















File system is a common form of storage, which internally consists of data and metadata. Data is the file content presented directly to the user; while metadata is the data describing the file itself, e.g. file attributes, directory structure, data location. Generally speaking, metadata has very distinctive features, i.e., it takes up less space but is accessed very frequently.
Some of the distributed file systems nowadays such as S3FS, unifies metadata and data management to simplify system design, but the disadvantage is that some metadata operations can cause significant lag for users, such as listing large directories, renaming large files, and so on. More file systems choose to manage metadata separately and optimize them accordingly, JuiceFS adopted this design, with the following architecture diagram.
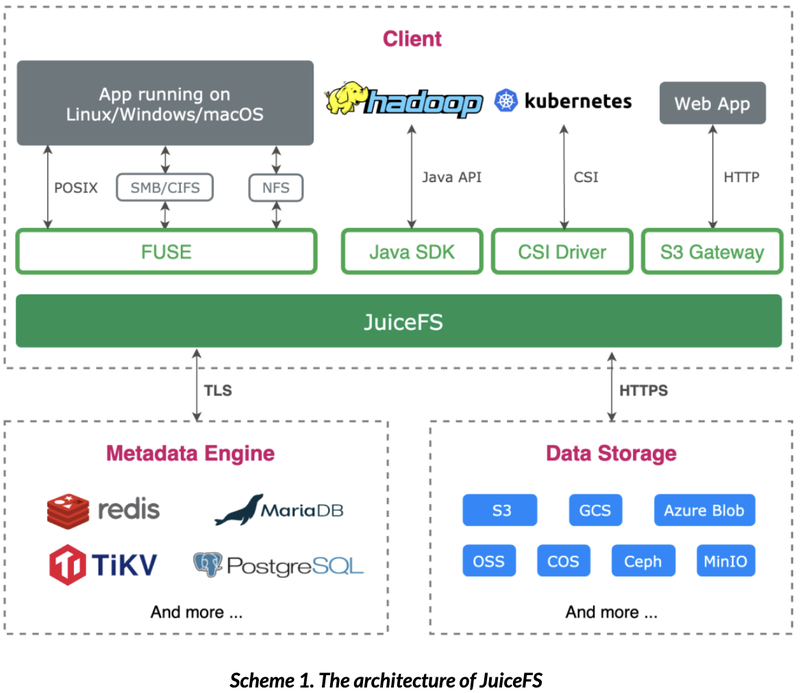
In the above diagram, metadata engine needs to be a database that supports transaction operations, and data storage is one of the supported object storage. So far, JuiceFS has supported more than 10 databases as metadata engine and more than 30 object storage for data storage.
Users are free to choose mature products to act as metadata engine and object storage, to cope with the challenges from different enterprise data storage requirements. But here comes the question: in my scenarios which database is the right one to choose as the metadata engine? This article will introduce you to the types of metadata engines available for JuiceFS from a product design perspective, as well as their advantages and disadvantages.
01-JuiceFS Metadata Engine Type
There are three main types of metadata engines supported by JuiceFS.
The first one is Redis, which is the metadata engine supported by JuiceFS since its first release. JuiceFS also supports databases that are compatible with the Redis protocol, such as KeyDB and Amazon MemoryDB.
However, the reliability and scalability of Redis is limited, and the performance is not good in scenarios with high data security requirements or large scale, so we have developed support for two other types of engines.
The second is the SQL-like class. Such as MySQL, MariaDB, PostgreSQL. They are highly popular and usually have good reliability and scalability. In addition, SQLite, an embedded database, is also supported.
The last one is the TKV (Transactional Key-Value Database) class, which has a simpler native interface and therefore better customizability in JuiceFS, and generally higher performance compared to the SQL databases. Currently, TiKV, etcd and BadgerDB (which is also an embedded database) are supported, FoundationDB support is also work in progress.
Above is a classification based on database protocol. There are various databases in each category, and each one has its own characteristics, the following is a comparison of several options commonly used by users based on these characteristics.
Comparison of meteda engines
| Redis | MySQL/PostgreSQL | TiKV | etcd | SQLite/BadgerDB | |
|---|---|---|---|---|---|
| Performance | High | Low | Medium | Low | Medium |
| Scalability | Low | Medium | High | Low | Low |
| Reliability | Low | High | High | High | Medium |
| Availability | Medium | High | High | High | Low |
| Popularity | High | High | Medium | High | Medium |
As mentioned above, the biggest advantage of Redis is its high performance, as it is an all-in-memory database. It is mediocre in other aspects.
In terms of scalability, a single Redis can typically support around 100 million files, When above 100 million, Redis single-process memory usage will be higher and management performance will decrease. The open source version of Redis supports a clustered model to expand the total amount of data it can manage, but since Redis does not support distributed transactions in clustered mode, each JuiceFS volume can only use a single Redis process as its metadata engine, thus the scalability of a single volume is not much improved compared to standalone Redis.
In terms of reliability, Redis flushes the data every second by default, which can lead to small data loss in the case of exceptions. By changing the `appendfsync` configuration to `always`, you can make Redis flush after every write request, which improves data reliability but decreases performance.
In terms of availability, deploying Redis sentry monitor nodes and replica nodes allows you to select a replica node to revive the service after the master Redis node hangs, improving availability to some extent. However, Redis itself does not support a distributed consistency protocol, and its replica nodes use asynchronous replication, so although the new node is up, there may be data differences in between, resulting in minor data loss in the newly deployed Metadata instance.
The overall performance of MySQL and PostgreSQL is relatively similar. They are both database products that have been proven by a large number of users over many years, with good reliability and availability, and high popularity. They just have average performance compared to the rest of the metadata engines.
TiKV was originally as the underlying storage for PingCAP TiDB, but has now been developed to become a standalone KV database component. From our test results, it is an excellent choice as the metadata engine for JuiceFS. It has inherent data reliability and service availability that is not inferior to MySQL, and performs better in terms of performance and scalability. It's just that it's not as good as MySQL in terms of popularity. From what we know about the JuiceFS community, former TiKV or TiDB users usually end up favoring TiKV as the metadata engine for JuiceFS. But if people are not familiar with TiKV before, they will be much more cautious to accept such a new component.
etcd is another TKV-like database. etcd is supported because it is very popular in container scenarios, and basically Kubernetes uses etcd to manage its configuration. Using etcd as the metadata engine for JuiceFS is not a particularly well suited scenario. On the one hand, it has average performance, and on the other hand, it has a capacity limit (default 2G, max 8G), which makes it difficult to scale. However, its reliability and availability are very high, and it is easy to deploy in containerized scenarios, so if users only need a file system that scales in the millions of files, etcd is still a good choice.
Finally, SQLite and BadgerDB, which belong to the SQL and TKV classes respectively, have a very similar use experience, as they are both standalone embedded databases. These databases are characterized by medium performance, but poor scalability and availability, as their data is actually stored in the local system. They have the advantage of being very easy to use, requiring only JuiceFS binary and no additional components. Users can use these two databases for some specific scenarios or to perform some simple evaluations.
02- Performance test for metadata engines
We have done some performance tests of typical engines and put the results in this document (https://juicefs.com/docs/zh/community/metadata_engines_benchmark/ ).One of them is obtained from the test of source code interfaces, showing: Redis > TiKV (3 copies) > MySQL (local) ~= etcd (3 copies), as follows.
| Redis-Always | Redis-Everysec | TiKV | MySQL | etcd | |
|---|---|---|---|---|---|
| mkdir | 600 | 471 (0.8) | 1614 (2.7) | 2121 (3.5) | 2203 (3.7) |
| mvdir | 878 | 756 (0.9) | 1854 (2.1) | 3372 (3.8) | 3000 (3.4) |
| rmdir | 785 | 673 (0.9) | 2097 (2.7) | 3065 (3.9) | 3634 (4.6) |
| readdir_10 | 302 | 303 (1.0) | 1232 (4.1) | 1011 (3.3) | 2171 (7.2) |
| readdir_1k | 1668 | 1838 (1.1) | 6682 (4.0) | 16824 (10.1) | 17470 (10.5) |
| mknod | 584 | 498 (0.9) | 1561 (2.7) | 2117 (3.6) | 2232 (3.8) |
| create | 591 | 468 (0.8) | 1565 (2.6) | 2120 (3.6) | 2206 (3.7) |
| rename | 860 | 736 (0.9) | 1799 (2.1) | 3391 (3.9) | 2941 (3.4) |
| unlink | 709 | 580 (0.8) | 1881 (2.7) | 3052 (4.3) | 3080 (4.3) |
| lookup | 99 | 97 (1.0) | 731 (7.4) | 423 (4.3) | 1286 (13.0) |
| getattr | 91 | 89 (1.0) | 371 (4.1) | 343 (3.8) | 661 (7.3) |
| setattr | 501 | 357 (0.7) | 1358 (2.7) | 1258 (2.5) | 1480 (3.0) |
| access | 90 | 89 (1.0) | 370 (4.1) | 348 (3.9) | 646 (7.2) |
| setxattr | 404 | 270 (0.7) | 1116 (2.8) | 1152 (2.9) | 757 (1.9) |
| getxattr | 91 | 89 (1.0) | 365 (4.0) | 298 (3.3) | 655 (7.2) |
| removexattr | 219 | 95 (0.4) | 1554 (7.1) | 882 (4.0) | 1461 (6.7) |
| listxattr_1 | 88 | 88 (1.0) | 374 (4.2) | 312 (3.5) | 658 (7.5) |
| listxattr_10 | 94 | 91 (1.0) | 390 (4.1) | 397 (4.2) | 694 (7.4) |
| link | 605 | 461 (0.8) | 1627 (2.7) | 2436 (4.0) | 2237 (3.7) |
| symlink | 602 | 465 (0.8) | 1633 (2.7) | 2394 (4.0) | 2244 (3.7) |
| write | 613 | 371 (0.6) | 1905 (3.1) | 2565 (4.2) | 2350 (3.8) |
| read_1 | 0 | 0 (0.0) | 0 (0.0) | 0 (0.0) | 0 (0.0) |
| read_10 | 0 | 0 (0.0) | 0 (0.0) | 0 (0.0) | 0 (0.0) |
- Above table shows the time taken for each operation, the smaller the better; the number in parentheses is a multiple of Redis-always for this metric, also the smaller the better
- always and everysec are optional values for the Redis configuration item appendfsync, meaning that the disk is flushed on every request and once per second, respectively.
- As is shown, Redis performs better when using everysec, but the difference with always is not that great; this is because the local SSD disks on the AWS machine used for testing are inherently higher in IOPS performance
- TiKV and etcd both use triple replicas, while MySQL is deployed as a singleton. Even so, TiKV performance is higher than MySQL, while etcd is close to MySQL
It is worth mentioning that the tests above use the default configuration and do not go for specific tuning of each metadata engine. Users can adjust the configuration according to their needs and experience, and may have different results.
| Redis-Always | Redis-Everysec | TiKV | MySQL | etcd | |
|---|---|---|---|---|---|
| Write big file | 565.07 MiB/s | 556.92 MiB/s | 553.58 MiB/s | 557.93 MiB/s | 542.93 MiB/s |
| Read big file | 664.82 MiB/s | 652.18 MiB/s | 679.07 MiB/s | 673.55 MiB/s | 672.91 MiB/s |
| Write small file | 102.30 files/s | 105.80 files/s | 95.00 files/s | 87.20 files/s | 95.75 files/s |
| Read small file | 2200.30 files/s | 1894.45 files/s | 1394.90 files/s | 1360.85 files/s | 1017.30 files/s |
| Stat file | 11607.40 files/s | 15032.90 files/s | 3283.20 files/s | 5470.05 files/s | 2827.80 files/s |
| FUSE operation | 0.41 ms/op | 0.42 ms/op | 0.45 ms/op | 0.46 ms/op | 0.42 ms/op |
| Update meta | 3.63 ms/op | 3.19 ms/op | 7.04 ms/op | 8.91 ms/op | 4.46 ms/op |
Another test was run with JuiceFS's own benchmark tool, which runs the operating system's interface for reading and writing files, with the following results.
As is shown from the table above, the final performance of using different metadata engines when reading and writing large files is about the same. This is because at this time the performance bottleneck is mainly in the object storage data read and write, although the metadata engine latency is a little different, but is almost negligible compared to the actual file IO. Of course, if the object storage becomes very fast (such as local full-SSD deployment), then the metadata engine performance differences may again be manifested. In addition, for some pure metadata operations (e.g. ls, creating empty files, etc.), the performance difference between different metadata engines will also be more obvious.
03-Considerations for Selecting meteda engine
According to the characteristics of each engine described above, users can choose the right engine according to their own situation. The following briefly shares a few key considerations when we are making recommendations.
Requirements evaluation: for example, if you want to use Redis, you need to see whether you can accept a small amount of data loss, short-term service interruptions, etc. If you are using JuiceFS as temporary or intermediate data storage, Redis is really a good choice because it has good performance, and a small loss of data will not have a big impact. But if you want to store critical data, Redis is not suitable. If it is expected to be around 100 million files, Redis can handle it. If it is expected to be around 1 billion files, then obviously a single Redis instance is not going to be able to handle it.
Hardware evaluation: for example, whether you can connect to an external network, use a hosted cloud service, or deploy privately in your own datacenter. If it is a on-premise deployment, you need to evaluate whether there are enough hardware resources to deploy some related components. No matter which metadata engine is used, it basically requires a high-speed SSD disk to run, otherwise it will have a big impact on its performance.
Evaluating O&M capabilities is something that many people will overlook, but in our view it should be one of the most critical factors. For storage systems, stability is often the first focus once they are in production. When choosing a metadata engine, users should first think about whether they are familiar with it, whether they can quickly come up with a solution in case of problems, and whether there is enough experience or energy within the team to control the component well. Generally speaking, we would recommend users to choose a database that they are familiar with at the beginning. If there are not enough Ops staff, then choosing public cloud service is really a worry-free option as well.
Here I'd like to share some statistics on the community's use of metadata engines.
So far, Redis still accounts for more than half of the users, followed by TiKV and MySQL, and the number of users in these two categories is gradually growing.
The maximum number of files in a running Redis cluster is about 150 million, and the operation is relatively stable. The 100 million files mentioned above is the recommended value, not that it is impossible to exceed 100 million.
TiKV is used by the top 3 clusters in terms of overall number of files, and they all exceed 1 billion files. Now the largest file system has more than 7 billion files and the total capacity is more than 15 PiB, which proves the scalability of TiKV as a metadata engine from the side. We have measured internally using TiKV as a metadata engine to store 10 billion files. So if your entire cluster is expected to be very large, then TiKV is indeed a good choice.
04-Metadata engine migration
This article concludes with an introduction to metadata engine migration. As business grows, an organization's requirements for metadata engine will change, and when the existing metadata engine is no longer suitable, users may consider migrating metadata to another engine. We provide a complete migration solution for users, which can be found in this document.
This migration method has some limitations, firstly, it can only migrate to the empty database, and it is temporarily impossible to combine the two file systems directly; secondly, it needs to stop writing, because it is difficult to migrate the metadata online in its entirety when the data volume will be relatively large. To do this, many restrictions need to be added, and from the actual test, the speed will be very slow. Therefore, it is safest to stop the whole file system and then do the migration. If there is a need for certain services to be provided, read-only mounts can be retained, and user read data will not affect the entire metadata engine migration action.
Although the community provides a full set of migration methods, it is still good to keep in mind that you should try to plan ahead for the growth of data volume and try not to do migration or migrate as early as possible. When the size of the data to be migrated is large, it will also take longer and the probability of problems during the migration will also become greater.
About author:
Sandy, system engineer in Juicedata,mainly responsible for development and maintenance of JuiceFS community version. And he has ten years experience in distributed storage systems.