















This case study is sourced from a JuiceFS customer, a leading provider specializing in autonomous driving.
The scale of data generated in the autonomous driving sector is unprecedented. Starting in 2021, the company decided to build its own cloud-native storage platform. After considering factors like cost, capacity elasticity, and performance, they ultimately chose to build their storage infrastructure based on JuiceFS. Currently, the storage platform efficiently manages tens of billions of files, achieving 400,000 IOPS, nearly 40 GB/s throughput, and performance on par with their previous commercial storage solution. What’s more, the company significantly reduced their storage costs.
This post will cover the storage challenges in the autonomous driving industry, why the company chose JuiceFS over other solutions like Amazon S3 and Alluxio, and how they use JuiceFS.
Storage challenges in the autonomous driving industry
Autonomous driving research generates an enormous volume of data, with each test vehicle collecting around 60 TB of data daily. Industry giants like Mobileye have amassed over 200 PB of data, and General Motors' autonomous driving division, Cruise, has data exceeding the exabyte level. However, this data, after processing, isn't static "cold data"; it’s frequently used in activities like model training. Therefore, managing this massive amount of data poses unprecedented challenges, including:
-
High commercial storage costs: Acquiring high-performance commercial storage servers and hard drives entails fluctuating prices and procurement cycles.
-
High throughput data access challenges: As AI usage with GPUs increases, underlying storage I/O can't keep up with computing capabilities. Enterprises demand storage systems offering high throughput data access to leverage GPU computing power.
-
Management of tens of billions of small files: In the autonomous driving field, training models rely on small images, each just a few hundred kilobytes in size. A single training set comprises tens of millions of such images, with each image treated as an individual file. The total volume of training data can reach billions or even tens of billions of files. Managing this volume of small files has always been a challenge in the storage field.
-
Providing throughput scalability for hot data: In the autonomous driving field, data used for model training must be shared for reading and writing by multiple development teams. This leads to data hotspots. Even when disk throughput is fully utilized, it can't meet the application's needs.
-
High-performance data access in hybrid clouds: In hybrid cloud environments, data may be distributed across local, public, and private clouds. Ensuring high-performance access to data across these different environments is a significant challenge, considering data transfer speed, access latency, and data consistency in hybrid cloud setups.
Why choose JuiceFS over Amazon S3 and Alluxio
Faced with the challenges mentioned above, the company embarked on building its storage platform, starting with the selection of a file system. According to incomplete market statistics, mainstream storage systems in the industry can be categorized into three types:
- Cloud provider file storage: These systems typically feature all-flash hardware configurations, offering outstanding performance but come at a high cost.
- Object storage: While cost-effective, these systems often fall short in terms of training speed and may not meet the demands of training scenarios.
- Cloud-native file systems: The company evaluated various systems, such as Alluxio, RapidFS, JindoFS, and JuiceFS.
The table below summarizes key characteristics of selected products:
| Category | Amazon S3 | Alluxio Community Edition | JuiceFS Community Edition |
|---|---|---|---|
| Cost | See details | N/A | N/A |
| Maximum capacity | Several hundred petabytes | PB-level | 100 PB |
| Number of files | 100 billion | 1 billion | 10 billion |
| Protocols | POSIX/S3 | POSIX/NFS/SMB/HDFS/S3/K8s CSI | POSIX/NFS/SMB/HDFS/S3/K8s CSI |
| Caching | Commercial acceleration | Supports local and cluster caching | Supports local caching |
After a comprehensive evaluation based on cost, capacity, protocols, and performance, the company chose JuiceFS. Testing revealed that JuiceFS excelled in scenarios involving large file sequential read/write operations. However, it did not fully meet their requirements for random read/write operations and small file read/write scenarios.
Nevertheless, because JuiceFS caters to enterprise-specific customization needs and has cost advantages, the company ultimately opted for JuiceFS. For scenarios where its performance was not optimal, they embarked on a series of optimization efforts, which will be elaborated on in the following sections.
JuiceFS application scenarios
Scenario 1: Data processing
In an IDC environment, various data processing tasks, such as frame extraction, are performed to generate training data. Initially, the dedicated 40 Gbps link between the IDC and cloud-based object storage could handle the bandwidth requirements. However, as data processing demands grew, this link became saturated quickly. To address this, the link's bandwidth was upgraded to 100 Gbps, which alleviated some of the bandwidth pressure. However, during peak usage periods, even the requirements of just a few users could saturate the link once again.
To address the issue of insufficient bandwidth for object storage, the company used a temporary solution, involving the use of commercial storage as a cache for JuiceFS. This helped reduce the dependency on the dedicated link bandwidth during data processing.
This approach encountered several challenges:
-
Cache time-limit and performance issues: JuiceFS periodically scans the cache disk, storing file indexes in memory after each scan. This means that changes made by one user in the cache data are not immediately visible to another user. Additionally, managing a large volume of cache data places a burden on index scanning and updates.
-
Cache rebuild performance: Given the large amount of cache data, multiple cache directories were added to speed up index rebuilding through multi-threading. However, the cache hit rate was still not ideal.
-
TiKV stability and performance issues: The high volume of data resulted in increased disk I/O load, necessitating optimizations to TiKV. Parameters such as locks, caches, threads, and fault domain levels were optimized to address stability and performance issues.
-
Upload speeds: Some machines experienced slow upload speeds. Investigation revealed that this was due to certain machines being in power-saving mode. This was rectified by setting all machines to high-performance mode.
-
Slow client reads/writes: Initial read and write performance during uploads was not optimal. Various parameters were optimized, including adjusting FUSE queue sizes and increasing concurrency to improve upload and read performance.
With these optimizations, the system effectively handled data processing and frame extraction for training data. The temporary solution relied on commercial storage clusters as local cache disks for JuiceFS. However, as the subsequent development progressed, the company introduced a dedicated read/write cache cluster to fully replace the temporary solution based on commercial storage.
Scenario 2: Model training
Model training is one of the most complex scenarios in terms of data capacity and performance requirements. Challenges in this scenario stem from multi-cloud environments and data access performance.
Given the limited GPU resources in the in-house IDC, collaborations with multiple cloud providers were initiated to achieve elastic resource scheduling, while also ensuring disaster recovery, high availability, and cost reduction.
To lower costs, additional GPU procurement was made in regions with lower GPU prices and multiple deployments. Although the dedicated link within the IDC maintained low latency (1-2 milliseconds), external dedicated links exhibited higher latency (4-6 milliseconds). This level of network latency significantly hindered the efficient use of JuiceFS for training models with data from hundreds of millions of images.
To address this challenge, the company decided to build a dedicated cache system to reduce I/O access time, ensuring high-speed data access within the same data center and optimizing data access performance while minimizing network latency costs.
Building a read cache cluster
The business primarily emphasizes read operations, where the read-to-write ratio can be 4:1 or higher. Optimizing read performance is crucial in such cases. Since the JuiceFS Community Edition does not support distributed caching, the company planned to build an independent cache cluster. Unlike write caching, read caching is more straightforward and does not result in data loss, only impacting read speed.
Challenges related to read amplification:
After the initial setup of the read cache cluster, issues related to read amplification surfaced. To address this, an explanation of JuiceFS' "prefetch" mechanism is necessary. Depending on the file reading method, JuiceFS clients employ different prefetch modes: "prefetch" for random reads and "readahead" for sequential reads. These mechanisms result in data read amplification as data is loaded from object storage. Even when requesting a small amount of data, for example, 4 KB of data, the prefetch mechanism (both prefetch and readahead) can expand this request to 4 MB or 32 MB, causing significant read amplification, especially from readahead. This, in turn, strained the cache cluster's network cards.
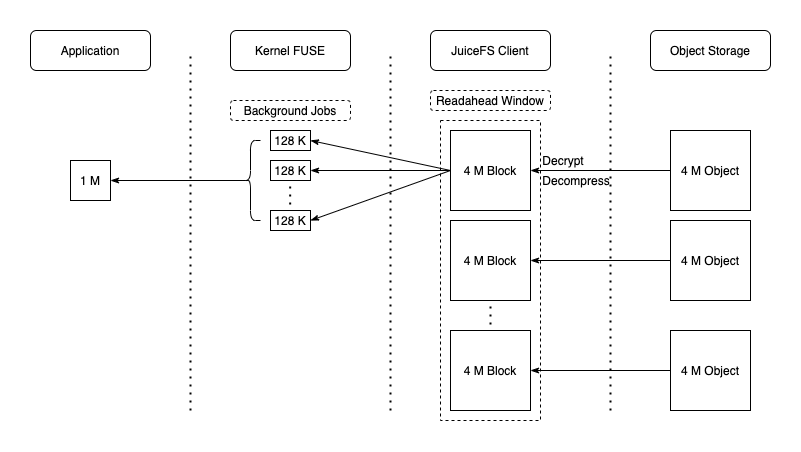
To mitigate this issue, the prefetch strategy was customized in the JuiceFS Community Edition. Readahead prefetch was enhanced to be a switchable mode (turned off by default), thereby moving the readahead mechanism to a dedicated cache system, relieving pressure on the cache cluster.
Establishing a write cache cluster
When data was first accessed by a user, it might experience slow read speeds because it had not yet been cached in the read cache cluster. To address this issue, the company built a write cache cluster.
In the event of a write operation, data was initially written into a write cache cluster, which was built on flash storage. While there was consideration to modify read cache to support write caching and dual writes, the implementation posed challenges, as it could potentially lead to lost write requests during high loads, and it was technically complex. Consequently, the company chose write cache as the write caching solution.
To ensure data reliability, the write cache cluster supports various redundancy configurations. For the first data write, small I/O operations can opt for dual or triple copies, while large I/O operations are written directly into Erasure coding (EC) object storage. Once data is successfully written to the write cache cluster, it immediately responds to the client and asynchronously copies data to the read cache cluster. This ensures that users can quickly access the data during subsequent read operations.
In addition to asynchronous copying to the read cache cluster, data also needs to be asynchronously uploaded to the object storage. In cases where the write speed is significantly higher than the consumption speed, it can result in higher upload latencies. Therefore, the company employed a multi-threaded and multi-client upload approach to accelerate the uploading process, ensuring that pending data remained within manageable limits. To prevent data amplification due to data contention between multiple threads or clients, a distributed locking mechanism was introduced. Thread locking mechanisms ensure data upload to the object storage and compare it with data in the write cache, subsequently clearing the write cache data upon a match.
By establishing a dedicated write cache cluster, the company further optimized the initial read speeds. Currently, both read and write caches can be dynamically adjusted based on requirements. Moreover, the company introduced degradation strategies, such as switching to synchronous writes when a certain threshold is reached.
Metadata cache optimization
Currently, the company faces a situation where GPU training resources are located in a different city from the metadata storage. With a dedicated link latency of 4-6 milliseconds, every metadata request has to be sent to the metadata cluster, leading to challenges in meeting the performance requirements of GPU training tasks.
While using JuiceFS Community Edition, the system supports kernel and in-memory caching for metadata. However, this approach carries the risk of data inconsistencies. For example, when a user modifies data, another user may not immediately perceive these changes (only upon reopening the file). This situation is particularly prevalent in scenarios involving the generation of JSON files, where the same file may undergo frequent overwrites or appends. To address these issues, the company has optimized the metadata caching of JuiceFS Community Edition with the following approach:
- Intelligent file type caching: The company categorizes files into dynamic and static types and applies distinct caching strategies based on their classification. This enhances cache efficiency and consistency.
- Metadata cached on the client or within the same data center: Storing metadata caches in client memory or within cache clusters in the same data center is an effective strategy. It reduces the need for cross-data center metadata requests and improves metadata access speed.
Scenario 3: HDFS support
To unify the storage technology stack for voice-related scenarios and enhance performance, the company made a decision to migrate the storage cluster for voice scenarios from HDFS to JuiceFS + Ceph RADOS. While this migration presented some challenges, the current solution effectively meets business requirements.
One of the primary challenges was that the JuiceFS Community Edition supports a Java SDK but lacks support for C++ and Python SDKs. To avoid the high cost of developing custom solutions, the application side transitioned from using SDKs for Python and C++ to utilizing POSIX interfaces for accessing the storage cluster, enabling data access similar to reading from local hard drives.
If you have any questions or would like to learn more details about this story, feel free to join discussions about JuiceFS on GitHub and the JuiceFS community on Slack.