















NetEase Games, a division of NetEase, Inc. (NASDAQ: NTES and HKEX: 9999), is one of the largest Internet and video game companies in the world. Our portfolio includes popular titles like Knives Out, Harry Potter: Magic Awakened, and Naraka: Bladepoint. We also partner with major entertainment brands like Warner Bros and Mojang AB (a Microsoft subsidiary).
In early 2020, as our international business grew and data compliance demands increased, we initiated the internationalization of our big data offline computing platform. Initially, we used cloud-hosted virtual machines with high-performance EBS storage, but this approach proved costly, much higher than the costs of our self-built data centers in China.
Therefore, we opted to construct a platform on a public cloud, aiming to better suit current business needs, maintain legacy compatibility, and offer a more cost-effective solution than public cloud-managed EMR. Our cost optimization efforts focused on storage, compute, and data lifecycle management, with key contributions from JuiceFS.
This project successfully provided full Hadoop compatibility to downstream data and analytics teams without the need for extensive reworking. It also delivered substantial cost savings for our international gaming data business: storage costs were reduced to 50% of the original, total compute costs dropped to 40%, and the cost of storing cold data reached just 33% of the online storage costs post-optimization. As our business continues to grow, we anticipate a tenfold cost reduction, offering robust support for future data-driven international operations.
This article will explore our cloud migration solution for the big data platform, specifically focusing on our storage solution after comparing HDFS, object storage, and JuiceFS. We’ll delve into how we optimized our costs in storage, computation, and data lifecycle management, as well as evaluate the performance and cost-effectiveness of our new architecture online.
Designing an international cloud migration solution for our big data platform
Originally, our operations relied on self-built clusters for deployment and execution in China. In 2020, we embarked on an urgent international expansion mission. To ensure a swift launch, we quickly introduced a solution identical to the original cluster setup. We implemented a storage-compute coupled system using physical nodes. We used the bare-metal server m5.metal and employed Amazon EBS gp3 for storage.
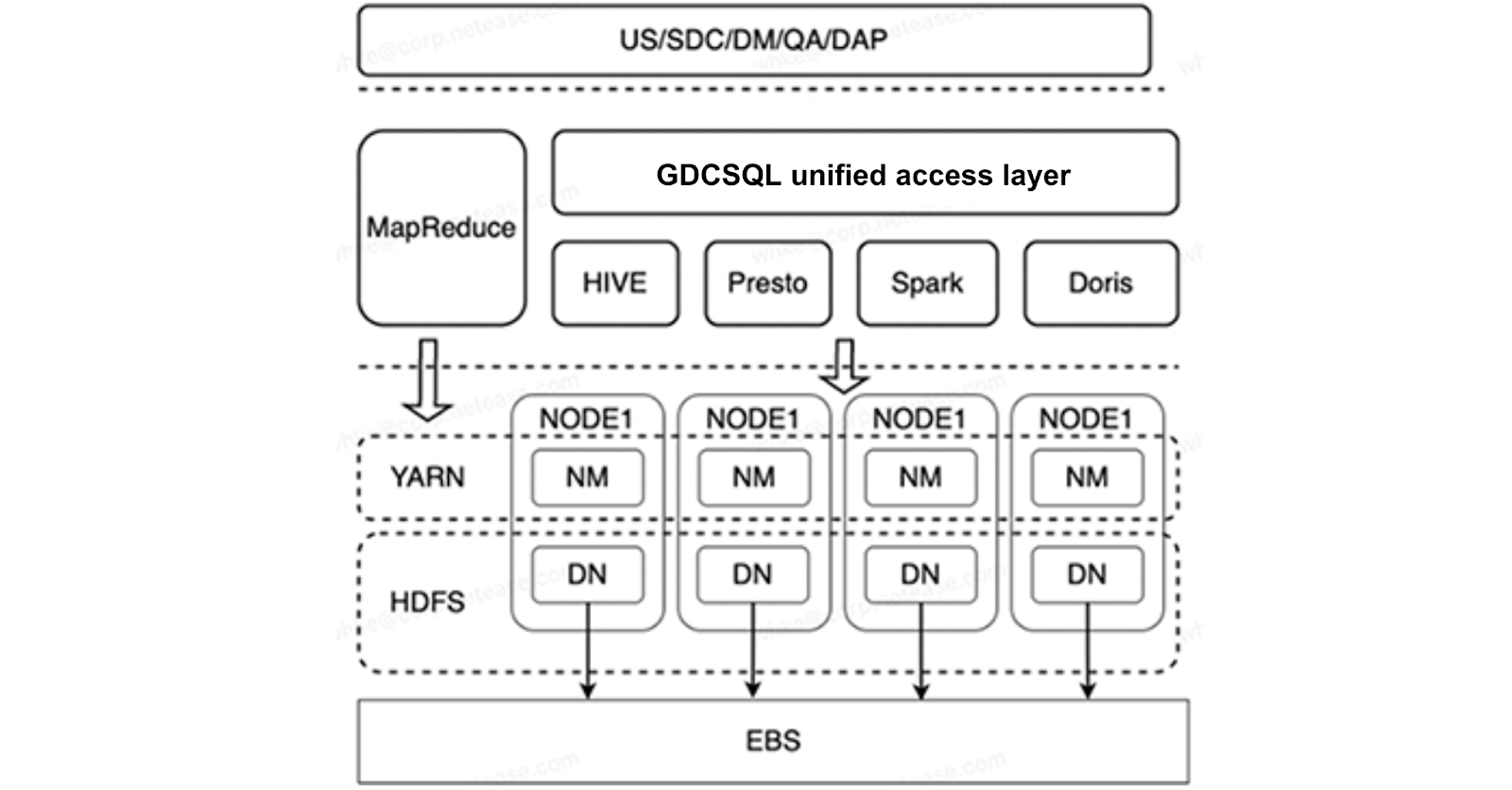
While this solution addressed the immediate challenge of seamless migration of historical application processes, it came with the drawback of high costs. As we move forward, we need to reevaluate our approach to achieve higher performance, lower costs, and maintain compatibility. We've assessed potential strategies based on application requirements and the characteristics of big data scenarios:
- Balancing performance improvements with trade-offs in time and space.
- Customizing deployment strategies according to specific application needs.
- Incorporating middleware to ensure seamless compatibility.
- Maximizing cost efficiency using cloud resource features.
Migrating Hadoop to the cloud
Two common approaches for moving Hadoop to the cloud are EMR + EMR File System (EMRFS) and Dataproc + Google Cloud Storage (GCS). However, we didn’t choose these options due to our heavy reliance on our customized internal version of Hadoop, tailored to our unique application needs. Additionally, transitioning to cloud-native solutions like BigQuery, Snowflake, and Redshift posed substantial changes.
Why we didn’t choose EMR
Our applications heavily relied on our customized Hadoop version with various backward-compatible features and optimizations. Many internal requirements were not covered by EMR's Hadoop version. Cloud-native solutions like BigQuery would entail significant and distant changes to our existing setup.
Why we didn’t directly use S3 storage
We didn’t directly use S3 storage because of the following reasons: - Due to stringent security requirements, our applications demanded complex permission designs beyond the capabilities of AWS Identity and Access Management (IAM) roles. - S3's performance limitations required optimizing measures like bucket partitioning and random directories. Adapting our current directory structure to S3 partitioning or using more buckets would necessitate significant adjustments to our application processes. - S3's directory operations like listing and du are impractical for large file datasets, a common occurrence in big data scenarios.
Storage options: HDFS vs. S3 vs. JuiceFS
We evaluated HDFS, S3, and JuiceFS and made a quick comparison summary as shown in the table below:
| Comparison basis | HDFS (block device) | S3 (object storage) | JuiceFS Community Edition |
|---|---|---|---|
| Application compatibility | High | Limited | Moderate (SDK deployment) |
| Consistency | Strong consistency | Partial strong consistency | Strong consistency |
| Capacity management | Reserved resources | On-demand | On-demand |
| Performance | Strong | Limited | Strong |
| Authentication | Enterprise-grade | None | None |
| Data reliability | High | Moderate | Low (Redis-based) |
| Cost | High | Lowest | Low |
We made this comparison based on the following criteria:
- Application compatibility: Given our need to migrate numerous existing applications, compatibility was crucial. We needed to reduce not only storage costs but also resource and labor costs. JuiceFS Community Edition offers Hadoop compatibility, but it requires deploying the JuiceFS Hadoop SDK on the user side.
- Consistency: S3 lacked strong consistency before the first quarter in 2020, so it was unsuitable for our needs. Currently, not all platforms can achieve strong consistency.
- Capacity management: Our self-built cluster required resource reservations, so on-demand usage was a cost-effective approach.
- Performance: A HDFS-based solution could match the performance of our original HDFS. The SLA we provided to our original applications was to achieve P90 RPC performance within 10 milliseconds under a single-cluster scenario with 40,000 QPS. However, achieving similar performance with S3-like solutions was challenging.
- Authentication: Our self-built cluster used Kerberos and Ranger for authentication and permission management, which S3 did not support. JuiceFS Community Edition also lacks this support.
- Data reliability: HDFS ensured data reliability with three replicas. In our tests, JuiceFS used Redis as a metadata engine. We found that in high-availability mode, storage experienced delays during primary node switches. This was unacceptable for us. Therefore, we opted to individually deploy Redis metadata services on each machine.
- Cost: A solution involving block devices would incur high costs. Our aim was to use S3, as the lowest cost is attained when everyone only uses S3. However, using JuiceFS introduces some additional costs in the later architecture.
Hadoop multi-cloud migration solution
The storage layer: Hadoop+JuiceFS+S3
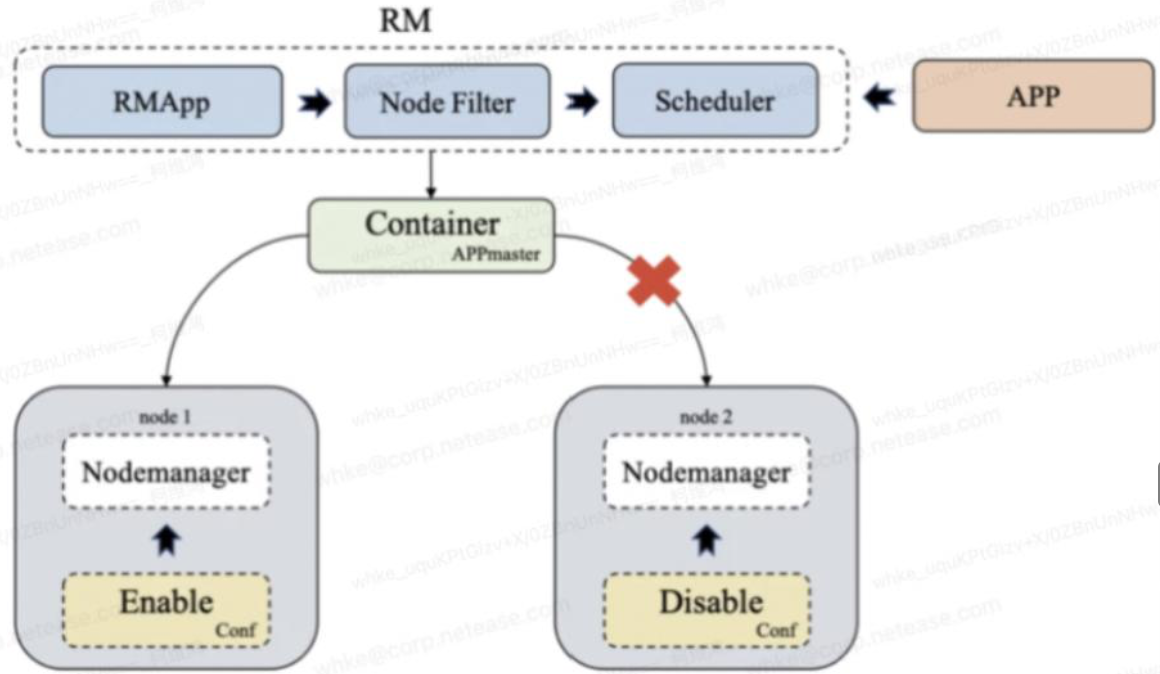
We've integrated JuiceFS with Hadoop to lower compatibility costs. While many users use JuiceFS Hadoop SDK with the open-source version of Hadoop, the absence of Ranger and Kerberos support in JuiceFS Community Edition posed authentication challenges. Therefore, we use Hadoop's complete framework. As the figure below shows, we mount JuiceFS onto Hadoop via FUSE and link it with S3 storage.
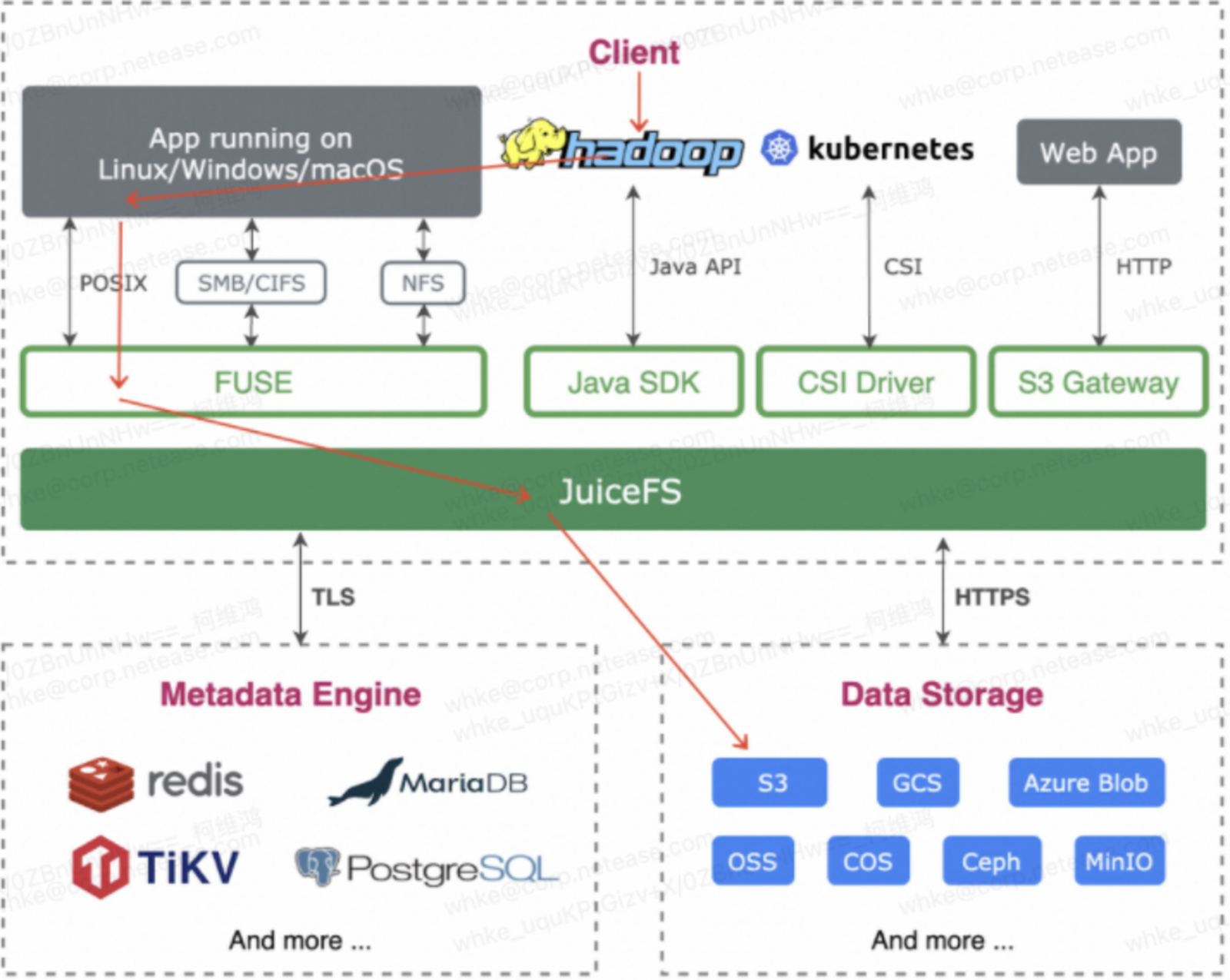
Comparing performance with the EBS-based single-cluster approach:
- We achieved a P90 latency of 10 ms at a rate of 40,000 queries per second (QPS).
- Our single node effectively handled 30,000 input/output operations per second (IOPS).
We initially used the HDD mode (st1 storage type), when transitioning to the cloud. However, we quickly realized that the actual IOPS provided by st1 storage fell significantly short of our requirements when the node count was low. Consequently, we made the decision to upgrade all st1 storage types to gp3.
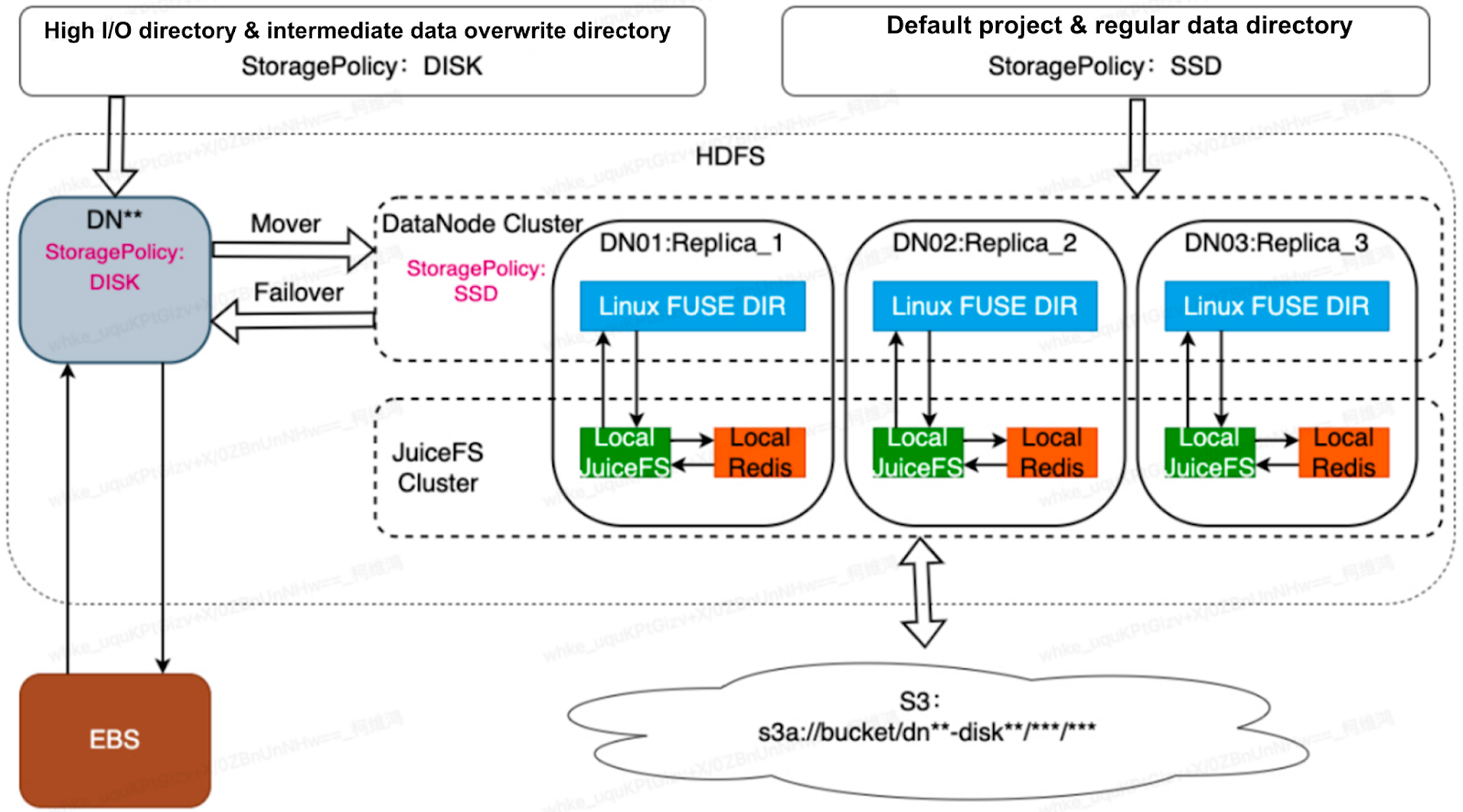
We upgraded from HDD to gp3 storage, achieving 30,000 IOPS. Each node has 10Gb bandwidth. Our goal is to integrate S3 storage cost-effectively while ensuring compatibility with Hadoop.
We deploy local JuiceFS and Redis instances on each machine to maximize the performance of JuiceFS and minimize the local metadata overhead.
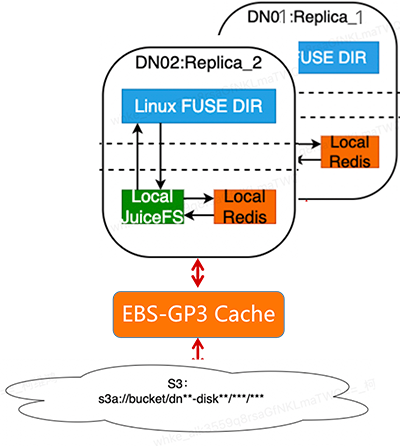
We bind our system to Data Node Objects (DNO) and use HDFS multi-replica mechanisms for data reliability.
Our optimizations include using JuiceFS for caching and read-write strategies, allowing us to achieve high-performance HDFS. We divide HDFS storage into "DISK" and "SSD" components. "DISK" uses EBS storage for frequent overwrites, while "SSD" leverages JuiceFS and S3 for cost-effective, high-performance storage.
The compute layer: Mixed deployment of Spot nodes and on-demand nodes
When we migrated our self-built YARN cluster to the cloud, it could not adapt to the cloud's resource characteristics to achieve cost optimization. As a result, we implemented a combination of YARN-based intelligent dynamic scaling and label scheduling. We also deployed a mixture of Spot and on-demand nodes to optimize compute resource utilization. Key strategies employed:
- Adjusted the scheduler strategy to CapacityScheduler.
- Divided the on-demand nodes and Spot nodes into several partitions.
- Adjusted the stateful nodes to the on-demand node partitions, allowing different states of tasks to run in different partitions.
- Used on-demand nodes as a fallback.
- Implemented node reclamation notifications and GracefulStop, ensuring preempted nodes receive advance notices before recycling, allowing for graceful termination of jobs.
- Utilized Spark+RSS to reduce the probability of job recalculations when nodes are recycled.
We’ve implemented dynamic intelligent scaling solutions based on our application requirements. Compared with the native solution, we focus more on dynamic scaling based on application status because cloud vendors may not be aware of peak business times.
Our intelligent scaling strategies included:
- Periodic forecasting using our internal operational tool, Smarttool. This involved fitting historical data from the previous three weeks, generating a residual sequence (resid), and predicted values (ymean). Smarttool then forecasted resource usage for specific days and times, enabling dynamic scaling.
- Timed scaling based on time rules, such as pre-scaling for specific times like monthly report generation on the first day of each month or major promotions.
- Dynamic scaling based on utilization rates. If capacity usage exceeded an upper threshold or fell below a lower threshold within a specified timeframe, automatic scaling out or in was triggered to accommodate unexpected usage demands.
Lifecycle management: Data tiering for storage cost optimization
We’ve integrated JuiceFS and S3 for data reliability through a replication mechanism. Whether it's 3 replicas or 1.5 replicas with erasure coding (EC), there are additional storage costs involved. However, once data reaches a certain lifecycle stage, its I/O demands may decrease. Therefore, we introduced an additional layer of Alluxio+S3 with a single replica to manage this data. It's worth noting that without changing the directory structure, the performance of this layer is lower than using JuiceFS. Nevertheless, in scenarios with infrequently accessed data, we find this performance acceptable.
To address this, we developed a data governance and tiering service that asynchronously manages and optimizes data based on its lifecycle. This service is known as the Business Tiering Service (BTS).
BTS is designed around our file database, metadata, and audit log data. It manages data lifecycles by regulating tables and their hotness. Users can create custom rules using the DAYU Rulemanager and define rules based on data hotness to categorize data as either hot or cold. Based on these rules, we perform various lifecycle management operations on data, such as compression, merging, transformation, archiving, or deletion, and distribute them to a scheduler for execution. BTS provides the following capabilities:
- Data reorganization: Merging small files into larger ones to optimize EC storage efficiency and reduce namenode pressure.
- Table storage and compression format conversion: Asynchronously transforms tables from text storage format to ORC or Parquet, and converts compression formats from None or Snappy to ZSTD, improving storage and performance efficiency. BTS supports asynchronous table conversions by partition.
- Heterogeneous data migration: Asynchronously moves data between storage architectures to provide organizational capabilities for data tiering.
Our storage tiering architecture consists of three layers:
- HDFS on JuiceFS (hot), with 3 replicas for high performance.
- HDFS on JuiceFS EC mode (warm), with 1.5 replicas.
- Alluxio on S3 (infrequently accessed cold data), with 1 replica.
All data is archived to Alluxio on S3 and converted to a single replica before it is removed from the system. Currently, the data lifecycle governance results are as follows:
- 60% cold, 30% warm, 10% hot.
- Average replicas is 1.3 (70% * 1 + 20% * 1.5 + 10% * 3 = 1.3). In low-performance scenarios like archiving, we achieve approximately 70% with 1 replica, around 20% with EC replicas, and about 10% with 3 replicas. Overall, we control the number of replicas, maintaining an average of around 1.3.
The performance and cost of our new architecture online
During testing, JuiceFS achieved high bandwidth for reading and writing large files. Especially in the multi-threading model, the bandwidth for reading large files approached the limit of the client's network interface bandwidth.
In the context of small files, the IOPS performance of random writes was good (thanks to the gp3 disk serving as a cache), while the IOPS performance of random reads was low, about five times worse.
The table below shows the test results of JuiceFS Community Edition’s read and write performance:
| Scenario | IOPS | Bandwidth | P95 USEC |
|---|---|---|---|
| Single-threaded writes (File of 4 MB) | 171 | 718 MB/s | 14,353 |
| Multi-threaded writes (File of 4 MB) | 175 | 738 MB/s | 128 |
| Single-threaded reads (File of 4 MB) | 231 | 970 MB/s | 13,829 |
| Multi-threaded reads (File of 4 MB) | 427 | 1,794 MB/s | 134 |
| Single-threaded random writes (File of 4 KB) | 3,272 | 13.4 MB/s | 64 |
| Single-threaded random reads (File of 4 KB) | 630 | 2,584 KB/s | 2,245 |
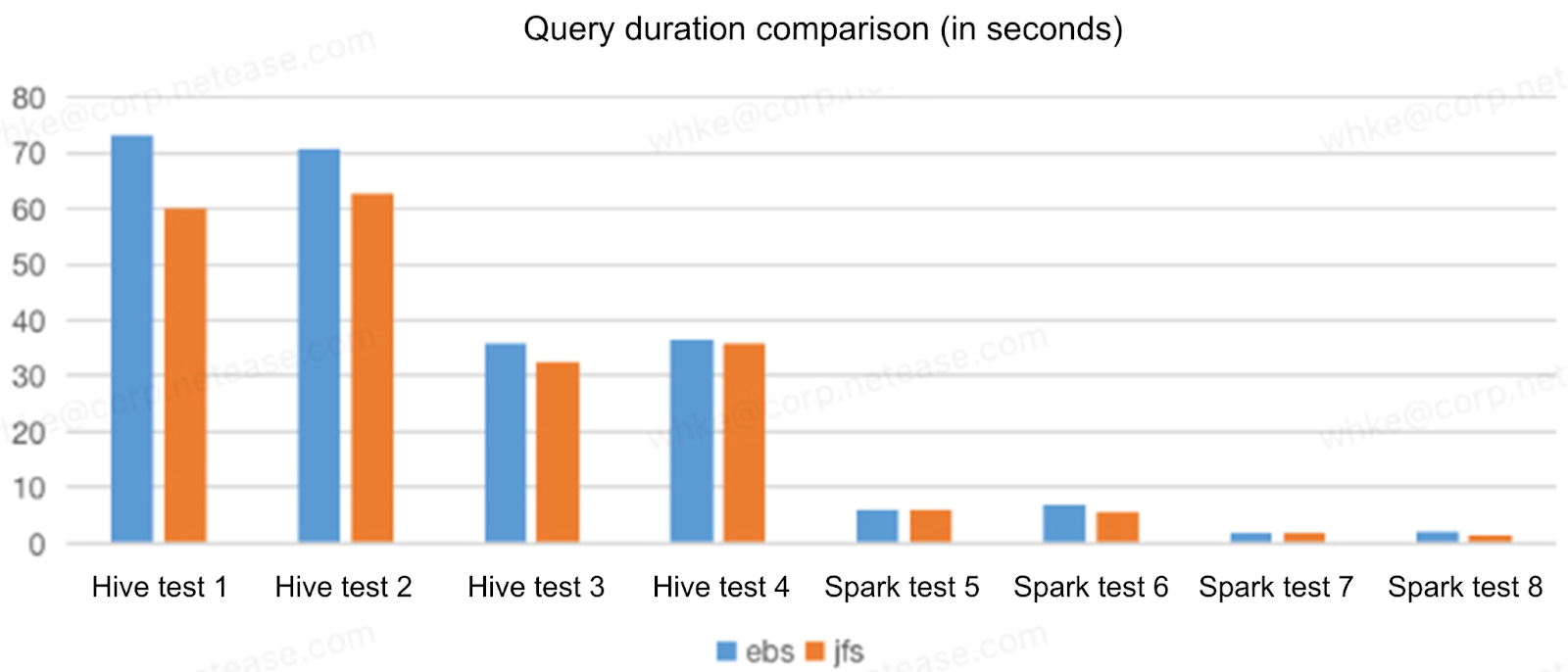
The following figure is a comparison between the EBS solution and the JuiceFS+S3 solution in application testing. The test case is the application SQL statements in our production environment. The results show that the performance of JuiceFS+S3 was not much different from that of EBS, and the performance of some SQL queries was even better. So JuiceFS+S3 could replace all EBS services.
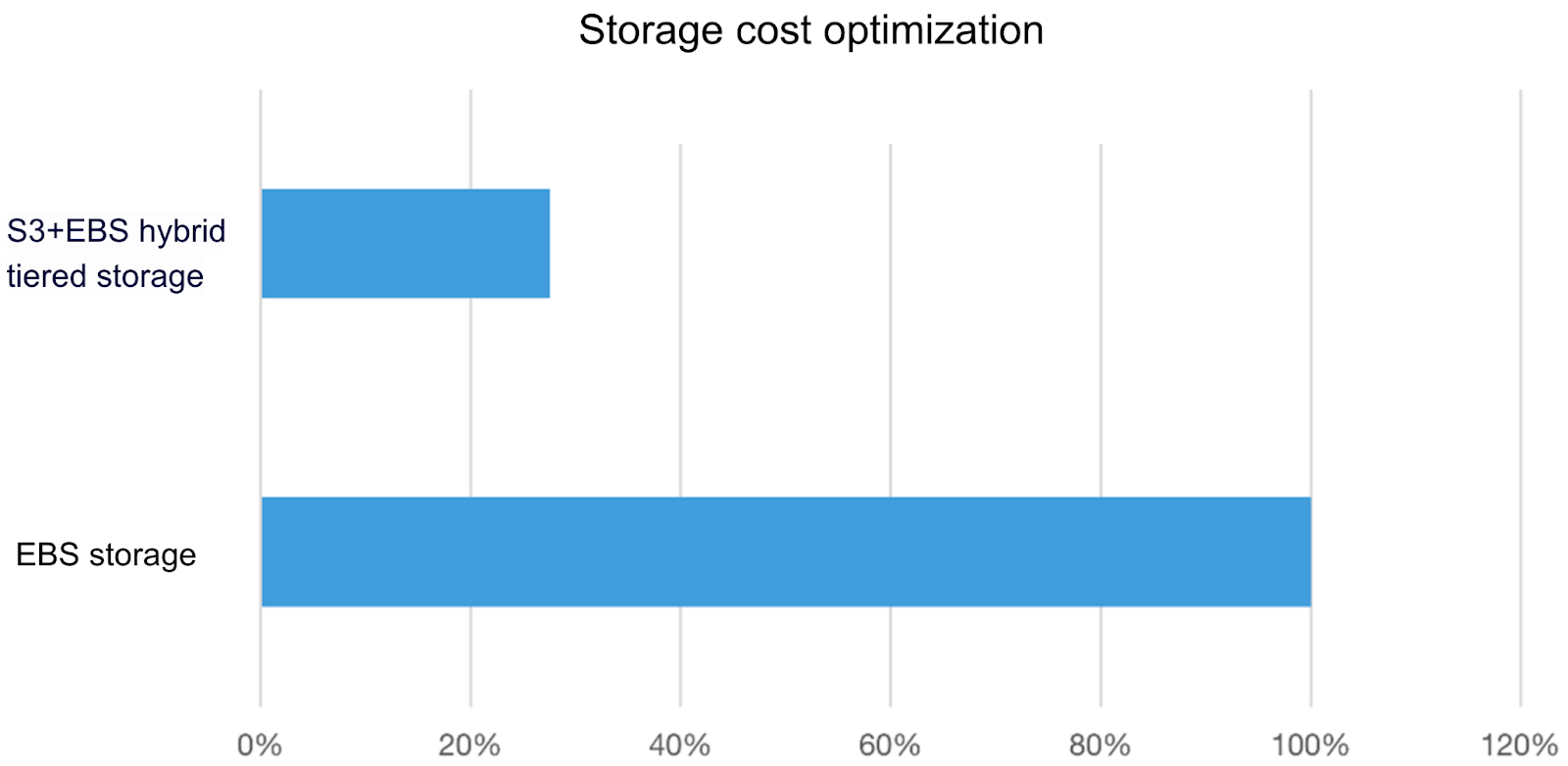
We use JuiceFS-based S3+EBS hybrid tiered storage-compute decoupled solution to replace the original EBS solution. By data governance and data tiering, we’ve reduced the original Hadoop 3-copy mechanism to 1.3 copies, saving 55% on multi-copy cost. The overall storage cost dropped by 72.5%.
Through intelligent dynamic scaling, our cluster utilization has reached 85% and we’ve replaced on-demand nodes with 95% of Spot instances. The overall computing cost has been optimized by over 80% compared to before.
What’s next
Compared to the native JuiceFS solution, the Hadoop+JuiceFS approach employs additional replicas to enhance storage performance and ensure compatibility and high availability. The solution of DataNodes (DN) writing only a single replica relies on iterative improvements in JuiceFS for reliability.
While we've successfully implemented a multi-cloud-compatible solution that outperforms EMR on different cloud platforms, there's still room for further refinement when it comes to hybrid multi-cloud and cloud-native scenarios.
Looking ahead to the future of cloud-native big data, our current solution is not the final iteration but rather a transitional one aimed at addressing compatibility and cost issues. In the future, we plan to take the following steps:
- We’ll advance our application towards a more cloud-native approach, decoupling from the Hadoop environment and tightly integrating data lakes with cloud-based computation.
- We’ll drive higher-level hybrid multi-cloud compute and storage solutions, achieving true integration rather than just compatibility. This will deliver increased value and flexibility to our upper-layer application units.
If you have any questions or would like to learn more details about our story, feel free to join discussions about JuiceFS on GitHub and the JuiceFS community on Slack.