















Sun Yat-sen University is one of the top universities in China. Its Intelligence Science and System (iSEE) Lab focuses on human identification, activity recognition, and other related topics in visual surveillance. For dealing with large-scale vision data, we’re interested in large-scale machine learning algorithms such as online learning, clustering, fast search, cloud computing, and deep learning.
During deep learning tasks, we needed to handle massive small file reads. In high-concurrency read and write scenarios, our network file system (NFS) setup showed poor performance. We often faced node freezes during peak periods. In addition, NFS had single point of failure issues. If that node failed, data on the server was completely inaccessible. Scalability was also challenging. Each new data node required multiple mounts across all compute nodes. Small data volumes of the new node did not effectively alleviate read or write pressures.
To address these issues, we chose JuiceFS, an open-source distributed file system. Integrated with TiKV, JuiceFS successfully manages over 500 million files. The solution markedly enhanced performance and system stability in high-concurrency scenarios. It ensures continuous operation of compute nodes during deep learning training, while effectively mitigating single point of failure concerns.
JuiceFS is easy to learn and operate. It doesn’t require dedicated storage administrators for maintenance. This significantly reduces the operational burden for cluster management teams primarily composed of students in the AI field.
In this article, we’ll deep dive into our storage requirements in deep learning scenarios, why we chose JuiceFS, and how we built a storage system based on JuiceFS.
Storage requirements in deep learning scenarios
Our lab's cluster primarily supports deep learning training and method validation. During training, we faced four read and write requirements:
- During the training process, a large number of dataset files needed to be read.
- At the initial stage of model training, we needed to load a Conda environment, which involved reading many library files of different sizes.
- Throughout the training process, as model parameters were adjusted, we frequently wrote model parameter switch files of varying sizes. These files ranged from tens of megabytes to several gigabytes, depending on the model size.
- We also needed to record training logs (for each training session), which mainly involved frequent writing of small amounts of data.
Based on these needs, we expected the storage system to:
- Prioritize stability in high-concurrency read and write environments, with performance improvements built upon stability.
- Eliminate single points of failure, ensuring that no node failure would disrupt cluster training processes.
- Feature user-friendly operational characteristics. Given that our team mainly focused on AI deep learning and we had limited storage expertise, we needed an easy-to-operate storage system that had low maintenance frequency.
- Provide a POSIX interface to minimize learning costs and reduce code modifications. This was crucial, because we used a PyTorch framework in model training.
Current hardware configuration
Our hardware consists of three types of devices:
- Data nodes: About 3 to 4 nodes, each equipped with a lot of mechanical hard drives in RAID 6 arrays, totaling nearly 700 TB storage capacity.
- Compute nodes: Equipped with GPUs for intensive compute tasks, supplemented with 1 to 3 SSD cache disks per node (each about 800 GB), since JuiceFS has caching capabilities.
- TiKV nodes: Three nodes serving as metadata engines, each with about 2 TB data disk capacity and 512 GB memory. According to current usage, each node uses 300+ GB of memory when handling 500 to 600 million files.
Challenges with NFS storage
Initially, when there were not many compute nodes, we built standalone file systems on data nodes and mounted these file systems onto the directory of compute nodes via NFS mounts for data sharing. This approach simplified operations but as the number of nodes increased, we encountered significant performance degradation with our NFS-based storage system.
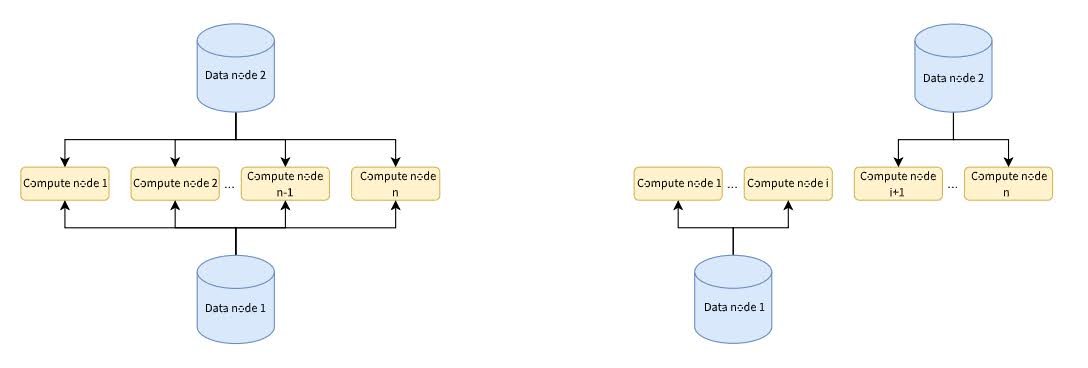
During peak periods of high concurrency and training, the system frequently experienced severe slowdowns or even freezes. This severely impacted our work efficiency. To mitigate this issue, we tried to divide the cluster into two smaller clusters to reduce data pressure on each node. However, this temporary measure did not bring significant improvements and introduced new challenges such as limited data interchangeability between different clusters.
Overall, our NFS storage solution demonstrated poor read performance and high risk of system crashes, especially in scenarios involving reading numerous small files. In addition, the entire system lacked a caching mechanism. But deep learning dataset training needed frequent reads. This exacerbated read and write pressures. Therefore, we sought a more efficient and stable storage solution to address these challenges.
Why we chose JuiceFS
We chose JuiceFS due to the following reasons:
- POSIX compatibility: JuiceFS supports POSIX interfaces. This ensures a seamless migration experience without disruption to users when switching systems.
- Cache feature: JuiceFS’ caching feature is crucial for training deep learning models. Although the cache may not be directly hit during the first round of data loading, as training progresses, subsequent rounds can use the cache almost 100%. This significantly improves the data reading speed during the training process.
- Trash: JuiceFS trash allows data recovery. The one-day trash we set up allows accidentally deleted files to be recovered within one day. In practical applications, it has helped users recover accidentally deleted data in a timely manner.
- Specific file management commands: JuiceFS offers a set of unique file management commands that are not only user-friendly but also more efficient compared to traditional file systems.
- Operational excellence: Since our lab does not have full-time personnel responsible for storage, we expect a storage system that should be easy to use and have low operation frequency, and JuiceFS exactly meets these needs. It provides rich documentation resources, allowing us to quickly find solutions when getting started and solving problems. JuiceFS can automatically back up metadata and provides an extra layer of protection for data. This enhanced our sense of security. The Prometheus and Grafana monitoring functionalities that come with JuiceFS allow us to easily view the status of the entire system on the web page, including key information such as the growth of the number of files, file usage, and the size of the entire system. This provides us with timely system monitoring and management convenience.
Building a JuiceFS-based storage system
Our JuiceFS setup uses TiKV as the metadata engine and SeaweedFS for object storage.

JuiceFS is divided into two directories for mounting:
- One directory stores user files. The independent mounting method allows us to flexibly adjust the mounting parameters to meet the specific needs of different directories. In terms of user file directories, we mainly use the default mount parameters to ensure stability and compatibility.
- The other directory is for the dataset. Given its almost read-only nature, we specifically increased the expiration time of the metadata cache. This can hit the metadata cache multiple times during multiple reads, thereby avoiding repeated access to the original data and significantly improving the speed of data access. Based on this change, we chose to mount the dataset and user files in two different directories.
In addition, we’ve implemented practical optimizations. Considering that the main task of the compute node is to process computing tasks rather than background tasks, we equipped an idle node with a large memory specifically for processing background tasks, such as backing up metadata. As the number of files increases, the memory requirements for backup metadata also gradually increase. Therefore, this allocation method not only ensures the performance of the compute nodes, but also meets the resource requirements of background tasks.
Metadata engine selection: Redis vs. TiKV
Initially, we employed two metadata engines: Redis and TiKV. During the early stages when data volume was small, in the range of tens of millions of data records, we chose Redis. At that time, because we were not familiar with these software solutions, we referred to relevant documents and chose Redis for its ease of adoption, high performance, and abundant resources. However, as the number of files rapidly increased, Redis' performance significantly degraded.
Specifically, we set up Redis database (RDB) persistence for Redis. When the memory usage increased, Redis was almost constantly in RDB backup state. This led to a significant decline in performance. In addition, we adopted sentinel mode at the time and enabled primary-secondary replication to increase availability, but this also caused problems. Because it was asynchronous replication, it was difficult to guarantee the data consistency of the secondary node after the primary node went down.
In addition, we learned that the client did not read metadata from the Redis secondary node, but mainly relied on the primary node for read and write operations. Therefore, as the number of files increased, the performance of Redis further degraded.
We then considered and tested TiKV as an alternative metadata engine. Judging from the official documentation, the performance of TiKV was second only to Redis. In actual use, the user experience is not much different from Redis. TiKV's performance is quite stable when the data volume reaches 500 to 600 million files.
Another advantage of TiKV is its ability to load balance and redundant storage. We use a three-node configuration, each node has multiple copies. This ensures data security and availability. For the operation and maintenance team, these features greatly reduce the workload and improve the stability and reliability of the system.
Metadata migration from Redis to TiKV
We migrated the system around January this year and have been using TiKV stably for nearly half a year without any downtime or any major problems.
In the early stages of the migration, because Redis could not support the metadata load of 500 to 600 million files, we decided to use the export and import method to implement the migration. Specifically, we used specific commands to export the metadata in Redis into a unified JSON file, and planned to load it into TiKV through the load command.
However, during the migration process, we encountered a challenge. We noticed that a user's directory encountered a failure during export due to excessive file depth or other reasons. To solve this problem, we took an innovative approach. We exported all directories except the problematic directory separately and manually opened and joinedthese JSON files to reconstruct the complete metadata structure.
When we manually processed these files, we found that the metadata JSON files had a clear structure and the join operation was simple. Its nested structure was basically consistent with the directory structure, which allowed us to process metadata efficiently. Finally, we successfully imported these files into TiKV and completed the migration process.
Why choose SeaweedFS for object storage?
Overall, we followed the main components and basic features recommended in the official SeaweedFS documentation without going into too many novel or advanced features. In terms of specific deployment, we use the CPU node as the core and run the master server on it. The data nodes are distributed and run on different bare metals, and each node runs the volume service to handle data storage. In addition, we run the filer server on the same CPU node, which provides the S3 service API for JuiceFS and is responsible for connecting with JuiceFS. Judging from the current operating conditions, the load on the CPU node is not heavy, and the main data reading, writing and processing tasks are distributed on each worker node.
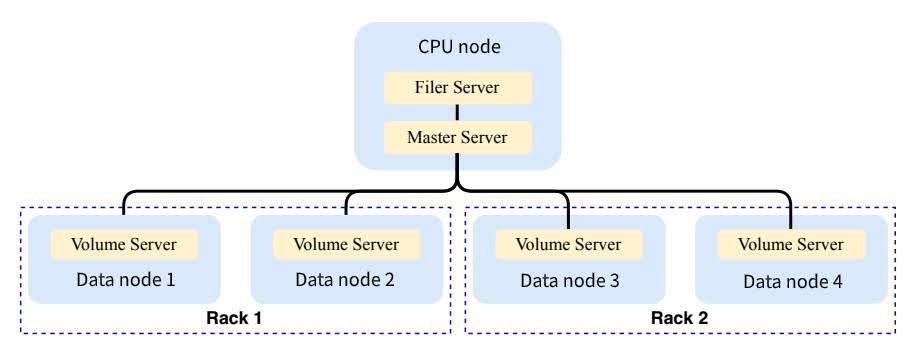
Regarding data redundancy and backup, we used SeaweedFS' redundancy features extensively. Logically, we divided data nodes into two racks. When writing data, it’s simultaneously written to both Rack 0 and Rack 1 to ensure dual backups. Data is considered successfully written only when it’s successfully written to both racks. While this strategy logically reduces our disk capacity by half (as each piece of data is stored twice), it ensures high availability and data safety. Even if a node in one rack fails or goes offline, it does not impact overall read, write operations, or data safety.
Challenges and solutions
When we used JuiceFS, we encountered the following challenges.
Client abnormal exits
We faced issues with clients unexpectedly exiting. Upon analysis, we identified these exits were caused by out-of-memory (OOM) errors. As the original data grew, specific nodes without the --no-bgjob option enabled experienced high memory consumption tasks (primarily automatic metadata backups). This led to insufficient remaining memory for backing up original data. This triggered OOM errors and client exits. To resolve this issue, we added the --no-bgjob option across all compute nodes and used idle data nodes specifically for background task processing.
Slow initial read of large files
During our initial use phase, we observed significantly slower read speeds than the gigabit network bandwidth limit particularly when accessing large files for the first time. Upon deeper investigation, we found this was due to incorrect configuration of JuiceFS command parameters during performance testing.
We did not specify the --storage s3 option. As a result, the performance was local disk performance by default rather than actual object storage performance. This misunderstanding led to a misjudgment of object storage performance. Through further inspection, we found performance bottlenecks in the SeaweedFS Filer metadata engine, primarily due to the use of a single mechanical disk at the underlying level. Thus, we considered optimizing this aspect to enhance performance.
Slow dataset decompression (large volume of small file writes)
We occasionally needed to decompress datasets in daily use. This involved writing a large number of small files. We found this process to be significantly slower compared to local decompression. The JuiceFS team suggested using the write-back acceleration feature. This feature allows for immediate returns after a file is written, while the background uploads the data to object storage. We plan to implement this recommendation in the future to optimize decompression performance.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and their community on Slack.