















When using JuiceFS, we chose SeaweedFS as the object storage and TiKV as the metadata storage. Currently, we’ve stored nearly 1.5 PB of data on SeaweedFS. Since there is limited reference material available for configuring SeaweedFS+TiKV, we’d like to share our experience for your reference. In this article, we’ll show you our deployment practice with detailed code examples. At the end of the article, we’ll include our experience with implementing quota management across multiple files and conducting cross-data-center data migration within the JuiceFS file system.
Why use SeaweedFS as the object storage for JuiceFS
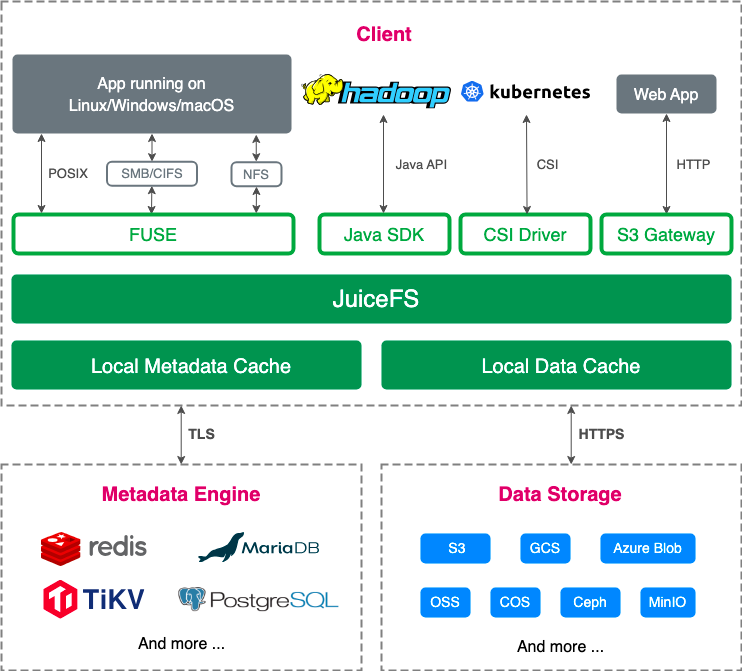
JuiceFS is a high-performance distributed file system designed for cloud-native environments. It’s open source under the Apache 2.0 license. The system fully supports POSIX, allowing users to use various object storage solutions as massive local disks. You can learn why we chose SeaweedFS as the object storage for JuiceFS from the following articles:
- Building an Easy-to-Operate AI Training Platform: SmartMore's Storage Selection & Best Practices
- iSEE Lab Stores 500M+ Files on JuiceFS Replacing NFS
How to deployment TiKV+SeaweedFS
1. Configure the deployment environment
This section describes how to deploy the JuiceFS file system using a combination of SeaweedFS and TiKV. SeaweedFS supports the S3 protocol and is used as the object storage, while TiKV provides metadata services for JuiceFS. When the prefix of the JuiceFS file system does not align with SeaweedFS' key construction rules, you can use the same TiKV instance. For example, you can use a Universally Unique Identifier (UUID) as the prefix for JuiceFS. In this article, we assume that JuiceFS and SeaweedFS share the same TiKV setup. However, we recommend separate deployments for them.
We’ll perform the operations on the Rocky 8.9 operating system, with commands compatible with CentOS.
Software version information:
- TiKV: 6.5.0
- SeaweedFS: 3.59
Node information:
| Server | Operating system | Kernel version | CPU | Memory | Disk |
|---|---|---|---|---|---|
| tikv01 | Rocky 8.9 | 4.18.0-513.5.1.el8_9.x86_64 | 80 core | 512 GB | 1* NVME 1.92T DWPD >=1 |
| tikv02 | Rocky 8.9 | 4.18.0-513.5.1.el8_9.x86_64 | 80 core | 512 GB | 1* NVME 1.92T DWPD >=1 |
| tikv03 | Rocky 8.9 | 4.18.0-513.5.1.el8_9.x86_64 | 80 core | 512 GB | 1* NVME 1.92T DWPD >=1 |
| seaweedfs01 | Rocky 8.9 | 4.18.0-513.5.1.el8_9.x86_64 | 80 core | 256 GB | 10* 18TB HDD |
| seaweedfs02 | Rocky 8.9 | 4.18.0-513.5.1.el8_9.x86_64 | 80 core | 256 GB | 10* 18TB HDD |
| seaweedfs03 | Rocky 8.9 | 4.18.0-513.5.1.el8_9.x86_64 | 80 core | 256 GB | 10* 18TB HDD |
2. Optimize server configuration
Tune node parameters:
yum install -y numactl vim
echo vm.swappiness =0>>/etc/sysctl.conf
echo net.core.somaxconn =32768>>/etc/sysctl.conf
echo net.ipv4.tcp_syncookies =0>>/etc/sysctl.conf
echo fs.nr_open =20000000>>/etc/sysctl.conf
echo fs.file-max =40000000>>/etc/sysctl.conf
echo vm.max_map_count =5642720>>/etc/sysctl.conf
sysctl -p
echo'* - nofile 10000000'>>/etc/security/limits.conf
Synchronize server time:
# Rocky 8.9 comes with the chronyc tool, so you don’t need to download it.
vim /etc/chrony.conf
# Comment out the following line and add: server time1.aliyun.com iburst.
# pool 2.pool.ntp.org iburst
server time1.aliyun.com iburst
# Execute the following commands to trigger time synchronization.
systemctl daemon-reload
systemctl restart chronyd
chronyc makestep
timedatectl set-timezone Asia/Shanghai
date
3. Deploy TiKV
According to TiKV's document, you need to first check if the server configuration meets the prerequisites. By default, TiKV can utilize up to 75% of the server’s memory. It’s strongly not recommended to deploy TiKV along with other services without adjusting parameters.
For hybrid deployments, see TiKV's Hybrid Deployment Topology for parameter tuning and deployment. You can also modify the configuration based on TiKV Configuration File.
1) Initialize the cluster topology file:
tiup cluster template > topology.yaml
# Modify the TiKV configuration file according to actual requirements.
topology.example.yaml
# Configure TiKV global parameters.
global:
user: "root"
ssh_port: 22
deploy_dir: "/mnt/disk1/tikv-deploy"
data_dir: "/mnt/disk1/tikv-data"
listen_host: 0.0.0.0
arch: "amd64"
# Enable TLS authentication. After deployment, use tiup cluster display test to obtain certificate file paths.
enable_tls: true
monitored:
# It is recommended to avoid using default ports to prevent port conflicts in hybrid deployment scenarios.
node_exporter_port: 9900
blackbox_exporter_port: 9915
pd_servers:
- host: 192.168.0.1
client_port: 2279
peer_port: 2280
- host: 192.168.0.2
client_port: 2279
peer_port: 2280
- host: 192.168.0.3
client_port: 2279
peer_port: 2280
tikv_servers:
- host: 192.168.0.1
port: 2260
status_port: 2280
- host: 192.168.0.2
port: 2260
status_port: 2280
- host: 192.168.0.3
port: 2260
status_port: 2280
monitoring_servers:
- host: 192.168.0.1
port: 9190
grafana_servers:
- host: 192.168.0.1
port: 3100
alertmanager_servers:
- host: 192.168.0.1
web_port: 9193
cluster_port: 9194
2) Execute deployment commands
Check and resolve potential issues in the cluster:
tiup cluster check ./topology.yaml --user root [-p] [-i /home/root/.ssh/gcp_rsa]
# Most encountered issues can be fixed using --apply
tiup cluster check ./topology.yaml --apply --user root [-p] [-i /home/root/.ssh/gcp_rsa]
Deploy the cluster using the deploy command:
tiup cluster deploy test v6.5.0 ./topology.yaml --user root [-p] [-i /home/root/.ssh/gcp_rsa]
Installing TiKV components may take a long time. Be patient.
3) Check and deploy the TiKV cluster
Run the commands below to check and deploy the TiKV cluster:
tiup cluster list
tiup cluster display test
4) Start the TiKV cluster
Run the command below to start the TiKV cluster:
tiup cluster start test
5) Test the TiKV cluster
Refer to TiKV Performance Overview and use the Yahoo! Cloud Serving Benchmark (YCSB) tool for performance testing. After testing, redeploy TiKV.
4. Deploy SeaweedFS
For an introduction to SeaweedFS components, see SeaweedFS Components. This article assumes a default data replication level of three replicas.
Node information:
| Server | IP | Operating system | Kernel version | CPU | Memory | Disk |
|---|---|---|---|---|---|---|
| seaweedfs01 | 192.168.1.1 | Rocky 8.9 | 4.18.0-513.5.1.el8_9.x86_64 | 80 core | 256 GB | 10* 18TB HDD |
| seaweedfs02 | 192.168.1.2 | Rocky 8.9 | 4.18.0-513.5.1.el8_9.x86_64 | 80 core | 256 GB | 10* 18TB HDD |
| seaweedfs03 | 192.168.1.3 | Rocky 8.9 | 4.18.0-513.5.1.el8_9.x86_64 | 80 core | 256 GB | 10* 18TB HDD |
Architectural information:
| Service | Node |
|---|---|
| master01 | seaweedfs01 |
| master02 | seaweedfs02 |
| master03 | seaweedfs03 |
| filer01 | seaweedfs01 |
| filer02 | seaweedfs02 |
| filer03 | seaweedfs03 |
| volumer01-10 | seaweedfs01 |
| volumer11-20 | seaweedfs02 |
| volumer21-30 | seaweedfs03 |
1) Deploy Prometheus Pushgateway
The Prometheus Pushgateway aggregates monitoring data from SeaweedFS and interfaces with Prometheus to store metrics in a time-series database (TSDB).
deploy prometheus pushgateway
wget https://github.com/prometheus/pushgateway/releases/download/v1.5.1/pushgateway-1.5.1.linux-amd64.tar.gz
tar -xvf pushgateway-1.5.1.linux-amd64.tar.gz
cd pushgateway-1.5.1.linux-amd64/
cp pushgateway /usr/local/bin/pushgateway
cat>/etc/systemd/system/pushgateway.service <<EOF
[Unit]
Description=PrometheusPushgateway
Wants=network-online.target
After=network-online.target
[Service]
User=root
Group=root
Type=simple
ExecStart=/usr/local/bin/pushgateway
[Install]
WantedBy=multi-user.target
EOF
cd..
rm-rf pushgateway-1.5.1.linux-amd64.tar.gz
systemctl daemon-reload
systemctl start pushgateway
2) Deploy SeaweedFS master service
Download SeaweedFS binary file. Deploy SeaweedFS master:
wget https://github.com/seaweedfs/seaweedfs/releases/download/3.59/linux_amd64_full.tar.gz
tar -xvf linux_amd64_full.tar.gz
rm -rf ./linux_amd64_full.tar.gz
cp weed /usr/local/bin
Documents for your reference:
3) Prepare master configuration file + runtime environment
In this article, we’ll deploy a master service on each of three SeaweedFS servers, specifying a data replication level of three replicas.
Prepare the master configuration file:
# Clean the directories to be used by SeaweedFS.
# rm -rf /seaweedfs/master/*
mkdir -p /seaweedfs/master/mlog /seaweedfs/master/mdir
mkdir -p /etc/seaweedfs
cat > /etc/seaweedfs/master.conf << EOF
loglevel=2
logdir=/seaweedfs/master/mlog
mdir=/seaweedfs/master/mdir
# Three master addresses
peers=192.168.1.1:9333,192.168.1.2:9333,192.168.1.3:9333
port=9333
# Set cluster replication level to three replicas.
defaultReplication=020
# Current node IP
ip=192.168.1.1
# Prometheus Pushgateway address
metrics.address=192.168.1.1:9091
EOF
Configure the master service:
cat > /etc/systemd/system/weed-master.service << EOF
[Unit]
Description=SeaweedFSServer
After=network.target
[Service]
Type=simple
User=root
Group=root
ExecStart=/usr/local/bin/weed master -options=/etc/seaweedfs/master.conf
WorkingDirectory=/usr/local/bin
SyslogIdentifier=seaweedfs-master
[Install]
WantedBy=multi-user.target
EOF
4) Deploy SeaweedFS volume services
In this article, we’ll deploy 10 volume servers on each SeaweedFS server, without showing repetitive operations. Please format and mount your disk accordingly.
Documents for reference:
Tips:
- Adopting a single volume per disk management approach facilitates disk replacement after failures.
- Parameters for volume servers are written into services rather than configuration files for easier service management.
- Configure
index=leveldbto reduce memory usage (SeaweedFS Memory Consumption). - Default volume size is 30 GB, with
-maxlimiting the maximum number of volumes. - Ensure volume directories are created beforehand.
- According to SeaweedFS FAQ, it’s recommended to keep the total volume max size smaller than the disk size.
Deploy volume services:
# Replace mserver addresses with actual master addresses.
# Configure dir, datacenter, rack, ip, and port information according to the actual situation.
# Repeat the command according to the number of disks to create multiple services.
mkdir -p /seaweedfs/volume1/log /mnt/disk1/volume
cat > /etc/systemd/system/weed-volume1.service << EOF
[Unit]
Description=SeaweedFSVolume
After=network.target
[Service]
Type=simple
User=root
Group=root
ExecStart=/usr/local/bin/weed volume -index=leveldb -logdir=/seaweedfs/volume1/log -dir=/mnt/disk1/volume -mserver=192.168.1.1:9333,192.168.1.2:9333,192.168.1.3:9333-dataCenter=dc1 -rack=rack1 -ip=192.168.1.1-port=10001-max=20000
WorkingDirectory=/usr/local/bin/
SyslogIdentifier=seaweedfs-volume
[Install]
WantedBy=multi-user.target
EOF
5) Deploy SeaweedFS filer services
In this article, we’ll deploy 1 filer on each of 3 SeaweedFS servers, using TiKV to provide storage. Repetitive operations will not be covered here.
Documents for reference:
Tips:
- Prepare
/etc/seaweedfs/filer.tomland/etc/seaweedfs/s3.jsonfiles on the servers in advance./etc/seaweedfsis the default configuration file path for the filer. You can specify specific file locations as needed. - Copy the TiKV keys to the server running the filer in advance.
- By default, SeaweedFS filer allows access without authentication for data security. Refer to Longhorn Create an Ingress with Basic Authentication (nginx) to configure nginx with authentication for the filer web UI. The default port for filer web UI is
8888.
Configure file service:
mkdir -p /seaweedfs/filer/log
cat > /etc/systemd/system/weed-filer.service << EOF
[Unit]
Description=SeaweedFSFiler
After=network.target
[Service]
Type=simple
User=root
Group=root
ExecStart=/usr/local/bin/weed filer -logdir=/seaweedfs/filer/log -ip=192.168.1.1-port=8888-master=192.168.1.1:9333,192.168.1.2:9333,192.168.1.3:9333-s3 -s3.config=/etc/seaweedfs/s3.json
WorkingDirectory=/usr/local/bin/
SyslogIdentifier=seaweedfs-filer
[Install]
WantedBy=multi-user.target
EOF
filer.toml
cat > /etc/seaweedfs/filer.toml << EOF
[tikv]
enabled = true
# If you have many pd address, use ',' split then:
# pdaddrs = "pdhost1:2379, pdhost2:2379, pdhost3:2379"
pdaddrs ="192.168.0.1:2279,192.168.0.1:2279,192.168.0.1:2279"
# Concurrency for TiKV delete range
deleterange_concurrency =1
# Enable 1PC
enable_1pc = false
# Set the CA certificate path
ca_path="/etc/seaweedfs/tikv/tls/ca.crt"
# Set the certificate path
cert_path="/etc/seaweedfs/tikv/tls/client.crt"
# Set the private key path
key_path="/etc/seaweedfs/tikv/tls/client.pem"
# The name list used to verify the cn name
verify_cn=""
EOF
S3.json
# Configure s3 information.
cat > /etc/seaweedfs/s3.json << EOF
{
"identities": [
{
"name": "Name",
"credentials": [
{
"accessKey": "access key",
"secretKey": "secret key"
}
],
"actions": [
"Read",
"Write",
"List",
"Tagging",
"Admin"
]
}
]
}
EOF
Start the master server:
systemctl daemon-reload
systemctl start weed-master.service
Start the filer and volume servers:
systemctl start weed-filer.service
# Start all volume servers.
systemctl start weed-volume{1..10}.service
6) Verify
Use the weed shell to check the status of SeaweedFS components.
# Log in to any master node and enter the weed shell console.
weed shell
# Common commands:
cluster.check # Check cluster network connectivity.
cluster.ps # Check cluster process status.
volume.list # List cluster volume servers.
7) Access SeaweedFS filer
Visit http://192.168.1.1:8888 in a web browser.
Replace the IP with the actual filer address or domain name. It’s recommended to use a domain name for production environments and configure nginx with authentication for the web UI.
Advanced management strategies for JuiceFS
Implementing directory quota management with multiple file systems
When we initially used JuiceFS, the community edition did not yet support the directory quota feature. Therefore, we managed multiple JuiceFS file systems to control file system quotas. This approach required sharing the same cache disk among multiple file systems, leading to competition for cache capacity.
In extreme cases, inactive directories could fill up the cache disk space, preventing active directories from effectively using the cache disk. With the introduction of directory quota feature in JuiceFS 1.1, we evaluated whether to consolidate all file systems and use directory quotas to limit the capacity of each directory. Here are some of our own analyses:
-
Multiple JuiceFS file systems
- Advantages
- Allows directory capacity limitation without using JuiceFS directory quotas.
- Limits data volume in a single file system, facilitating migration of file systems (backing up file systems, cross-data-center migration, negotiating downtime windows).
- Limits the impact range of mount point drop in a single JuiceFS file system.
- Disadvantages
- When a single server mounts multiple JuiceFS file systems, using the same cache disk can lead to cache disk space competition issues.
- Significant waste of CPU and memory resources when multiple directories are mounted simultaneously on a node.
- Low efficiency in copying data across file systems.
- In CSI scenarios, mounting multiple JuiceFS processes on a single server can preempt a certain amount of task memory resources.
- Advantages
-
A single JuiceFS file system
- Advantages
- Exclusive cache disk usage; better caching of hot data compared to mounting multiple JuiceFS file systems on one server.
- Convenient data copying and cloning within the file system.
- Overall fewer JuiceFS processes to maintain.
- Disadvantages
- The bucket is huge. Some object storage has problems such as object number limit, total size limit, and performance degradation. Such extremely large buckets are not supported. This can be addressed by configuring data sharding in JuiceFS.
- Large metadata volume required memory on metadata backup servers, with long backup time making it difficult to back up metadata every hour or every 8 hours. This issue was addressed in JuiceFS 1.2.
- Larger impact range of mount point drops.
- Advantages
Considering our specific situations and migration requirements, we ultimately chose to manage multiple JuiceFS file systems. However, for new users, we still recommend a single file system approach.
Cross-data-center migration of PB-scale data within JuiceFS
Over the past three years, we’ve conducted extensive data migration work involving a total data volume of 3 PB. Our experience indicates that the fastest method for migrating data between two JuiceFS instances is using S3 data transfer combined with metadata switching. For example, while scanning a 50 TB file system with rclone may take at least half a day, direct data transfer methods could complete the migration in as short as 10 minutes to half an hour.
Typical file system migrations rely on data copying methods, whereas migrations between JuiceFS file systems incorporate innovative approaches. JuiceFS itself does not directly store data but maintains file metadata in a metadata engine and stores file data in object storage.
This unique architecture allows for innovative approaches to handle data migration. Specifically, JuiceFS allows migration operations by replacing metadata and S3 data. By ensuring complete alignment of metadata and S3 data before and after migration, a clone system that is the same as the original system can be generated through configuring JuiceFS settings.
- When migrating object storage, use object storage copying and configure object storage settings.
- When migrating metadata, use metadata dump and load (metadata backup and restore).
- When migrating both object storage and metadata, simultaneously use S3 data transfer, metadata import/export, and configure object storage.
After switching data, verify data consistency using the juicefs fsck command to check the existence of every S3 object required by the file system. However, the main drawback of this method is the downtime required for incremental data synchronization and metadata switching. For a single file system, downtime duration = incremental data synchronization + metadata switching (+ data verification). In addition, extra outdated data at the destination end can be cleaned up later using juicefs gc during the data synchronization process.
Incremental synchronization + data switching:
# Use juicefs sync for initial data synchronization.
juicefs sync--list-depth=2-u --delete-dst --no-https -p 40 s3://xxx:xxx@$bucket.oss s3://xxx:xxx@$bucket.oss2
# Use rclone for supplementary synchronization.
rclone copy --log-file=xxx --ignore-existing --checkers 300--transfers 150 s3-1:bucket1 s3-2:bucket1
# Use juicefs to dump and load metadata.
juicefs dump "origin meta address" meta.json
juicefs load "new meta address" meta.json
# Configure the new file system to use the new S3 and update AK/SK.
juicefs config "new meta address"--bucket $NEW_BUCKET_ADDRESS--access-key xxxx --secret-key xxxx
# Use fsck to check file system consistency.
juicefs fsck "new meta address"
In this article, we shared how we deployed SeaweedFS and TiKV, performed data migration, and set directory quotas. We hope our experience provides valuable reference to other users in the community.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and their community on Slack.