















The content of this article is from the keynote speech of Juicedata co-founder Rui Su at the CNutCon 2018 Global Operations Tech Conference held in Shanghai.

Hello everyone, my name is Rui Su. The topic I am going to share today is called Building a SA friendly storage system. Our team has built a cloud distributed shared POSIX file system over the past year and a half. In general, it is a cloud hard drive with features like unlimited capacity, flexible expansion, and shared among machines. When we initiated this product, we set a goal: excellent user experience.
When talking about the user experience, we must first define who the user is? In daily work, the most frequently dealing with the storage system is the operation engineer. Therefore, our primary goal is to be operators friendly. Therefore, I also want to share what has been done to improve the operation and maintenance experience in the process of building JuiceFS over the past year.
Over the past 20 years, there has been an apparent data explosion every five years, the web portal in 2000, Web 2.0 in 2005, big data in 2010, artificial intelligence in 2015, smart manufacturing and IoT in 2020. However, no matter how it grows, the most concerned aspects of storage have not changed: capacity, security, performance.
I will follow around these three aspects. The essential works in terms of capacity are capacity planning and space management. Security is indispensable for backup. The performance revolves around monitoring and performance analysis.

First of all, capacity planning has always been a dilemma. Small capacity unable to fulfill the fast-growing business, and requires continually expanding. Large capacity means low resource utilization and high cost.
The data center era will involve procurement and the process will be longer. The cloud platform can reduce the procedures, but the cloud disk space still needs to do capacity monitoring, manual expansion, manual partition expansion, etc. Some clouds need to restart the machine to take effect, which causes the whole process is not easy.

When thinking about the cloud era, must we plan capacity? Our idea is: unnecessary.
One of the most significant advantages of the cloud is on-demand and flexibility. Is there a storage system on the cloud with these advantages? Naturally, we think about object storage. However, the key-value structure of the object storage cannot meet the needs of many business scenarios and requires a customed API. Besides, it is hard to manage data without directory. Don't underestimate the problem of not having a directory, because the object storage space is unlimited, it seems very fabulous, so everyone is used to putting all kinds of data into it, including some temporary files, forgetting to delete when used, my colleague working for Facebook have done a data cleanup, guess how much useless data is eliminated? Dozens of PBs! As another example, if you want to know what types of data stored in a bucket, it is not easy to traverse the scan. My colleagues have done it while working on Databrick, and the workload is at least "week" level.
We believe that the experience of file management and use in a single node operating system is better. Therefore, JuiceFS fully inherits the experience of the single node file system, while providing unlimited capacity and flexible scaling.
Back to the previous example, it is much simpler if it is a file system, Using command ls, or du to lists the overall directory capacity distribution. However, it is relatively slow with du statistics for a folder with a deeper level and an immense number of files. The user experience is terrible, and we want to make a change, the goal is faster and intuitive.
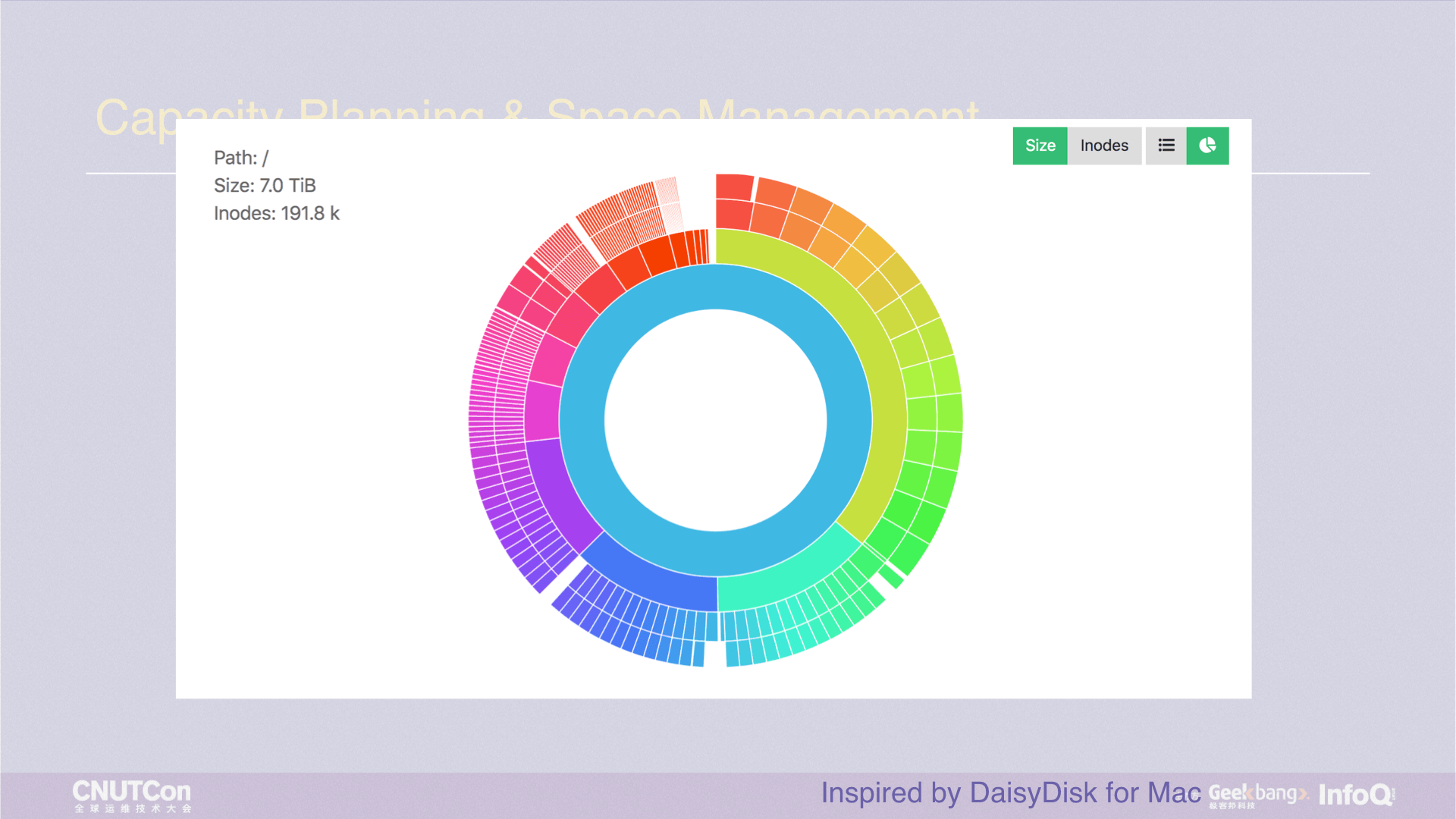
JuiceFS provides a web management interface. Here we present a graphical data distribution that shows the current capacity or distribution of inodes in real time. The circle in the picture has four layers, which represent the top four-level directories. Each small color block is a directory. Move the mouse pointer over it, and the directory name will be displayed, so that you can precisely know which one is the largest.
Suppose the red part of the diagram is a /tmp directory with lots of subdirectories and files. I want to delete it. Using rm -rf will result in the same situation as the du command, costing a long time, because it is essentially a recursive delete. This kind of experience is terrible, we hope to delete files in seconds level, so we made a juicefs rmr command, any directory can be deleted in seconds. Moreover, if you delete mistakenly, rest assured. JuiceFS has a trash mechanism, and you can recover the files from the trash.

Next, let's talk about backup.
Previously in the data center, the first data security mechanism was RAID. On the cloud, the cloud drive is redundant with multiple copies, but it does not mean it is 100% secure. AWS published official data: EBS annual failure rate is 0.1%~0.2%, which means that if you have 1000 disks, each year will break 1~2 disks, but the break here means that part or all of the data is lost.
Doing backups is not copy it to elsewhere. Many applications have data backup problems with logical correctness, such as databases. In 2017, GitLab accidentally deleted the online database on maintenance. Although they have a backup mechanism, they found the five backup are all broken. Because these backups have not been verified, and they found this problem only when they need to do recovery.
After backup and verification, the data is secured? Not enough, valuable data must be backed up in offsite. In 2015, Google Europe's data center was thundered. After various recovery, some data is still lost, because all copies of this part of the data are stored in this data center without offsite backup.

As I just mentioned backup verification, let me talk about it in detail. The figure is a standard process for MySQL physical backup. Make a physical backup with xtrabackup on a MySQL slave library, and the first step is to write to the local disk, then compress and encrypt it, and upload to the object storage or HDFS. Then start the verification process, download/copy from the object storage or HDFS, decrypt, decompress, and then load the data with a new MySQL instance. If it can start successfully, check the replication status of the MySQL main library, if it is normal, then it is a valid backup.
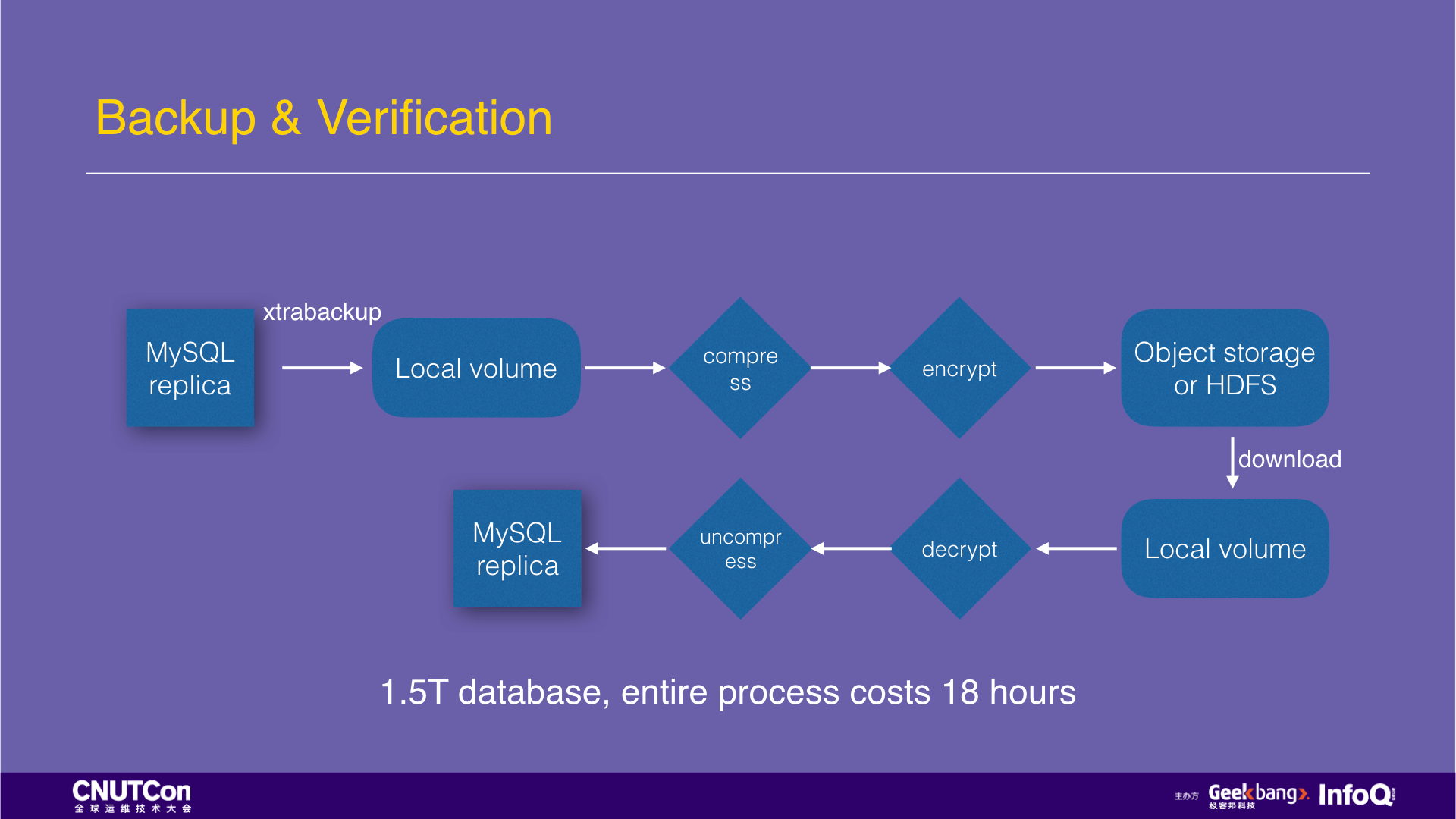
Such MySQL backups are highly serialized. In the production environment practice, it takes 18 hours for the 1.5T data to complete the above process. If you switch to JuiceFS to store backups, the physical backup files made by xtrabackup can be written directly to JuiceFS, which is automatically compressed and encrypted during the writing process and is highly parallelized. After the backup data is completed written, create a snapshot in 1 second, load the snapshot with an empty MySQL instance and you can verify it. It takes a total of 2 hours and tremendously increased the performance. (attached detailed documentation and code)

Time savings are the most valuable part when recovering from a failure. In the previous GitHub 24 hours accident, 10 hours of the recovery process was used to download the database backup. If they used JuiceFS, it would not take so long.
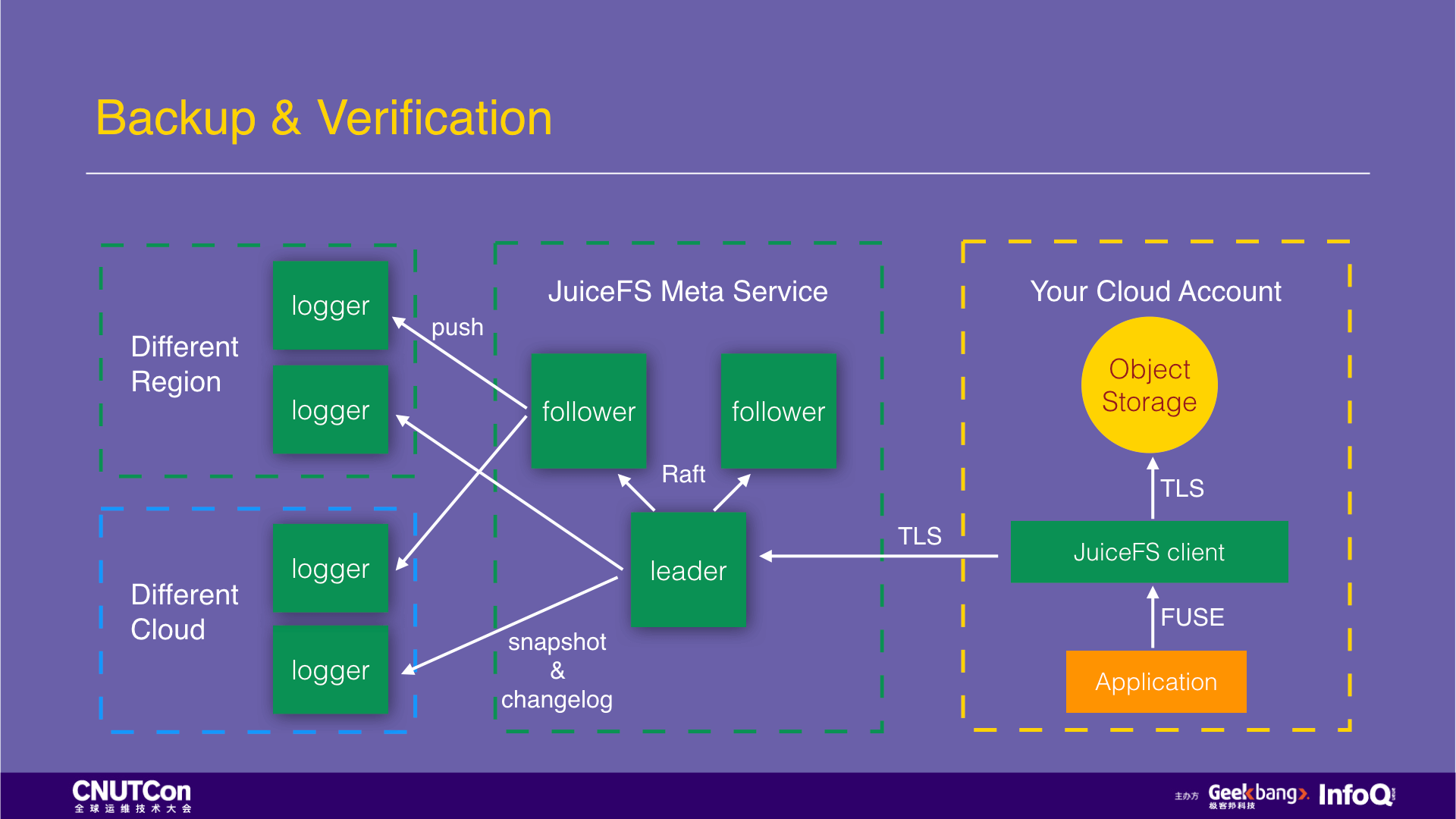
After talking about MySQL backup, let's talk about how JuiceFS does its backup. The following is the architecture diagram of JuiceFS. After the data is written by the JuiceFS client, the data content will be stored in the customer's object storage. JuiceFS will never be accessible, and the persistence security of this part of the data is provided by the object storage. Usually, it is 99.99999999%. The Inodes data is saved to the metadata service of JuiceFS. This service deploys three nodes. They use the Raft protocol to ensure strong consistency and high availability. Each write transaction requires two nodes to confirm the completion. The data is first saved in the memory to meet the needs of high-performance access, and write a copy to the hard disk as a backup. At the same time, two nodes will push two transaction logs to loggers in different cloud platforms and different availability zones for offsite backup. In addition to the transaction log, the metadata service also creates a snapshot of the metadata information in memory every 8 hours for backup.
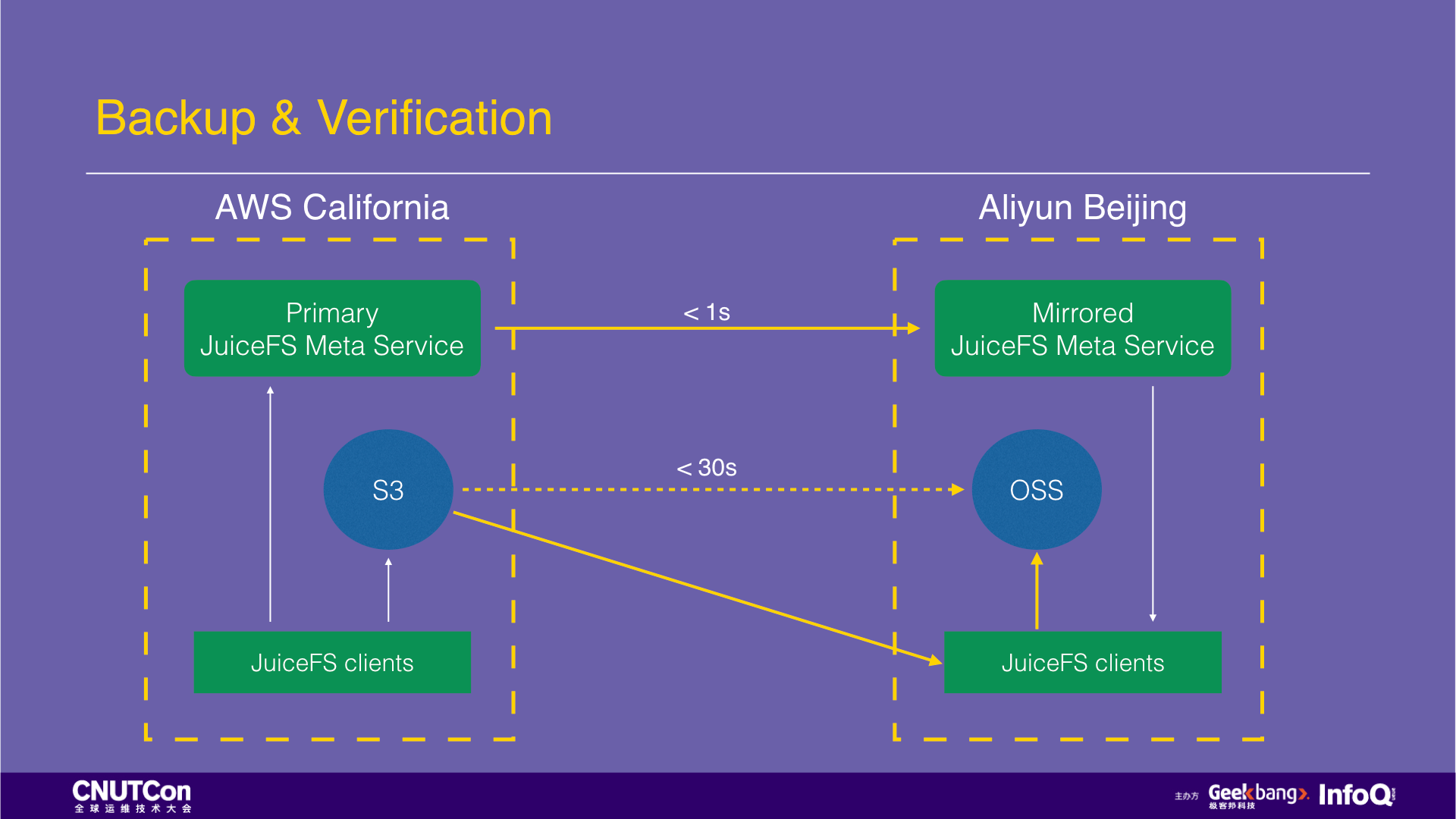
Now let's talk about offsite backup. Suppose a Chinese company that does an oversea business. They deployed services in California and wants to do an offsite backup in China. The usual way is to use the cronjob to perform timing synchronization with tools such as scp and rsync. What if doing the offsite backup using JuiceFS?
Just check the “Enable replication” function on the JuiceFS web console, select which cloud and region for the destination, and then all the written data will be copied automatically. The entire offsite backup process is entirely transparent to the user. Moreover, the high-performance access to this data is also available on the cloud platform of the destination.
We mentioned object storage, so if I want to make a backup for my object storage? We recently open source a tool named JuiceSync, which can copy files in two arbitrary object stores and currently supports 13 object storage service providers worldwide.

Finally, let's talk about monitoring. First ask everyone a question: How many monitoring metrics do you need to operate an HDFS cluster? The following slide shows only a small set of core metrics, and each time after the DataNode node expanded, a new set of metrics will be added. The collection and monitoring configuration of these indicators is not the most trouble. The painful problem is that if there is an indicator alarm at night, and you have to get up and handle it.

We believe that maintaining a distributed system is not an easy task, and these complex operations and processes did not create value for users. Therefore, we have made JuiceFS a fully managed service, and users do not need to deploy, operate, and maintain. Just click on the website, the client is ready after the installation. At the same time, JuiceFS is not a black box for users but exposes all key indicators to users through API. For popular monitoring systems, such as Prometheus, we also have pre-defined dedicated APIs. Just add it then all the indicators of JuiceFS can be monitored.

For storage systems, in addition to monitoring health status and ensuring that it continues to provide reliable service, an important aspect is performance. Storage systems often become performance bottlenecks of the entire system. However, at first, we need to analyze whether the upper-layer applications reasonably using storage systems. Many times the I/O bottleneck is not caused by the storage system, but caused by improper usages.
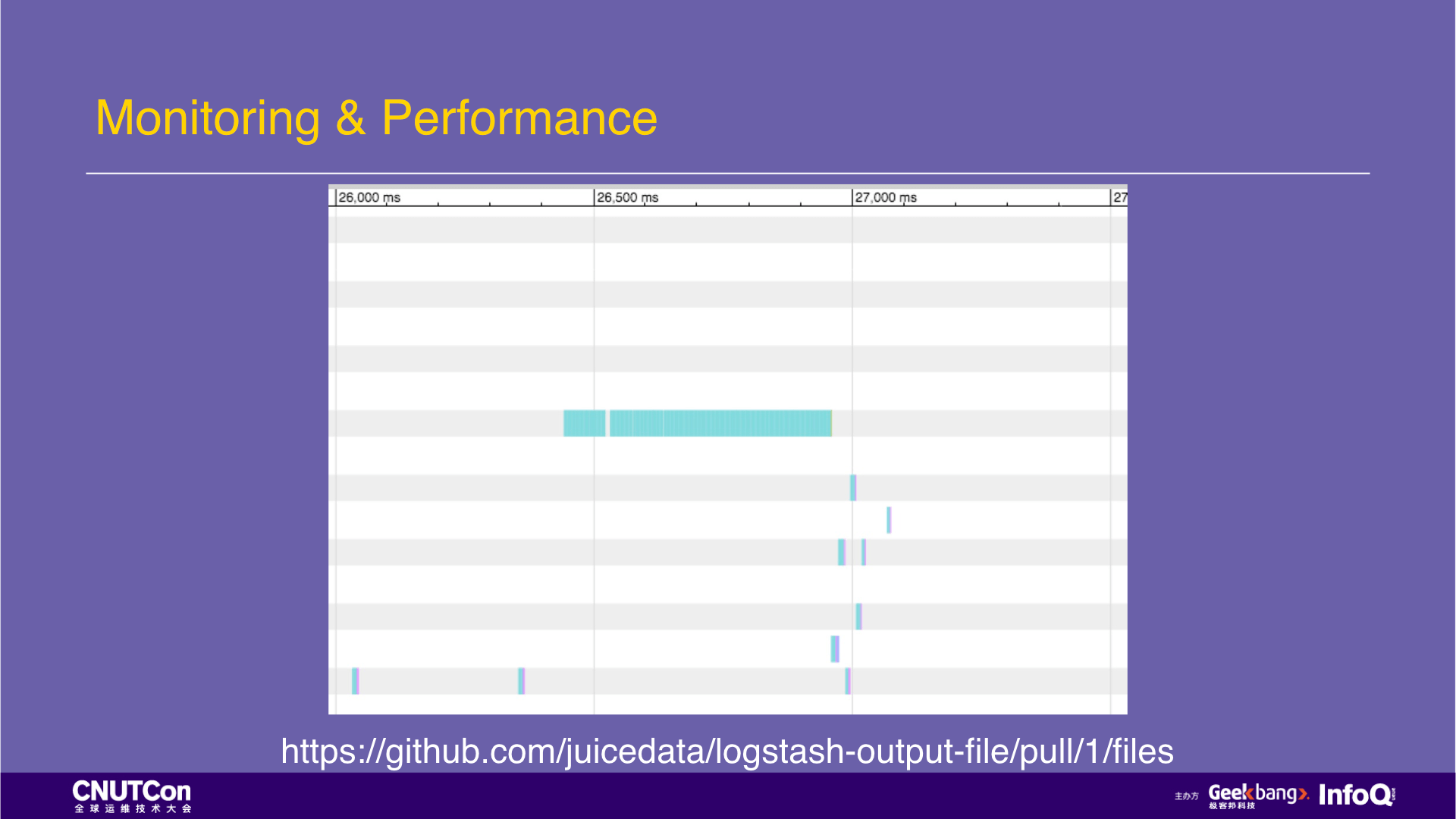
JuiceFS also provides a graphical approach for performance analysis. For example, here is a real customer case. The problem occurred in the logstash-output-file plugin. The customer was saying that their log write load is too high, and JuiceFS can't carry it, so there is a write bottleneck.
Analyze the read and write properties of a period with JuiceFS graphical performance analysis tools. It shows the system calls on all file systems. At this time, only the logstash is written, so it is also very simple to do the isolation of the system call, ensuring that no other irrelevant information will be mixed into the analysis.
In the figure below, each row represents a thread, and each color is a file system access, and different colors represent different system access functions.
From the figure, we can see two problems. The first is that most of the color blocks are blue, and the blue color represents the lookup operation. Another problem is that the operation of JuiceFS has filled the entire process time, which indicates that the storage is the bottleneck.

According to the first question, why most of the calls are lookups? What is the application layer doing? With these questions, we look at the source codes of logstash-output-file. We found that logstash was checked whether the file exists before writing the file. The lookup call also checks whether the file exists before writing the file. In POSIX, this statement will generate a large number of lookup operations according to the level of the directory hierarchy. The problem here is that logstash-output-file checks that the file is deleted or not each time new data is written although the write cache is turned on. This kind of operation to check whether a file exists or not is very inefficient, and it is inconsistent with its write cache, so we made a modification: managed the buffer that writes the data by itself (instead of JRuby's default buffer), so that the check is done only when the data is to be written to the file, which greatly reduces the frequency of its calls and improves the overall performance.
After the completion of this modification, the effect is as follows. The operations of writing files are merged, the entire process is no longer occupied by I/O operations, and storage is no longer a bottleneck. See the Pull Request link for this improvement.
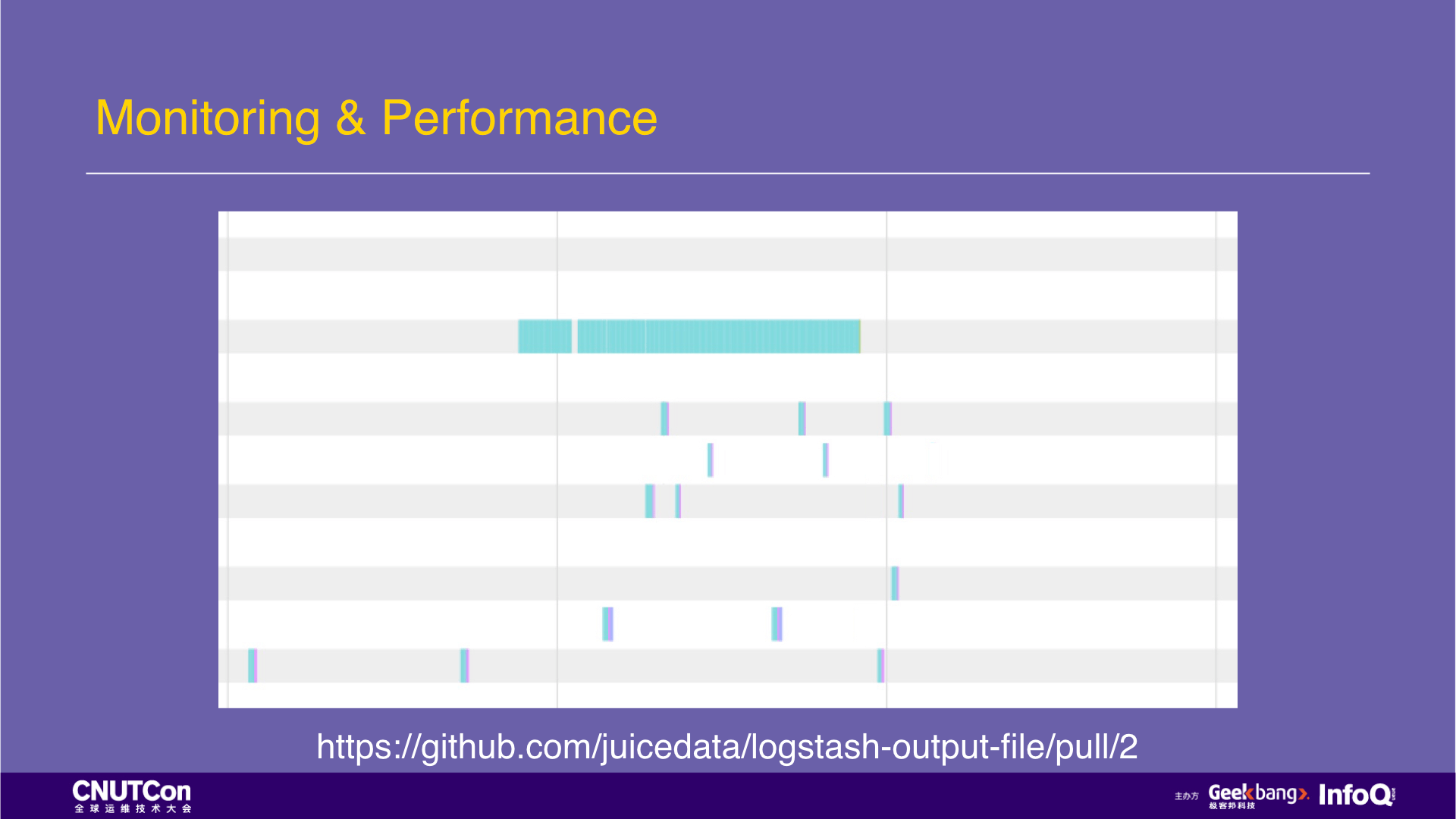
However, there is another problem. In multiple threads, I/O operations are not parallelized, and threads are waiting for each other. Why? We have a hypothesis that a global lock is used in this program, which leads to the above situation.
With the problems, we continue to look at the source codes of logstash-output-file, and finally found a global lock. Through analysis, we determine that the global lock granularity is too large. We made changes to reduce the lock granularity to the file level, then run the application and capture the performance log of the following figure. It can be seen that the I/O operations between multiple threads can be paralleled and the performance is further improved. Here we also submitted the Pull Request for the modification of the lock.
That's it. Let us do a review.
In terms of capacity, JuiceFS provides elastic capacity and no longer requires capacity planning. It also provides a fully POSIX-compatible experience with advantages such as directory structure, file permissions, compatibility with all Linux command-line tools and scripts, and graphical management and optimized commands to speed up execution.
In terms of security, JuiceFS is very suitable for data backup of various applications. It can easily perform backup verification and can be fully transparent for compression, encryption, and offsite backup and disaster recovery. The efficiency is increased by order of magnitude.
In terms of performance and monitoring, JuiceFS provides a monitoring API to let users understand all aspects of the metrics, and provides a graphical way to do performance analysis, making performance optimization work easier and intuitive.

That's all. Thank you!