and try JuiceFS 1.3 now.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and community on Slack.