















Trip.com is a global online travel agency, offering comprehensive services such as hotel bookings, flight reservations, and railway ticketing across 50+ countries. We were honored with the 2019 Google Material Design Award: Universality for our inclusive and globally adaptable travel booking experience.
Over the past two years, with the rapid development of AI large language models (LLMs), JuiceFS, an open-source distributed file system, has gained increasing attention from AI users in our company. Currently, we manage 10 PB of data using JuiceFS, providing storage services for scenarios like AI training.
In this article, we’ll introduce our implementation of JuiceFS and key management capabilities enabled by JuiceFS (including multi-tenant permissions, billing, troubleshooting, and monitoring). Finally, we’ll compare JuiceFS with Alibaba Cloud Extreme NAS in performance and cost. Our tests show that JuiceFS delivers performance comparable to Extreme NAS in most scenarios at one-tenth the cost.
From cold storage to AI
In 2022, we adopted JuiceFS to replace GlusterFS, aiming to enhance directory listing performance for DBA teams and optimize cold data management. By integrating JuiceFS with OSS lifecycle policies, we significantly reduced storage costs for infrequently accessed data. Click here for the early case study.
With the rise of AI applications, storage requirements shifted toward high-bandwidth I/O and frequent write operations, such as model checkpoint saving, data distribution and storage. Key challenges included:
- Disconnected training and inference systems: Models generated during training required complex uploads and downloads to other platforms. This was inefficient.
- Storage bottlenecks: Inference workloads demanded higher read bandwidth, which many storage solutions struggled to deliver.
Solution:
- Unified storage via JuiceFS CSI:
- Training platforms with
ReadWriteManypermissions. - Inference platforms use
ReadOnlyManyaccess, optimized with JuiceFS prefetching.
- Training platforms with
- OSS auto-scaling: OSS bandwidth scales with data volume, ensuring sufficient throughput for large-scale AI workloads.
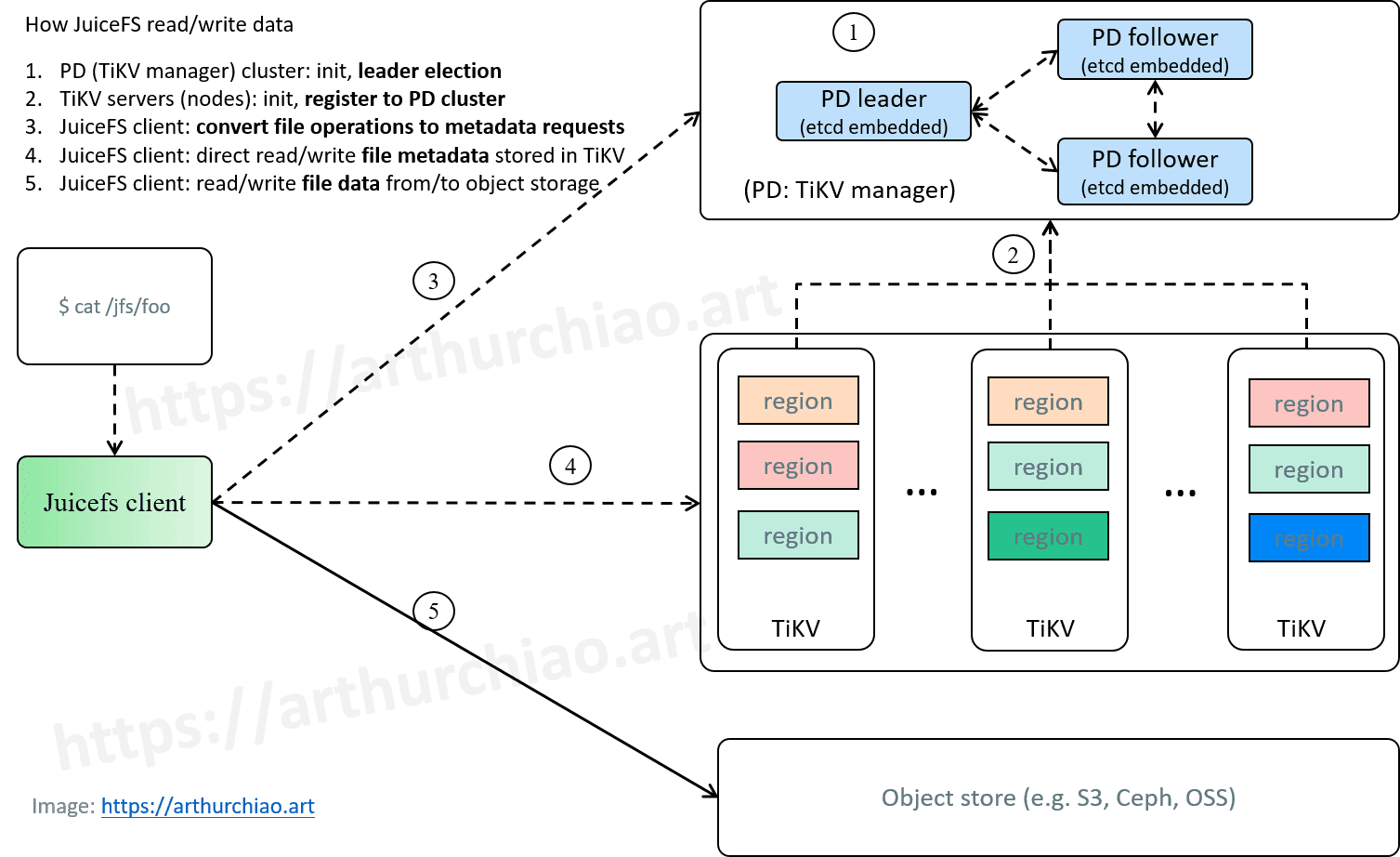
JuiceFS deployment architecture and key features
Core components:
- TiKV & PD as the metadata engine: TiKV supports a distributed architecture and transaction processing with excellent performance. Cross-IDC deployment ensures high availability of the system.
- Ali OSS as the storage backend: The dedicated network connection ensures high-bandwidth transmission capabilities, while OSS' automatic cold data tiering optimizes cost control, delivering a cost-effective solution.
- Customized JuiceFS client: We implemented targeted modifications to the JuiceFS client, particularly enhancing its internal management capabilities such as self-service, billing, rate limiting, Kubernetes integration
Key capability 1: Multi-tenant access management & billing
To serve diverse user groups (such as AI teams and DBAs), we implemented resource isolation by assigning each user a unique token for volume mounting.
To control costs, we strictly monitor and bill users for their usage. We conduct real-time monitoring at the volume level and generate hourly bills to ensure that each user's usage is clearly recorded and billed.
In a Kubernetes environment, many users use dynamic storage classes to achieve automated scheduling of storage. But to enable self-service requests and facilitate billing, we use static PVCs. This method allows for easy association of volumes and can be combined with automated processes to ensure that the costs for each volume are accurately recorded. In JuiceFS, each volume records a global variable (totalUsedSpace). It tracks usage related to billing.
Although the community also supports billing at the subdirectory level, for our initial development, billing at the volume level is simple and efficient.
Billing principles
The tool FinOps used internally in our company can regularly pull data from Alibaba Cloud's cost center to obtain the cost information for each cloud product. Through this tool, we can achieve real-time monitoring of the costs of various cloud services.
When we use this tool to apply for a JuiceFS volume, it needs to be associated, and the volume creation is linked to the corresponding user. To manage effectively, we perform a monitoring check every hour, recording metrics such as space usage and file reference counts, and send this data to the FinOps system. Then, FinOps allocates costs for each volume, proportionally distributing the OSS costs to the owners of each volume.
Abnormal charges: Storage leak
In daily operations, the main focus is on the increase in expenses and the trend of expense allocation. The cost data can reflect whether there are any abnormal issues. In a cost analysis, we encountered a typical issue: the usage statistics from JuiceFS showed no significant change, but the overall OSS cost had increased. After further analysis, it was confirmed that Alibaba Cloud's pricing policy and the OSS unit price had not changed. However, the unit price allocated has increased, resulting in an overall increase in costs.
When checking the billing statistics of JuiceFS and the file count statistics on Alibaba Cloud OSS, we found a significant discrepancy between the two. OSS provides a storage space inventory feature that allows you to view the usage of all files under the current bucket. By using the OSS inventory to aggregate the data, we found that the usage reported by JuiceFS was much lower than that reported by OSS. This led to the underestimation of users' storage space usage in JuiceFS, resulting in the OSS storage space costs being incorrectly allocated to other users. This increased the unit price for those users.
The fundamental reason for this difference lies in the way JuiceFS implements file deletion. For a large number of deleted files, JuiceFS uses a soft delete strategy to mark files as deleted, but the backend gradually deletes these data. Due to the disabling of all background tasks during use, users' delete operations resulted in many pending and failed delete requests. After further analysis, we found that JuiceFS has two types of data leakage issues: one is pending delete, and the other is data in the trash. To address this issue, we set up an additional monitoring service that scans for potential data leaks every 6 hours. If any leaked data is found, we’ll enable a dedicated client, cancel the disabled background tasks, and clean up the leaked data.
Features disabled
Disabling the trash
The trash feature does not need to be enabled in many scenarios. The trash is a background task that requires additional resources for cleanup, especially when using TiKV (such as the RocksDB database). The trash can put a certain amount of pressure on database performance, particularly during sudden large-scale deletions. Therefore, we don’t enable the trash feature.
Disabling the BackupMeta feature
JuiceFS provides a metadata backup feature. However, when the data volume is large, the logical backup speed is slow and cannot meet our needs. To improve backup efficiency, we prefer to use the official backup tools provided by TiKV for database backup, as this better supports the backup needs of large-scale data.
Key capability 2: Log collection and management to improve troubleshooting efficiency
We use internal tools to collect logs from TiKV and PD into ClickHouse, transmit them via Kafka, and finally store them in ClickHouse.
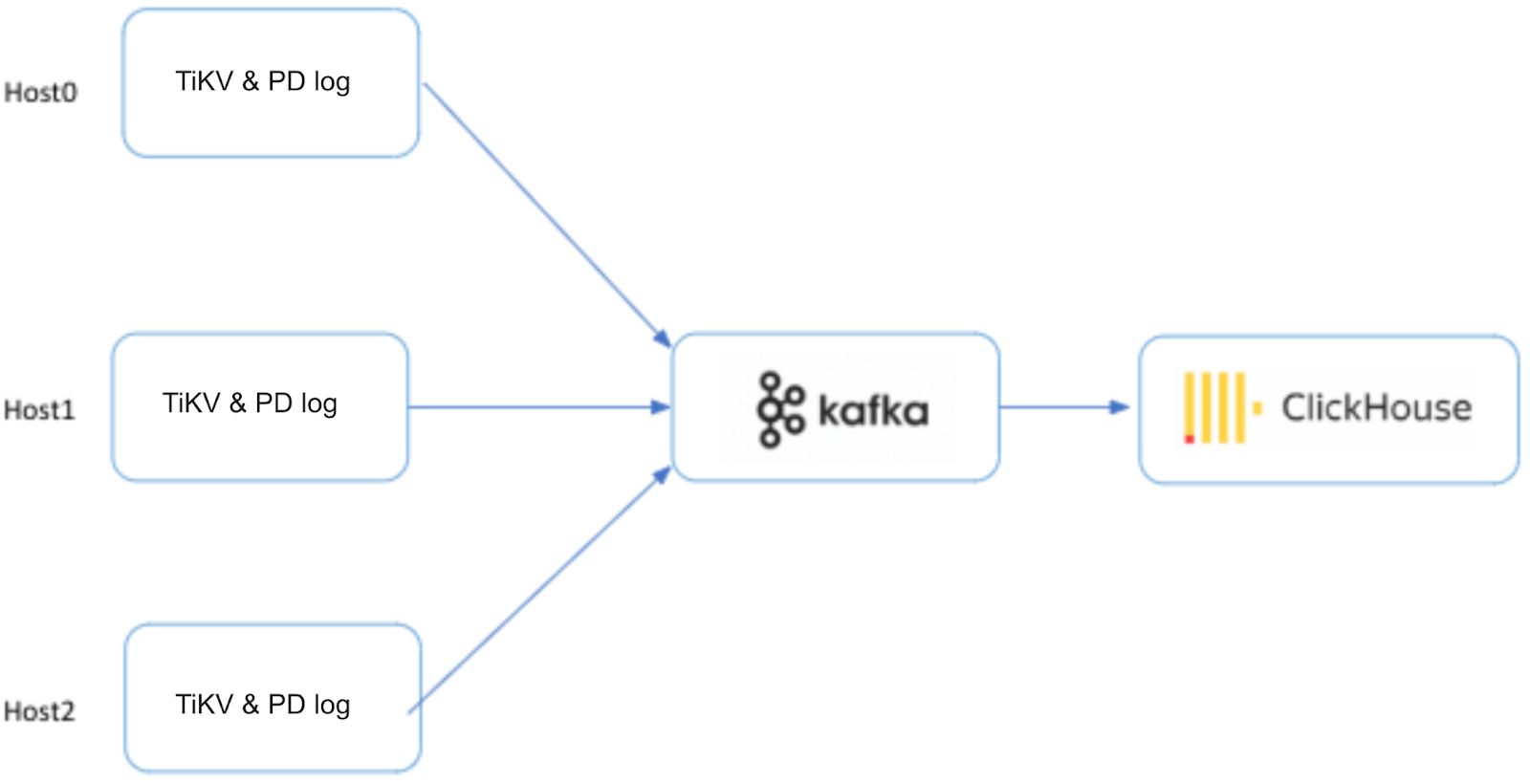
Through log collection, we can promptly capture error information within the cluster. In many cases, the cluster may generate a large number of errors, but users may not notice them. From the users’ perspective, performance does not seem to be significantly affected. However, after handling multiple incidents, we found that many issues were discovered through analyzing TiKV logs, allowing us to address potential problems in the early stages.
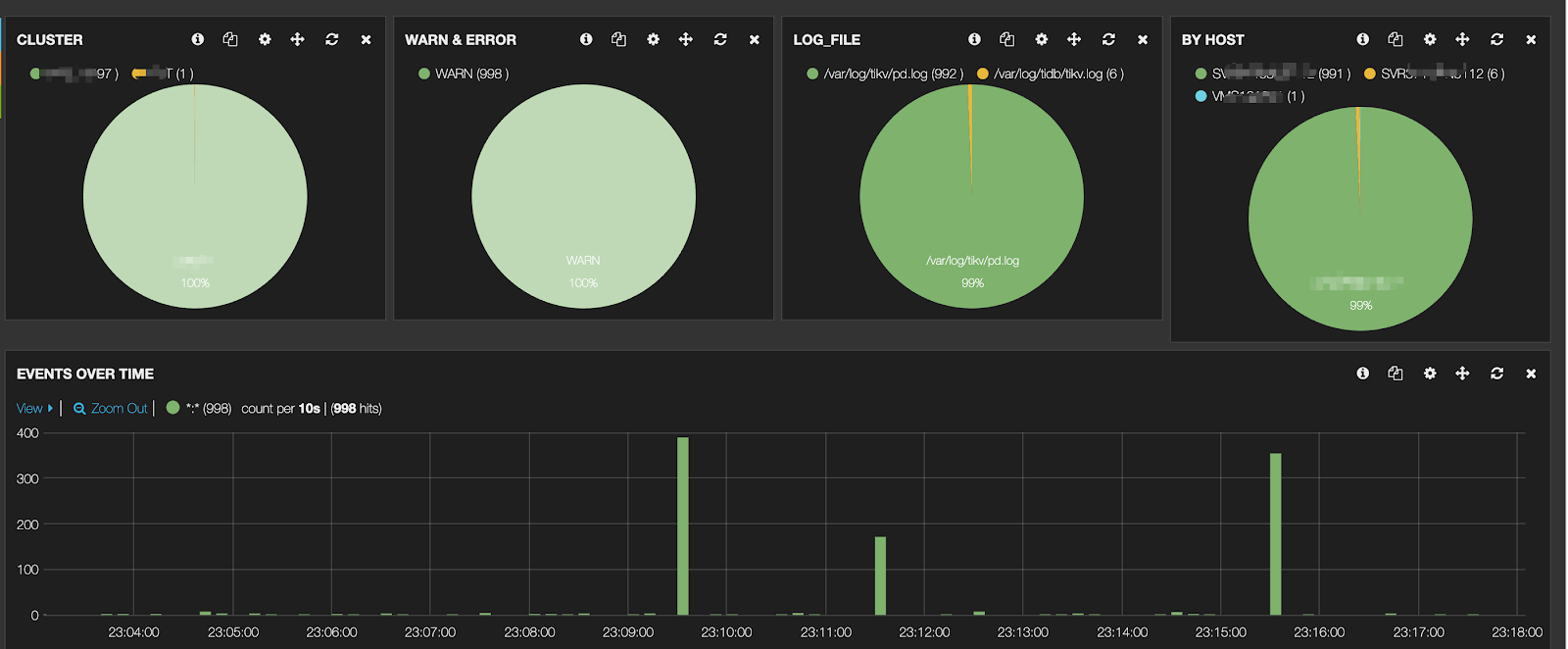
Key capability 3: Monitoring
In terms of monitoring, we selected some key metrics provided by TiKV to build our own monitoring system. The overall monitoring system of TiKV and TiDB is complex. The official monitoring dashboard contains a lot of information, making it seem overly complicated. When I first took over, I really didn't have a clear understanding of this part.
In practice, we ultimately selected several core metrics to more effectively monitor TiKV's performance:
- Performance-related metrics: including CPU, memory usage, and hot reads/writes.
- PD related metrics: focusing on Region leader distribution and scheduling status.
- GC (Garbage Collection) related metrics: including GC time and MVCC deletions.
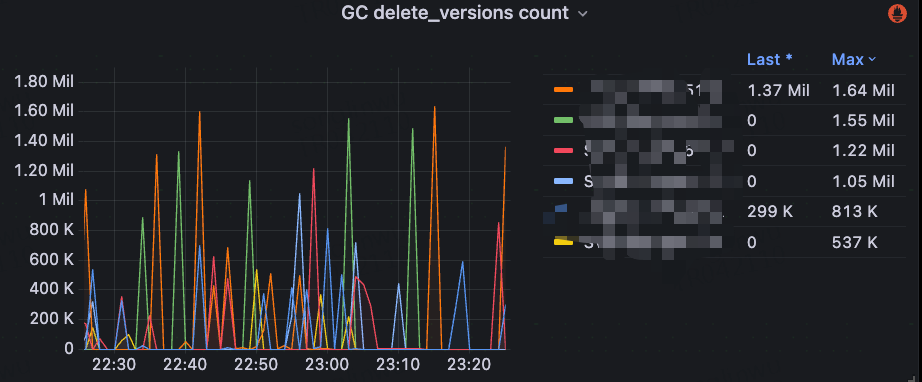
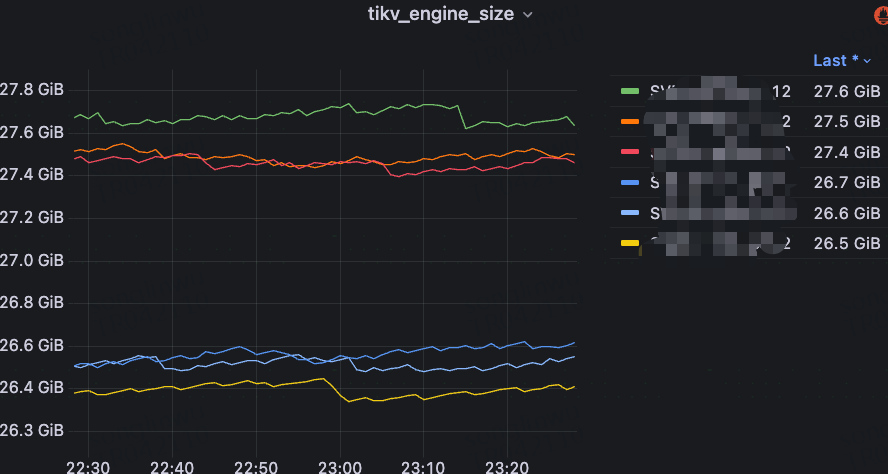
In the JuiceFS client monitoring, we obtain CSI metrics through the Prometheus interface. However, for regular mount scenarios, especially on machines where users have deployed JuiceFS themselves, we cannot directly control or access this data. Therefore, we use the .stats file provided by JuiceFS to collect simplified monitoring metrics. In most scenarios, the .stats file is already able to cover the metrics we need. To efficiently collect data, we deploy a DaemonSet on each machine, which regularly reads the .stats files and monitors them.
The client monitoring dashboard includes:
- CPU and memory usage
- Startup time and startup parameters
- Golang performance metrics, such as active objects in heap memory
- Read/write performance, including the usage of buffers and block caches
Besides focusing on the read and write performance of the client, we more often pay attention to the overall bandwidth.
Key capability 4: Metadata backup
In the TiKV ecosystem, there are two different br backup tools. The br tool mentioned in the TiKV documentation can only back up data written through the rawKV API and cannot back up data written through the txnKV API.
However, the br tool in the TiDB repository focuses more on backing up TiDB data. This tool provides the backup txn subcommand, specifically for backing up data written through the txnKV API. In the end, we adopted TiDB's full snapshot backup solution, performing scheduled backups daily.
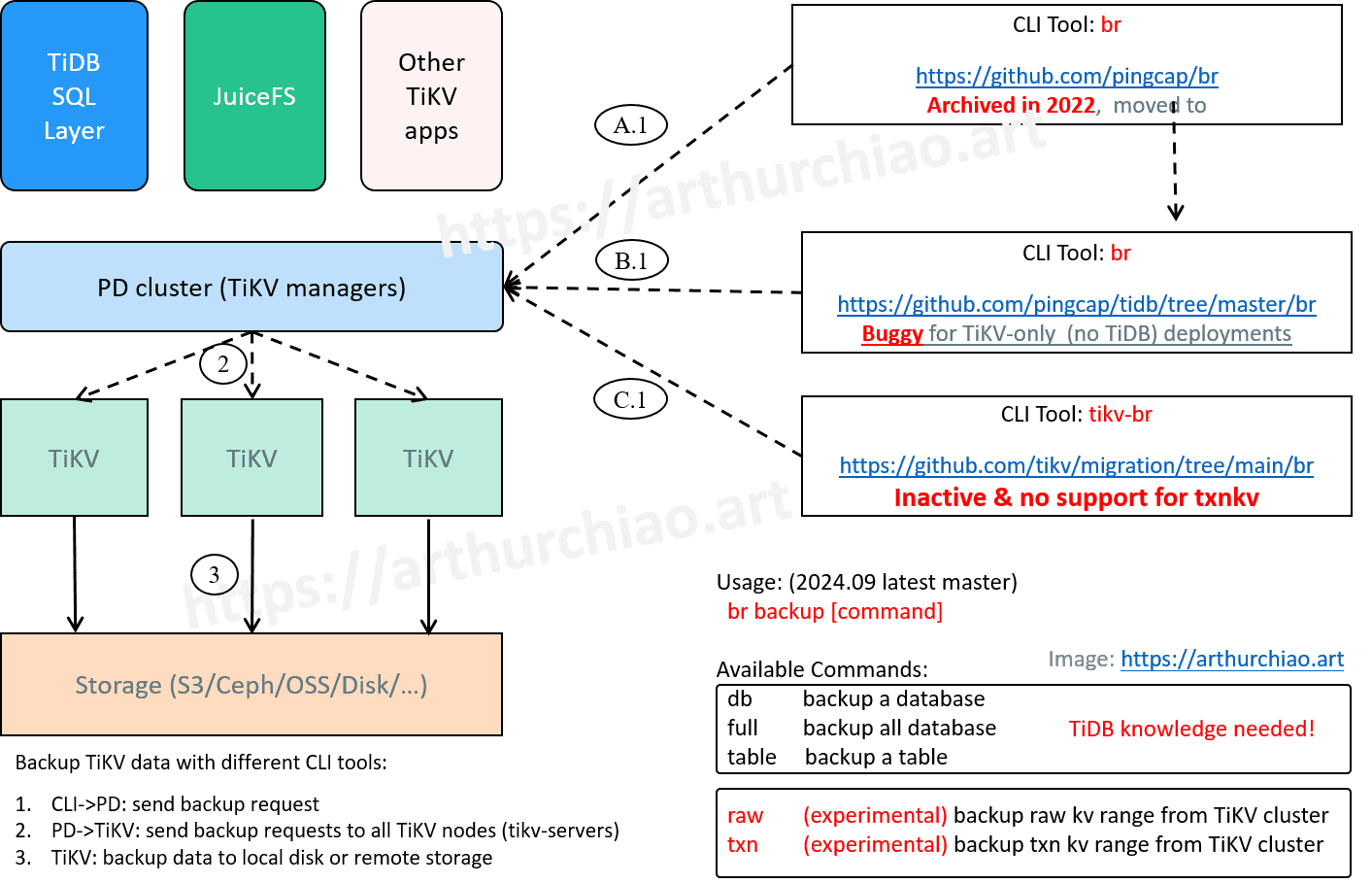
Currently, in our production environment after the maximum cluster scaling, we can complete a full backup within 20 minutes. Backup tasks are basically scheduled to run daily and the backup status is monitored in real-time. Since the JuiceFS service does not have a significant low point throughout the day, we back up TiKV during the day.
JuiceFS' cost advantage
We conducted a performance comparison between JuiceFS and Alibaba Cloud Extreme NAS. The results showed that in most read and write scenarios, JuiceFS was on a par with Extreme NAS and even delivered better performance.
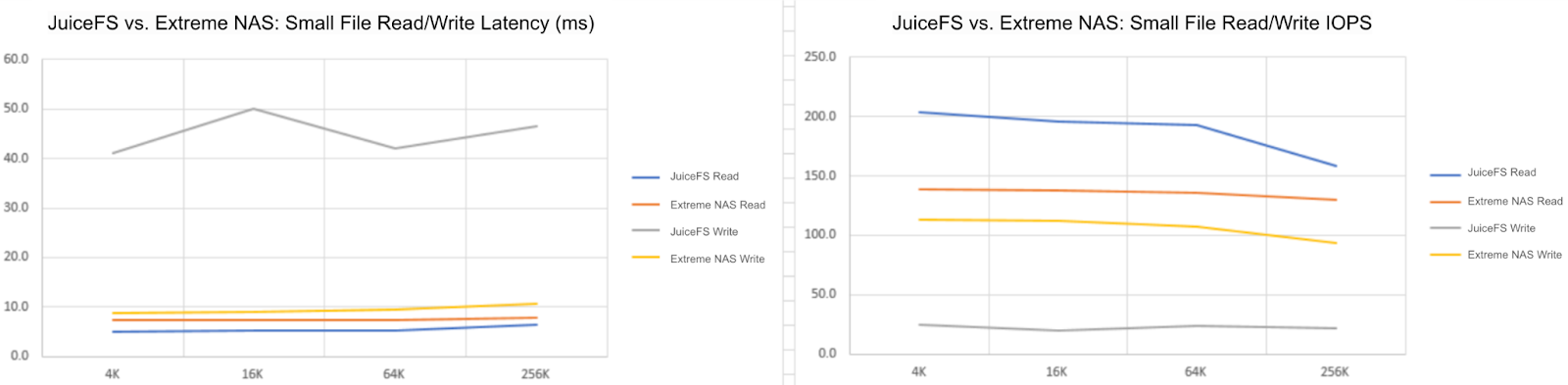
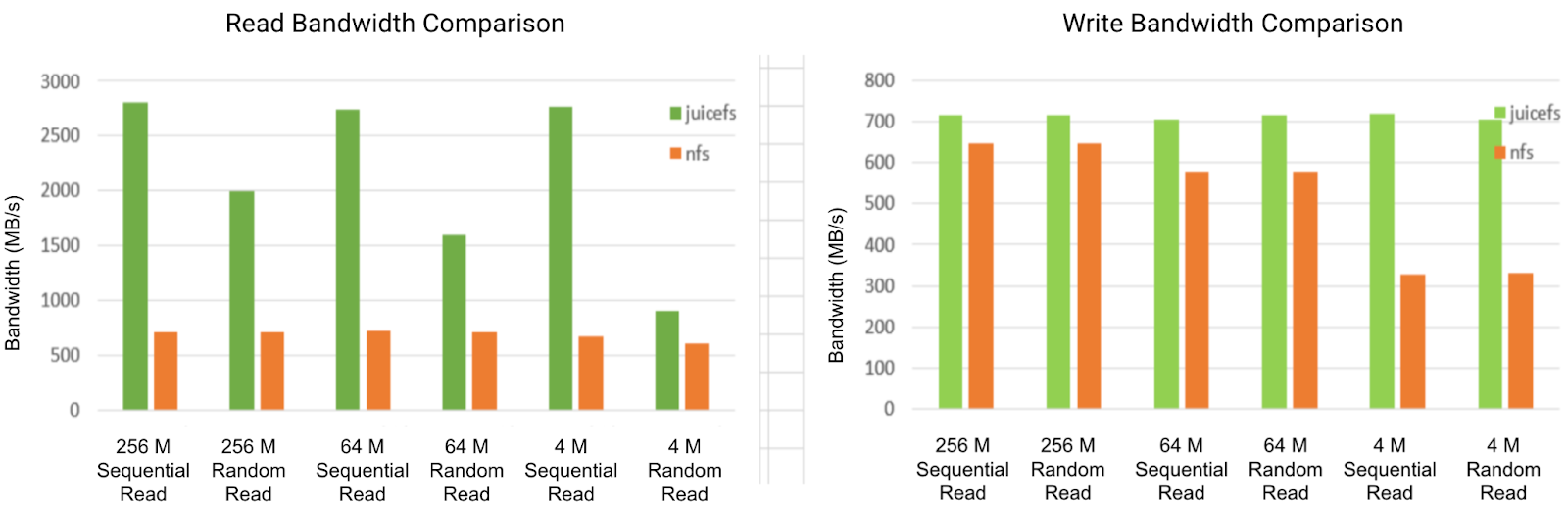
JuiceFS has client caching and prefetching capabilities. It employs OSS with high bandwidth, as well as a design that separates data and metadata. This makes it perform exceptionally well in most application scenarios, especially in LLM inference applications. LLM inference applications typically require high-bandwidth sequential read scenarios.
By combining JuiceFS with OSS, we’ve implemented a distributed file system solution that can provide the same functionality and comparable performance as Extreme NAS in most application scenarios, but at only one-tenth of the cost. This cost advantage is one of the greatest attractions of the JuiceFS solution, as it can significantly reduce our operating costs.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and community on Slack.